數據挖掘技術在工程造價領域的綜述
2022-04-14 02:02:36金春月孟云桃何潔
建材發展導向 2022年7期
金春月 孟云桃 何潔
(上海市機電設計研究院有限公司,上海 200040)
隨著科技的進步,以大數據、云計算、BIM、人工智能等為代表的新技術得到了廣泛地發展和應用。面對“大數據”浪潮的沖擊,建筑工程領域還停留在通過人工方法和工具對數據進行簡單錄入、查詢、更改、統計、輸出。人工統計方法工作內容繁重極易出錯,且無法從海量數據預測未來趨勢,不能給決策者提供有利的數據支撐。因此通過數據挖掘技術從工程歷史造價數據中挖掘出數據間隱含規則,并應用于實際工程管理,已是大數據環境下工程造價管理研究的主流,也是工程造價管理的必經之路。
目前、國內在數據挖掘技術的理論研究和應用層面都有了一定數量的研究,但總體還處于探索階段。大部分數據挖掘技術的綜述集中在計算機、中醫與中西醫結合、工商管理等領域,尚無專題總結建筑工程領域數據挖掘技術和應用的文獻。鑒于以上現狀,需填補國內針對建筑工程領域數據挖掘現狀的綜述文獻的空白。
本文從技術層面和應用層面對文獻進行分類。前者列舉和總結了數據挖掘技術在工程造價方面的關鍵技術,包括數據分類技術、數據建模技術;后者總結了數據挖掘相關應用。在此基礎上討論了現存的問題和未來發展方向。
1 數據挖掘技術現狀分析
數據挖掘技術通過計算機等信息處理工具對海量的、不完整的數據信息進行針對性地分類、整理、清洗、提煉,高效地把隱含在信息中的數據關系挖掘出來,為項目的投資決策、方案比選、限額設計、可行性研究、以及投標決策等提供可靠依據,并準確快速地預測工程造價信息。
在中國知網(CNKI)以“數據挖掘”和“造價數據挖掘”為關鍵詞進行檢索,文獻類型包括學術期刊與學位論文,時間區間從2011年到2020年,得到文獻數量如圖1。
由圖1有不難看出,每年有幾千篇關于數據挖掘技術的文章在中國知網發表,但針對工程造價的數據挖掘文獻每年只有二三十篇,僅占數據挖掘總文獻數量的0.4%左右。可見近幾年數據挖掘技術在我國有了飛速發展,但在工程造價領域數據挖掘技術的相關研究及應用還處于起步階段。因此需要加強工程造價領域數據挖掘力度和數據利用深度。
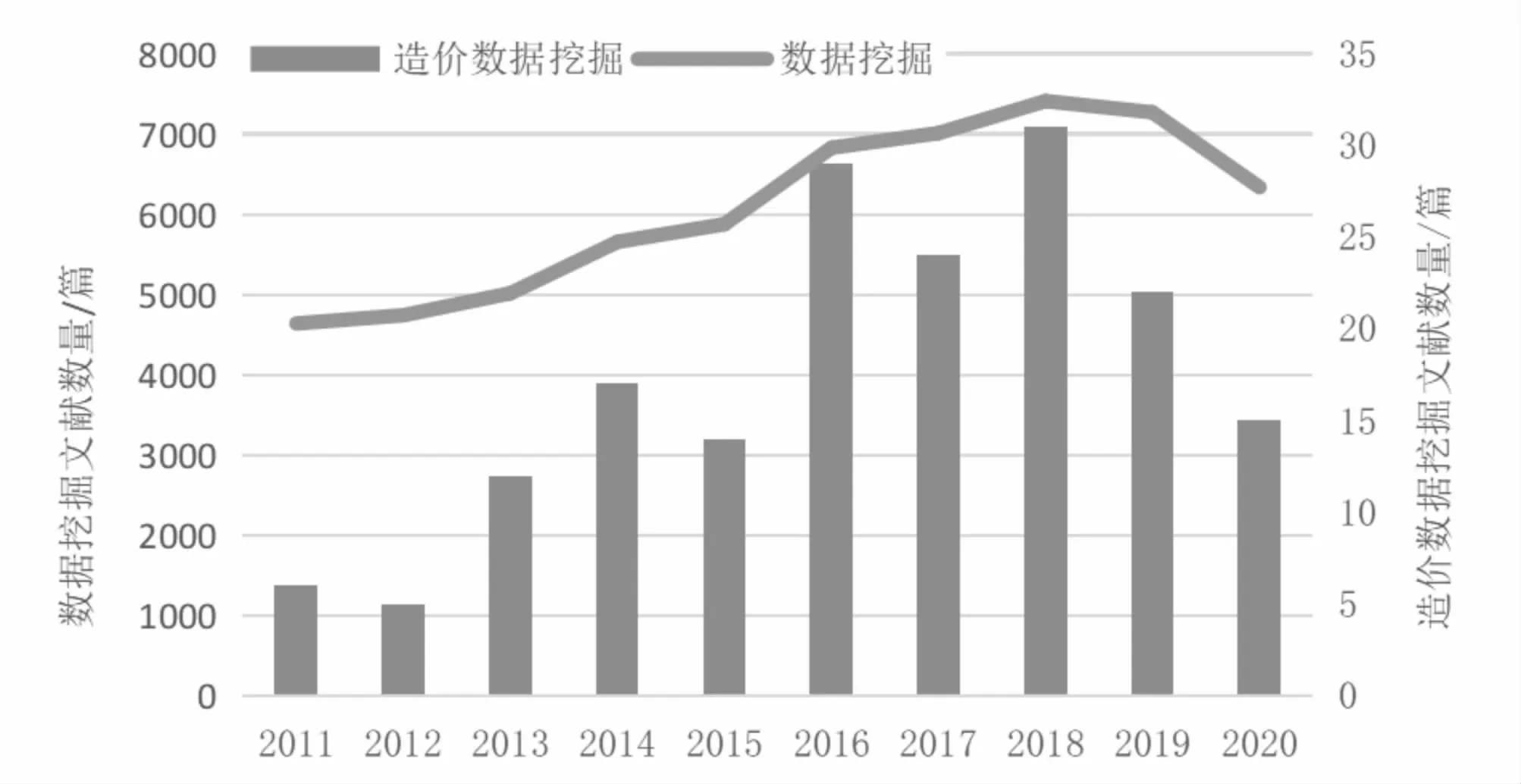
圖1 中國知網的文獻數量
2 技術層面綜述
在進行建筑工程造價數據挖掘時,若將不同類型、不同地區的工程造價信息簡單地雜糅在一起,會使計算出來的造價指數失去本身的指導價值。因此數據挖掘首先通過數據分類技術,把預處理好的工程造價信息根據項目需要進行分類,并從數據源中收集與目標項目相關的數據信息,將其轉化為滿足挖掘算法需求的形式,然后依據之前選定的數據挖掘算法,采用相應工具從準備好的工程數據中提煉出感興趣的價值信息和知識并進行展示。
數據挖掘技術的主要流程包括數據采集、數據預處理、數據分類、數據建模技術。其中最核心的技術是數據分類技術和數據建模技術,其相關文獻如表1所示。

表1 關鍵技術相關文獻
2.1 數據分類
建筑工程項目特征指繁多,包括定性特征值和定量特征值,且數據差異性較大。在大數據環境下,直接對類型多樣的數據特征值進行學習,會影響預測結果的準確性。因此依靠有效的數據分類技術對海量、多源、異構的工程項目數據信息進行合理分類是數據挖掘的重要技術前提。數據分類技術大體包括聚類法分類和決策樹法分類。
