基于集成學習的風險預測模型研究與應用
2022-04-21 08:01:20張文靜郭瑩瑩
計算機工程與設計 2022年4期
彭 巖,馬 鈴,張文靜,李 曉,郭瑩瑩
(首都師范大學 管理學院,北京 100056)
0 引 言
隨著人工智能的快速發展,機器學習技術廣泛應用于疾病的風險預測,預測的模型從簡單到復雜,逐步由單一模型發展為集成模型[1]。基于機器學習算法,研究者提出一系列經典的疾病預測模型。Yan Jianzhuo等[2]構建Random Forest模型、張春富等[3]構建XGBoost模型進行糖尿病風險預測,為糖尿病的診斷、篩查提供了科學指導。同時,基于回歸分析[4]、神經網絡[5]的模型在糖尿病及其并發癥的預測中均取得良好的預測精度。但單一的機器學習算法在樣本多、指標復雜的疾病數據中,存在泛化差、精度低等弊端。隨著大數據、云計算技術的發展,基于集成學習算法,結合患者的多項檢查指標來構建疾病風險預測模型,是近年來疾病預防的研究熱點。Chen P等[6]構建LogitBoost模型,驗證了基于Boosting的集成算法對糖尿病早期篩查具有重要意義。Syna Sreng等[7]、吳健等[8]基于Bagging算法構建糖尿病眼病集成預測模型,為糖尿病眼病的早期篩查提供了有效手段。
基于此,本研究提出一種基于差異性大、性能好的XGBoost、Random Forest算法的集成預測模型,并應用在糖尿病并發視網膜病變的研究,旨在解決單一預測模型精度提升有限、泛化性能較低的問題,為醫生臨床實踐中對類似疾病的風險評估提供有效輔助,從而有效減少嚴重后果的產生及診治費用。
1 相關算法描述
1.1 Logistic回歸模型
Logistic回歸[9]是一種廣義線性回歸分析模型,按因變量的類型,可分為二分類Logistic回歸和多分類Logistic回歸。由于因變量只有患病與不患病兩種情況,因此采用二分類Logistic回歸。該模型可用于尋找發生某種疾病的關聯因素、確定不同因素對疾病發生影響的相對重要程度以及預測在不同自變量下發生該病的概率。Cox回歸模型[10]引入Logit變換,建立以Logit(P)為因變量擁有p個自變量的Logistic回歸模型如式(1)所示
Logit(P)=β0+β1x1+…+βpxp
(1)
1.2 XGBoost模型
