基于可見光視覺圖像的路面裂縫識別深度學習方法述評*
2022-04-21 05:07:02盧凱良
計算機工程與科學 2022年4期
盧凱良
(江蘇自動化研究所,江蘇 連云港 222061)
1 引言
結構裂縫(或稱裂紋)不可避免地廣泛存在于土木建筑、交通運輸和工程機械等諸多行業的各類建造物、結構、零部件或制品中。針對工程結構中的裂縫檢測或監測技術手段主要有:(1)無損探傷技術[1,2],包括射線探傷(如CT)、超聲波探傷(如聲發射[3])、電磁渦流探傷、磁粉探傷和滲透探傷等。無損探傷技術適用于表面、近表面和內部裂縫等全場景,測量精度高;但其是一種主動探測技術,需要發射和接收檢測物理介質并可能依賴于耦合介質,因此相應的檢測設備通常較為復雜,且價格不菲。(2)結構健康監測技術[4],包括基于應力應變信號和基于振動信號等。該技術借助于預先布置的傳感器采集并分析時間歷程信號,對結構有無裂縫進行識別,因是間接測量方式,對內部裂縫的識別和定位精度尚需提高。(3)非接觸式檢測技術,包括紅外、激光和超聲檢測[1 - 3]以及基于可見光視覺圖像的檢測[5 - 18]等。非接觸式檢測技術與前2類技術相比,無需與被測對象直接接觸,具有不受被測對象的材質限制,檢測速度快,易于實現全自動檢測等優點,不足之處是目前僅用于檢測表面裂縫。
基于視覺圖像的表面裂縫識別具有非接觸式檢測的全部優點,物理介質是可見光,無需發射或能見度差時只需補光光源,整個檢測系統成本優勢明顯。借助于傳統手工設計特征工程(Hand- crafted Feature Engineering)、機器學習(Machine Learning)和深度學習(Deep Learning)方法,基于圖像的識別技術可以實現裂縫定性、定位、定量各個層次的目標:(1)判斷有無裂縫,可視為分類(Classification)問題;(2)探測裂縫的位置,可視為檢測/定位(Detection/Location)問題;(3)檢測裂縫的分布、拓撲結構和尺寸,可視為分割(Segmentation)問題,按分割精度可分為區域級/補丁級(region/patch-level)和像素級(pixel-level)。
2 裂縫公開數據集
2.1 概述
本文搜集了土木建筑領域路面裂縫和混凝土裂縫的開源數據集,常見的公開數據集如表1所示。這些數據集中的圖像樣本均是通過個人相機、移動終端攝像頭或車載攝像頭采集的,采集成本低。圖像數目視數據集的使用目的和需求從數十張到數千張不等,圖像分辨率因采集設備而不同,根據后續處理算法的需要可以裁剪為小樣本(region/patch),例如圖像識別深度學習算法中常用的256×256或227×227;還可以通過數據增強進一步增加樣本數。總的來說,相對于ImageNet、Pascal VOC等通用大型數據集而言,本文所搜集的裂縫公開數據集尚屬專門應用領域的小型數據集。