2.1.1 聚類法分類
K-means聚類法是把空間內的點分成K類,將距離函數做為研究數據相似度的衡量標準,通過算法對數據樣本進行分類解算,測算不同分類數據的距離,并迭代找到距離最近的分類和點,往復迭代直到找到最優解為止。K-means聚類法具有釋放性強,收斂速度快,聚類效果好等特點,但需要提前確定聚類數K值。聚類數K值的取值對聚類結果有較大的影響。模糊C均值聚類法是在聚類法的基礎上融入了模糊數學理論,解決了分類過程中非此即彼的問題,因此在分析正態分布數據的聚類有較好的效果,且能處理高維數據信息。
2.1.2 決策樹法分類
決策樹是通過已知的訓練數據建立決策樹,并利用建好的決策樹對數據進行預測。決策樹的建立過程可以看成是數據規則的生成過程。內部節點表示數據屬性上的判斷,分支代表一個數據判斷結果的輸出,葉節點代表一種數據分類結果。建設工程數據因為包含了大量的連續性屬性,因此采用傳統的決策樹分類方法進行計算將面臨非常大的挑戰。C4.5算法能對分類樹進行剪枝優化,且能對連續性屬性進行離散化處理。除此之外,針對高維小樣本數據或有很大一部分特征遺失的數據,隨機森林算法也可以維持較好準確度,且能平衡數據集的不平衡誤差。
2.2 數據建模
BP神經網絡算法具有智能學習能力,可以對建筑工程造價成本與其影響因素之間的關系進行非線性擬合,但人工神經網絡的結構復雜,追求最小誤差會導致出現“過擬合”現象,且降低模型的泛化能力。
總而言之,根據不同的要求實施適宜的護理干預措施十分重要,對降低泌尿外科醫院感染具有積極作用,且進一步改善預后。
支持向量機(SVM)利用核函數,將低維空間數據映射到高維特征空間,并在高維特征空間構造線性判別函數來實現原空間中的非線性判別函數。支持向量機(SVM)擺脫了高維數的冗余,使其算法與樣本維數無關,并實現了較好的推廣能力,但實際應用中核函數的選擇還沒有得到很好的解決。近些年各學者在支持向量機(SVM)的基礎上進行的不同程度的改進,均取得了良好的效果,詳見表1。
3 應用層面綜述
工程造價管理貫穿于工程建設全過程,充分挖掘歷史工程造價信息并合理應用到工程建設中,將對工程造價管理產生明顯效果。所考察的文獻中,有相當數量的文獻分析了工程建設各種環節中的數據分析應用,歸納至表2。數據挖掘技術不僅可以應用于造價估算、 工程審核階段, 趙平還通過數據挖掘技術分析工程造價與控制策略的智能匹配關系。

表2 應用方案相關文獻
此外,有些學者還研究了基于數據挖掘技術的工程造價信息平臺架構及管理,并進一步提出數據標準、可視化挖掘等問題。
4 討論及展望
隨著數據挖掘的不斷發展和對數據挖掘技術的不斷探索,許多研究者做出了技術上的貢獻,也取得了一定成果。
在上述調研中發現,相較于其他領域,數據挖掘技術在工程造價領域還處于初級階段,既表現在相關研究深入程度不足和缺乏成熟規模的應用案例,其原因如下。
1)數據挖掘深度比較淺。大部分學者的研究集中于造價指標、造價影響因素為代表的單一因素分析為主。工程造價信息除了造價指標外,還有材料的價格、綜合單價、建筑工程造價指數、建筑工程消耗量指數、建筑工程費用指數等有價值信息。深入挖掘和提煉信息間隱含關系,將大大提高工程管理效率。
