神經網絡分類器檢測異常數據的方法*
2022-04-14 09:58:56劉洋張勝茂王斐樊偉鄒國華伯靜
數字技術與應用 2022年3期
劉洋 張勝茂 王斐 樊偉 鄒國華 伯靜
1.中國水產科學研究院東海水產研究所,農業農村部漁業遙感重點實驗室;2.上海海洋大學信息學院;3.上海峻鼎漁業科技有限公司;4.湖南省武漢市武漢紡織大學
神經網絡默認所有輸入數據均屬于正常數據,當輸入異常的數據,網絡會在已知的標簽中找到高度自信的錯誤結果,這種無法檢測異常數據的現象出現在所有學習模型中。使網絡具備檢測異常數據的能力,對于系統安全、算法可靠性和算法的實際應用具有重要的意義。實驗提出一種區分異常數據和正常數據的方法,該方法首先訓練一個名為Wildnet的分類網絡,而后去掉該網絡的Softmax層作為特征提取器,提取正常數據的高層語義信息Embedding,并用該Embedding構建卷積網絡的認知域,通過計算測試數據的Embedding是否屬于該認知域,來判斷該數據是否為異常數據,達到異常檢測的目的。實驗在海鮮市場拍攝的1284張包含13個種類的魚類圖像上進行,用前11種魚類數據作為正常數據,后2種魚類數據作為異常數據。并用正常數據的60%訓練Wildnet網絡,得到測試精度91.10%的分類網絡,然后去掉網絡的Softmax層作為特征提取器,提取訓練數據的Embedding,建立認知域,最后用20%未經訓練的正常數據和異常數據作為測試集,測試其是否屬于網絡認知域,來判斷測試數據區分異常數據的能力,精度達到71.59%。證明通過建立卷積網路的有界認知域,可以區分異常的數據,達到異常檢測的目的。該方法能讓神經網絡算法具備檢測“異常數據”的意識,為傳統神經網絡算法增加了異常檢測功能,進一步提高系統安全性和算法魯棒性。
自Rumelhart等人[1]證明反向傳播算法的可行性以來,神經網絡被廣泛的應用目標識別[2]、分類[3]、檢測[4]、跟蹤[5-6]等領域。通過反向傳播算法學習數據分布特征的方法,使它具有了逼近真實的結果的能力,超越了傳統機器學習方法。在圖形識別領域,神經網絡分類器在訓練數據集上學習決策規則,將卷積模型提取的特征,分配給正確的類標簽[3,7]。該方法的缺陷是將訓練數據的識別域作為網絡的全局識別域,默認所有的輸入數據均屬于網絡的識別域,當算法預測訓練數據分布之外的數據時,由于其不具備識別異常數據的能力,完全有可能得到高度自信卻錯誤的結果。此外訓練數據可能不足以表達實際應用中所有類的完整情況,因此分類網絡的泛化能力可能很差[8]。由于大多數神經網絡算法不具備異常數據檢測的能力,導致實際應用部署中面臨巨大的挑戰。而這些問題都有一個共同的特點,那就是測試數據為學習窗口之外的異常數據,解決這個問題的關鍵在于量化當前神經網絡的自我的認知范圍。
Chow等人[9]將分類問題轉換為決策問題,為每一個類別建立一個模型,用權重函數來度量系統決策結果,通過不斷的優化權重函數來提高異常檢測能力。通過后驗概率建立決策系統,如果后驗概率的最大值小于閾值,則拒絕輸入,并闡述了錯誤識別、拒絕識別和正確識別在決策系統中相關關系。利用Weihull分布計算Softmax層向量的激活分數(OpenMax分數),來判斷圖像是否屬于異常數據,該方法能提高網絡的識別率。Softmax層的設計方式,沒有表達異常檢測的能力,而Softmax層的前一層沒有受到這種約束,并且同一個類別的數據應當屬于同一個集合,對于未知類應當遠離已知數據集合,基于此,他們為網絡的Embedding設計了被稱為ii-loss的損失函數,可以最大程度的減小類內距離,并擴大類間距離。通過減小異常數據在反向傳播過程中的貢獻,來增加網絡檢測異常數據的能力。SVDD(Support Vector Data Description)的級聯分類器,對訓練數據進行建模,任何不屬于該模型的樣本將被標記為異常數據。
