Python數據結構在社保大數據領域的應用
2022-04-14 09:58:58鄂爾多斯市人力資源和社會保障局綜合保障中心達斯孟
數字技術與應用 2022年3期
鄂爾多斯市人力資源和社會保障局綜合保障中心 達斯孟
當前大數據應用在政務服務各個領域正在如火如荼的進行,Python語言作為一種高效的編程語言正在成為軟件開發的趨勢,本文從Python語言不同數據結構在社保大數據應用方面進行了構造方法的介紹、性能的比較和造成性能差異的分析。
社保領域作為我國重要的民生工程,一直備受關注。社保大數據在推動社會保險管理服務模式創新,改進公共服務水平,減少重復參保,查處重復領取待遇方面有著非常重要和廣泛的應用。Python語言可以被應用于系統編程、GUI編程、互聯網腳本、數據編程等多個領域。根據2018年5月KDnuggets對“最受歡迎的分析、數據科學、機器學習工具”的調查,Python以65.2%的比例奪冠。本文以A市社保大數據比對工作中應用Python語言編寫相關應用程序時所應用的集合SET、列表LIST等兩個高頻數據結構進行性能和特點分析,以便為更多政務服務領域提供可供遵循的指導。
1 Python數據結構中的集合SET,列表LIST介紹
要用好Python語言并發揮其作用,必須理解數據結構的一般性知識和Python的特殊情況[1],筆者在社保大數據應用領域使用的是Python數據結構中的集合SET,列表LIST。要弄清楚上述兩個數據結構首先要從上述數據結構的構造原理進行探究。首先我們要明確任何數據結構其實都是一種從內存獲取數據地址從而讀取或者操作數據的一種方式。就像生活中我們想要出售一處房產,但是你不可能像推銷其他產品一樣將房產攜帶在身上四處給人看,最好的做法就是你告訴潛在客戶一個地址讓客戶根據你給的地址自己過來訪問。這個過程其實就是我們計算機用來讀取內存中數據的一種形象的方式。在Python中我們建立一個列表MYLIST=LIST[1,2,3,4]的列表,其中的MYLIST本質上就是指針,指向LIST[1,2,3,4]占據的內存地址塊。不同的數據結構其本質的區別就在于如何讓指針更快,更準確的指向需要訪問的地址。
1.1 LIST數據結構
Python中的LIST是處理一組有序元素得數據結構[2]。本質上是一個over-allocate的數組實現的。LIST可能是計算機科學中使用最為頻繁的數據結構。Python中的LIST共有三類,分別為單鏈序列Singly Linked LIST,雙鏈序列Doubly Linked LIST,環形序列Circular Linked LIST。下面對三類序列進行分析:
如圖1所示為單鏈序列Singly Linked LIST:除了末尾節點外每個節點都包含一個數據值部分和指向下一節點的地址部分。單鏈序列只能進行單向的索引,因為每個節點只包含下一節點的位置。
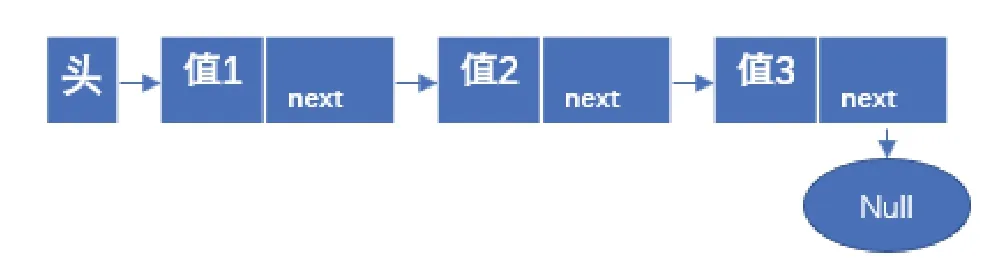
圖1 單鏈序列Fig.1 Singly Linked LIST
如圖2所示為雙鏈序列Doubly Linked LIST:除了末尾節點外每個節點都包含一個數據值部分和指向下一節點的地址部分和指向上一節點的地址部分。雙鏈序列可以進行向前和向后的雙向查找,因為每個節點即包含了前一節點的地址又包含了后一節點的地址。

圖2 雙鏈序列Fig.2 Doubly Linked LIST
如圖3所示為環形序列Circular Linked LIST:環形序列的末尾節點的下一節點指向的是序列的第一個節點,其他都和單項序列是一樣的。

