基于神經網絡模型的電子病歷文本提取及質量缺陷分析
2022-04-25 05:53:48曹新志沈君姝袁雪王澤川胡欣馬存寧王至誠王杰
中國醫療設備 2022年4期
曹新志,沈君姝,袁雪,王澤川,胡欣,馬存寧,王至誠,王杰
江蘇省中西醫結合醫院 a. 信息中心;b. 設備科,江蘇 南京 210028
引言
醫院的電子病歷是醫院進行醫療服務的憑證,全面記錄了在醫院進行的所有醫療工作[1],反映了對患者疾病診斷、治療和轉歸的全過程,不僅充分體現了醫療質量,也是保障醫療安全的重點[2],同時也是鑒定醫療事故和處理醫患糾紛的法律依據[3]。其在書寫中瑕疵或質量缺陷會涉及醫患雙方權利及義務[4],而隨著人們法律意識的提升與醫療技術進步的不平衡性,醫患矛盾發生的概率逐年增加。為避免因電子病歷質量缺陷引發醫療糾紛,對病例的真實性和規范性要求越來越嚴格[5],各醫院也分別采取有力的規范措施提升電子病歷的書寫質量。所以醫院強化電子病歷質量管理對加強電子病歷質量控制有重要意義。
隨著電子信息技術和人工智能的發展,神經網絡模型在醫學中的應用越來越廣泛,用于文本分類任務的卷積神經 網 絡(Text Convolutional Neural Networks,TextCNN)模型作為其中一種,可利用多個不同大小的卷積核來提取句子中關鍵信息,能更好地捕捉局部相關性。在篩查文字、圖片等信息中的問題方面有一定優勢,現在多應用在病例首頁問題中的篩查,可識別和分類所提取的首頁問題[6],目前較少用于篩查電子病歷所遇到的質量問題。為更好地預測和篩查電子病歷文本提取及質量缺陷,本文通過建立TextCNN模型,探討和分析其預測電子病歷文本提取及質量缺陷的情況。
1 資料與方法
1.1 資料來源
選擇并抽取我院于2020年1月1日至2021年10月31日歸檔的電子病歷9萬份,其中門診病例7萬份,住院病例2萬份。
1.2 方法
1.2.1 電子分組和抽取情況分析
本次研究的樣本量共有9萬份,按照7∶3的比例把所有電子病歷分為訓練集和測試集,其中訓練集有63000份電子病歷(11540份有質量缺陷,51460無質量缺陷),測試集有27000份電子病歷(5145份有質量缺陷,21865例無質量缺陷)。訓練集采用K折交叉驗證(K=10)。
1.2.2 運用自然語言處理技術提取信息
本研究是運用中文自然語言處理系統從電子病歷系統中提取出臨床有用信息。處理方法如下:① 預處理:先將系統內的電子病歷轉換成TXT可編輯的文本格式,同時清除掉文中的空白行和空格;② 句子分割:全文分割應用的是常在文檔中詞語或句子間斷開的標點符號,包括“,”“。”“!”“?”“;”等;③ 段落篩選:應用段落篩選排除不必要的信息以便簡化工作量;例如入院記錄和首程中主訴這一行,從“主訴:”后的句子內容均是臨床上的關鍵信息,這需要設定兩個固定的邊界篩選文本內容,而影像或病理學中的結論報告與上述問題類似;④ 關鍵詞識別和值的提取:按照預定義的關鍵詞提取電子病歷中的關鍵詞,在匹配過程中按順序進行逐步的運算算法(如果遇到文本中無法識別的預定義字段,程序會跳過此段處理下一個)。
