基于深度強化學習算法的高能效數據負載均衡方法
2022-04-15 01:59:58張思松
安陽工學院學報 2022年2期
張思松
(銅陵學院 數學與計算機學院,安徽 銅陵 244061)
在過去的一段時間中,主流的網絡處理器多為單核處理器。隨著網絡結構的不斷發展,傳統的處理器已經無法適應復雜的網絡環境。為了提升網絡系統的性能,本研究對系統服務器展開了優化。系統性能的迅猛提升,擴大了并行程序在網絡中的應用范圍。無論并行程序提供什么類型的服務,都需要物理機與虛擬機進行綜合部署,以此實現網絡數據的傳輸與分發。資源調度是提升網絡利用率、降低能耗、降低服務成本的重要技術,其目標為提升性能、降低能耗、降低成本[1-3]。
負載均衡可有效避免某些網絡資源利用率過低所引發的性能低下問題。以往的研究中設計出多種以不同技術為核心的負載均衡方法,但均存在網絡節點吞吐量較小或不穩定的問題。以文獻[4]為例,該文提出了一種采用流水線模型分解工作負載從而實現數據負載均衡的方法,此方法提升了數據負載均衡計算速度,但無法避免網絡節點吞吐量不均衡的問題,長時間使用此種類型的方法會出現網絡運行不穩定的次生問題。鑒此,本文以深度強化學習算法為核心技術設計新型高能效數據負載均衡方法。
1 高能效數據負載均衡方法設計
1.1 網絡數據并行程序設計
數據并行處理是數據負載均衡處理的基礎。在進行數據負載處理時,有必要首先設計并行程序,同時選擇合適的性能指標分析與調節并行程序的性能。在借鑒有關文獻[5-6]基礎上,本文選擇隱式并行程序設計方法,使用傳統串行語言編寫并行程序,而后利用程序變化技術實現串行代碼與并行代碼之間的轉換。根據網絡數據的使用要求,本文將并行程序組成內容設定為任務劃分、通信分析、任務整合和服務器映射處理等4個部分。使用C語言完成子程序設計后,將其組合為一個具有整體性的程序組合,將其作為本研究的并行程序。
為保證此并行程序具有研究價值,采用加速比性能定律以及等效比度量[7-8]對并行程序的使用性能進行驗證。具體計算過程如下:

其中,A(x)表示并行程序加速比;Tu表示單一處理器運行時間;Tx表示整個網絡結構處理器運行時間。使用此公式可對并行程度的加速比展開計算。處理器的計算效率也是對并行程序進行分析的重要指標之一,其計算公式可表示為

其中,Q(x)表示處理器利用率,當0≤Q(x)≤1時,Q(x)取值越高,并行程序的計算速率越快;反之,并行程序的計算速率越慢。
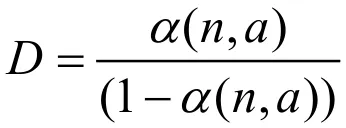
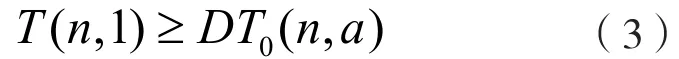
使用公式(3)計算結果繪制成如圖1的等效率曲線形式,分析此曲線對并行程序的可擴展性。
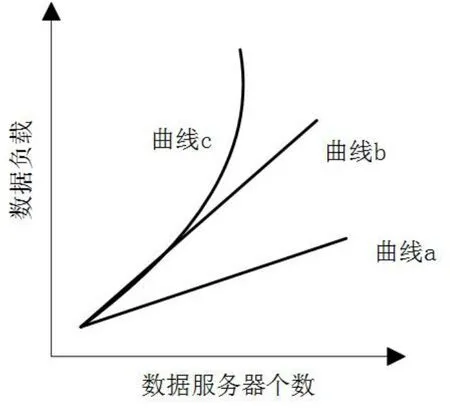
圖1 等效率曲線示意圖
圖1曲線a到曲線c分別表示并行程序的擴展性程度。當取值結果繪制曲線為曲線a形式時,并行程序具有良好的擴展性;取值結果繪制曲線為曲線b形式時,并行程序具有可擴展性;取值結果繪制曲線為曲線c形式時,并行程序不具有擴展性。根據上述設定內容對并行程序設計結果進行檢測,如并行程序符合檢測指標要求,將此程序作為后續處理的基礎。
1.2 存儲節點數據分配
為保證數據在存儲節點時各數據在服務器中能夠均衡用戶的請求,需對存儲節點的數據遷移與分配方式進行設定。
根據各存儲節點數據量計算網絡結構整體的數據量,計算過程如下:

其中,Wi表示網絡結構的數據總負載量;Wall表示網絡系統數據總容量。根據公式(4)可得到存儲節點的數據負載量:
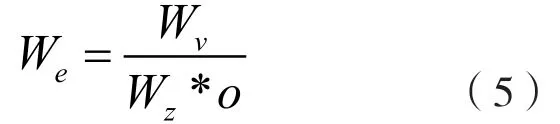
其中,Wv表示存儲節點的數據負載量;Wz表示各個存儲節點的可使用數據資源[9];o表示數據異構權值。式(4)、式(5)中W與We用于衡量網絡系統的節點負載分配情況;W根據帶寬以及網絡利用率等因素進行綜合設定。根據此設定,將式(4)、式(5)的約束條件設定如下:
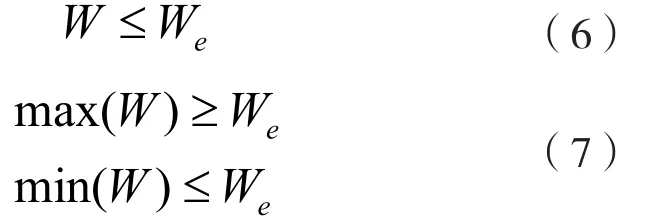
當計算過程滿足上述約束條件時,遷移存儲節點的數據負載。當We≥Wall時,說明網絡結構負載加重,需要增加存儲節點數量。在存儲節點的數據處理過程中,需要處理目標服務器、源服務器以及需處理數據[10-11],具體處理過程設定如下:
設定目標服務器為Q,源服務器為K,需處理數據為L。當約束條件為公式(7)時,需要降低Q的數據處理次數。為實現此目標,K設定為負載最輕的服務器,最大化限額提升數據負載的處理效率,同時保證We≤Wall,V表示K與Q的比值。根據此需求,可得到遷移數據量計算公式:
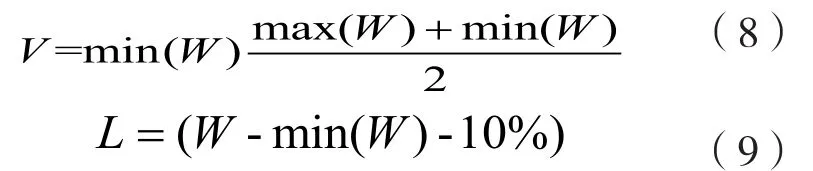
根據式(9)計算結果,選擇可重新分布的數據,并以存儲節點為單位完成數據遷移,選擇的目標服務器不能為Q。將此數據分配原理作為后續數據負載均衡算法的設計基礎。
1.3 數據負載深度強化學習均衡算法設計
上文已經構建了網絡數據模型,并設定了存儲節點的數據負載遷移條件,根據設定選擇深度強化學習算法,設計數據負載均衡算法。
針對當前數據負載均衡方法使用中存在的不足,本研究將對網絡中的網關資源消耗進行處理,設定網絡節點中包含多個處理器和內存資源。為此,設定網絡中含有n個數據出口,其帶寬為Si={S0,S1,...,Sn-i},Si表示網絡中的第i個出口的帶寬。設定Sc為0,1,...,niSSS-的最小公約數[12-13],使用參數Hi描述數據出口i負載能力,則有