2)工程造價歷史造價數據分享困難。因工程造價信息有較大使用價值,不同參與方為獲得超額利潤,拒絕分享有價值的信息。工程造價信息主管部門雖然會定期發布工程造價信息,但指數發布效率較低,且大部分是建安工程信息,市政工程、電力工程等專業的數據信息較少,無法滿足數據模型的多專業、多方面的驗證需求,基礎數據急需系統性管理與維護
3)各地區造價信息主管部門未頒布統一的工程造價信息標準。各地區造價行政主管部門發布的工程造價指數體系的測算方法、測算標準不統一,主要體現在發布形式不同、費用構成不同、編制范圍不同。因此在利用工程造價數據時,需對原始數據需進行復雜的數據清理才能能輸入到數據模型中并加以利用。
4)針對實際問題的研究方法比較基礎,數據挖掘技術在工程造價領域的應用研究仍然比較少,在平臺開發和算法實現方面有待提高,
5)需進一步優化數據挖掘模型的準確度和泛化能力,保證海量數據的有效利用,加快我國信息化技術的快速穩定發展。
針對以上問題,展望數據挖掘技術在工程造價領域的發展,將包括但不限于以下幾點。
1)進一步優化工程造價指標的數據挖掘算法,提高算法的有效性及準確率。并進一步擴大數據挖掘范圍,如:材料價格、綜合單價、主要材料消耗量等信息。
2)建筑工程造價指數測算過程中需要采集大量的、不同地區、不同類型的工程造價信息。開發適用于企業的數據挖掘工具,并以特定形式有償共享造價數據,提高工程造價數據的共享積極性,使各企業和造價相關人士能主動錄入準確、完整、真實的工程造價數據,形成信息共享產業鏈,做到全國范圍內的工程造價信息的互聯互通,實現工程造價數據的真正共享。
3)建議由政府相關部門牽頭,進一步完善全國范圍內的工程造價信息標準,包括但不限于信息編碼標準、數據采集標準、數據存儲標準、數據計算標準等。統一的數據標準可大大降低后續數據處理的人力與財力成本,提高數據挖掘效率。
4)建立全國統一的工程造價數據信息采集平臺和工程造價信息指標指數發布系統,由工程造價相關行政主管部門定期向社會發布建筑工程指標指數,并定期對信息采集系統和指標指數發布系統進行數據維護,優化工程造價信息的數據化管理及控制效果。
5)在數據分析及模擬過程中,需要對工程造價信息進行可視化的開發研究,并應用于數據的分析、統計、預測。可視化設計可以按照人的思維關聯模擬,從不同角度觀察和分析數據,便于人機交互的實現及應用效果的提升。
5 結語
本文考察了有關造價領域數據挖掘文章,列舉了數據挖掘關鍵技術,概括總結了數據挖掘的應用方向。最后討論了造價領域數據挖掘技術現存問題和今后的發展方向。未來的研究如果能解決這些問題,突破這些關鍵技術和障礙,將帶來巨大的效益。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
建材發展導向(2019年10期)2019-08-24 06:26:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
中國工程咨詢(2016年12期)2016-01-29 02:21:46
信息通信技術(2015年6期)2015-12-26 01:16:46
電子設計工程(2014年18期)2014-02-27 12:00:13