Table 1 Common public crack datasets
2.2 典型裂縫公開數據集
2.2.1 JapanRoad
JapanRoad數據集樣本是從汽車前擋風玻璃處采集的真實道路街景透視圖像,可用于裂縫等8類道路缺陷定位檢測[6],包含163 664幅道路圖像,其中9 053幅圖像含有裂縫,采用與PASCAL VOC相同格式的邊框(bounding box)標注。
2.2.2 SDNET2018
SDNET2018是一個帶補丁級/區域級標注的圖像數據集,可用于混凝土裂縫人工智能檢測算法的訓練、驗證和測試。
原始圖像是利用16 MP Nikon數碼相機拍攝的,包括230幅開裂和未開裂混凝土表面圖像(54座橋面、72面墻壁和104條人行道,均位于猶他州立大學校園內)。
每幅圖像再被裁剪分割為256×256像素的子圖像樣本,共計包含超過56 000個樣本,樣本中包含的裂縫窄至0.06 mm,寬至25 mm。數據集還包括帶有各種障礙和干擾(陰影、表面粗糙度、縮放、邊緣、孔洞和背景碎片等)的圖像樣本,詳見表2和表3。
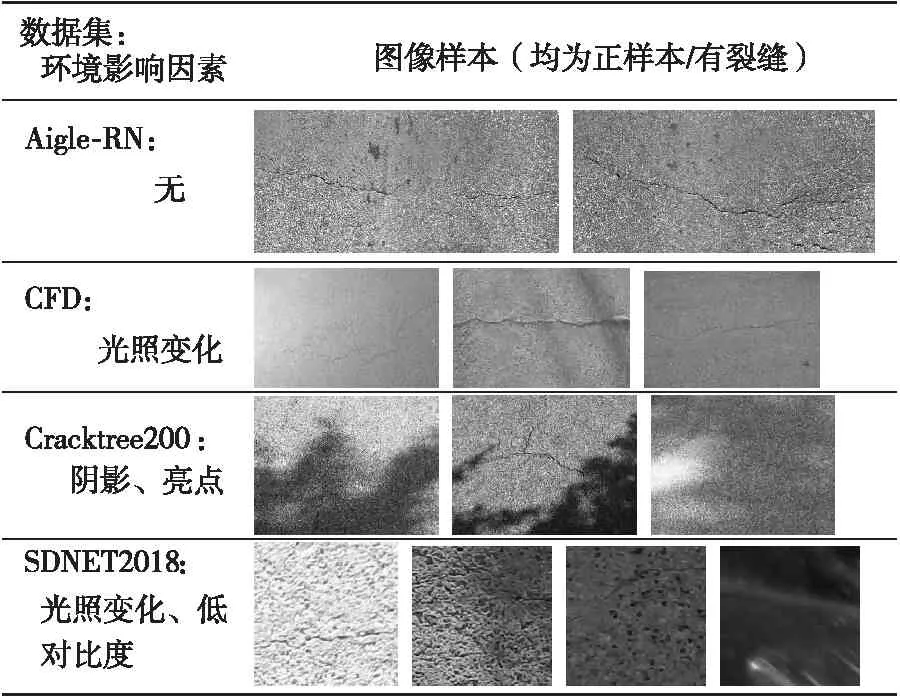
Table 2 Environmental factors in crack datasets
2.2.3 CFD
CFD是反映北京城市路面總體狀況的像素級標注的路面裂縫數據集,是常用基準數據集之一。使用手機(iPhone 5)拍攝采集,共包括480×320分辨率的圖像樣本118個,樣本中包含車道線、陰影和油漬等噪聲或干擾因素。
2.3 數據集圖像樣本中的隨機可變影響因素
數據集中涉及的隨機可變影響因素越多,包含的高級特征越豐富,則經過該數據集訓練和驗證的學習模型在真實測試場景中的泛化能力越強。這些隨機可變影響因素主要包括圖像背景、環境影響以及其他干擾因素,并且在圖像樣本中這些因素通常組合疊加呈現。為了清晰展現,表3中所展示的一組(一行)圖像樣本盡可能體現單一因素。