XGBoost模型也稱為極端梯度提升樹模型,由Chen等[11,12]基于GBDT改進而來,是一種通過Boosting思想將基函數與權重進行組合形成的集成學習算法。它將多棵樹的預測結合在一起,將每個樹的預測分數相加以得到最終分數,算法步驟如下:
步驟1 確立優化目標。
步驟2 二階泰勒展開和移除常數項操作。
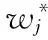
1.3 Random Forest模型
隨機森林是樹結構分類器組成的集合[13],它可以使用ID3、C4.5、CART等[14]決策樹算法作為基本分類器。隨機森林基本思想可以概括為:在給定原始樣本集和輸入向量X的情況下,采用Bootstrap重抽樣方法從初始樣本集中抽取特定份額的樣本,對每個樣本建立決策樹模型,從而得到不同的分類結果。每個決策樹分類器通過對不同分類結果投票來決定最優的分類結果。在分類問題中,Random Forest的組合模型可以表示為式(2)
(2)
1.4 XGB-RF預測模型
模型集成是一種通過增加算法的多樣性、減少泛化誤差來提高模型效能的有效手段。Random Forest是Bagging型算法,XGBoost是Boosting型算法。Bagging主要關注降低方差,而Boosting主要關注降低偏差。這是兩種完全不同的機器學習算法,具有差異性大、性能好等特點。集成學習需針對實際問題設計合適的學習方案,才能得到性能更優的解決策略。本研究受到Stacking融合的啟發,基于單一的Random Forest、XGBoost模型,設計一種XGB-RF集成預測模型,并在糖尿病數據集上進行仿真實驗,構建過程如圖1所示,算法描述如下:
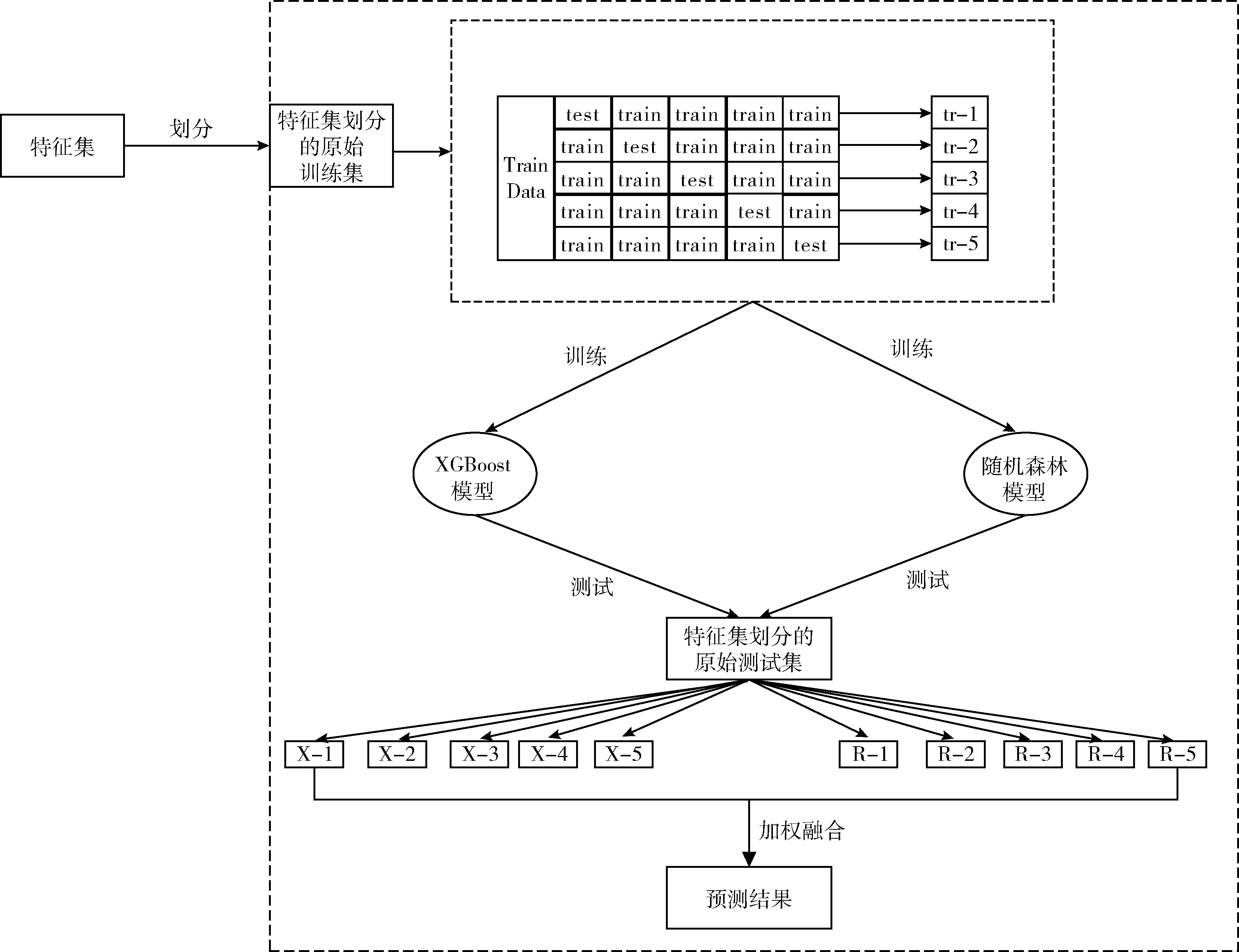
圖1 XGB-RF模型構建過程
步驟1 特征集劃分。在Pearson 相關系數單因素分析的基礎上,利用多因素 Logistic 回歸算法提取影響糖尿病并發視網膜病變的顯著特征。經特征篩選后,將僅含特征變量的數據整理為特征集,并進行特征集的劃分,數據集中75%的數據作為訓練集記為Train Data,余下的25%作為測試集記為 Test Data。
步驟2 單一模型訓練。使用步驟1中劃分的特征集訓練XGBoost模型和Random Forest模型,采用網格搜索算法優化模型的參數。