1.2.3 構建人工神經網絡
采用TextCNN探索卷積神經網絡深度與其性能間的關系,TexTCNN構建了包含嵌入層、卷積、最大池化層、全連接輸出層的卷積神經網絡(圖1),通過以詞為單位進行文本表示形成詞向量,再將詞向量按照詞在句子中出現的順序進行拼接,形成代表句子的矩陣,從而實現句子特征的自動提取和學習。本研究使用TextCNN模型進行遷移學習,其中嵌入層為采用經自然語言處理技術提取后的關鍵詞,并將之轉化為詞向量,構成文本特征向量作為循環層的輸出(文本會轉變成一個二維矩陣,假設文本的長度為|T|,詞向量的大小為|d|,則該二維矩陣的大小為|T|×|d|);卷積層則采用列數與循環層相等的卷積矩陣窗口,并將矩陣中的列矩陣塊由上到下依次進行卷積運算,將矩陣所有相同位置的元素相乘后再求和并提取矩陣特征;在池化層中采用最大池化的方法取每個卷積窗口卷積得到的卷積層向量中最大的元素作為特征值,通過降低特征的維度,進一步提高分類效率;輸出層與池化層全連接,以池化層向量為輸入對向量進行分類,并輸出最終的分類;而后將輸出結果與之前預先基于中文醫學主題詞表構建好的醫學主題詞模型進行比對,并將所有比對完成的TextCNN模型的參數定義為集合,并采用隨機梯度下降方法訓練,得到最終模型,最后將驗證集輸入模型中以進行驗證。
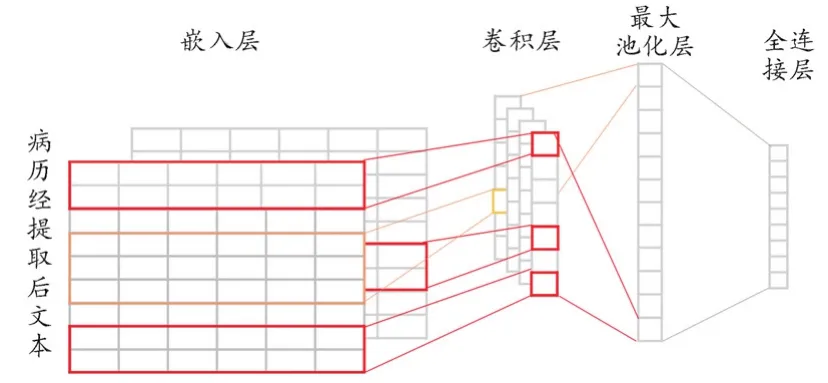
圖1 TextCNN 模型結構略圖
1.2.4 人工神經網絡模型的評估
根據選出的測試集為驗證對象,用TextCNN構建出模型進行驗證,先通過疾病診斷相關分類系統(Diagnosis Related Groups,DRGs)對測試集內所有電子病歷分組,將提取出問題的電子病歷同時由一名具有中級職稱并有5年以上審核病案工作經驗的主治醫師和此次建立的神經網絡模型進行核查,如果二者審查結果不一致時交由病案室內具有副主任醫師以上職稱的專家醫師進行復測,此結論是此病歷質量檢驗的最終判定結果。統計所有神經網絡模型判斷錯誤的電子病歷數并計算出人工網絡模型的準確率、特異度和敏感度。
1.3 統計學分析
實驗數據分析采用的硬件平臺為i7-7700K+GTX1060(6G),軟件平臺為Python 3.7.10及TensorFlow-gpu 2.4.0人工神經網絡庫建立TextCNN模型,從預訓練基線卷積層中提取特征優化的優化策略。準確率比較采用χ2檢驗,P<0.05為差異具有統計學意義。
2 結果
2.1 電子病歷質量缺陷統計