圖3 環形序列Fig.3 Circular Linked LIST
三種序列對存放于其中的數據都進行了精確的索引,數據值可以重復。其特點為高擴展,可任意大小位置切片,任意位置刪除或插入。
1.2 SET數據結構
Python中的SET數據結構是由具有唯一性的hashable對象所組成的無序集合。由于SET數據結構索引數據的方式為hash算法,因此相同值的數據經過hash算法后其哈希值也是相等的,所以SET中不會有重復的數據。常見的用途包括成員檢測、從序列中去除重復項以及數學中的集合類計算,例如交集、并集、差集與對稱差集等[3]。
2 集合SET,列表LIST性能比對
在A市社保大數據應用領域,目前需求最密集的數據應用方式為跨統籌區或跨險種(企業養老保險、機關養老保險、城鄉居民養老保險)比對重復參保與重復待遇領取人員。由于政務服務特點,上述數據大多以Excel格式存放于社保部門不同科室且每個表格的數據較多(通常為幾十萬條)。因此如何高效、精準、快速進行數據比對就顯得尤為重要。
下面筆者以10000機關養老待遇領取人員和10000城鄉居民待遇領取人員比對為例展示Python中不同數據結構在上述需求中的性能差異(如表1所示)。LIST數據結構主要的算法為將兩個數據源的10000人的數據分別裝入兩個LIST中。之后經過FOR循環進行遍歷比對。
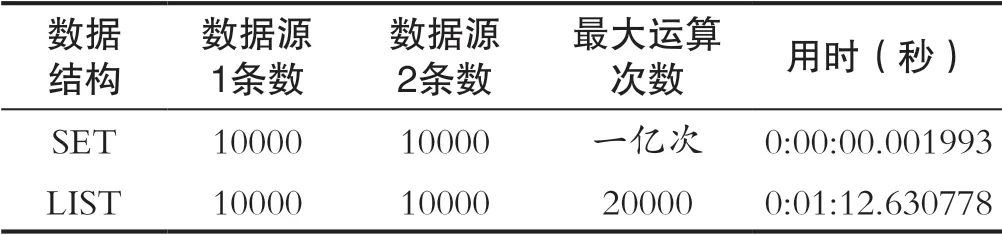
表1 為數據比對結果Tab.1 Shows the results of data comparison


SET數據結構主要的算法為將兩個數據源的10000人的數據分別裝入兩個SET中,通過intersection函數求解交集。

3 集合SET,列表LIST性能差異分析
經過上述實驗結果可以看出SET數據結構在社保大數據比對中效率明顯更優。其原因主要在于SET數據結構和LIST數據結構的構造方法的不同。眾所周知,最快速的訪問數據集合中數據的方式是隨機訪問,而不是順序訪問。下面我們就對兩種數據結構分別進行分析。從上述實驗結果得知LIST的查找效率較低,下面我們首先查看LIST的查找算法的抽象源碼和原理圖(如圖4所示)。


圖4 LIST數據存儲方式Fig.4 LIST data storage method
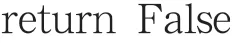
從圖四中可以看出我們現在有一個test=LIST[10,11,12,8,9,13,14]的未排序序列,序列中共有7個整數值。根據源代碼如果我們要查找13這個Key值,則需要從這個序列的head位置起循環比對(源碼中的WHILE循環)如果比對不成功則進行temp=temp.next操作進入下一節點進行比對直到比對成功為止則返回True跳出循環。因此得出LIST(以雙向鏈表為例)查找數據時需要按照索引順序對整個序列進行遍歷直至匹配到Key值。它適用于對順序敏感的數據。平均查找復雜度是O(n)(如果是以排序的序列則平均查找復雜度是O(log n))。
從上述分析得知要從一個LIST中查找某一Key值必須要對整個LIST進行遍歷,如果想要查找的Key值在序列的前端則還比較省時間,如果所要查找的Key值在序列的末尾則需要遍歷完整個序列才可以匹配到Key值。這樣無疑是非常耗費系統資源和時間的。因此我們不禁要問,為什么不能有一種數據結構可以直接告訴我所要查找的Key值的位置,從而讓我可以直接去訪問呢,就像我們之前提到的例子所說的那樣,直接告客戶一個詳細的地址,而不是像LIST一樣只告訴客戶需要出售的房產在某一個小區(內存塊),讓客戶逐戶去查找是否為要出售的房屋。而SET數據結構恰好就是利用哈希算法實現了一次尋址即得到結果的結構。下面我們首先查看set的查找算法的抽象源碼和原理圖(如圖5所示)。

從圖5中可以看出我們現在有一個test=set(對象1,對象2,對象3,對象4,對象5,對象6,對象7)的集合,其中共有7個對象值。根據源代碼如果我們要查找對象6這個Key值,首先我們需要通過ComputeHash(Key)函數計算對象6的哈希值(13),之后通過哈希算法對13這個哈希值進行除7取余的哈希計算得到哈希表中的索引位置(6),之后判斷索引位置的值是否與要查找的KEY值相等,如果相等則返回成功(在哈希算法出現沖突的情況下有可能出現索引值相同但是數據不相同的情況)。最終得到需要查找的值。因此SET數據結構的查找復雜度是O(1)(理想無沖突狀態下),且和SET規模大小無關。在SET中查找任何值在理想情況下只需要查找一次,只需要將需要查找的值進行哈希算法,將其哈希值與SET中相應位置進行比對,如果比對成功,則找到,如果比對失敗,則不存在。

圖5 SET哈希算法實現方式Fig.5 Implementation of SET hash algorithm
4 結語
根據上述實驗數據和結構原理,我們可以得出Python在社保大數據應用領域中SET具有查找比對速度的絕對優勢,其優勢來源于其數據結構的構成方法,而LIST則在數據比對查找方面不具有速度優勢,但是在需要按照某種規則進行排序使用數據時具有優勢。
