數據中心網絡路由研究進展*
2022-04-21 05:06:54王寶生
計算機工程與科學 2022年4期
關鍵詞:方法
段 晨,彭 偉,王寶生
(國防科技大學計算機學院,湖南 長沙 410073)
1 引言
路由是數據中心網絡的關鍵技術之一,負責在數據中心內部以及跨數據中心為流量選路。數據中心由服務器和交換機2種設備組成,服務器主要運行各種云計算應用,交換機實現組網通信。數據中心網絡通常使用傳統TCP/IP協議棧進行通信,也有研究提出了一些不采用TCP/IP的專用協議,以更好地利用數據中心網絡的拓撲結構和流量特點。
傳統因特網中的路由主要考慮網絡可達性,提供盡力而為的服務。而運行在數據中心的應用服務普遍具有更嚴格的低時延和高可靠性要求,因此數據中心網絡路由需要為數據流提供更精確的選路策略。
數據中心網絡路由研究中常常需要考慮以下4個方面的問題:(1)路由方法的可擴展性:能否適應數據中心網絡規模的不斷增長;(2)路由方法的部署成本:能否直接部署在現有的商用交換機上;(3)能否為不同服務質量要求的流量提供差異化的路由轉發服務,以及能否實現自適應負載均衡;(4)路由方法的容錯能力:能否從網絡故障中快速恢復。當前,數據中心網絡路由的研究大都集中在流量感知、多路徑計算和負載均衡的流量分發等方面,目標是提高網絡整體吞吐率或帶寬利用率,縮短數據流的傳輸完成時間等。
在數據中心網絡路由相關的綜述中,Habib等[1]對數據中心網絡路由技術進行了分類,但分類粒度較大,對已有研究工作的分析對比不夠清晰,缺少對近年來最新研究成果的分析;Quttoum等[2]對數據中心互聯拓撲結構、路由與流量工程進行了介紹,其中路由與流量工程部分側重闡述了面臨的問題和協議設計原則,但缺少對路由已有研究成果的詳細梳理和分析。
本文對數據中心網絡路由技術的當前研究進展進行綜述。首先對路由問題和路由方法進行分類,然后重點闡述數據中心網絡單播路由技術的研究進展。接著進一步闡述了擁塞感知的單播路由方法的研究成果,從多個維度進行分析對比,為數據中心網絡擁塞控制與負載均衡問題提供了研究思路和方向。本文還關注了基于光交換的數據中心網絡和有線無線混合的新型數據中心網絡中的路由問題,為未來的研究工作提供了研究方向。
2 數據中心網絡的路由模型
數據中心是支持各種網絡應用、政企業務和科學計算的基礎設施,內部網絡設備規模巨大且通信流量復雜。面臨的挑戰之一是如何能夠構建一個可擴展的數據中心網絡,為應用提供大規模的聚合網絡帶寬,并在此基礎上提供高效的負載均衡路由。
從路由的角度看,數據中心網絡的主要目標是實現服務器之間大量的互聯互通,且具有高效傳輸與容錯機制。數據中心網絡通信模型可以分為一對一、一對多和多對多3種,相應地數據中心網絡路由也可以分為單播路由與組播路由;根據路由服務所在的層級,可以分為網絡層路由與應用層路由。
2.1 單播路由 vs 組播路由
目前大多數研究都集中于一對一通信模型的單播路由,主要目標是利用多路徑傳輸解決數據中心網絡單播流量的負載均衡問題。存在的主要問題是面對大量的不可預估流量時,如何利用網絡中存在的冗余路徑進行合理的調度,滿足應用服務的需求,減少網絡擁塞,提升網絡整體性能。數據中心網絡的單播路由可以借用已有的因特網路由協議來完成,也可以采用新的技術途徑,設計新的負載均衡路由協議。
常用的因特網單播路由協議有開放式最短路徑優先OSPF(Open Shortest Path First)、中間系統到中間系統IS-IS(Intermediate System-to-Intermediate System)和邊界網關協議BGP(Border Gateway Protocol)[3]等。OSPF和IS-IS是鏈路狀態協議,當網絡中有鏈路狀態發生改變時,鏈路狀態改變信息需要以泛洪方式傳送給所有路由節點,洪泛的過程會消耗網絡帶寬資源,因此不適用于大規模的數據中心網絡。并且OSPF和IS-IS在路由策略支持上不如BGP靈活。結合實際部署經驗,OSPF通常被用于中小規模的數據中心網絡,BGP則被用于大型數據中心網絡。BGP設計的初衷是用于因特網自治系統AS(Autonomous System)之間的域間路由互通,并不直接適用于數據中心,因此Internet協會頒布的RFC 7938中提出了大規模數據中心中使用BGP路由協議需要考慮的問題以及相應的建議[4]。RFC 7938選擇外部邊界網關協議eBGP(extern Border Gateway Protocol)作為路由協議,主要原因是eBGP比內部網關協議iBGP(internal Border Gateway Protocol)更容易部署和管理。采用BGP實現組網,會面臨BGP私有自治系統號不足的問題,因此建議使用4字節AS號或在數據中心網絡核心層重用AS號。由于數據中心網絡存在大量的點到點直連鏈路,在路由通告中宣告這些鏈路可能會帶來大量的轉發表FIB(Forwarding Information Database)和路由表RIB(Routing Information Database)開銷。RFC 7938提出了2種解決方案,分別是不宣告鏈路地址和宣告鏈路地址并進行路由匯總。不宣告鏈路地址不會對網絡設備通信產生影響,但運維和監控會變得更復雜;宣告鏈路地址并進行路由匯總需要對網絡地址進行合理規劃,給路由器之間的鏈路地址分配連續可匯總的地址段。在數據中心網絡中存在許多等價多路徑ECMP(Equal-Cost Multi-Path),數據中心BGP路由可以實現基于多AS號的ECMP,允許AS_PATH長度相同但內容不同的等價多路徑生效。針對BGP在因特網中會出現路由黑洞和收斂慢的問題,RFC 7938指出如果支持BGP對等會話快速失效(BGP Fast Peering Session Deactivation),鏈路失效時RIB和FIB及時更新,就可以實現亞秒級的路由收斂。同時也可以通過配置BGP連接的保持時間(hold-time)、存活時間(keep-alive)和更新報文定時器等參數,實現路由快速收斂。