納入研究的9萬份電子病歷中,通過DRGs篩查后總共有16685份電子病歷存在質量缺陷,質量缺陷發生率是18.54%(16685/90000),分析系統運行界面如圖2所示,統計結果如表1所示。通過人工復檢后發現存在質量缺陷病歷中的問題主要有以下幾個方面:對病情和醫囑變化或檢查報告等病程記錄不全;部分檢查報告缺失不全;入院記錄或首程填寫不全;病程內容書寫錯誤或重復;醫生未能在規定時間內及時書寫病程或簽字提交;首頁填寫不全或錯誤;部分知情同意書等內容缺失;醫囑打印不全;出院記錄對病情記錄不全。
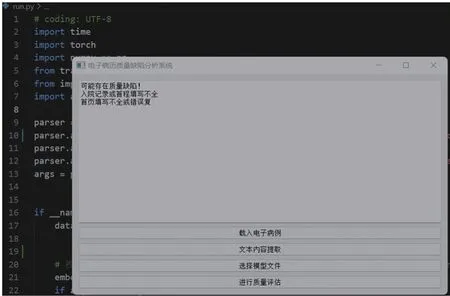
圖2 電子病歷質量缺陷分析系統界面
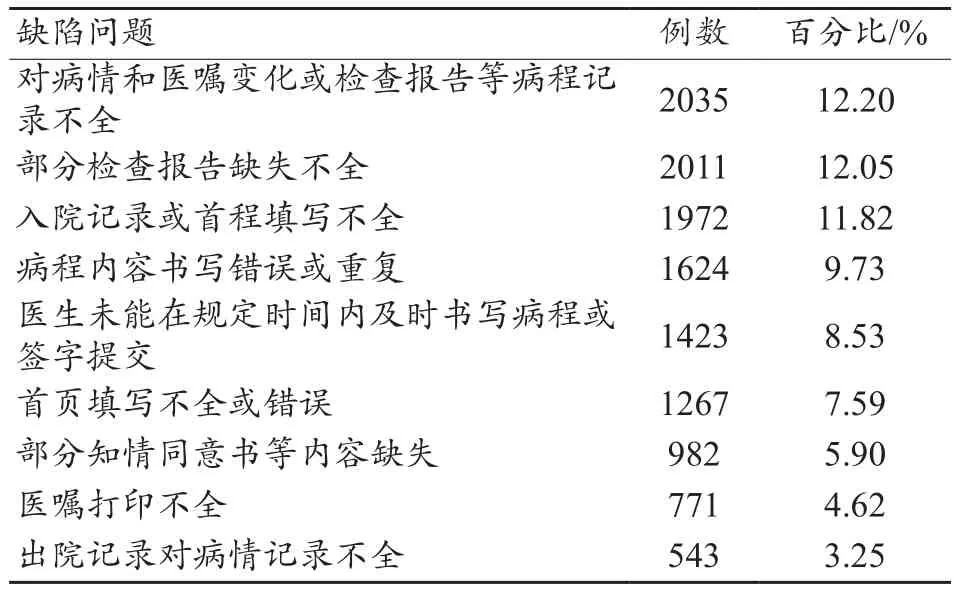
表1 電子病歷質量缺陷統計
2.2 預測模型的內部驗證和外部驗證結果
通過收集預測模型及人工復審的預測矩陣,見表2。計算比較TextCNN模型與人工復審的預測指標之間的差異結果顯示:TextCNN模型的準確率、敏感度、特異度、陽性及陰性預測值顯著高于人工復審,差異具有統計學意義(χ2=253.249、57.091、197.199、186.241、57.547,P值均<0.001),見表3。
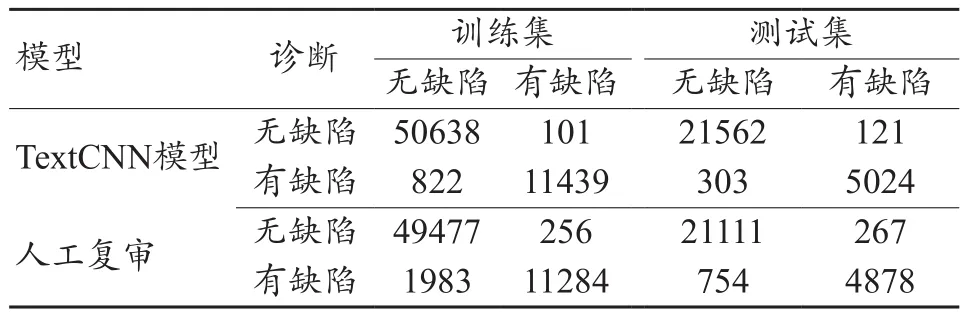
表2 TextCNN模型和人工復審預測質量缺陷的混淆矩陣(份)
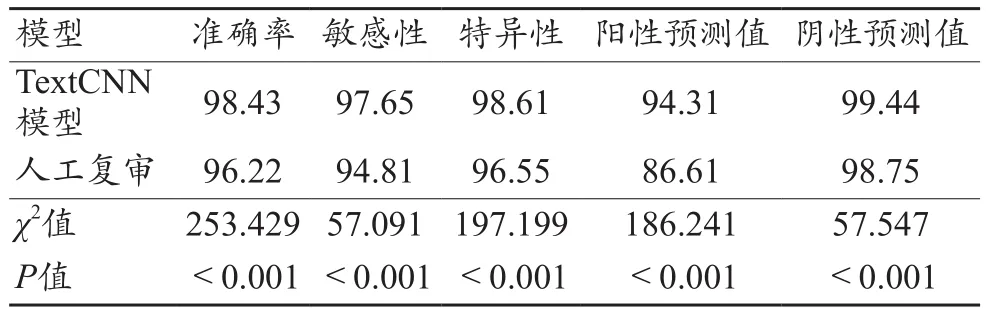
表3 TextCNN模型和人工復審預測測試集質量缺陷的效能對比(%)
2.3 應用CNN模型后逐月篩選出問題病案的情況對比
由2021年2—10月間DRGs篩選出問題病案的數量結果顯示(圖3),自開始采用TextCNN模型分析后,隨著模型系統應用逐漸熟練,DRGs每月篩選出有質量缺陷病的問題病案數逐漸下降,在3月份下降最明顯,后下降趨勢逐漸減緩,系統應用逐漸熟練、性能逐漸穩定。DRGs篩選出有質量缺陷病的問題病案發生率顯著下降(χ2=16.830,P<0.001)。
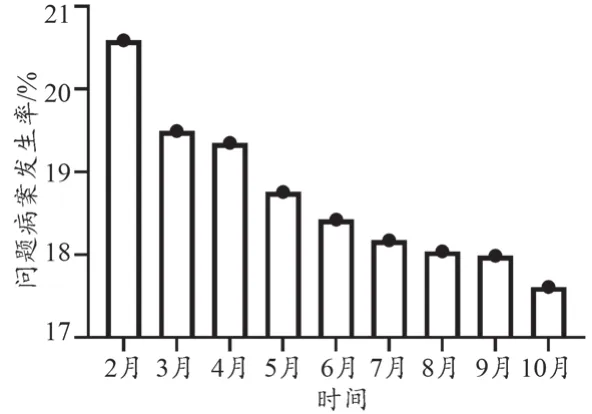
圖3 DRGs篩選出問題病案發生率
3 討論與總結
病歷是醫師基本醫學知識、技能與實際相結合的客觀體現,也是處理醫患糾紛及其他涉及醫學糾紛的法律依據[7],因此病歷質量和病歷質量管理在醫院管理中一直占據著重要地位。而且好的病歷還是醫院進行教學科研的重要資料,為醫師的成長提供幫助[8]。而隨著社會信息化的發展,電子病歷已逐漸代替了手寫病歷,成為醫院的組成部分,而電子病歷的質量缺陷也成為病歷質量管理中的關鍵部分[9]。如何提高電子病歷的質量也成為目前臨床研究的重要課題。TextCNN作為一種深度前饋人工神經網絡可用于提取文本中的關鍵信息,也可以識別和處理圖像,目前逐漸應用于處理病歷首頁,對識別首頁缺陷有較好的效果,有助于提高病歷質量[10],較少用于電子病歷的質量管理。