Table 3 Noise interference factors in crack datasets
2.3.1 背景
JapanRoad數據集中的圖像背景包括汽車、房屋、天空、行人、綠化帶、車道線和電線桿等。CFD數據集中也有少量圖像樣本具有街道實景背景。還有一類干擾背景如油漬、輪胎制動痕跡和斑點等。
2.3.2 環境影響
環境影響主要指由天氣、光照變化引起的亮度變化、陰影、亮點和低對比度等。作為對比,表2列出了不受環境影響的Aigle-RN數據集中的部分樣本(因其裂縫紋理特征較復雜,為減少不均勻照明專門進行了預處理)。
2.3.3 干擾因素
除了背景和環境影響,可變影響因素還包括車道線、油漬/瀝青/濕漬/斑點、井蓋、輪胎制動痕跡、紋理差異、表面粗糙度、邊界、孔洞以及其他雜物等噪聲干擾因素,如表3所示。
3 裂縫識別算法比較
裂縫識別方法可分為傳統手工設計特征工程、機器學習和深度學習3種,各方法中的常見算法及其特點如表4所示。
3.1 傳統手工設計特征工程
傳統手工設計特征工程通常使用邊緣或形態特征檢測算法和特征變換(或濾波)算法。邊緣或形態特征檢測算法包括Canny[7,8]、Sobel[14]、方向梯度直方圖HOG(Histogram of Oriented Gradient)和局部二值模式LBP(Local Binary Pattern)等。特征變換(或濾波)算法包括快速傅里葉變換FFT(Fast Fourier Transform)、快速哈爾變換FHT(Fast Haar Transform)、Gabor濾波器和亮度閾值[8]等。
這些算法借助數學計算方式逐步提取或解析出圖像中對象的邊緣和形態等特征,屬于非學習方法,不依賴于數據集;而且所用數學計算多為解析式,一般來說算法的計算量小、速度快。缺點是對隨機可變因素的泛化能力弱,且易受這些因素的干擾,自適應能力弱,應用場景或環境一旦改變就需調參、重新設計算法甚至方法失效。
3.2 機器學習方法
機器學習和深度學習均為學習類算法,依賴于數據集。不同的是,機器學習方法的數學表達是顯式的、可解釋的,而深度學習是隱式的。一般認為,深度學習(神經網絡的深度或層級更深)面向高維特征,機器學習面向低維特征;機器學習介于傳統手工設計特征工程和深度學習方法之間。
基于常見的機器學習方法例如支持向量機SVM(Support Vector Machine)[7]、決策樹(Decision Tree)和隨機森林(Random Forrest),相應的裂縫識別算法主要有CrackIT、CrackTree和CrackForest[8,10,14 - 17]等。
3.3 深度學習方法
深度學習方法的使用得益于并行計算硬件(GPU/、TPU/等)的飛躍、大規模數據集(ImageNet、Pascal VOC等)的基準催化作用和算法的不斷改進和完善。例如,批標準化(Batch Normalization)、殘差連接(Residual Connection)和深度可分離卷積(Depth Separable Convolution)是從2012年起開始聲名卓著的。雖然深度學習方法尚存在“黑箱”和解釋性問題,不可否認其在計算機視覺、自然語言處理和強化學習等領域取得的最新進展甚至超越人類水平的成績。目前科學家們正在理論攻關[18],工程師們也通過可視化技術不斷提升深度學習過程的可解釋性[19]。
卷積神經網絡CNN(Convolutional Neural Network)因其能學到的模式具有平移不變性(translation invariant)并且可以學到模式的空間層次結構(spatial hierarchies),自2012年始在計算機視覺識別等領域不斷取得突破性進展。基于CNN的圖像識別深度學習方法具有特征自動提取、泛化能力強和精度高等優點。按深度學習方法的不同范式,各類算法又可分為自搭架構、遷移學習、編碼-解碼器、生成對抗網絡及其他算法。

Table 4 Typical crack identification algorithms and their characteristics
自搭架構是依據CNN的一般設計原則,針對應用場景的特定數據集來設計和搭建的模型架構,如早期的ConvNet[7]、Structured-Prediction CNN[8]和近期的CrackNet/CrackNet-V[9,10]。這類算法具有對特定應用場景適應性好、模型小和參數少等優點,但泛化能力一般,且模型往往未經優化。

Figure 1 Illustration of ConvNet architecture [7]
遷移學習是利用在大規模通用數據集上預訓練的模型架構優化過的CNN主干網絡(backbone)學習到可移植的底層特征,再在專門數據集上微調高層和/或輸出層的神經網絡連接權重,以期學習到面向專門數據集的高維特征。遷移學習適用小型數據集問題,訓練快、易調整、泛化好。
編碼-解碼器由編碼器和解碼器組成。在CNN中,編碼器用于產生具有語義信息的特征圖;解碼器將編碼器輸出的低分辨率特征圖像映射回原始輸入圖像尺寸,從而可以逐個像素分類。編碼-解碼器適用于弱監督和小型數據集情形,其代表模型FPCNet(Fast Pavement Crack detection Network)[15]精度和速度俱佳。
生成對抗網絡利用2個網絡(判別網絡和生成網絡)對抗訓練,使生成網絡產生的樣本服從真實數據分布。ConnCrack(combining cWGAN & connectivity maps)[14]和CrackGAN(pavement Crack detection using partially accurate ground truths based on GAN)[16]是裂縫識別的代表性模型。生成對抗網絡識別精度高,還可用于難例挖掘。早期版本訓練和預測時間較長[14],改進的CrackGAN[16]在前期GAN算法基礎上,提出了僅基于裂縫補丁樣本CPO(Crack-Patch-Only)的監督對抗學習和非對稱U-Net網絡架構,可在人工半精確標注(1像素曲線標注)樣本上進行端到端訓練,并在全尺寸圖像上進行裂縫分割預測;還引入了遷移學習算法訓練編碼器原型網絡,以及從預先訓練的深度卷積生成對抗網絡中遷移知識,以提供端到端訓練中所產生的對抗性損失。CrackGAN[16]率先解決了裂縫和背景樣本數嚴重不平衡引發的“全黑”問題,計算效率大幅提升,減輕了標注工作量。
其他算法還包括FPHBN(Feature Pyramid and Hierarchical Boosting Network)[17],該算法融合了特征金字塔和分層增強等技術,模型架構與FPCNet[15]的類似。
4 裂縫識別深度學習方法進展
4.1 自搭架構
4.1.1 ConvNet
(1)數據集。
所用數據集包含500幅分辨率為3 264×2 448的原始圖像,裁剪生成包含640 000個樣本的訓練集、包含160 000個樣本的驗證集、包含200 000個樣本的測試集,樣本分辨率均為99×99,標注精度為補丁級。數據集未公開。
(2)網絡架構。
網絡架構比較簡單,包括4個卷積conv(convolution)層(4×4,5×5,3×3,4×4)和2個全連接層fc(fully connection),每個卷積層后都有最大池化層mp(max pooling),如圖1所示。
(3) 性能衡量指標。
樣本測試的準確度度量指標主要有:

(1)

(2)

(3)
(4)
其中,TP(True Positive)表示真陽例的數量,TN(True Negative)表示真陰例的數量,FP(False Positive)表示假陽例的數量,FN(False Negative)表示假陰例的數量,Total=TP+FN+FP+TN為總樣本數。由式(4)可知,F1-score是Precision和Recall的加權調和平均數。
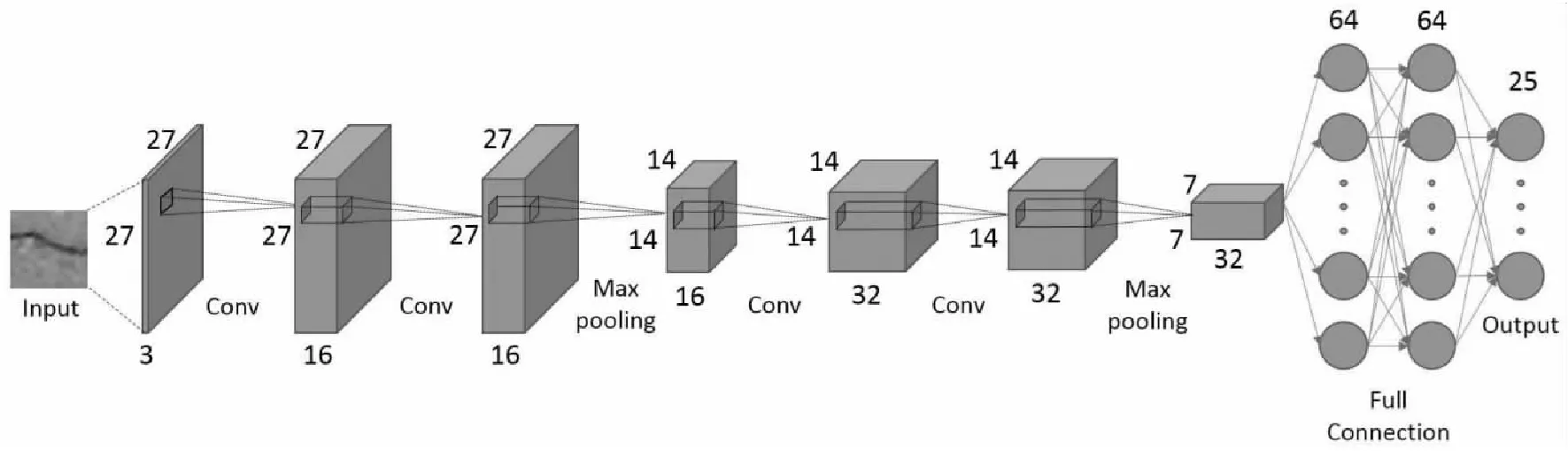
Figure 3 Architecture of Structured-Prediction CNN[8]
(4) 性能與效果。
ConvNet[7]的測試精確率、召回率和F1-score分數分別為0.869 6,0.925 1和0.896 5,均高于SVM和提升(Boosting)算法的,測試效果對比如圖2所示。無論在準確度度量指標還是在識別效果上,ConvNet[7]都明顯優于傳統機器學習方法。由于屬早期探索性研究,ConvNet[7]只關注了測試準確度,還未涉及測試速度。

