改進SSD的機場場面多尺度目標檢測算法
2022-04-09 07:06:18黃國新張比浩梁斌斌韓笑冬宮江雷武長青
計算機工程與應用 2022年5期
黃國新,李 煒,張比浩,梁斌斌,3,韓笑冬,宮江雷,武長青
1.四川大學 視覺合成圖形圖像技術國防重點學科實驗室,成都 610065
2.四川大學 空天科學與工程學院,成都 610065
3.四川川大智勝軟件股份有限公司,成都 610045
4.中國空間技術研究院 通信與導航衛星總體部,北京 100094
視頻監控系統可以提供信息豐富的圖像,精確而具體地描述物理世界。因此,視頻監控系統被廣泛應用于交通、公共安全、體育賽事等諸多領域。機場場面監控視頻中的多尺度目標檢測是指視頻每幀中包含的尺寸大小不同的物體,對它們進行類別識別和位置定位[1-2]。作為機場安全有效運行所必須面對的基本問題,有效且可靠的機場場面視頻目標檢測在其中扮演了重要角色[3]。然而,由于機場場面地理和環境限制,大部分的監視攝像頭只能架設在距離地面較遠的塔臺或者航站樓上,導致場面上的人員、車輛等目標,在圖像畫面中很小,甚至只有百余個像素大小。特別是在塔臺上架設的全景監視攝像頭圖像里,人員占比整個畫面可以低于1%,使得場面上的人員、車輛以及遠場的航空器在進行目標檢測時特征不明顯,難以被正確地檢測[4]。除此之外,機場場面環境中存在遮擋,各類目標間大小相差較大,還存在同一類目標,例如飛機,在遠場和近場時圖像占比差別較大的問題。
隨著近年來深度學習的發展,基于深度學習的目標檢測器采用卷積神經網絡結構,得到了巨大的發展。Liu等人提出的SSD(single shot multibox detector)[5]算法是一種單階段的目標檢測器,其方法核心是使用卷積濾波器來預測特征圖上固定的一組先驗邊框的類別分數和位置偏移。SSD算法去掉了VGG[6]網絡中的全連接層,并在后續中加入了6層尺度不一的檢測層。SSD在PASCAL VOC2007[7]數據集上取得了74.3%的均值平均精度(mean average precision,mAP),并且使用NVIDIA Titan X的情況下輕量版SSD幀率可以達到59 frame/s。但是由于SSD的額外特征層,特別是最后一層分辨率為1×1,導致包含的空間信息過于粗糙,難以進行對目標的精確定位。網絡的淺層部分所包含的語義信息不夠豐富,導致網絡無法區分該目標是“人員”還是“雪糕筒”。
在本文中,針對上述機場場面人員類別圖像占比小、飛機類別尺度變化大的問題。在SSD算法基礎上通過加深網絡層,使用一個更深的骨干網絡,用于提取更豐富的語義信息。為了綜合網絡淺層和深層各自具有的空間細節信息和高級語義信息,使得網絡淺層對小目標具有更魯棒的表征能力,本文使用融合特征層的方法,構建了一個基于元素積的特征金字塔網絡,從感受野較大的深層中檢測大目標,感受野較小的淺層中檢測小目標。針對目標遮擋重疊的問題,使用Soft-NMS算法[8]以保留檢測正確的預測框,減少漏檢的情況。最后為了更好地適應機場場面環境,調整先驗框的尺度,加速網絡的訓練和收斂。實驗結果表明,本文改進算法在機場場面環境下能夠取得先進的性能,特別是在人員類別精度上提升明顯。
1 研究與方法
1.1 網絡整體架構概述