由于網絡在有限的訓練集上學習數據的表征能力,數據能夠表征的范圍是網絡認知能力的極限[10]。如果能量化有限數據的信息表征能力,即可表征網絡的認知范圍,對于認知范圍之外的,就為異常數據。在分類神經網絡中,這種數據表征能力的實質是“識別類內相似性和類間差異性”的分類能力。基于此,本文提出一種利用卷積神經網絡的高層語義信息,量化訓練數據(正常)的信息表征能力的方法。該方法首先用交叉熵損失函數訓練了名為Wildnet的簡單分類網絡,然后去掉Wildnet的Softmax層,用Softmax前一層的Embedding表征數據的高層語義信息。而后將訓練數據的Embedding特征集,用主成分分析法PCA(Principal Component Analysis )降維到3維,并計算3維特征點的凸包,以此構建網絡的認知域,通過計算測試數據的特征是否屬于該認知域,來區分正常數據和異常數據。經過測試,該方法在數據不夠充分的情況下能得到了71.59%的正確檢測率。實現了卷積神經網絡對異常數據的檢測,增加了算法的魯棒性,并讓神經網絡具有了異常檢測的能力。
1 數據與方法
1.1 海洋捕撈魚類圖像
利用深度學習的CNN卷積網絡,對海洋捕撈魚類圖像的高層語義特征信息,進行精確提取,需要大量的、高質量的、多樣化的和差異明顯的圖像數據,供給深度學習模型學習不同魚種的紋理信息的區別。但是如何準確有效的采集和組織該類數據集,仍是關鍵的問題。為了收集高質量、多樣化和差異明顯的魚類數據集,該實驗的科研人員在海鮮市場挑選不同種類、大小、形態、姿勢和其他個體差異的海洋捕撈魚類,在純色背景上,用相機從不同角度拍攝捕撈魚類在不同擺放姿態下的照片1284張(如圖1所示),而后魚類鑒別專家將照片準確分成13個魚種,包括斑尾刺蝦虎魚、舌鰨某種、銀鯧、帶魚、棘頭梅童魚、三疣梭子蟹、對蝦、小黃魚、馬鮫、龍頭魚、鮸、馬面鲀、鮋(表1)。拍攝的圖像大小為4000×2248像素。

圖1 魚類照片,從正面、側面、以及改變魚的擺放姿勢拍攝照片Fig.1 Fish photos, taking photos from the front, side and changing the placement position of fish
在數據處理方面,考慮到深度學習中一張w×h像素的圖像,通過一個r×c神經元的乘法計算量為w×h×r×c,為避免因圖像尺寸導致乘法計算量太大引起學習過程中占用顯存過多,從而導致網絡計算緩慢的問題,本文使用OpenCV的區域插值法將圖像縮小到224×224像素,大大降低了網絡的計算量。另外為使網絡具有更好的魯棒性,提高網絡的泛化能力,降低過擬合,對原圖像進行偏移、旋轉、縮放、裁剪增廣數據集,并將圖像進行歸一化和白熱化處理。根據圖像所屬的魚種為每一張圖像制作標簽文檔。為了模擬正常和異常的場景,實驗將前11種魚類數據共1036張圖像作為正常魚種,后2種魚共計218張圖像作為異常魚種。本文將正常的魚種圖像數據充分打亂之后,按照6∶2∶2劃分為訓練集、驗證集和測試集;將異常魚種數據集作為異常魚種的測試集合。為方便闡述,設正常訓練集為Dtrain,正常的驗證集為Dvalid,正常的測試集為Dtest,異常的測試集為Dwild。其中Dtrain={Dt}11t=1,包含11種魚類,Dt表示第t種魚類數據集。Dtrain用于訓練Wildne網絡的分類能力,Dvalid用于驗證Wildne網絡的分類能力,Dtest和Dwild用于驗證本文提出的方法的可行性。