Figure 2 Test performance of two samples[7]
4.1.2 Structured-Prediction CNN
(1)數據集。
Structured-Prediction CNN[8]同時關注了測試準確度和速度,為了形成基準比較,在數據集Aigle-RN上進行了測試,還專門構建了CFD數據集。
(2) 網絡架構。
如圖3所示,輸入樣本為3通道的27×27的彩色圖像,其他立方體塊表示通過卷積或最大池化運算得到的特征圖,最后連接2個全連接層和1個輸出層。
(3) 性能表現。
在準確度上,表5和表6中的結果再次印證了深度學習CNN方法總體上比機器學習(如CrackForest)表現更優,且遠好于傳統手工設計特征工程方法(如Canny,Local thresholding)。
在預測速度上,原始圖片在NVIDIA GTX 1080Ti GPU上可達到2.6 fps。
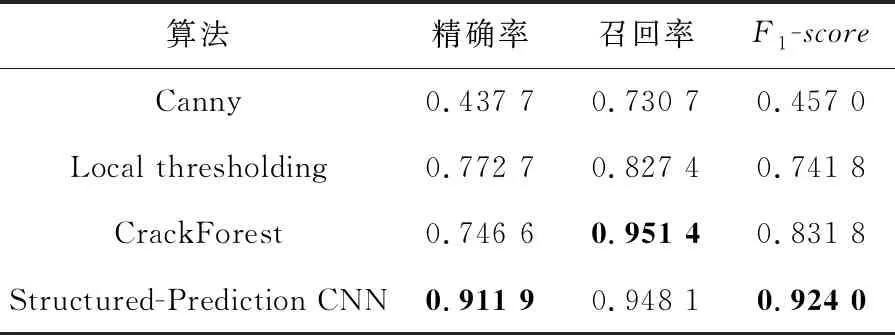
Table 5 Crack detection results of different methods on CFD

Table 6 Crack detection results of different methods on Aigle-RN
(4) 檢測效果。
Structured-Prediction CNN[8]采用了27×27的小尺寸輸入,且CFD和Aigle-RN均對裂縫進行了像素級標注(2個像素誤差),裂縫檢測效果遠好于ConvNet[7],已用于鱷魚皮狀裂紋的檢測,檢測效果如圖4所示。

Figure 4 Results comparison on CFD and Aigle-RN[8]
4.1.3 CrackNet/CrackNet-V
(1) 數據集。