步驟3 單一模型五折交叉驗證。對單一模型進行五折交叉驗證,每一次交叉驗證需對原始訓練集(Train Data)進行劃分,每次選取4折作為訓練集記為train,余下1折為測試集記為test,將得到5個訓練后的RF模型,5個XGBoost模型,并在原始測試集(Test Data)上進行預測。因此,每個模型將生成5個針對原始測試集的預測數據,即X-1…X-5,R-1…R-5。此外,在單一模型參數的基礎上,搜索集成模型的最優參數。
步驟4 輸出預測結果。由于隨機森林模型的預測結果優于XGBoost模型,對步驟3中輸出的10個預測結果進行加權融合時,XGBoost模型的權重設置為1.7,Random Forest模型的權重設置為2,相乘后取相對平均作為最終預測結果。
2 實驗過程
2.1 數據來源
為了驗證模型的有效性,本研究基于糖尿病并發視網膜病變數據進行仿真實驗。該數據來自國家人口健康科學數據共享服務平臺的糖尿病數據集,該數據集包含7499例個案。研究基于Pearson相關系數單因素分析的結果[15],采用多因素Logistic回歸模型進行直接關聯因素分析,共篩選出11個關聯因素,即全血糖化血紅蛋白、丙氨酸氨基轉移酶、尿素、肌酐、葡萄糖、尿白細胞、尿膽原定性實驗、尿紅細胞、尿酵母細胞、尿酮體實驗、尿濁度。將以上11個因素的數據進行合并,形成集成模型輸入的特征集。
2.2 模型評價標準
模型用于預測糖尿病并發視網膜病變的患病情況,針對的是一個二分類問題,因此采用ACC、AUC、Precision這3個指標進行模型的評價。ACC是正確率,反映了樣本中獲得正確分類的樣本占全部分類樣本的比例。AUC(area under curve)是ROC(receiver operating characteristic curve)曲線下的面積,一般用于評價一個分類器的性能。Precision為精準率,反映預測為正的樣本占所有樣本的比重。ACC與Precision的公式如下
(3)
(4)
其中,TP代表將正類預測為正類的樣本個數,FN代表將正類預測為負類的樣本個數,FP代表將負類預測為正類的樣本個數,TN代表將負類預測為負類的樣本個數。
2.3 模型調參