很多研究人員設計了新的數據中心單播路由方法,本文第3節將重點闡述這些方法,并對其進行比較分析。
組播路由將源節點發送的數據復制給多個加入組播組的節點,屬于一對多通信模型。它存在的主要問題是如何構建并維護一個組播樹,以實現高效的組播數據包分發。傳統的IP組播需要運行復雜的組播路由協議,同時還要維護每條流的轉發狀態,由于其可擴展性低而沒有得到大規模的使用。隨著數據中心內部點到多點通信流量的快速增加,部署IP組播的吸引力在不斷增加。隨著軟件定義網絡SDN(Software Defined Network)技術的發展,使用集中式控制器優化交換機和路由器轉發組播流量的方法備受關注。由Li等[5]提出的數據中心高效可擴展組播路由機制ESM(Efficient and Scalable Multicast routing scheme)將入包布隆過濾器(Bloom Filters)與交換機內轉發表相結合。一方面,入包布隆過濾器用于小規模組播組,節約交換機內部路由表空間,同時將大的組播組路由條目下發給交換機,減少帶寬開銷。模擬實驗結果表明,與接收端驅動的組播路由相比,ESM可以減少40%~50%的網絡流量且應用吞吐量提高了2倍,入包布隆過濾器和交換機轉發表的組合路由機制顯著減少了交換機所需的路由條數。
2.2 網絡層路由 vs 應用層路由
在大規模數據中心中,大多數的網絡架構都是由企業網或因特網演化而來的,系統運行基于傳統的網絡層路由模型。網絡層提供分組轉發和路由選擇功能。當分組從發送方流向接收方時,網絡層為這些分組決定所采用的路徑,其中計算路徑的方法稱為路由選擇算法。在網絡層路由模型中,網絡管理員控制路由策略并下發配置,業務服務器與網絡核心相互隔離。從數據中心運營商的角度看,網絡層路由模型便于管理,并且能夠在多租戶場景中更好地滿足客戶需求,提高數據中心網絡整體性能。然而從數據中心應用的角度看,網絡內部是一個黑盒,應用服務無法控制數據包的轉發決策。
應用層路由允許終端服務器參與到路由中,可以根據應用層服務的需求,定制路由協議或決定如何轉發。英國微軟研究院的Abu-Libdeh等[6]在CamCube項目中提出一種應用層實現路由的方法,應用可以根據自身需求在路由的不同目標之間進行不同的平衡,從而解決了單一路由協議優化目標單一的問題,提高了應用的路由性能。2014年Chen等[7]提出一個將路由作為服務、租戶可以直接定向路由控制的框架RaaS(Routing-as-a-Service)。在多租戶數據中心環境下,路由控制可看作是一個售票過程,租戶向運營商提交路由控制請求,運營商為租戶完成路由傳輸服務,租戶與運行商之間緊密耦合。RaaS將路由視作服務,只需要很少的管理開銷,租戶可以獨立地進行路由控制,且可以直接利用現有技術運行在商用交換機上,不需要改變數據中心的網絡硬件基礎設施。
3 數據中心網絡的路由方法
數據中心可以被定義為能提供大規模計算和多種網絡服務的基礎設施,隨著因特網應用的不斷增加,軟件開發者和用戶都需要更加高效的數據存儲平臺,因此人們對數據中心的性能需求也不斷提高。
路由協議決定了路由器之間的通信過程,也決定了最優路由。因為數據流量可能流向數據中心內部、外部或交換機之間,因此路由協議必須能在所有服務器之間路由并轉發數據,保證網絡的連通性。為了有效利用數據中心基礎設施,需要設計比傳統因特網路由協議更加高效的路由協議,因此近年來提出了很多數據中心網絡路由方法。
根據關注要素的不同,路由方法可以劃分為拓撲結構相關的路由方法、流量相關的路由方法和能量感知的路由方法。拓撲結構相關的路由方法通常依賴于某種特定拓撲,在此基礎上設計編址與路由轉發方法,支持最短路徑、非最短路徑和多路徑路由等。流量相關的路由方法主要關注數據中心內部流量調度,優化流量轉發路徑實現全局負載均衡,對拓撲結構不敏感。能量感知路由方法的主要目標是在不影響性能的前提下降低數據中心能耗,主要面臨2個問題:首先是如何篩選出冗余鏈路,其次是如何在動態拓撲的情境下為流量選路,因此能量感知的路由方法對效率和可靠性要求較高,需要在通信性能和節能之間達到合理的平衡。
3.1 評價指標
為了更直觀方便地對不同路由方法進行比較,Besta等[8]提出了以下6個路由方法的評價指標,本文根據路由方法對交換機的要求添加了第7個指標。
(1)最短路徑SP(Shortest Paths)的支持:是否可使用任意的最短路徑。
(2)非最短路徑的利用NP(Non-minimal Paths):是否可利用非最短路徑。
(3)多路徑支持MP(Multi-Path):是否可同時使用多條路徑。
(4)不相交多路徑DP(Disjoint Paths):是否支持不相交的多路徑。
(5)自適應負載平衡ALB(Adaptive Load Balancing):是否具有自適應負載平衡的能力。
(6)拓撲相關性TD(Topology Dependency):是否依賴于特定的網絡拓撲。
(7)交換機可編程SPA(Switch Programm Ability):是否要求數據中心交換機可編程,如采用白盒交換機。大多數商用交換機可以支持OpenFlow協議,因而可以利用交換機的可編程性來實現功能更強的路由控制方法。
3.2 拓撲結構相關的路由方法