1.2 正常與異常數據
神經網絡表征數據的能力,來源于對訓練數據Dtrain(正常數據)的學習,所以網絡對正常數據表征的信息分布是部分可知的;而異常數據Dwild表征的信息,網絡是不可知的;即正常數據在網路的認知域之內,而異常的數據在認知域之外。網絡對數據的認知域來源于數據本身表征的信息域,設正常數據和異常數據表征的全局信息域為G,正常數據表征(前11種魚圖)的信息域為R,異常數據表征(后2種魚圖)的信息域為O。理論上除了正常的數據,都是異常的數據,所以R∪O=G,R與O互斥。區分O和R的問題,只需在G中找到描述二者信息的邊界,表達其中一個即可表達另一個。由于O是開域的(未知域),缺乏數據支撐,無法直接表征,而R在本實驗中可通過訓練集(正常)的圖像數據間接表征。
由于卷積網絡通過提取數據的特征信息來識別數據,理論上用圖像的特征信息表征數據的信息域是合理的。假設卷積網絡識別第t類對象的信息域為Et,Et∈R;第t類數據的第j張圖像xj,通過映射關系(神經網絡)F(·)提取的特征信息ej∈Et。設某種魚有N張圖像,其通過F(·)映射后的信息域集合為At={ej|ej=F(xj)}N,當N趨近于無窮的時候,At表達的信息域趨近于Et,其中At?Et。即,提取同類圖像數據的特征信息表征類信息域Et,不同類的信息域組合R,從而構成網絡的認知域。所以,圖像xj可以準確有效的“映射”到其特征ej的情況下,更多樣的圖像可以更加完備的表達Et,而F(·)的準確性和可行性,是盡可能的將同類圖像的特征聚集在一起,而不同類的特征互相遠離,其取決于“描述種內相似性和種間差異性”的分類能力,這和深度學習分類網絡能力相似,實質就是描述類內相似性和類間差異性。基于此,本文利用卷積網絡訓練具備分類能力的特征提取器Wildnet,描述圖像xj與特征ej的映射關系F(·)。
1.3 特征提取器
Wildnet網絡結構如圖2所示。為了保證F(·)描述“種內相似性和種間差異性”的準確性和可行性,實驗用包含11個魚種的數據集Dtrain訓練網絡的分類能力,由于其數據量較少,不必使用較大參數量的網絡結構,實驗利用深度可分離卷積(Depthwise)搭建了一個較小的卷積網絡,在該網絡中,為了能靈活的壓縮和擴張通道,用Pointwise卷積融合Depthwise卷積后的張量信息;為了加速訓練與防止過擬合,在卷積之后使用Batch Normalization(簡稱:BN)模塊;為了防止特征消失,使用了特征融合和殘差的方法。在訓練過程中,用包含11種魚種的數據集Dvalid驗證其分類準確度,以防止過擬合和欠擬合。

圖2 Wildnet特征提取網絡Fig.2 Wildnet feature extraction network
為了計算真實數據分布和生成特征數據分布的相似度,用多分類交叉熵函數計算損失(式1),在反向傳播的過程中,用SGD (Stochastic Gradient Descent)更新權重。