本文算法框架主要分為骨干網絡、額外特征網絡以及特征融合網絡三部分組成,整體網絡架構如圖1所示。網絡輸入首先經過ResNet-50骨干網絡進行特征提取,再進入六層額外特征網絡進一步地提升語義信息維度,隨后將額外特征網絡中的三層與ResNet-50骨干網絡中后三個階段的末層特征圖進行自頂向下的特征融合,最后將特征融合網絡的六個融合特征圖輸入到檢測層。研究表明[9],殘差網絡模型能夠提取語義信息更加豐富的特征圖,在此基礎上利用多尺度特征金字塔網絡[10]融合模塊進行不同尺度的特征圖融合,獲得細節信息和語義信息更豐富的檢測特征圖。其次,在模型大小與計算量方面,殘差模型ResNet-50在分類精度與ResNet-101相差不多的情況下,計算量遠小于后者。因此本文將SSD本身的骨干網絡VGG替換為網絡層更深且計算量相對較低的ResNet-50。本文在額外特征網絡中設計了六個特征圖,在每次縮小特征圖前使用1×1的卷積核調整通道數,減小計算量[11-12],詳細參數如表1所示。在圖1額外特征網絡中為了使網絡結構表達簡潔,將Conv6_1、Conv7_1和Conv8_1未顯式地表明出來。特征融合網絡中,在不同分辨率大小特征圖間做融合時,未將低分辨率特征圖上采樣步驟顯式表明,具體實現在下一小節會詳細介紹。最后,利用特征融合后得到的不同層級的特征圖進行不同大小尺度的目標候選框生成和類別預測,并在模型推斷階段采用Soft-NMS軟性非極大抑制算法進行重疊框過濾以減少目標重疊情況下的錯刪情況,最終得到檢測結果。
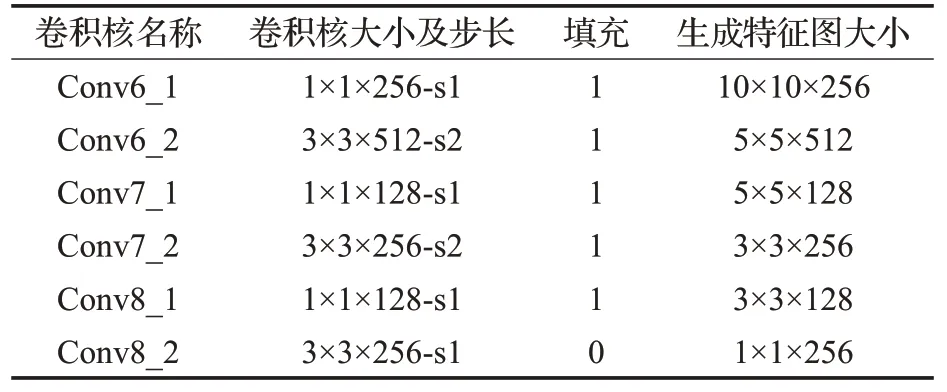
表1 額外特征網絡卷積核詳細參數Table 1 Additional feature network convolution kernel detailed parameters
1.2 基于特征金字塔的特征融合網絡
在原始的SSD檢測模型中,其對輸入圖像進行特征提取的卷積神經網絡通過逐層計算的方式得到特征圖層次結構。由于特征圖層次結構之間存在子采樣層,最終得到的特征圖層次呈現為多尺度的特征圖金字塔結構。利用不同層級的特征圖對不同尺寸大小的物體進行檢測,以達到多尺度目標檢測的目的。對于尺寸較小的目標,SSD利用淺層特征圖進行檢測,而對于尺寸較大的目標物體,則依靠深層特征圖進行檢測。
卷積神經網絡越深的特征層不變性越強而同變性越弱,而低層網絡雖然語義特征比較差,但是含有更豐富的邊緣及輪廓信息。所以SSD中淺層的特征圖雖然具有高分辨率和豐富的物體細節特征,但其語義抽象信息往往不足。而深層特征圖經過多層卷積層后其語義抽象十分豐富,但由于池化層的采用又導致其分辨率較低。因此,SSD采用各層級特征圖獨立檢測不同尺度大小物體的方法往往在小目標物體較多,物體尺度變化較大的場景中檢測效果較差。為了同時保持不變性和同變性,可以采用融合多層特征圖的方式[13-14]。一個直接改進的方法是融合不同層級的特征圖,使各層級特征圖既具有豐富的物體細節特征,又具有高分辨率與抽象的語義信息。