借助已知的拓撲結構知識,優化路由轉發的路由方法稱為拓撲結構相關的路由方法,這類路由方法又分為以交換機為中心(Switch-Centric)的路由方法和以服務器為中心(Server-Centric)的路由方法。
當采用交換機來構建數據中心網絡時,根據交換機的開放可編程情況,一般采用2類路由協議:一類是直接利用商用交換機提供的路由協議,如常見的OSPF和BGP路由協議;另一類要求交換機是開放可編程的白盒交換機,支持用戶設計實現自己的路由協議。
3.2.1 以交換機為中心的路由
在傳統的因特網中,網絡終端只負責數據包的發送與接收,數據包轉發都交給了網絡核心的交換機與路由器完成。類似地,在數據中心網絡中,在交換機上運行路由協議,通過交換機來構建數據中心網絡,如典型的Clos結構網絡,基于這種網絡的路由方法稱之為以交換機為中心的路由方法。
以交換機為中心的路由可以在已有拓撲的基礎上,添加對虛擬機遷移前后不改變地址的支持或提供統一的高容量傳輸。如Greenberg等[9]提出的虛擬二層VL2(Virtual Layer 2)數據中心架構,由低開銷的專用交換機組成Clos拓撲結構。這種網絡架構可以提供所有服務器之間統一的高容量、同一臺服務器上的服務之間性能隔離,還支持以太網二層語義,管理員可以給服務分配任意服務器并配置任意IP地址。VL2的一個限制在于它不能提供服務器之間的帶寬保證,對于很多要求實時性的應用來說是不足的。Al-Fares等[10]提出了一個可擴展的商用數據中心網絡架構,支持任意主機之間充分利用本地網絡接口的帶寬進行通信。該架構使用胖樹(Fat-tree)拓撲,根據服務器所處的機架以及接入交換機的位置進行編址,設計了二級查表匹配的路由方法,一級表使用前綴匹配,二級表使用后綴匹配,在存在多路徑的情況下,可以將相同目的地的連續數據包沿相同路徑轉發,避免數據包重排序。
Besta等[8]提出了一個簡單、通用、健壯的以太網路由架構FatPaths,能充分利用數據中心的路徑多樣性,同時支持最短路徑和非最短路徑。通過形式化分析,實現了非常高的以太網性能提升,可以應用于超算系統和數據中心。FatPaths重新設計了傳輸層協議,改善了TCP啟動慢等性能障礙,且使用流粒度交換,能避免TCP報文重排序,因此可以很簡單高效地實現負載均衡。另外,作者使用了最多一百萬個終端節點進行模擬,結果表明使用FatPaths的短直徑拓撲比Fat-tree結構性能更好。
3.2.2 以服務器為中心的路由
以服務器為中心的路由方法在服務器上運行路由協議,目的是充分利用服務器的硬件資源,減小核心交換機的壓力,因此服務器在多跳通信中起到了中繼節點的作用;并且以服務器為中心的路由方法常常將拓撲設計為由遞歸或模塊化的方式得到,具有很好的擴展性,如BCube[11]和Dcell[12]等。
BCube整個結構采用遞歸定義,結構雖然工整但是比較復雜。BCube的拓撲結構中一個BCubek是由n個BCubek-1和nk個n端口交換機組成。Guo等[11]針對BCube結構設計了BCube源路由算法,數據源服務器會持續發送探測報文探測鏈路可用帶寬,同時還使用寬度優先搜索算法進行替代路徑查詢,具有很好的容錯性。
類似地,DCell也以遞歸定義的方式來連接服務器[12],即高維的DCell由許多低維DCell遞歸連接而成,具有很好的容錯性,且提供高了吞吐量。Wang等[13]提出的SprintNet拓撲結構也是以服務器為中心的路由方法,它使用分割轉發單元的方法提供可擴展的網絡架構,且能夠保證轉發路徑較短。
3.2.3 拓撲結構相關的路由方法小結
基于上述評價指標,表1對與上述拓撲結構相關的路由方法的研究工作進行了比較。從表1中可以得知,拓撲結構相關的路由方法通常依賴于某種特定拓撲,在此基礎上設計編址與路由轉發方法,從而實現比胖樹(Fat-Tree)和葉脊(Spine-Leaf)架構更好的性能。然而,由于它們與底層路由機制相互獨立,因此在實踐中難以實現理論的高帶寬,同時還需要對網絡拓撲和網絡協議棧進行修改或重新設計,增加了實際部署的難度。
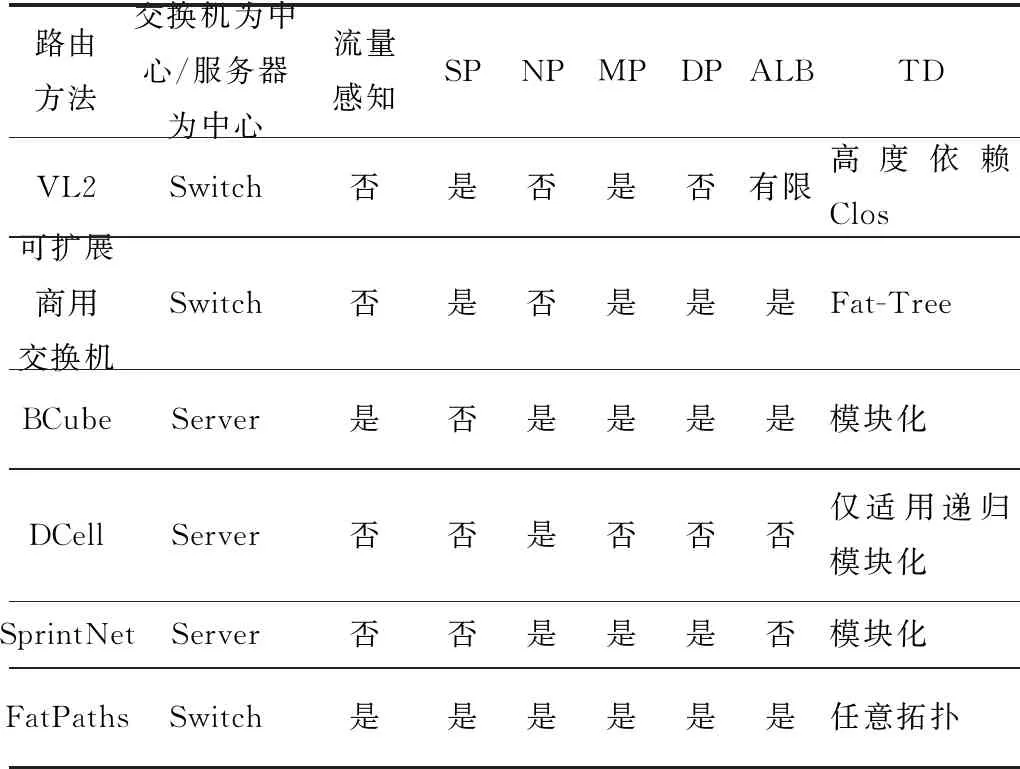
Table 1 Comparison among topology-aware routing methods
3.3 流量相關的路由方法
流量相關的路由方法是指能夠根據數據中心內部流量特點進行調度的方法,路由算法根據不同的優化目標做出滿足服務需求的轉發決策,總而言之以提升網絡整體帶寬利用率、實現負載均衡等為主要目標。Benson等[14]指出,傳統的流量相關的路由方法只能達到最優路由機制80%~85%的性能。主要原因包括3點:(1)沒有利用數據中心多路徑特性;(2)無法自適應動態流量負載;(3)進行路由決策時沒有掌握全局視圖。本節將參考以上3個因素,對流量相關的路由方法進行分析與評估。
流量相關的路由方法可以從2個維度進行分類。首先,根據轉發決策所掌握的信息和決策范圍可以分為分布式路由方法和集中式路由方法。分布式路由方法使用局部或全局信息進行局部決策,集中式路由方法使用全局信息進行全局決策。其次,根據流量調度是否能提前避免擁塞事件的發生可以分為主動式流量調度和被動式流量調度。主動式流量調度能在網絡故障或突發流量發生時,在網絡擁塞導致丟包前,一定程度上避免網絡擁塞,但靈活性不足;被動式流量調度通常依賴網絡負載信息做出判斷,具有較強的靈活性,但不可避免地會引入反饋時延。
3.3.1 分布式路由方法vs集中式路由方法