Figure 5 Architecture of CrackNet[9]
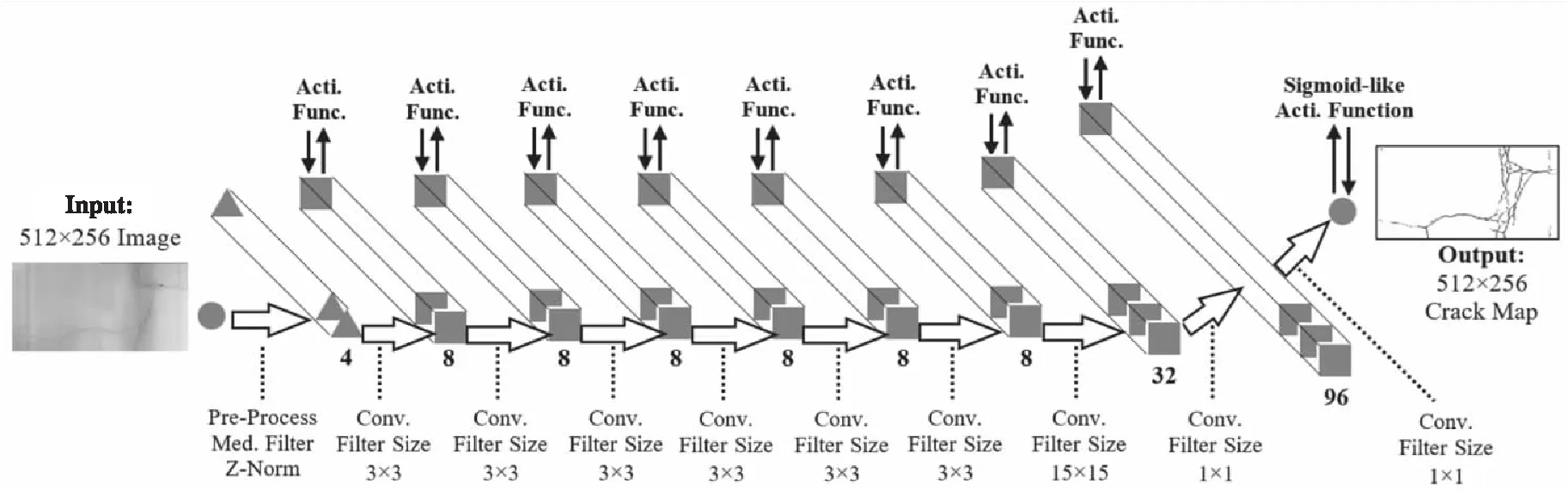
Figure 6 Architecture of CrackNet-V[10]
與之前算法不同的是,CrackNet / CrackNet-V[9,10]使用激光掃描獲得的3D瀝青路面圖像作為輸入。相比可見光攝像頭采集的圖像,激光掃描圖像分辨率更高,可過濾部分噪聲,相當于做了一次圖像預處理,因而圖像更加清晰,可以實現像素級裂紋標注和分割。因此,不僅僅是可見光攝像頭,激光掃描、紅外攝像頭甚至聲發射等無損穿透式檢測或監測傳感器采集得到的圖像或信號,均可作為深度學習網絡的輸入,從而不僅可以檢測表面裂縫,亦有望探測或監測被測物內部裂縫。
3D瀝青路面圖像數據集包括訓練集的2 568個圖像樣本、驗證集的15個典型圖像樣本和測試集的500個圖像樣本。CrackNet[9]輸入樣本的分辨率為1 024×512,CrackNet-V[10]輸入樣本的分辨率為512×256。
(2)網絡架構。
CrackNet[9]網絡架構如圖5所示,包括輸入層、2個卷積層(卷積核(Filter Size)分別為50×50和1×1)、2個全連接層和輸出層;卷積層激活函數(Activation Function)為Leaky ReLU,輸出層為Sigmoid,共計1 159 561個參數。
CrackNet-V[10]網絡架構如圖6所示,增加了預處理(Pre-Process)層,包括中值濾波(Med-Filter)和Z標準化(Z-Norm)。總體上借鑒了VGG模型架構,大量采用3×3卷積,增加了1個15×15卷積層和2個1×1卷積層,比CrackNet[9]的層數更深,由于沒有全連接層且卷積核更小,參數反而更少,模型更輕量化。
CrackNet[9]和CrackNet-V[10]均無池化層,輸入和輸出圖像的分辨率不變,故可用于實現像素級分割。
(3) 性能表現。
對比表7和表8可知,在準確度上,CrackNet-V[10]比CrackNet[9]略高;在運算速度上,無論訓練和測試(前饋和反饋運算)時長,前者約為后者的1/4,證實了CrackNet-V[10]的架構更優化。
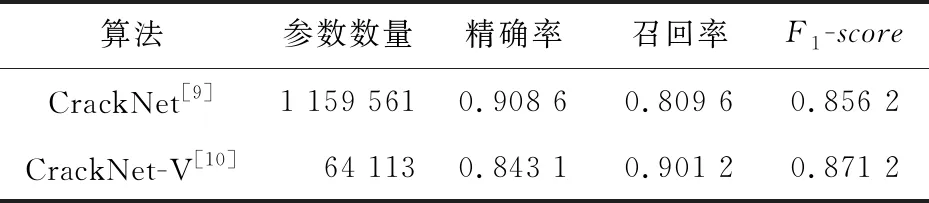
Table 7 Test results comparison between CrackNet and CracNet-V

Table 8 Speed comparison between CrackNet and CrackNet-V

Figure 8 Framework and steps of deep(transfer) learning
(4)檢測效果。
CrackNet-V[10]對鱷魚皮狀細裂縫的檢測效果如圖7所示。因為模型架構的特殊優化設計,CrackNet-V[10]可以實現完美像素級裂紋分割;另一方面,檢測速度也非常快,在NVIDIAGTX1080TiGPU上測試速度約為0.33s/img,與Structured-PredictionCNN[8]的速度相當。