在本研究結果中發現,近兩年我院的電子病歷質量缺陷發生率是18.54%,說明我院在提高電子病歷質量方面仍有較大的提升空間。而通過復檢后發現最重要的質量缺陷問題主要包括對病情和醫囑變化或檢查報告等病程記錄不全、部分檢查報告缺失不全等,一方面考慮與患者多、周轉快、醫師工作強度大、書寫病歷時間少有關;另一方面考慮與部分醫師法律觀念薄弱、缺乏自我保護意識、對電子病歷質量重要性的認知程度不夠、容易出現錯別字或記錄不嚴謹等情況有關[11],而且電子病歷有復制粘貼等功能,在打電子病歷時容易出現病程內容書寫錯誤或重復、與病情不符或忘記簽字等低級錯誤。在沈占英等[12]的研究中也列舉了包括病程記錄缺陷、病案首頁缺陷、入院記錄缺陷等在內的病歷質量缺陷,與本文研究結果類似。也說明了如何提高電子病歷質量是目前大多數醫院所面對的重要問題。
通過預測模型內部和外部驗證發現TextCNN模型準確率、敏感度、特異度、陽性及陰性預測值均高于人工復審。這說明了TextCNN預測模型在預測電子病歷質量缺陷中有一定優勢。在現今的通用技術中,機器學習對大規模數據處理有較大的優勢,TextCNN可以通過構建模型對提取的數據反復對比篩查,可提高缺陷的檢出率,特別是對電子病歷中的圖像、文字和表格等多個方面的識別和提取有較大的優勢[13]。而人工檢測由于人的固有觀念及對問題的主觀意識不同,對不同問題的看法不一致,而且病案審查人員數量少、工作量繁重,均會導致人工檢測的敏感性和特異性降低[14]。在我院,通過應用TextCNN模型分析后發現DRGs篩選出問題病案發生率顯著下降。觀察我院每月有質量缺陷的問題病例檢出率發現,隨著應用TextCNN模型時間的延長,問題病例檢出率逐漸降低。主要是在剛開始使用DRGs系統時,由于對診斷、格式、系統等模不熟悉,使得早期問題病歷的檢出率相對較高,而隨著對DRGs系統的熟悉,缺陷病歷的檢出率明顯降低。而且網絡系統具有記憶性,能共享模型中各分層的實現參數,并且能儲存各種長度不等的數據片段,增加了數據片段的識別性[15],減少了由于數據長度增加引起的不能識別文本的情況。TextCNN模型還能在局部感知和權值共享時通過模型進一步減少模型內訓練參數的數目,提高模型效率,減少電子病歷質量缺陷檢出率[16],對提高電子病歷質量有良好的效果。
綜上所述,神經網絡模型在電子病歷文本提取和篩查質量缺陷病歷中的效果較好,可用于臨床推廣以提高病歷質量。雖然系統使用后有質量缺陷的電子病歷檢出率下降,但由于電子病歷的復雜性,仍有部分電子病歷質量缺陷檢測存在誤差,需要更完善的系統進一步檢測,也需要進一步完善質量管理規定,提高電子病歷質量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中國生殖健康(2019年2期)2019-08-23 08:12:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