分布式路由方法中網絡設備使用局部或全局信息進行局部決策。Wu等[15]提出了數據中心網絡分布式自適應路由框架DARD(Distributed Adaptive Routing architecture for Datacenter networks)。該算法的目標是不對現有的基礎設施進行修改或升級,且輕量可擴展,能充分利用數據中心對分帶寬(Bisection Bandwidth),同時能在大流之間提供公平性。DARD運行在終端主機上而不是交換機上,對網絡中的動態流量負載敏感,可以將超載路徑上的流量高效分擔到空閑路徑。DARD的設計目標之一是解決大流之間的公平性問題,因此不可避免地忽略了小流的調度。在數據中心網絡中,小流產生的流量占比小于10%,流數量卻占總流數量的99%。每條小流都必須由交換機進行轉發決策,因此對數據中心網絡性能也產生了很大的影響。Li等[16]提出了任務級性能優化專用調度器OPTAS(OPtimize TAsk-level performance Scheduler),這是一個分布式小任務感知的流監控和調度系統,主要解決目前很多研究中小流被忽略或小流給集中式調度帶來的開銷過高的問題。OPTAS 的架構包括運行在數據接收端的任務監控器(Task Monitor)和決策計算模塊(Policy Calculator),其中任務監視器用來識別任務的開始與結束;還包括運行在發送端的緩存監控器(Buffer Monitor)和決策執行模塊(Policy Enforcer),可以根據緩沖區待發送數據大小區分大任務和小任務。OPTAS會給小任務分配更高的優先級。實驗結果表明,OPTAS的調度速率比公平調度快2.2倍,比僅分配小任務最高優先級快1.2倍。
在數據中心網絡中,網絡設備由運營商統一管理,具有網絡拓撲的全局視圖,因此集中式路由方法被認為是可行的數據中心路由方法。集中式路由方法將數據平面與控制平面分離,將OpenFlow協議視作網絡設備數據平面的標準化編程接口。一些研究為了實現功能更強的路由控制,使用可編程的白盒交換機。
Hedera是由Al-Fares等[17]提出的一個集中式可擴展、動態流調度器,可以有效利用數據中心網絡中的聚合網絡資源。它的主要目標是以最少的調度開銷最大化對分帶寬的利用率。Hedera實現了路由和流量信息的全局視圖,調度器從邊緣交換機收集流信息來挑選無擁塞路徑,然后交換機負責轉發流量。作者提出了全局首次適配(Global First Fit)和模擬退火(Simulated Annealing)2種啟發式算法來解決流調度的NP完全問題。與Hedera相似,農黃武等[18]提出了基于SDN的胖樹數據中心網絡的多路徑路由算法。針對Hedera提出的全局首次適配算法無法達到全局最優,而模擬退火法收斂速度可能很慢的問題,該算法使用基于深度優先查找的思路計算緩存網絡中所有節點對的多路徑信息,以提高響應速度。當新的數據流到來時,使用最差適應法確定備選路徑,即在所有的路徑中,挑選出瓶頸鏈路負載最小的路徑,實現了快速有效的流量負載均衡。
另外,Hedera忽略了數據中心網絡流數量中占據大多數的小流,無法精確地實現負載均衡。楊洋等[19]提出了一個基于多路徑傳輸的動態路由算法Dramp。Dramp對鏈路權值進行優化,在節點對之間的多條有效路徑上合理地分配流量,確保關鍵鏈路不會成為產生擁塞的瓶頸鏈路。并且Dramp在完成細粒度流量均衡的同時,能很好地控制控制器的額外計算開銷,也不需要對目前的通信協議進行任何改動。彭大芹等[20]提出了基于SDN的胖樹數據中心網絡多路徑路由算法,將數據流分為大流和小流,大流根據路徑權重值進行路由,小流數量多但處理的復雜性要求較低,選擇可用剩余帶寬最大的路徑,這樣能夠提高胖樹數據中心網絡的平均鏈路利用率和網絡吞吐量。
集中式控制方法面臨單點失效、控制器負載過重等問題。如果使用冗余備份控制器,則會增加部署成本和控制器同步開銷。為了改善如Hedera使用一個控制器掌握全局視圖導致的負載過重問題,Tam等[21]引入了下放控制器的概念,為集中式路由方法提供了新的思路。每個小控制器只負責局部的網絡視圖,但是所有的控制器可以覆蓋整個網絡,并提出了路徑分區啟發式算法和分區路徑算法為流分配路徑。Tam等[21]在Spring等[22]測量得到的ISP拓撲結構上,對這2種算法進行評估,結果表明這2種算法都可以很好地限制控制器負載,雖然找到的不是全局最優解,但找到的解和模擬退火算法找到的解相近且速度更快。
也有研究對單個控制器進行優化,通過減少與控制器的通信過程,減小控制器負擔。Ramos等[23]提出了SlickFlow可靠的源路由方法,使用OpenFlow協議實現,把源路由與備用路徑信息搭載在數據包頭部,實現支持快速故障恢復的彈性源路由機制。當首選路徑出現故障時,數據包可以通過交換機重路由到備用路徑而不需要詢問控制器,但需要交換機支持對數據包備用路徑的解析。Wang等[24]提出了一個低開銷的、負載均衡路由管理框架L2RM(Low-cost, Load-balanced Route Management framework),通過持續監控網絡流量并計算負載偏差參數來檢驗是否有交換機鏈路負載過重,如果有則觸發路由修改機制,將流分發到不同的鏈路實現平衡負載。與此同時還采用輪詢的方式查詢交換機的狀態,減少控制器的開銷。
以上2種方式都是嘗試減少與控制器的通信,提高調度實時性,但必然會面臨可擴展性的問題,即隨著網絡規模的增大,要保證在可接受的時間內完成路由優化。陳松等[25]提出了一種新穎的面向數據中心網絡流量的路由優化算法,其主要優化對象是具有語義相關性的Coflow流(指數據中心中傳輸的具有相關性的若干個流),并提出了面向海量流采用GPU并行計算的路由優化算法。相比于CPU,GPU可以支持數百倍數量的線程。算法還使用了拉格朗日松弛方法分解路由優化問題,利用Bellman-Ford最短路徑算法為每個業務計算路由,結果表明該算法可以提高流量調度的實時性。