公式(1)中,C為類別總數,i表示類別數,xi表示輸入圖像,yi表示圖像的真實標簽,;表示Wildnet網絡的權重,L為損失率。在成功訓練之后,先用測試集Dtest測試網絡識別能力,確定其已經具備“識別類內相似性和類間差異性”的分類能力后,再將網絡去掉Softmax輸出層,留下Embedding層作為輸出層,改造成特征提取器,作為圖像到特征的映射關系F(·)。去掉Softmax的原因是Softmax激活層輸出11維張量,其維度偏少且數值分布不均勻,不能很好的表達圖像的高層語義信息,不適合作為特征提取器的輸出。而經過Embedding層輸出128維的張量,是經過Batch Normalization歸一化處理的,其分布較為均勻,且維度足夠表達圖像的高層語義信息,對于輸入圖像xj能夠得到一個表達更全面的特征ej。因此在特征提取過程中,去掉該網絡層Softmax層,留下Embedding層,作為特征提取器。由于該特征提取器已經具備了“描述種內相似性和種間差異性”的能力,其輸出的特征能夠很好的表征真實數據分布,因此本文將該特征提取器作為圖像xj和特征ej的映射關系F(·)。
Convolution(k,k,s,c):表示c個卷積核大小為k,步長為s的CNN卷積。
Pointwise (1,1,s,c):表示c個卷積核大小為1,步長為s的CNN卷積。
Depthwise(3,3,2,c):表示c個卷積核大小為3,步長為2的通道可分離卷積。
Route:表示兩個張量在通道上拼接。
BN(Batch Normalization):表示對輸出特征歸一化,使其符合均值為0,方差為1的分布,防止ICR現象。
Mish:平滑的激活函數,能讓模型擬合更細膩。
Embadding:128∶128的特征張量層。對于輸入圖像xj,該層輸出128維的特征張量,即圖像經過映射關系F(·)輸出的ej。
Softmax:分類層有11個神經元,表示11個已知魚種。
1.4 已識別信息域
在成功制作特征提取器Wildnet之后,為了近似的量化正常數據的信息域R,達到在全局信息域G中描述“正常和異常的邊界”的目的,如圖3所示,實驗將Dtrain,Dtest和Dwild數據集輸入到Wildnet特征提取器中,分別生成正常特征集Etrain,Etest和異常特征集Ewild。由于Dtest和Dtrain擁有同樣的魚種,屬于同種數據分布;Dwild數據集與Dtrain數據集擁有不同的魚種,表征不同的數據信息,其數據分布不同。由于使用交叉熵作為損失函數訓練網絡,最小化了真實分布和預測分布的差異,即輸入數據(真實分布)和特征數據(預測分布)是相似的分布。所以,同一分布的數據與經過映射關系F(·)生成的特征數據,其分布相似,反之亦然。即Dtrain,Dtest和Etrain,Etest分布相似,Etrain和Ewild屬于不同分布,加之Wildnet的認知域來源于Dtrain表征的數據信息(正常的信息域R),即Etrain可近似表征Wildnet的認知域。而Dwild數據集與Dtrain屬于不同的分布,故Ewild表征的數據信息屬于異常的信息域O。因此實驗將Etrain,Etest,Ewild用PCA方法降維,將128維特征向量的維度降到3維,而后將Etrain的特征集構成的空間作為Wildnet網絡的認知域,其外為異常信息域O。
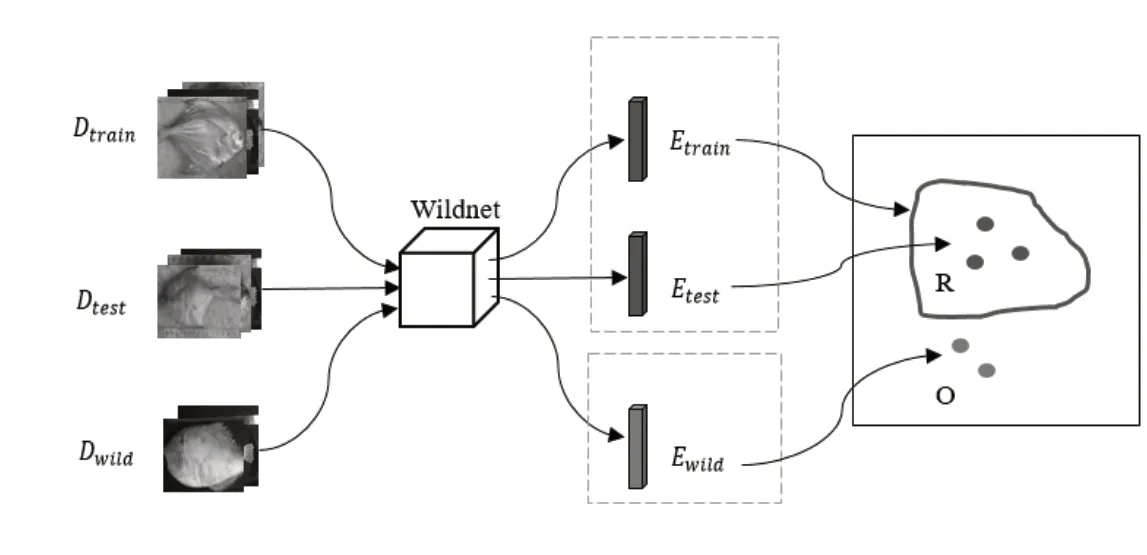