算法參數的確定直接決定機器學習模型的預測效能,常用的調參方法有專家經驗法以及網格搜索法[16]。GS算法[17],即網格搜索法,是一種通過遍歷既定參數組合來優化模型性能的方法,其原理是在一定的范圍內,通過對待搜索參數劃分成的網格的所有可能取值進行遍歷的方式來計算相應的實驗結果,最優參數即為最佳實驗結果獲取的對應參數。
2.4 預測模型的構建
2.4.1 XGBoost模型的構建
XGBoost模型有眾多參數,不同參數有不同功能,這些參數設定是否合理,對于模型的好壞有重要影響。基于Python平臺建立XGBoost模型,根據前人研究經驗,將樹的個數(n_estimators)設置在10~1000的區間,采用GS算法,每隔50個單位進行一次參數搜索,并繪制n_estimators與預測準確率的折線圖,由圖2(a)可知,將n_estimators設置為60時,ACC出現最大值。
在參數調節中,某些參數存在相互影響,需要對其進行聯合調參。將樹的最大深度(max_depth)設置在3~10的區間,最小葉子節點權重和(min_child_weight)設置在1~6的區間,每隔1個單位進行一次參數搜索,實驗結果表明,max_depth設置為4,min_child_weigh設為3時,ACC最高。其次,將最小損失函數下降值(gamma)設置在0~0.5的區間,采用GS算法進行參數搜索,并繪制gamma與預測準確率的折線圖,由圖2(b)可知,將gamma設置為0.3時,ACC出現最大值。此外,將隨機采樣比例(subsample)和隨機采樣的列數的占比(colsample_bytree)設置在0.5~1的區間進行參數搜索,實驗結果表明,subsample設置為0.8,colsample_bytree設為0.5時,ACC最高。除此之外,將模型的學習率(learning_rate)設置為0.05。
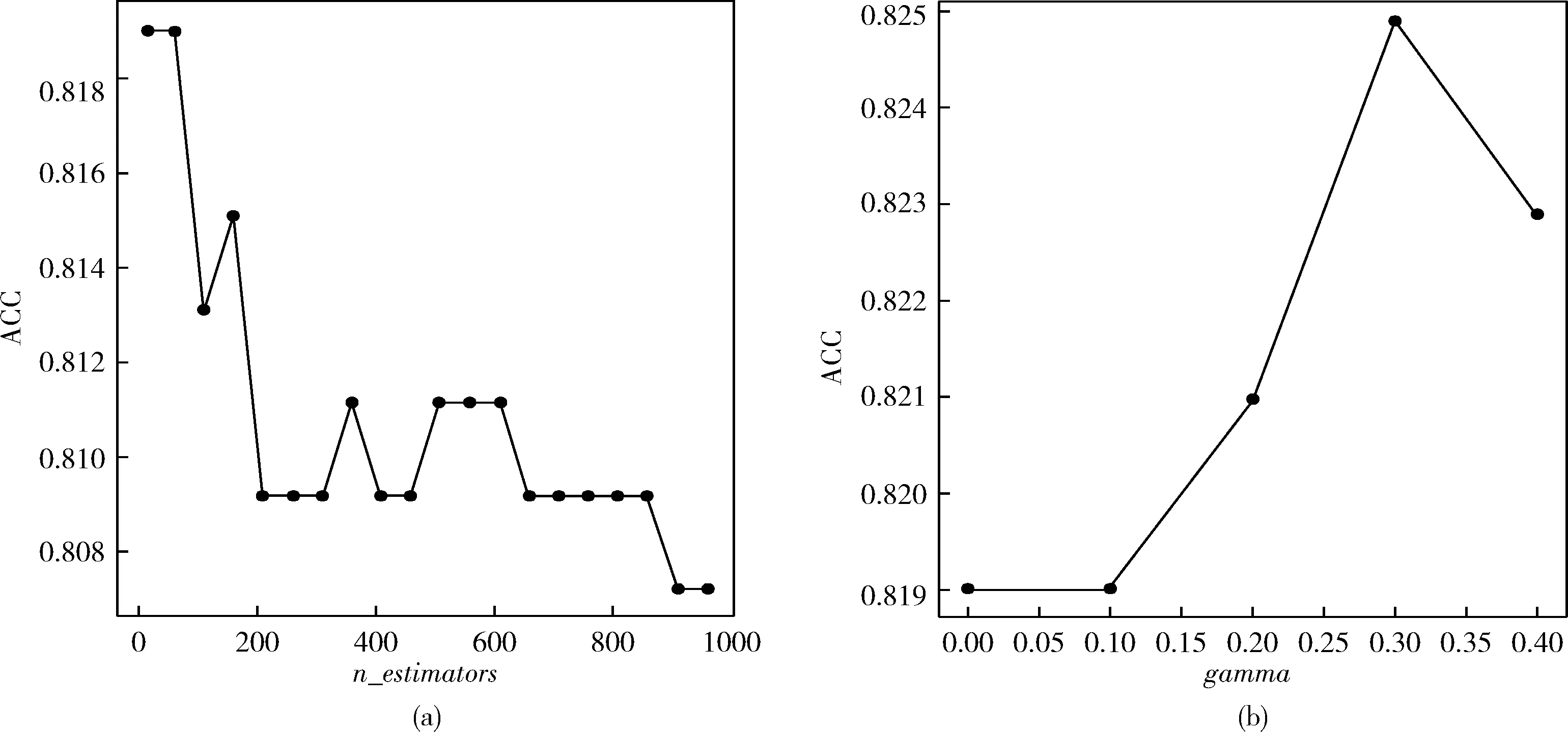
圖2 XGBoost模型參數與ACC變化曲線
2.4.2 Random Forest模型的構建
Random Forest模型基于Python平臺進行構建。首先需確定森林中樹的數量,即確定樹的個數(n_estimators),該參數主要用于降低整體模型的方差。將n_estimators設置在1~500的區間,采用GS算法,每隔10個單位進行一次參數搜索,繪制n_estimators與預測準確率的折線圖,由圖3(a)可知,將n_estimators設置為291時,ACC出現最大值。criterion即節點劃分標準,將criterion設置為“gini”和“entropy”,圖3(b)表明gini指數效果更優。