3.3.2 主動式流量調度vs被動式流量調度
路由方法根據流量調度是否能提前避免擁塞事件的發生,可以分為主動式流量調度和被動式流量調度[26]。主動式流量調度主動進行流量調度,從而達到避免擁塞發生的目的;被動式流量調度是在擁塞事件發生后,再相應地進行流量調度,以緩解網絡擁塞。
ECMP是最常見的主動式流量調度方法,它是一個具有主動特性且無狀態調度的負載均衡方法。通過對流的頭部字段進行哈希運算,根據哈希值決定流的傳輸路徑。ECMP的缺陷在于難以適應非對稱拓撲和大小流混合的場景。盡管如此,研究表明[27],隨著流的數量增加以及流的大小分布的方差減小,ECMP的缺陷可以得到緩解并獲得近似最優解。He等[26]提出了一個基于軟件邊緣的主動式流量調度方案Presto,利用邊緣虛擬交換機(Virtual Switch)將每條流整形成相似大小的子流,并且將它們均勻地分發到網絡中,從而實現負載均衡。Presto可以提升網絡吞吐率和流調度公平性,降低網絡延遲,同時能夠縮短小流的流完成時間。
被動式流量調度是當調度器或交換機感知到網絡擁塞事件后,再進行流量調度。如果突發流量的持續時間很短,被動式流量調度則難以發揮很好的作用。很多集中式流量調度機制處理網絡擁塞時都是采用被動方式,并且由于它們的控制環路存在時間延遲,因此只能實現粗粒度優化,如上文提到的Hedera[17]和Dramp[19]。
3.3.3 流量相關的路由方法小結
流量相關路由方法主要關注數據中心內部流量調度,針對不同的流量模型設計調度策略。上述流量相關的路由方法都不依賴于特定網絡拓撲,也不保證對所有數據流都支持使用非最短路徑或不相交路徑。因此,表2主要關注路由方法對交換機的可編程要求(SPA),并使用是否支持多路徑(MP)、自適應負載均衡(ALB)和拓撲依賴性(TD)3個指標進行對比。
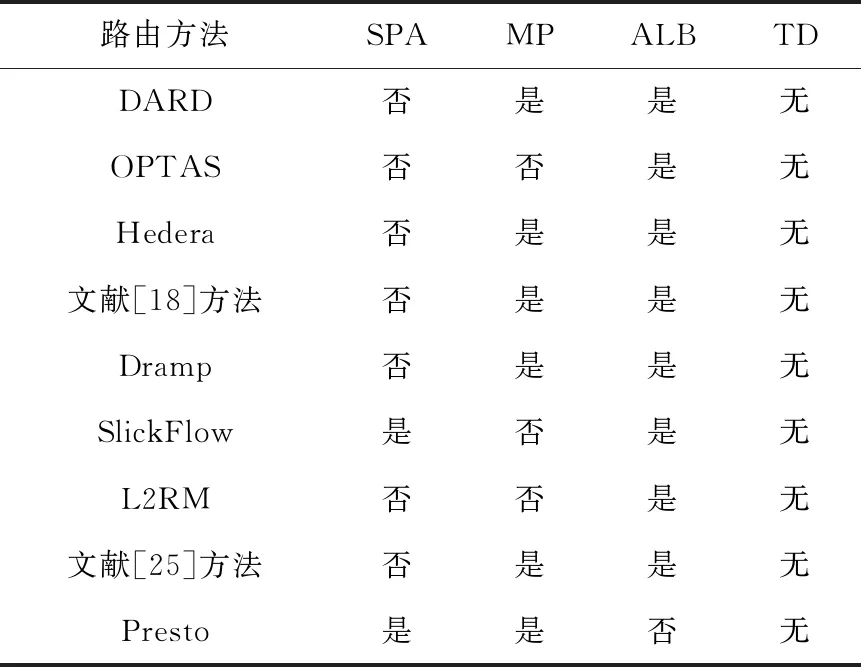
Table 2 Comparison among traffic-aware routing methods
3.4 能量感知的路由方法
大型數據中心全天候運行數十萬臺網絡設備,為了節約能量,可以讓不參與通信的設備在不影響網絡性能的前提下進入休眠狀態,因此需要有高效的能量感知路由方法。目前有很多研究對數據中心網絡能量感知路由方法進行探索,由于該優化問題屬于NP難問題,因此大多數研究都選擇啟發式算法求解該問題。
Shang等[28]提出了數據中心網絡綠色路由,嘗試從路由的角度減少數據中心能源消耗。該方法建立了能量感知的路由模型,證明了問題的NP難性質并設計了一個啟發式算法,將網絡吞吐量視為性能的度量值。該算法首先在所有交換機上計算最短路由,稱之為基本路由。然后逐一地將流量負載最低的交換機設置為睡眠狀態,直到網絡吞吐量下降到某個閾值,達到了網絡管理者對網絡吞吐量的最低要求,算法結束,并更新拓撲結構,移除處于睡眠狀態的交換機。類似地,Xu等[29]提出了具有吞吐量保證的能耗感知路由算法,主要目標是減少密集連接數據中心中網絡設備的能耗。該啟發式算法首先將拓撲結構、流量矩陣和吞吐量閾值等輸入路由生成(Route Generation)模塊,為流量矩陣中的每條流計算一條傳輸路徑;然后經過吞吐量計算(Throughput Computation)模塊得到網絡吞吐量,再判斷是否需要移除交換機或鏈路;最后輸出新的網絡拓撲。同時,為了提高可靠性,用戶可以在可靠性適應(Reliability Adaptation)模塊中通過配置可靠性參數確定為每條流保留備選路徑的數量。如果由于網絡故障等原因,導致之前移除交換機和鏈路后產生的路徑不可達,流可以切換到備選路徑中。
這2種能量感知路由協議都需要預先知道流量矩陣。如果流量矩陣不準確,可能會出現網絡無連接的問題。何榮希等[30]提出了軟件定義數據中心網絡多約束節能路由算法MER(Multi-constrained Energy-saving Routing),考慮網絡連通性和時延等因素,選擇代價最小的路徑傳輸數據流。
由于能量感知路由方法的目的是降低數據中心能耗,而3.1節中的7個指標主要關注路由方法的功能,因此表3從能量感知路由方法的目標和主要思路2方面進行比較。
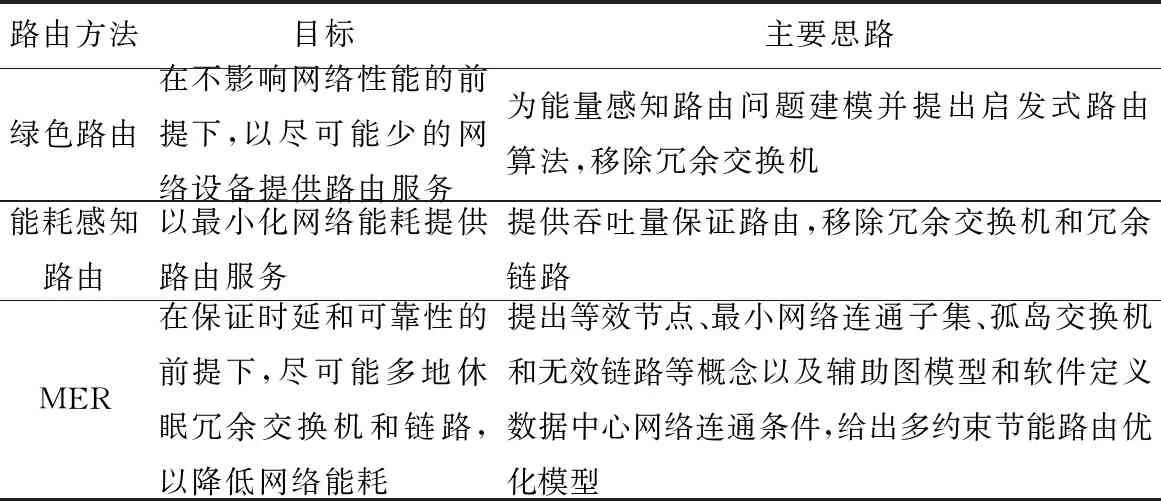
Table 3 Comparison among energy-aware routing methods
根據對上述能量感知路由方法的相關研究比較分析,可以得出能量感知的路由方法的本質是在變化拓撲下的流量調度問題。與流量相關的路由方法的不同之處在于,能量感知的路由方法需要根據網絡流量狀況休眠部分網絡設備,因此關鍵問題是如何篩選出網絡中存在的冗余設備,而流量調度問題則可以交給流量相關的路由方法負責解決。
4 擁塞感知的路由方法