根據此公式,設定Hg為網絡系統的數據處理能力,則有
根據深度強化學習算法中的貝葉斯計算原理[14-15],選擇最佳網絡數據出口,以此實現數據負載均衡處理。將網絡數據出口設定為Oi={O0,O1,...,On-i},每個數據出口的權值用f(Oi)表示,函數X(Oi)表示數據出口為i時的連接數。數據出口的連接數可表示為
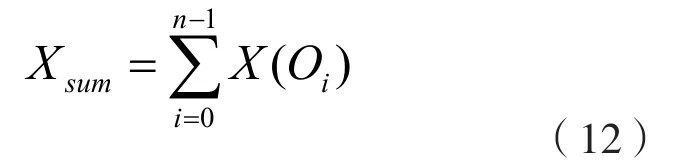
由公式(12)可得到數據出口的新連接數,用J(Oi)表示,則有:
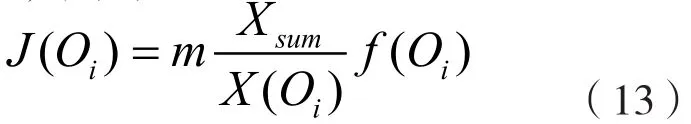
其中,m表示計算中固定比例系數。J(Oi)中取值最高的結果為最優數據負載傳輸出口。在公式(13)的計算過程中,可將其優化為:
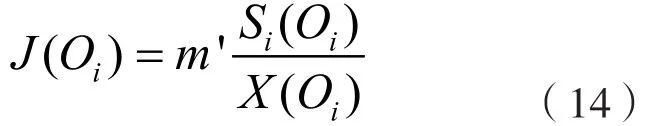
使用公式(14)選擇數據負載傳輸出口,同時根據公式(4)~公式(9)完成數據負載的轉移與處理,實現數據負載均衡設計目標。至此,基于深度強化學習算法的高能效數據負載均衡方法設計完成。
2 仿真測試分析
本研究使用深度強化學習算法設計了一種新型的數據負載均衡方法,為探究此方法是否具有現實應用意義,特構建仿真測試環節對其使用效果展開分析。
2.1 測試平臺搭建
本文以Matlab網絡仿真平臺為測試平臺,測試網絡構建過程設定如圖2所示。
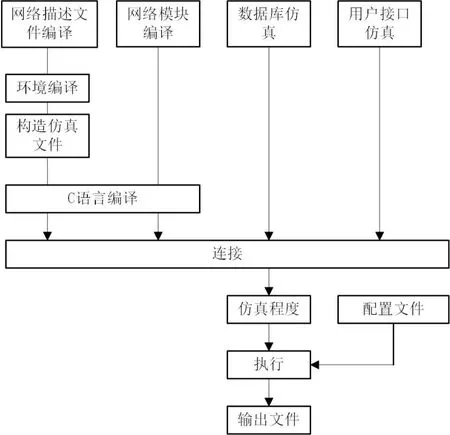
圖2 Matlab網絡仿真過程示意圖
根據圖2描述的仿真過程,使用編譯器以及消息編譯器將選定的網絡結構編譯成C++語言。然后,將網絡中各層級的模塊使用代碼的形式編譯,并將其連接為可執行文件,將此部分文件作為獨立的仿真程序運行。
2.2 設定測試方案
本次測試中,為充分分析深度強化學習負載均衡方法的使用效果,選擇文獻[6]多信道協作負載均衡、文獻[7]國產化服務器集群與本文提出的深度強化學習負載均衡方法進行對比,確定不同負載均衡方法的使用性能。
本次測試中將數據劃分為5個等級,分別對應優秀、良好、一般、差、極差。將表1數據信息輸入網絡仿真測試平臺中作為測試的數據基礎,根據處理效果確定不同均衡方法的使用效果。
2.3 測試環境設定
為增強測試的真實性,對仿真測試中的網絡拓撲結構進行設定。本次仿真網絡中包含512臺服務器和220臺交換機(64臺core-switch、100臺edge-switch、56臺aggregation-switch)。此外,網絡拓撲中包含20臺網絡節點控制器,每個網絡節點控制器包中分別設定有相同臺數的coreswitch、edge-switch與aggregation-switch。每個服務器中設定16個數據交換端口。根據此設定繪制仿真網絡,并將其結構信息輸入Matlab網絡仿真平臺,構建相應的虛擬測試環境。為保證本次測試結果的代表性,設定了兩種網絡運行模式:模式a為網絡服務器全部運行狀態,模式b為網絡服務器部分運行狀態。
2.4 測試指標選取
本次測試將測試對比指標設定為數據負載均衡后的網絡節點吞吐量。本研究指標體現為多個服務器在仿真過程中的數據吞吐量。假設網絡中服務器為n個,仿真次數為δ次,則吞吐量計算公式可表示為
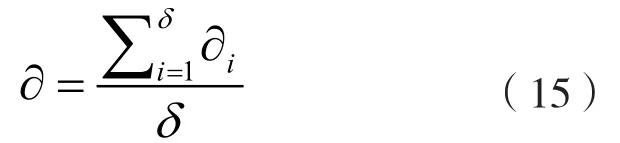
其中,?表示多次處理后的吞吐量,?i的計算公式可表示為

其中,T表示服務器數據吞吐量。根據公式(16)計算網絡的數據吞吐量,將此作為評價數據負載均衡方法使用效果的一組指標。數據吞吐量取值結果越大,說明數據負載均衡方法的使用效果越好,進而說明此方法具有高能效。
2.5 測試結果分析
圖3分別為網絡服務器全部運行狀態下和部分運行狀態下的網絡節點平均吞吐量。如圖3所示,在不同網絡服務器運行環境下,文獻[6]、文獻[7]和本文所構建的深度強化學習算法等3種方法具有不同的節點平均吞吐量。在網絡服務器全部運行狀態,深度強化學習負載均衡方法使用后,提升了網絡節點的數據吞吐量。其他兩種方法使用后,網絡節點的平均吞吐量并未提升,僅保持了應有的節點吞吐量,對網絡數據的均衡處理沒有太大的幫助。在網絡服務器部分運行狀態情況下,上述3種方法的使用差異較大。深度強化學習負載均衡方法在兩種測試環境中并未出現較大的變化,具有較為穩定的應用效果。其他兩種方法中數據吞吐量差異較大,影響了網絡的穩定運行。綜合上述測試結果可知,無論是測試環境(a)還是測試環境(b),深度強化學習負載均衡方法的使用效果均優于其他負載均衡方法。
3 結束語
無線網絡的發展為數據處理提供了幫助,也為網絡數據管理帶來挑戰,網絡中的物理服務器與虛擬機需要一個高效的數據調度方法。本研究提出了一種基于深度強化學習算法的高能效數據負載均衡方法,提高了數據處理性能。在后續研究中還需對網絡的數據管理技術進行深入分析。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
兒童故事畫報(2019年5期)2019-05-26 14:26:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
新聞傳播(2015年10期)2015-07-18 11:05:40