本文使用的特征圖融合方式如圖2所示。ResNet-50由于具有殘差模塊,因而可以在保證模型訓練收斂的同時使特征提取網絡具有更好的語義抽象能力。本文將ResNet-50的第三階段末層、第四階段末層和第五階段末層稱為{Conv3_x,Conv4_x,Conv5_x}。雖然ResNet-50中有5個階段殘差塊,但是前兩個階段產生的特征圖語義信息維度太低,所以本文在常規ResNet-50網絡后增添了三層特征圖用于特征融合。由于做特征融合計算時,需要特征圖的分辨率和通道數嚴格相同,所以在特征圖進入到特征融合網絡前,都預先使用1×1的卷積核進行通道調整。例如圖2中,Conv6_2經過1×1卷積后與P7層通過2倍最鄰近插值上采樣后的特征圖進行元素式操作。元素式操作,通常有三種方法,一是對應元素的和,二是對應元素的積[15],三是元素并置即通道疊加(concat)。對應元素的和是執行特征融合最簡單的方法。它最近被頻繁地用于許多目標檢測器中。對應元素的積與對應元素的和非常相似,唯一的區別是使用乘法而不是求和。求積的一個優點是它可以用來抑制或突出某個區域內的特性,這可能進一步有利于小目標檢測。元素疊加是特征融合的另一種方式。它的優點是可以用來集成不同區域的語境信息,缺點是增加了內存。本文采用的是對應元素的積的方式,以針對機場場面上的小目標,例如人員取得更好的檢測效果。最后,將自頂向下融合生成的網絡特征圖輸入到檢測層中,使用不同分辨率的特征圖來檢測不同大小的目標。
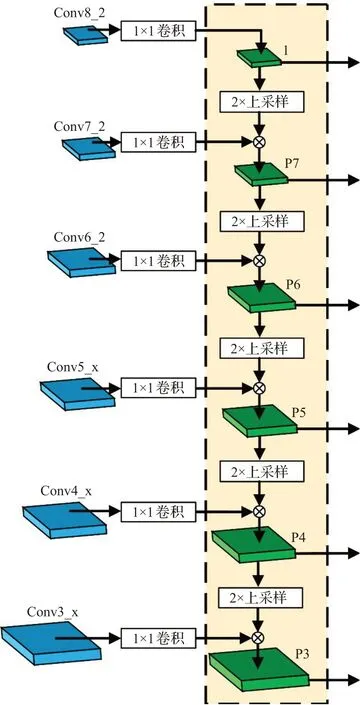
圖2 特征金字塔融合網絡Fig.2 Feature pyramid fusion network
1.3 Soft-NMS軟性非極大值抑制
在傳統的目標檢測框架中,其采用滑動窗口機制來對窗口中可能出現前景目標或者背景目標的置信度進行打分。然而,由于相鄰的滑動窗口之間的置信度通常相近,這就會提高假正例目標的出現,因此,傳統的解決方案是采用非極大值抑制(non-maximum suppression,NMS)進行后處理操作,其算法流程如算法1所示。NMS能過濾掉面積重疊部分大于一定閾值的滑動窗口,以獲得最終檢測結果[16]。隨著深度學習的發展,滑動窗口機制已被基于卷積神經網絡預測的區域候選框所替代,但是仍然采用NMS來降低假正例數量和消除冗余檢測框。然而,由于NMS直接將重疊的候選框刪除,在同一類別物體位置相近的情況下,其往往會出現將真正例物體錯誤過濾的情況。
算法1常規NMS算法
步驟1在所有生成的預測框中找到置信度最高的預測框A,將預測框A與其他的預測框進行交并比計算,判斷是夠大于預先設置的閾值p。
步驟2將步驟1中大于設定閾值p的預測框刪除,保留預測框A。
步驟3在其余剩下的預測框中找到置信度最大的預測框B,重復步驟1和步驟2,直至遍歷完所有的預測框。
步驟4算法結束。
鑒于機場場面環境中目標類別少,同一類別物體往往同時存在。因此,若仍然直接采用NMS進行預測候選框的后處理操作,將容易導致漏檢情況的發生。針對NMS的缺點,本文在模型測試階段將其替換為軟性非極大值抑制Soft-NMS來過濾檢測框,其算法如算法2所示。
算法2Soft-NMS算法
步驟1在所有生成的預測框中找到置信度最高的預測框A,將預測框A與其他的預測框進行交并比計算,判斷是夠大于預先設置的閾值p。
步驟2將步驟1中大于設定閾值p的預測框使用高斯加權衰減處理,降低其預測框的置信度,并且保留預測框A。
步驟3在其余剩下的預測框中找到置信度最大的預測框B,重復步驟1和步驟2,直至遍歷完所有的預測框。
步驟4算法結束。