數據中心網絡時常發生網絡擁塞事件,傳統的TCP/IP協議棧使用TCP協議實現擁塞控制,而網絡層路由對網絡擁塞狀態是無感知的。因此,TCP擁塞控制機制無法充分利用數據中心網絡的冗余傳輸路徑,且對時延敏感的流量不友好。一些研究工作提出了適用于數據中心的傳輸層協議,根據擁塞控制的位置分為發送端擁塞控制和接收端擁塞控制。發送端擁塞控制是指發送端根據擁塞狀況調節發送速率,比較典型的有數據中心傳輸控制協議DCTCP(Data Center Transmission Control Protocol)[31]、流截止時間感知的數據中心傳輸控制協議D2TCP(Deadline-aware Datacenter Transmission Control Protocol)[32]、基于延遲測量的傳輸層協議TIMELY(Transport Informed by MEasurement of LatencY)[33]和數據中心量化擁塞通知DCQCN(Data Center Quantized Congestion Notification)[34]。接收端擁塞控制是指接收端根據擁塞狀況來調節控制發送端的發送速率,如Homa[35]和ExpressPass[36]。DCTCP、D2TCP和DCQCN借助擁塞信號完成閉環擁塞控制,TIMELY通過往返時間RTT(Round Trip Time)調節發送速率,但是由于一個RTT內數據包往返轉發路徑可能不同,因此無法精確感知擁塞狀況。在Homa和ExpressPass中,接收端為發送端發送數據授權并指派優先級,從而控制發送端的發送速率。以上擁塞控制協議都發生在終端主機的傳輸層,網絡層路由器的路由轉發決策對傳輸層而言是透明的,無法充分利用數據中心網絡的多路徑特性。因此,路由協議能夠根據網絡擁塞狀態為流量選擇不同的路徑,成為提高數據中心網絡通信性能的重要途徑,這樣的路由方法稱為擁塞感知的路由方法。
根據現有研究,擁塞感知的路由方法可以分為集中式擁塞感知路由與分布式擁塞感知路由。集中式擁塞感知路由通常使用集中控制器獲取全局擁塞信息,為流分配傳輸路徑并將轉發表項下發到交換機上。分布式擁塞感知路由通常使用全局或局部擁塞信息在網絡局部實現優化,局部優化的決策設備分為網絡邊緣設備和網絡交換設備。
4.1 集中式擁塞感知路由
Kanagevlu等[37]提出了一個針對大小流混合的邊緣到邊緣重路由機制,當發生擁塞時,考慮到小流存在周期短,重路由會增加它們的延遲和開銷,因此只將大流重路由到備用路徑。Kanagevlu等[38]還提出了一個局部重路由機制,基于SDN技術在數據中心網絡中高效管理鏈路擁塞或故障。不同于其它研究中通過通知源節點進行適當的速率調整,以及在源節點進行重路由來處理擁塞,局部重路由機制是在擁塞發生點或擁塞發生點的上一跳,根據流分類機制把數據流重路由到其它可能的路徑。類似地,Fastpass也是一個集中式控制系統[39],其目的是能夠實現交換機零隊列(或非常淺的隊列)。它使用集中式控制器決定每個數據包的傳輸時間和傳輸路徑,因此該系統的關鍵在于時間片分配算法和路徑分配算法。控制器需要快速響應用戶發送數據的請求。同時控制協議要非常穩定,否則數據沒有得到分配的時間片,無法發送數據,因此Fastpass在實現上受到了可擴展性與可靠性的限制。與上述2種方法不同,Vissicchio等[40]提出的Fibbing是一個在分布式路由之上使用集中式控制的聯合優化架構。Fibbing不需要可編程交換機,可以直接部署在商用交換機上,集中控制器會生成一個增強型拓撲,其中包含一些實際不存在的節點和鏈路。例如,這些實際不存在的鏈路可以組成一條新的最短路徑,且第一跳與實際拓撲中的非最短路徑重疊,則集中控制器下發偽造的最短路徑后,在實際轉發過程中流量會沿著實際拓撲中的非最短路徑轉發,從而達到網絡路由優化的目的。生成增強型拓撲的關鍵在于能夠避免環路和路由黑洞,且生成的拓撲要盡可能小。如果給定希望得到的轉發條目和路由協議,Fibbing會計算出應當通告給路由器的消息,可以實現流量工程、負載均衡和故障恢復。
以上3種集中式擁塞感知路由都是使用SDN對數據流的傳輸進行集中式控制,以此減少或避免擁塞,但存在集中式方法的單點失效等問題。
4.2 分布式擁塞感知路由
CONGA(CONGestion-Aware load balancing scheme)是一個分布式擁塞感知的路由方法[41],使用全局擁塞信息以流片(flowlet)粒度決策,比流粒度調度的方式更精確。一條流包含了一系列的突發流量,當一條流中2個數據包到達的時間間隔超過某一閾值,則將之前的數據包劃分為一個流片[42]。CONGA將擁塞控制的功能從網絡核心設備卸載到網絡邊緣的接入交換機上,數據包會攜帶該條路徑上的最大負載并抵達目的交換機,目的交換機將負載信息搭載在返回的數據包中,從而實現一個擁塞感知的反饋機制。CONGA在二層葉脊拓撲中可以達到很好的效果,但在復雜拓撲中,因為一條路徑由多條鏈路組成,降低了CONGA的擁塞控制效果。與CONGA類似,逐跳帶寬利用率感知的負載均衡框架HULA(Hop-by-hop Utilization-aware Load balancing Architecture)也是一個使用全局信息實現擁塞控制的路由機制[43]。但是,HULA以逐跳的方式實現反饋,每一個交換機節點會周期性地向其它節點發送自身負載信息。這引入了不必要的探測數據包開銷,尤其是當網絡處于擁塞狀態時,探測數據包不僅無法抵達目的地,而且還可能會加劇擁塞程度。Fan等[44]提出了一個基于全局信息決策的分布式數據驅動的擁塞反饋機制,對CONGA和HULA進行改進,可以在大規模多級胖樹拓撲中實現很好的性能。它將網絡劃分為多個獨立的路由域,不同路由域之間的數據包經過核心交換機時會攜帶網絡接口的負載信息,因此路由域具有網絡的全局負載信息。路由域內的交換機負責維護域內和域外負載矩陣,以流片粒度為數據包選路。一般情況下路由算法若要掌握全局信息需要巨大的控制報文開銷,但Fan等提出的機制將負載信息搭載在數據包中,大大減少了控制報文開銷。
對于基于全局擁塞信息進行優化的方法,研究認為其控制環路所消耗的時間可能大于大多數擁塞事件的持續時間,因此無法對網絡擁塞做出及時的響應。