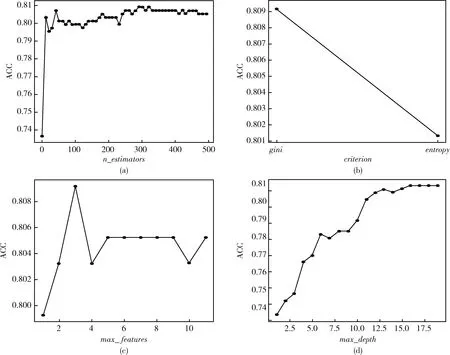
圖3 Random Forest參數與ACC變化曲線
將最大特征數(max_features)設置在1~15的區間,每隔1個單位進行一次參數搜索,由圖3(c)可知,將max_features設置為3時,ACC出現最大值。將樹的最大深度(max_depth)設置在1~20的區間,每隔1個單位進行一次參數搜索,由圖3(d)可知,將max_depth設置為16時,ACC出現最大值。max_features和max_depth存在相互影響,需要對其進行聯合調參。根據先前實驗,將max_features設置在6~15的區間,max_depth設置在12~20的區間,每隔1個單位進行一次參數搜索,實驗表明,max_features設置為11,max_depth設為13時,ACC最高。
2.4.3 XGB-RF模型的構建
在XGB-RF模型的構建過程中,將特征集作為輸入數據集,基于XGBoost模型和Random Forest模進行XGB-RF模型的訓練和預測。為了提高XGB-RF模型的預測效果,在單一模型最優參數的基礎上,對XGB-RF模型的參數進行了調整,各參數具體數值見表1。
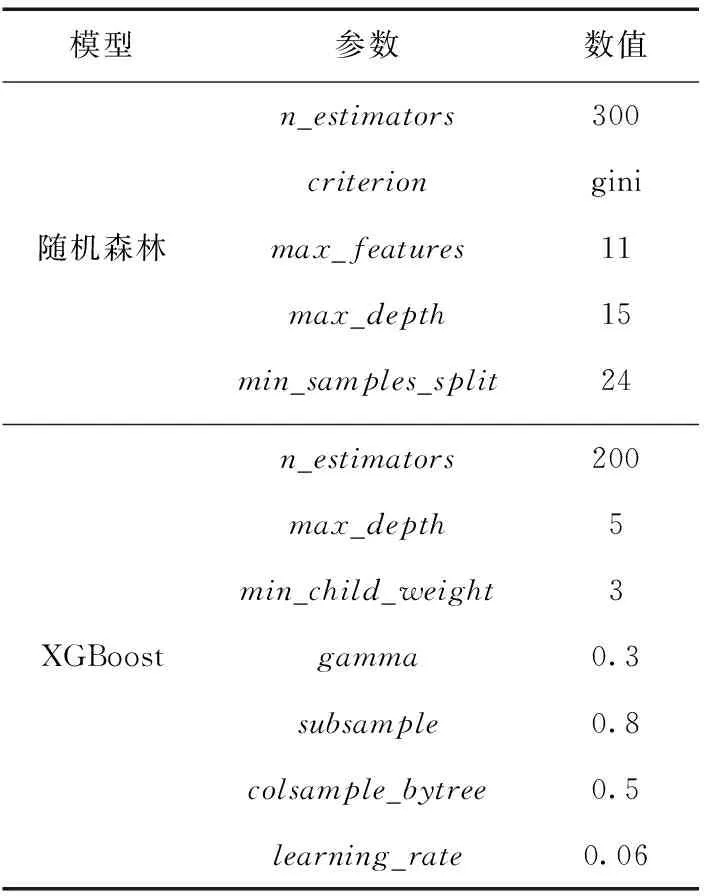
表1 XGB-RF模型參數
3 對比實驗與分析
為了驗證XGB-RF模型的有效性,本研究利用國家人口與健康科學數據共享服務平臺提供的糖尿病患者數據集進行了仿真實驗,并設置了兩組對比實驗:
(1)采用GS算法優化的XGB-RF模型與使用默認參數的XGB-RF模型的對比;
(2)構建的XGB-RF模型與使用傳統XGBoost以及Random Forest單一算法對比。
3.1 模型參數優化對比分析
為驗證通過GS算法優化參數的有效性,取10次實驗的預測結果的均值,將使用默認參數的XGB-RF模型預測結果與使用GS算法優化參數后的XGB-RF模型的預測結果進行了對比,對比結果見表2。
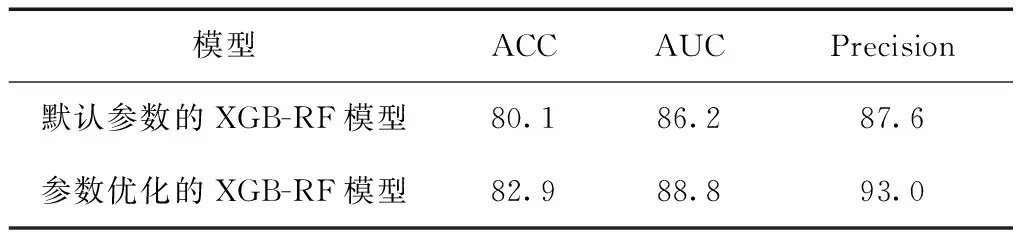