Soft-NMS僅降低預測置信度較高目標候選框附近的其他同類別目標的置信度大小,降低的幅度大小由一個與最高分檢測框交并比大小(intersection-over-union,IoU)有關的懲罰函數來決定。當前檢測框與最高分檢測框的IoU越大,其懲罰也將越大,從而達到過濾無效的重疊檢測框,又避免不同物體的檢測漏檢情況,以提升檢測模型在預測密集目標時的檢測精度。本文所采用的懲罰函數如公式(1):

其中,si為第i個預測框的置信度,e為自然底數,M為最大置信度的預測框,bi為第i個預測框,σ為常數0.5,D為已經遍歷后的預測框集合。
1.4 先驗框尺度調整
改進的SSD從特征融合后的卷積層中分別提取P3、P4、P5、P6、P7和最后的1×1層,作為檢測所用特征圖。由于網絡結構中不同層級的特征圖的感受野不同,因此SSD依靠在不同層級特征圖上預定義一系列不同尺度大小的先驗框來定位不同尺度大小的物體。假設使用了m張不同層級的特征圖來進行檢測,各層級特征圖上的先驗框尺寸大小計算如公式(2)所示:
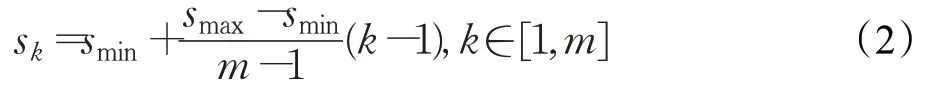
其中,sk表示先驗框尺寸相對于輸入圖片的比例大小,smin和smax表示比例的最小值與最大值。在原始的SSD論文中,smin和smax的取值為0.2和0.9,然而該比例是針對于日常生活中的環境,并不能有效地擴展到其他特定的檢測場景。通過對機場場面監控數據集分析,本文將smin和smax的值調整為0.1與0.8,這能使先驗框更好地覆蓋機場場面物體尺度大小分布,且能有效地避免小目標物體的漏檢問題,使檢測模型網絡能夠被更充分訓練。
2 數據與實驗分析
2.1 機場場面監控數據集
在目標檢測領域有許多非常具有挑戰意義的公開數據集,例如PASCAL VOC[17]和MS COCO[18]等,但是在機場場面的監視數據集方面,由于機場的特殊環境及安全保密限制,目前暫時沒有公開的數據集。本文通過獲取機場場面的監視視頻及在塔臺自制機位的監視器拍攝視頻,包含成都雙流國際機場、貴陽龍洞堡國際機場、麗江三義國際機場和海口美蘭國際機場在內的國內中大型機場總時長超過300小時的視頻數據,累計標注5 064個有效樣本。由于拍攝時間和設備的不一致,數據集中含有960×540和1 920×1 080兩種不同大小分辨率的圖片樣本。本文使用labelImg工具對樣本進行標注,仿照PASCAL VOC格式進行存儲最終得到機場場面數據集。本文還使用了隨機亮度、隨機裁切和隨機翻轉的數據增強方法,在訓練和測試時,將兩種分辨率的樣本均縮小到300×300。
本數據集分為兩部分,一部分供神經網絡進行學習為訓練集共4 051個樣本,另一部分用于網絡模型的測試評估為測試集共1 013個樣本。訓練驗證測試樣本比例與通常的3∶1∶1不同,本實驗直接將訓練集和驗證集進行合并。其中,測試集通過均勻抽取的方式獲得,即每5個樣本抽取1個樣本作為測試集。通過對數據集進行分析,共標注了航空器13 117個、車輛8 660個、人員8 942個。機場場面數據集包含了場面目標不同姿態、環境光照、角度變換、日夜色彩及常見的天氣狀況下的各種情況,可以作為較為普適性的通用機場場面數據集。圖3展示了機場場面數據集的部分示例,包含了晴天、夜晚、目標大小不一致等情況。表2統計了數據集中航空器、車輛和人員的尺度大小和樣本個數。

圖3 機場場面數據集部分樣本示意圖Fig.3 Schematic diagram of some samples of airport surface dataset