Zhang等[45]提出了分布式擁塞感知自適應轉發方法CAAR(Congestion-Aware Adaptive foRwarding),交換機僅依賴于局部信息(鄰居節點的隊列長度)就可以實現流量負載均衡,其中心思想是選擇鏈路帶寬未被充分使用的路徑進行數據包轉發。如果所選擇的路徑在傳輸過程中發生擁塞,流可以重定向到另一條未充分利用的路徑。模擬實驗顯示,CAAR可以在多種流量模型下自適應流量變化,相比于ECMP可以很好地提高冗余帶寬利用率,但它需要交換機可編程,具有一定的部署難度。Ghorbani等[46]提出了一個針對Clos網絡拓撲的微秒時間尺度的網絡內部分布式隨機本地負載均衡DRILL(Distributed Randomized In-network Localized Load balancing)機制。每個數據包僅根據局部交換機隊列占用情況和隨機算法分發負載,就能夠快速對擁塞做出反應。DRILL使用了類似power of two choices[47]的調度算法,選路時會隨機選取2個可用的出接口,并與上一次決策時選擇的最低負載出接口的隊列占用情況進行對比,選擇3個接口中負載最小的出接口發送數據包。DRILL還對常常面臨的數據包重排序與非對稱拓撲問題進行研究并提出了解決方案。與CONGA相比,DRILL可以在隊列長度開始增加時就迅速調整流量分發。在80%的流量負載下,DRILL可以實現99%的流完成時間比CONGA的快1.4倍。Huang等[48]提出了隊列延遲感知的數據包分發負載均衡機制QDAPS(Queueing Delay Aware Packet Spraying for load balancing)。QDAPS以數據包粒度進行轉發,針對數據包粒度轉發面臨的共同問題——非對稱拓撲會引起數據包重排序,QDAPS根據這條流的上一個數據包在隊列中的排隊延遲決定輸出端口,讓先到達的數據包比后到達的數據包先發送,從而解決該問題。文中還指出以流粒度、流片粒度轉發雖然可以避免數據包重排序問題,但是靈活性不足,會降低鏈路利用率。
也有一些研究立足于在盡可能不改變交換機硬件的前提下實現分布式擁塞感知的負載均衡路由。Kabbani等[49]提出了一個流級別的擁塞感知路由方法Flicr。Flicr利用ECN感知擁塞,當擁塞發生時,主機修改流的VLAN字段實現重路由。目前商用交換機都支持VLAN功能,因此Flicr不需要改變交換機硬件,只需要修改主機內核、并對交換機進行VLAN相關配置,就可以快速完成部署。Flicr不僅降低了鏈路故障導致的流恢復時間,而且還適用于非對稱網絡拓撲。
4.3 擁塞感知的路由方法小結
表4對擁塞感知的路由方法進行比較,主要分析了集中式/分布式、擁塞控制設備、擁塞控制使用的擁塞感知信息和擁塞控制粒度4個特征。總的來說,集中式擁塞感知路由方法普遍掌握全局擁塞信息視圖,為交換機下發配置,需要解決的關鍵問題是實時性和可擴展性問題;而分布式擁塞感知路由方法更加靈活,且獲取擁塞信息的方法簡單快速,需要解決的關鍵問題是局部擁塞信息帶來的局限性。另外,不同路由方法選取的擁塞控制粒度不同,數據包粒度實現簡單,但需要解決數據包重排序問題;流相關粒度不會面臨數據包重排序問題,但需要解決的關鍵問題是流表規模、查表速度以及在大小流混合的流量模型中如何均勻轉發大小流實現擁塞避免。
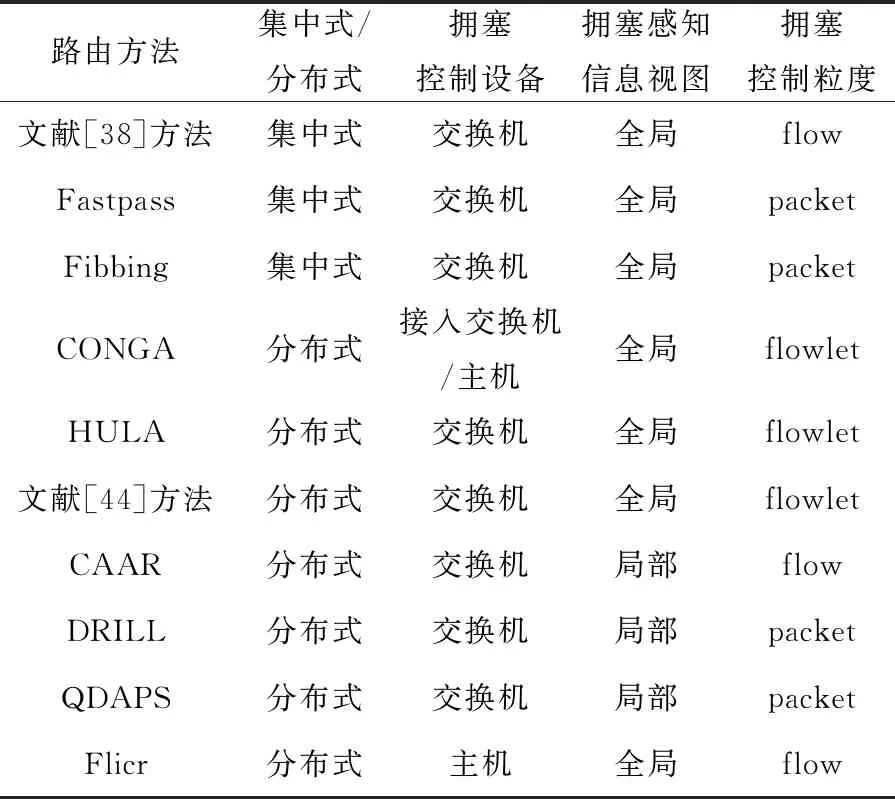
Table 4 Comparison among congestion-aware routing methods
5 新型數據中心網絡的路由技術
5.1 光交換的數據中心網絡
云計算和Web服務要求數據中心能提供非常高的通信帶寬。相比由商用以太網交換機構成的數據中心網絡,光交換網絡可以提供更高的吞吐量、減少能量消耗且具有可重構特點,是未來數據中心網絡的發展方向。目前已有DETOUR[50]、c-Through[51]、Helios[52]和MegaSwitch[53]等光交換數據中心網絡,它們使用高容量的光纖和光交換機互聯,可以實現光電路交換、光分組交換或光突發交換。光分組交換和光突發交換由于帶寬資源粒度較小,可以滿足突發性較大的業務流量的交換[54]。
傳統交換機存在入接口和出接口緩沖區,負責暫存數據包。對于一個數據包而言,最優的情況是當它經過交換機時,入接口緩沖區和出接口緩沖區都為空,可以直接為它提供服務,如Fastpass[39]通過集中式調度為所有數據包分配發送時間片和傳輸路徑,避免數據包排隊甚至擁塞。然而由于缺乏全網同步機制,Fastpass也需要很小的緩沖區。在全光或混合數據中心網絡,光纖會引入特定的傳播延遲,但只要交換機在延遲時間內能夠完成數據包選路,就不需要交換機接口緩沖區[52]。因此,光數據中心網絡的路由方法需要在非常短的時間內實現選路并完成重構。
傳統交換機基于數據包頭部內容或數據包元數據為其選路。OpenFlow協議作為SDN網絡設備數據平面的標準化編程接口,使用集中控制器為流計算路由并將流表項下發到轉發表,并可以基于更多字段為數據包選路。光數據包交換OPS(Optical Packet Switching)查表可以在有限的時間內完成標簽提取和重構操作,光纖延遲線引入的延遲起到了緩存數據包的作用,等待OPS查表完成后轉發數據包。這種方法非常適用于光數據中心網絡。另一種光數據中心網絡常用的選路方法是波長查表,即將接收到的具有特定波長的光信號轉發到特定端口,因此波長選路不需要提取任何標簽字段,直接使用波長實現路由決策,但前提是需要預先建立波長電路[55]。與電路交換類似,波長選路的優勢在于選路迅速且選路過程中不需要任何內存和處理資源。Wang等[56]提出全光交換的數據中心網絡端到端調度方法,其主要目標是解決網絡內部零緩沖和不可忽視的重構時延,并提出了2種具有重構時延的交換機調度算法。