圖3 特征提取流程圖Fig.3 Flow chart of feature extraction
如算法2所示,判斷測試數據是否為異常數據,只需判斷其特征是否在R中。在該實驗中,用凸面體體積法判斷Etest和Ewild的3維特征點是否屬于Etrain構成的凸面體,來判斷是否屬于認知域內。為了獲得由Etrain中不同類別魚種數據表征的信息域,首先用Graham掃描法計算Etrain中3維特征點的凸包Tt,根據凸包計算鄰點集合{P1,P2,P3}N,其中P1, P2, P3表示三角形的頂點集,N為凸包頂點數量。然后根據鄰點集依次計算三角形的面積,以及測試點到所有三角形的高,并用三角形的面積和測試點到該面的距離計算四面體的體積,最后求和所有四面體的體積,得到測試點與凸包構成的多面體的體積。如果其值等于原凸包構成的凸面體體積,則在認知域內,否則在認知域外。實驗在Dtest與Dwild數據集上測試,其異常檢測的正確率為71.59%。
2 結果與分析
實驗在32G內存,16G顯存(TeslaV100)的Linux主機上進行,開發框架為Pytorch。為了讓神經網絡對不確定的數據具有認知能力,本文做了兩個實驗,第一個實驗是訓練Wildnet網絡,使其具有識別“種間差異性和種內相似性”的能力。第二個實驗利用Wildnet網絡生成的高層語義信息,描述正常數據的信息域,并通過該信息域來判斷測試數據是否屬于正常范圍。
2.1 Wildnet分類網絡
實驗用Dtrain數據集訓練網絡具備分類能力,設置SGD優化器的初始學習率η;η為0.001,momentumα為0.9,decay為1e-9;用Softmax激活函數激活最后一層的神經元,并配合交叉熵損失函數(公式1)計算網絡損失。為了防止訓練過程中的過擬合和欠擬合現象,實驗用Dvalid數據集每迭代10次計算網絡的驗證損失,如果降低則保存權重,可有效的防止過擬合。訓練在經過90次迭代后,訓練精度為97.10%,驗證精度為92.29%(如圖4所示)。
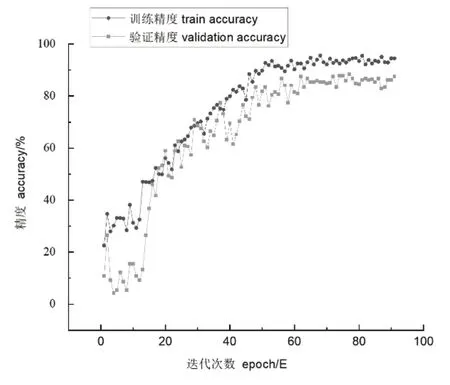
圖4 Wildnet訓練過程圖Fig.4 Wildnet training process
在網絡訓練成功之后,用測試集Dtest測試網絡的分類能力,其測試精度為91.10%。說明該網絡已經具備“識別種間差異性和種內相似性”的能力,可以表征11種數據的大部分信息特征,將輸入數據和輸出數據分布的差異最小化,這是量化正常信息域的基礎。
2.2 正常信息域
由于Softmax層中的神經元被限定為只能表示已知類別,無法表示未知類別,其張量信息難以表征未知類別的高層語義信息。而Embedding層位于Softmax的前一層,沒有受到該限制,并且相比于Softmax層的11維張量,Embedding層有128維的張量,能夠更加全面的表征數據的高層語義信息。據此,實驗將Wildnet網絡去掉Softmax層,用Embedding層作為網絡的輸出層,將修改后的網絡作為特征提取器。實驗將訓練集Dtrain的圖像輸入到特征提取器,生成128維的特征向量集合Etrain={At}11t=1,其中At表示第t種魚的特征集合;將Dtest和Dwild數據集分別輸入到Wildnet網絡,生成Etest和Ewild。其中Etrain中包含640個128維的具有類別標簽的特征向量;Etest包含213個128維的具有類別標簽的特征向量;Ewild中包含218個128維的具有類別標簽的特征向量,其中馬面鲀的數量為104,龍頭魚的數量為114。