表2 機場場面數據集目標像素統計Table 2 Object pixel statistics of airport surface dataset
通過圖3樣本示例和表2像素統計可以看出,航空器目標類的尺度變化最大,最極端的情況下高達兩千余倍的大小差異,且在部分角度下存在較大幅度的遮擋的情況。場面上的人員所占像素太少,平均像素值只有523,檢測該類別相比于其他類別更難。所以本文的數據集還是具有一定的檢測難度。
2.2 實施細節與評價標準
本文實驗基于PyTorch[19]深度學習框架,硬件平臺為Nvidia 1080Ti顯卡和Intel i7-8700K中央處理器,操作系統為Ubuntu 18.04。為了保證測試結果的公平性,本文對所有檢測模型都未使用預訓練模型。本文算法使用交叉熵作為損失函數,為了使模型完全收斂一共訓練了6萬次,初始學習率為0.01并逐步衰減到0.000 1至訓練完成。
評價一個目標檢測器的好壞,通常從兩方面來考慮,一方面是檢測的精度,另一方面是檢測的速度。評價檢測速度通常用每秒鐘檢測器能夠檢測圖片的數量即幀率(frames per second,FPS)作為檢測算法的實時性指標。檢測精度通常使用均值平均精度mAP來表示。檢測目標需要兩個信息,一個是預測的目標框位置,一個是預測的目標類別。當預測框與實際真實框的IoU大于等于0.5時,則認為該框的位置預測正確。IoU的計算方法如公式(3)所示:

式中,Bp代表預測框的區域,Bg代表真實框的區域。IoU越高,代表預測框與真實框的重疊度越高,則預測值就越接近真實值。
有了對框的評價,結合框的位置和分類結果進行評價,引出兩個概念,精度(precision)和召回率(recall)。將預測框的結果分為4類,包括了有無預測框和類別是否正確的四種情況。當目標檢測器的預測框出現,即為正,反之則為負;預測正確即為真,反之則為假。基于此定義,精度可以使用下列公式(4)計算:

式中,TP代表該目標被正確檢測,即目標的類別預測正確,且預測框與真實框的IoU大于設置的閾值。反之,則FP代表該目標被預測錯誤。上述說明了有預測框的兩種情況,當沒有預測框時,使用TN代表沒有預測框在沒有目標的位置,也可以認為是正確的預測為背景;使用FN代表沒有預測框在有目標的位置,即為漏檢。召回率可以使用下列公式(5)計算:

簡單來說,精度代表了在已經預測的框中,預測正確的框占比多少;召回率代表了在所有真實的實際框中,預測正確的占比多少。一般來說,目標檢測器的精度和召回率都同時越高越好,但是在實際情況中,通常這兩個指標成負相關,當調節閾值使得精度較高時,召回率會下降,當召回率高時,精度會下降。
平均精度(average precision,AP)是指在不同召回率情況下,對精度的求和平均。通常平均精度的召回率取值區間為[0,0.1,0.2,…,0.9,1],對這11個召回率值下的精度求和平均得到某個類別的平均精度。對于多目標檢測器來說,將多個類別的平均精度進行累加求和后再平均,即可求得mAP。
2.3 實驗結果與分析
為了驗證本文提出的改進SSD算法能否取得更好的檢測效果,在上述的機場數據集中進行測試實驗。首先進行消融實驗,以驗證改進算法的各組件的性能。消融實驗中,除變量參數以外,其余網絡設置,訓練步驟均保持一致。首先使用特征提取網絡ResNet-50替換SSD中特征提取網絡VGG-16,作為基準模型。然后依次實驗分析了,獨立加入金字塔特征融合網絡和獨立加入Soft-NMS對基準模型的影響,最后同時使用兩個組件得到最終的實驗結果,詳細實驗數據如表3所示。