目前光數據包交換查表的路由方法如果出現查表時間超出時間界限,則數據包會被丟棄并重傳。未來,光數據包交換查表的路由方法可以考慮的研究方向應當是有上下界決策時間保證的路由方法,能夠形式化證明路由方法的決策時間上下界,從而為光數據中心網絡提供更高的可靠性。另外,波長查表的路由方法可以充分利用物理特性進行轉發,但需要集中控制器參與,類似于OpenFlow的方式,為不同波長的光信號分配時間片和路徑并下發給交換機。未來,研究波長查表的路由方法可以根據集中式調度引入的額外時延開銷,考慮分別對不同階段所引入的時延進行優化,如發送方上報時延、集中式算法運行時延等,從而降低集中式控制對實時性的影響。
5.2 有線無線混合的數據中心網絡
有線數據中心網絡面臨布線復雜與熱點鏈路2個不可避免的問題,導致了很高的部署和運維成本,并且熱點鏈路會產生擁塞事件以致影響全局性能。因此,一些研究工作建議將無線通信技術應用于數據中心網絡。其設計的初衷是在不降低鏈路傳輸速率的前提下,服務器之間采用無線連接減輕核心交換機負載,降低布線復雜度和運維成本,方便擴展數據中心網絡。
目前無線網絡的特點是:高頻段速率快且穩定,但容易被遮擋和干擾;低頻段不易受干擾但速率慢;另外無線設備的天線方向也對傳輸性能影響比較大。因此,將無線通信應用于數據中心還面臨以下難點:首先必須提供高速率通信技術,60 GHz技術的發展使得高速無線通信技術應用于數據中心成為可能,Kandula等[57]提出在架頂ToR(Top of Rack)交換機之間添加60 GHz的無線鏈路來緩解局部熱點的擁塞問題。其次為了保證各機柜之間快速建立高速鏈接,必須優化數據中心網絡拓撲結構,傳統基于行的數據中心機架排布方式在一定程度上阻礙了機架間建立無線連接[58]。第三還需要設計合理的資源分配機制,為數據流分配互不干擾的信道。清華大學Cui等[59]對無線數據中心網絡面臨的實際部署問題進行了研究,文中將信道分配問題形式化為一個最大化無線傳輸總利用率的優化問題,為此設計并實現了一個基于Hungarian算法[60]的啟發式算法。針對以上問題目前已經有許多研究成果,為無線數據中心網絡設計提供了參考。
為解決無線數據中心網絡中的負載均衡問題,Celik等[61]提出了應用于光無線數據中心網絡的流量聚合路由方法。它只對小流采用三步流聚合3SFG(Three-Step Flow Grooming)的方法處理。3SFG方法發生在源服務器節點與交換機上,分為以下3個步驟:(1)服務器到服務器S2S(Server-to-Server):源服務器節點聚合所有去往相同目的服務器的小流,生成S2S數據流;(2)服務器到機架S2R(Server-to-Rack):源服務器聚合所有去往相同機架交換機的S2S數據流,并轉發給機架交換機;(3)機架到機架R2R(Rack-to-Rack):機架交換機將收到的S2S數據流根據目的機架不同,聚合成多條R2R數據流,然后使用R2R光無線鏈路傳輸數據流。3SFG方法會根據機架間的長期流量統計數據決定R2R數據流的路徑容量和路由。由于大流已經有明確的流量需求如流的大小、持續時間等,因此當檢測到大流后,不需要流聚合,機架交換機會建立從源到目的的光無線鏈路,當大流傳輸完成后終止鏈路連接。由于3SFG方法使用長期流量統計信息,因此被稱為長期負載均衡,無法在具有突發流或流量頻繁變化的流量模型中實現負載均衡。AlGhadhban等[62]提出了一個靈活的短期負載均衡機制SoftFG(Soft-reconfigurations and Flow Grooming)。SoftFG能夠應對變化的流量模型,可以在無線數據中心網絡中,對不同類別數據流對應的多個虛擬拓撲實現負載均衡。SoftFG可以在不對路徑容量進行硬件重構的前提下,將擁塞路徑上的大流重路由到未完全利用的鏈路上。考慮到重路由引起的重排序開銷對小流影響較大,因此SoftFG不對小流進行處理。SoftFG作為內核模塊被安裝在虛擬交換機中,它可以基于源和目的之間的協作機制收集數據流的統計信息,同時結合主動探測技術,確保對網絡路徑的實時監測、早期擁塞感知和快速準確的重路由。網絡模擬顯示,在部署SoftFG的無線數據中心網絡中,數據流完成時間比部署LetFlow(Let the flowlets Flow)[63]和CONGA[41]分別快了12倍和17倍。
未來,針對有線無線混合的數據中心,應當提出更多能充分利用無線通信技術特點的路由方法。其次由于無線網絡也存在多路徑,且鏈路狀況更加復雜,SoftFG沒有解決數據包重排序問題,未來可以借鑒文獻[10,48]中解決重排序問題的方法實現更好的路由。最后,由于無線網絡通信不需要繁瑣的布線且容易改變位置和天線方向,因此可以以綠色節能為優化目標,借鑒文獻[28 - 30]中的方法,實現有線無線混合數據中心能量感知的路由方法。
6 結束語
本文綜述了數據中心網絡路由技術的研究發展現狀,通過對數據中心網絡路由模型進行分類比較,討論了近年來數據中心網絡路由方法的相關研究。本文重點關注數據中心網絡單播路由方法,分別從拓撲結構相關的路由方法、流量相關的路由方法和能量感知的路由方法3個角度,列舉分析了現有的研究工作,并使用合理的評價指標對其進行比較。并進一步介紹了擁塞感知的負載均衡路由方法,通過對現有研究工作的整理分析,比較展示了擁塞感知路由方法的一些重要研究成果,為未來的研究提供了思路。最后,介紹了新型數據中心網絡——基于光交換的數據中心網絡和有線無線混合的數據中心網絡,對2種數據中心網絡路由技術的難點和技術途徑進行了分析,闡述了對未來該領域研究方向的一些認識與理解。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