將Etrain,Etest和Ewild的128維高層語義信息,用主成分析法PCA降維到3維,并將其3個維度上的數值作為3維坐標系的x, y, z上的坐標值。通過Etrain和Etest在3維坐標系中的分布分析,Etrain和Etest特征點在空間中呈現彼此交融的分布狀態,這證明了本文的觀點,即網絡成功學習了Dtrain數據集的分布特征,而Dtest數據集與Dtrain擁有一樣的魚種,表征同樣的數據特征信息,故Etrain和Etest屬于同一分布。由于Wildnet網絡表征數據的信息有一定的誤差,并且少部分數據質量較差,導致少部分的特征點游離于聚集區域以外。
由于Dtrain中沒有Dwild包含的新魚種數據,如果不經過處理直接交給Wildnet分類網絡分類,肯定會在訓練集的標簽上找到高度自信卻錯誤的結果。Dwild數據集通過Wildnet特征提取器生成Ewild特征集,包含異常魚類馬面鲀和龍頭魚的高層語義信息。將Ewild加入3維空間中,馬面鲀和龍頭魚的大多數特征點分布于Etrain和Etest的兩邊,證實了本文推論,即不同分布的數據,其特征信息屬于不同分布。并且同一魚種的特征點聚集在一起,這種現象一定程度上說明分類網絡,對同類數據表征的信息具有聚集作用,對不同種類的數據表征的信息具有遠離作用,這證實了本文的觀點,即分類的實質就是“識別種間差異性和種內相似性”,而數據量如果足夠大。聚集在一起的特征,可以逼近表征該類數據的完整信息域(Et),從而表達正常信息域R,達到檢測異常數據的目的。
為了表達正常信息域R和異常信息域O的邊界,實驗用Gramham-Scan算法計算Etrain中不同魚種數據的特征集At的凸包,得到11個不同類別數據特征的3維凸包,用每一個類別的凸包構成的凸多面體作為該類魚的信息域,所有凸面體空間作為Wildnet的認知域。實驗用體積法計算測試樣本是否屬于這11個凸面體,首先分別計算11個凸面體的體積,如果測試特征點屬于某一凸面體,則測試特征點與凸包組成的新凸面體體積等于原凸面體的體積。如果測試特征點不屬于任何一個凸面體,則該測試數據為異常數據。從未被訓練的馬面鲀和龍頭魚大多分布在認知域外,而正常的魚種,大多分布在認知域內。如算法2所示,實驗在Dtest與Dwild數據集上測試,檢測正確率為71.59%,證明了該方法的可行性。
根據實驗結果,可以得出如下結論:(1)卷積神經網絡對同一種類的數據特征信息具有聚類作用。(2)用訓練數據表征的數據信息域,可檢測異常數據。(3)具有分類能力的卷積神經網絡,其認知范圍可近似表征。
3 結論
為了讓卷積神經網絡具備檢測異常數據的能力,本文研究了卷積神經網絡對正常數據的表征能力。實驗用卷積網絡提取圖像的高層語義信息,構建正常數據的信息域,通過計算測試數據的高層語義信息是否屬于該空間,來判斷測試數據是否為異常數據,取得了71.59%的檢測正確率。結果表明該方法可量化卷積神經網絡的對數據的表征能力,讓神經網絡算法具備識別“異常數據”的能力,可達到檢測異常數據的目的,進一步提高系統安全性和算法魯棒性。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
軸承(2010年2期)2010-07-28 02:26:12