表2 模型參數優化對比/%
由表2可知,運用GS算法進行參數優化后,XGB-RF模型的ACC、AUC、Precision值均顯著提高,表明使用GS算法優化的XGB-RF模型能夠更好預測糖尿病并發視網膜病變。
3.2 XGB-RF模型與單一模型對比分析
為了驗證XGB-RF集成模型的預測效能,取10次實驗的預測結果的均值,將XGB-RF融合模型的預測效果與XGBoost以及Random Forest單一算法進行了對比研究,對比實驗結果見表3。
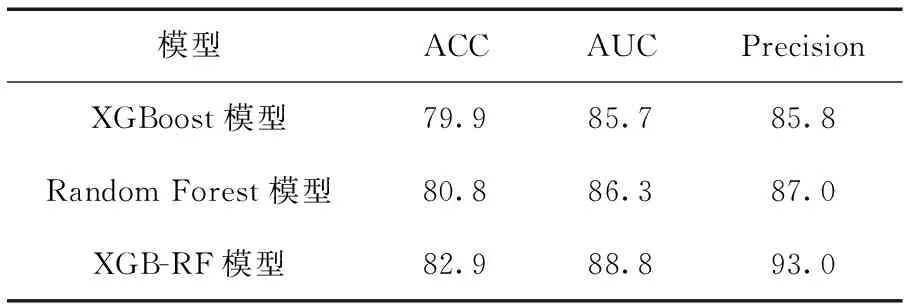
表3 模型結果對比情況/%
在Random Forest模型、XGBoost以及XGB-RF模型的構建中,均將11個特征作為輸入變量。表3、圖4是各模型預測效果的對比結果。由表3可知,與單一模型相比,XGB-RF模型的ACC增加了2.1%~3%,AUC增加了2.5%~3.1%,Precision增加了6%~7.2%。
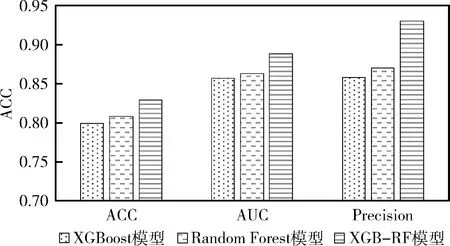
圖4 模型結果對比
綜上所述,就模型的分類預測效能而言,XGB-RF模型具有良好穩定性和較高預測準確性,針對糖尿病并發視網膜病變具有更高的預測精度,彌補了單一模型的弊端。此外,運用GS算法對模型參數進行的優化工作,使得模型預測效能有效提升。
4 結束語
本文構建了一種基于XGBoost模型、Random Forest模型融合的XGB-RF預測模型,提出了一種提高疾病預測準確率的集成學習方法。為了驗證所提方法的性能,與單一模型進行了對比實驗研究,實驗結果表明,與Random Forest模型、XGBoost模型相比,XGB-RF模型在糖尿病并發視網膜病變的預測中具有較高的準確率和分類效能,預測的結果均高于80%,AUC和Precision高于85%,驗證了本文方法的可行性。XGB-RF模型還可以用于糖尿病其它并發癥的輔助預測與診斷,同時,能夠廣泛識別和處理其它回歸預測和分類問題。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
少先隊活動(2021年4期)2021-07-23 01:46:22
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