Figure 7 Crack detection results of CrackNet-V[10]
4.2 遷移學習
4.2.1 遷移學習的框架和步驟
學習方法的一般步驟包括訓練(Train)、驗證(Validation)、測試(Test)和預測(Predict)。圖8展示了深度(遷移)學習的框架和步驟。
遷移學習主要包含以下步驟:
(1)在預訓練的基礎網絡上添加自定義的神經網絡層。基礎網絡由主干網絡(常見的如VGG-16[11]、VGG-19[14]、Inception-V3[12]、Xception[13]、Resnet152[14]等)及其在大規模數據集上預訓練的權重參數值組成。
(2)凍結基礎網絡。
(3)在專門的數據集(如SDNET2018/CCIC)上訓練所添加的自定義頂層。
(4)解凍基礎網絡中的某些層。
(5)聯合訓練未凍結的層和所添加的自定義頂層。
步驟(2)~步驟(5)又統稱為微調(Fine-tuning)。
最后,如果滿足預設目標,就輸出新的網絡模型和微調后的權重參數值,用于部署并預測待預測的圖像樣本,輸出概率值和類別;如果不滿足,可通過增大數據集、重選主干網絡和解凍更多層等措施來重新執行遷移學習過程,從而優化神經網絡模型和權重參數,直至滿足預設目標。
4.2.2 基準測試結果和性能比較
考慮到精度和效率的折衷以及在低算力平臺上的測試部署,本文重點選擇了InceptionV3和MobileNetV1/V2在CCIC和SDNET2018數據集上進行性能測試,并與相關文獻成果進行比較,結果如表9所示。由于表9用于性能比較的參考文獻裂縫數據集有些未公開(盡管類似),且計算平臺不盡相同,故本表中的性能比較并非完全嚴格,僅供參考。預測耗時含圖像載入、預處理等時間。從表9中可知:
(1) 應用遷移學習法對裂縫圖像分類,測試分類精度已超過ImageNet多分類基準線(參見https://github.com/mikelu-shanghai/Typical-CNN-Model-Evolution);在相近的分類比數據集(如CCIC)上,其結果也優于當前已公開發表的成果[11,12,20]。在人眼易辨識的CCIC數據集上,使用輕量級主干網絡MobileNetV1遷移學習的精度達到99.8%。
(2)TL-InceptionV3在人眼難辨識的SDNET2018數據集上的測試精度為96.1%,已較為接近FPCNet[15]的最佳水平97.5%(可用更重量級的主干網絡進一步提高遷移學習的精度),測試耗時16.1ms,遠低于FPCNet的67.9ms(測試平臺均為NVIDIAGTX1080TiGPU)。
4.3 編碼-解碼器(FPCNet)
以上算法存在2點不足之處:
(1)路面裂縫具有不同的寬度和拓撲,但是CNN/FCN方法的過濾器感受野僅使用特定大小的卷積核(kernel)來提取裂縫特征(特別是VGG之后的模型大量采用3×3),限制了其對裂縫檢測的魯棒性。
(2)未考慮裂紋的邊緣、模式或紋理特征對檢測結果的貢獻不同。
編碼-解碼器模型FPCNet[15]即是針對這2點不足設計的。
(1) 數據集。
FPCNet使用的測試數據集為CFD(樣本裁剪為288×288)和G45(樣本裁剪為480×480)。
(2) 網絡架構。
FPCNet[17]網絡架構包括多重膨脹MD(Multi-Dilation)模塊和擠壓-激發上采樣SEU(SqueezingandExcitationUp-sampling)模塊。多重膨脹MD模塊如圖9所示,該模塊級聯4個膨脹率分別為1,2,3和4的膨脹卷積通道(每通道2次膨脹卷積核操作)、1個全局池化層+1×1卷積+上采樣通道和原始的裂縫多層卷積MC(Multiple-Convolution)特征。之后,執行1×1卷積以獲得裂縫多層膨脹卷積特征。除了最后的1×1卷積,每個卷積都保留其特征通道的數量,并且使用填充來確保MC特征的分辨率恒定。
SEU模塊如圖10所示,H、W和C分別表示特征的長度、寬度和通道數。輸入的是MD特征和MC特征,輸出的是經過加權融合優化后的MD特征。
SEU模塊首先通過轉置卷積來恢復裂紋MD特征的分辨率,之后將MC特征添加到MD特征中,以便融合邊緣、模式和紋理等的相關裂紋信息,接下來執行全局池化以獲得C個信道的全局信息。
隨后,在經過對全局信息擠壓(Squeezing)和激發(Excitation)2個完全連接層后,通過學習獲得每個特征在其通道中的權重,從而使得SEU模塊可以為不同的裂縫特征(例如邊緣、模式和紋理)自適應地分配不同的權重。