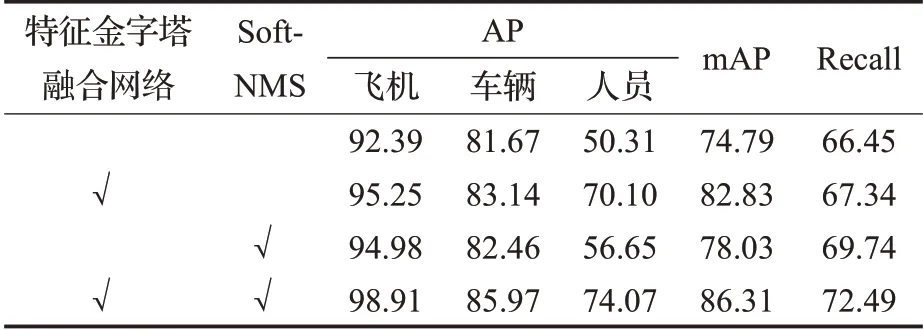
表3 特征金字塔融合網絡與Soft-NMS的消融實驗Table 3 Ablation experiment of feature pyramid fusion network and Soft-NMS %
由表3可以看出,在基準模型基礎上添加自頂向下的特征金字塔融合網絡,在三個類別的AP中都有一定程度的提升,mAP相較于基準模型提高了8.04個百分點。特別是在人員類上,相較于基準模型,驚人地提高了接近20個百分點。證明了基于元素相乘的特征金字塔融合網絡能夠對小目標有比較好的魯棒性。在預測框處理階段單獨使用Soft-NMS同樣有3.24個百分點的mAP的提升,特別在召回率方面,由于檢測到了更多正確的目標,召回率也提升了3.29個百分點。說明在一定程度上,解決了目標間重疊導致的漏檢和錯檢的情況。最終本文改進算法通過結合上述兩個組件,取得了86.31%的mAP和72.49%的召回率。為了更好地證明本文改進算法的性能,還與原始SSD、YOLOv3[20]等先進目標檢測算法在檢測精度和推斷速度進行實驗比較,結果如表4所示。
由表4可知,與其他算法相比,本文算法在mAP方面具有更好的性能。本文算法提高了三種類別的平均精度。特別是對于人員類別,在同一輸入大小情況下,相較于原始SSD,檢測精度提高了47.25個百分點,在推斷速度方面,本文提出的算法還可以保持較高的檢測速度,達到了32 frame/s。與YOLOv3算法相比,本文算法雖然在推斷速度上有所差距,但是在各類別和mAP的精度上均處于大幅度領先的水平。如圖4所示,可以直觀地看出本文算法是較好的,并且每個檢測框具有較高的置信度。YOLOv3和SSD512對于飛機等大目標也具有較好的檢測效果,但是在人員等小目標檢測上存在明顯的漏檢情況。Faster R-CNN(ResNet-50+FPN)[21]的檢測效果中有更多冗余框。特別是對于小物體,同一物體基本上具有兩個檢測框,如圖4(d)所示。通過與先進目標檢測算法對比,本文提出的改進SSD算法無論是在模型的推斷速度還是mAP上都處于先進的水平。

圖4 本文算法與先進檢測算法效果對比Fig.4 Comparison of effect of algorithm in this paper and SOTA detection algorithm

表4 本文改進算法與先進目標檢測算法實驗對比Table 4 Experimental comparison between improved algorithm in this paper and SOTA object detection algorithm
3 結束語
本文通過對SSD算法改進骨干網絡,加入特征金字塔網絡,使用Soft-NMS以及調整先驗框尺度四個方面以適應機場場面監視環境。實驗結果表明,本文算法獲得了在輕微降低推斷速度的情況下,大幅度提升檢測精度,特別是針對難以正確檢測的人員類目標。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