Table 9 Test results and performance comparison of some typical backbone network
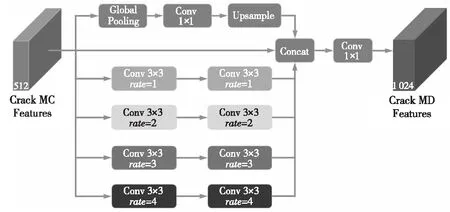
Figure 9 MD module [15]
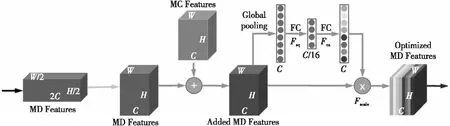
Figure 10 SEU module[15]
最后,將添加MC后的MD特征中的每個特征與其對應的權重(Fscale)相乘,以獲得優化的MD特征。
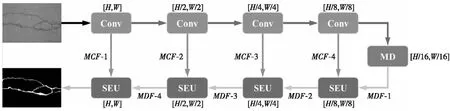
Figure 11 Overall architecture of FPCNet [15]
FPCNet[15]網絡的整體架構如圖11所示,該網絡使用4個卷積層(2個3×3卷積+ReLU)和最大池化作為編碼器來提取特征。接下來,使用MD模塊來獲取多個上下文大小的信息。隨后,將4個SEU模塊用作解碼器。圖11中,上排左數第2至第5個箭頭表示最大池化;下排右數第1至第4個箭頭表示轉置卷積,最后1個箭頭表示1×1卷積+Sigmoid;MCF表示在編碼器中提取的MC特征,MDF表示MD特征。
(3)性能表現。
在CFD數據集上的裂縫檢測結果如表10所示,FPCNet[15]的各項評估指標均優于機器學習、CNN等方法,是目前最新的網絡之一。FPCNet[15]的預測速度也較快,在NVIDIA GTX1080Ti GPU上單幅288×288的圖像樣本預測耗時67.9 ms即14.7 fps,能實現實時檢測。
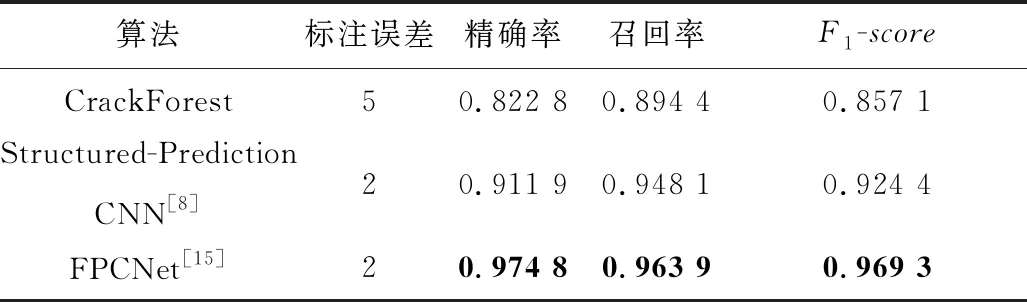
Table 10 Results for crack detection on CFD[15]
(4) 檢測效果。
FPCNet[15]與Structured-Prediction CNN[8]等在CFD數據集上的檢測效果比較如圖12所示,這2個網絡以及CrackNet/CrackNet-V[9,10]均能達到像素級精度的裂縫檢測(標注精度2個像素誤差)要求。FPCNet[15]正如其架構設計初衷,對諸如鱷魚皮狀等各類復雜形態裂縫的邊緣、紋理和細部的識別精確度較高。

Figure 12 Results comparison of proposed approach with Structured-Prediction CNN on CFD[15]
5 結束語
目前,研究人員已經能夠基于單一模型在低算力GPU平臺上實現裂縫補丁級實時檢測和像素級快速檢測。基于InceptionV3的遷移學習和編碼-解碼器FPCNet對單一測試樣本檢測總耗時低于100 ms,基于MobileNet更可低于10 ms;在準確度上,在人眼易辨識的CCIC數據集上測試精度可達到99.8%以上;在難辨識的SDNET2018數據集上,遷移學習算法最高接近96.1%。利用集成上述算法的集成方法還可進一步提高測試準確度。
對于工程結構中的裂縫檢測或識別問題,相較于無損探傷技術和健康監測技術等接觸式檢測方式,基于可見光視覺圖像的表面裂縫識別非接觸式檢測方法,可充分發揮其不受被測對象的材質限制、成本低、精度高和易于實現全自動在線檢測等優勢,因而適用于例行巡檢等預防性檢測或監測、幾何拓撲形式可抽象為2D平面形態的物體缺陷檢測等場景。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
