基于PCA-CNN的動態短文本分析研究
2022-04-28 09:23:38林寒冰金秀玲林云霞
科技創新與應用 2022年11期
林寒冰,金秀玲,王 婷,林云霞
(閩江學院 數學與數據科學學院(軟件學院),福建 福州 350108)
目前,人們的閱讀途徑已不局限于紙質媒體,博客、微博等社交網絡平臺成為人們獲取信息的重要來源,但其中的短文本信息繁雜、無序且多樣,不易獲取。本文幫助人們挖掘海量數據中的潛在聯系并篩選信息,提高閱讀效率。通過“人機對話”讓枯燥的閱讀更具有趣味性,加強人們閱讀體驗感。因此,動態短文本是十分具有研究意義的。
近年來,國內外學者關于話題信息獲取方面有大量研究。對于信息檢索、信息挖掘和信息抽取等自然語言處理技術可追隨到話題檢測與跟蹤(Topic Detection and Tracking,TDT)[1]的話題跟蹤任務階段。傳統文本信息的話題抽取研究最重要的環節是文本聚類的過程。在國內,尉景輝等[2]用傳統的K-means聚類算法對長文本聚類進行研究,解決了傳統的K-means聚類算法對長文本聚類導致的計算復雜度增加、聚類結果混亂等一系列問題。高長元等[3]利用CURE算法針對存儲網絡用戶的大型數據庫進行基于實際應用的改進。蔡岳等[4]利用最小二乘法降低文本向量的維度,創建了應用于DBSCAN算法的簇關系樹結構來文本聚類。李云紅等[5]建立了BGRU-CNN模型對長文本提取語義關鍵特征,提高了中文長文本的分類準確率。張昱等[6]用組合-卷積神經網絡模型對新聞文本進行分析,提高了新聞文本分類精確率。在國外,Kim提出了TextCNN[7]算法,使用卷積神經網絡(CNN)來對英文長文本建模,在公有數據集上超過了傳統方法的表征。卡內基梅隆大學的人員提出了HAN(層次注意力網絡)[8]算法建模更加復雜的文檔,使用詞、句、段落之間3種的注意力表示一篇文檔。對于微博短文本的研究,史偉等[9]采用情感圈的方法結合不同語境,對文本語義進行進一步挖掘,在精度、召回率、準確率方面比傳統基于詞典的方法都得到了提升。張佩瑤等[10]基于詞向量和BTM結合K-means算法對微博文本進行主題融合,該方法在主題模型提取效率上提高了10%。
綜上文獻分析,自然語言處理中,在研究內容上,CNN算法多用于英文文本、固定長文本的分析,長文本詞句間的聯系易把握,以往的研究缺乏對于當今熱門平臺如微博、知乎等用戶發布的情感態度強但詞句聯系較弱的短文本信息的研究。研究方法上,文本聚類方法有基于劃分K-means聚類算法、基于層次的CURE算法、基于密度的DBSCAN算法及CNN算法,在最新的研究中對于短文本的研究用到情感圈方法、基于詞向量和BTM結合K-means聚類算法。以上方法無法同時獲取文本中的詞語之間關聯性及上下文的情感表述,且聚類結果會受到特征向量的影響。
因此,本文對動態短文本關鍵詞提取方面的空缺展開研究,引入PCA算法,進一步融合CNN模型提出PCA-CNN模型,探討動態短文本的關鍵詞抓取與情感表述問題。該模型既考慮到中文語義復雜、情感多樣的特點,又有降維的作用,提高CNN模型的運行速度,PCA算法與CNN的結合能快速捕捉短文本中的上下詞聯系,在其他文本中搜索到目標事件關鍵詞并提取出來,提高短文本信息的理解性及關鍵詞的抓取速度,使用戶快速把握事件發展關鍵信息。
1 基礎算法介紹
1.1 PCA降維技術
PCA(Principal Component Analysis)[11]即主成分分析方法,是廣泛使用的一種數據降維算法,通過析取主成分將關系緊密的眾多特征提取出盡可能少的相互獨立的新特征,新特征能夠獨立代表各個部分的內容,使數據更易理解。PCA算法降維[12]計算如下:
(1)將原始數據按列組成n行d列矩陣X;
(2)再將每一維(代表一個屬性的每一列數據)去零均值化;
(3)然后計算協方差矩陣,并對協方差矩陣特征值和特征向量進行計算,

(4)接著對特征值進行排序,取前k行組成矩陣P,用數據矩陣乘以k個特征向量組成的矩陣P,得到降到k維的數據,

PCA降維后,高維數據的重要特征在數據中能更明確顯示出來,降低算法開銷。
1.2 卷積神經網絡模型(CNN)
CNN模型[13]是一種由輸入層、卷積層、池化層、全連接層和輸出層構成的自然語言處理模型,每一層的神經元呈寬度、高度、深度三維排列。多層的卷積、池化操作能夠捕捉到模型的全局語義信息和更高級的特征。其中,卷積層作為CNN模型構建的核心,對矩陣卷積計算獲取其特征。池化層進行一種降采樣操作(subsampling),以降低特征圖(feature maps)的特征空間,簡化計算復雜度,減少計算資源耗費。CNN的架構圖如圖1所示。
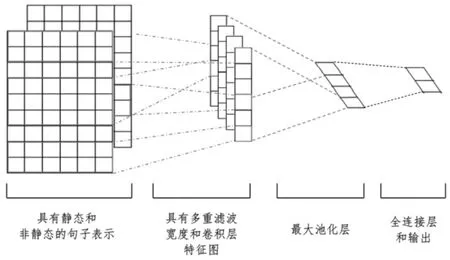
圖1 卷積神經網絡(CNN)架構圖
CNN中每一層實施的操作就是把上一層的輸出加權求和,加上偏置并輸入激活函數,激活函數輸出的所在層如果不是最后一層,則該輸出是下一層的輸入。計算公式如下:

其中,hi表示作用后的向量,S為輸入的句子,W表示一個窗口為m的卷積核,ci表示輸出的特征映射向量,bi表示偏置項,α表示非線性激活函數。
1.3 PCA-CNN模型構建
(1)數據獲取,在輸入目標關鍵詞后,通過網絡爬蟲技術爬取網頁相關的文本內容、鏈接、ID號等目標數據。
(2)數據預處理,提取目標數據的文本內容,進行文本清洗,包括去重及去除空格空行、去除停用詞過濾、數據降噪等操作后,使用jieba中文分詞,進行文本切分后計算生成特征向量矩陣。采用PCA算法過濾掉非重點特征項,去掉特征之間的無關性并保留語義特征,實現向量矩陣的初步降維。
(3)在輸入層結合訓練好的CNN模型將文本數據向量化。一方面,將分詞完成的測試集數據使用Word2Vec訓練[14],選擇skip-gram跳字模型[15]用Softmax函數作上下文詞分類,轉化文本數據為大小相同的情感特征詞向量矩陣。另一方面,采用TF-IDF關鍵詞提取法[16],構造出文本矩陣再將詞語轉化為詞頻矩陣。
(4)卷積層對向量矩陣卷積運算,對詞向量矩陣選定卷積核大小為2、3、4,卷積核數量為64的3層卷積操作。
(5)池化層降低文本特征維度,在對卷積后的特征圖降采樣,進行最大池化Max pooling[17]處理,將特征圖的各個維度全部降為1,以便后續最大特征地提取和聚類。
(6)輸出層文本聚類,分類輸出特征詞。結合池化層輸出的詞向量的最大池化結果,先輸入全連接層,對經過多次卷積和池化得來的高級特征采用全連接結合Softmax函數[18]進行分類后輸出。
(7)特征結構可視化。用Matplotlib繪制分類結果矩陣的散點圖,采用WordCloud[19]生成文本數據的詞云圖,使結果更加直觀。
(8)應用測試集數據對模型進行檢驗及模型對比,判斷其準確率,不斷提升模型的準確度。
PCA-CNN模型構建流程圖如圖2所示。

圖2 PCA-CNN模型構建流程圖
2 實證分析
2.1 實驗數據準備——以“河南暴雨”為例(事件已經結束,已構成完整數據)
本文通過python編程語言,采用訓練集和測試集進行研究。
突發極端事件會打破人們正常的生活節奏,往往是大眾的關注點,隨著短文本閱讀的普及,如微博等信息交流平臺的數據所包含的社會視角、話題影響力逐漸增大,足以反映大眾態度。本文借助網絡爬蟲技術,從微博網頁花費21 min爬取2021年7月20日至2021年7月27日的3 830條關于“河南暴雨”的微博話題。該話題事件現已結束,相關的數據較為完備,且該突發事件的相關話題持續1周位于熱搜榜首,其數據內容包含正面負面、消極積極多維度融合情感態度的信息。此外,該事件可以充分反映面對極端突發事件時,大眾的輿情傾向,國家和人民采取的緊急響應措施,具有代表性。
2.2 “河南暴雨”數據預處理
提取“河南暴雨”的詳細信息文本,在卷積操作前進行文本清洗,去除文本停用詞、無意義詞等冗余信息,降低數據噪聲。通過分詞,劃分地點、時間、事件為具體的詞組,得出鄭州、自然災害等詞語,進一步生成特征向量矩陣,將每條微博轉化為一個特征向量。轉化后得到628個特征向量,數量過多,需采用PCA降維。
2.3 PCA處理
使用PCA算法,對生成的m*n維特征矩陣,通過多重組合特征提取方法,計算協方差矩陣,每個向量對應的特征值,排列后選定的前k維正交化的特征項,提取出具有代表性的特征項,對特征向量矩陣進行初步特征降維處理。如圖3所示,在628個特征中選取特征值大于1、方差累積貢獻率超過80%的前256個主成分,確定所采用的維度為256。通過PCA降維,僅保留主要信息令詞特征向量間相互獨立,提煉語義信息,防止卷積出現過擬合。

圖3 “河南暴雨”相關數據PCA處理碎石圖
2.4 “河南暴雨”數據的CNN模型建立
將分詞完成的測試集文本數據轉化為大小相同的情感特征詞向量矩陣,采用HowNet構建情感詞典,建立詞向量矩陣。河南暴雨訓練數據的情感特征可分為積極和消極2個方面,表示積極和正面的賦值為1,表示消極和負面的賦值為0,得到詞匯向量的映射表。
利用CNN的滑動窗口對所有可能的詞向量組合進行卷積操作,得到交互的初步矩陣表示,保留詞矩陣中的特征向量。通過反復對比,發現使用兩層卷積時,關鍵詞分類結果中會出現如“災害”“災難”等大量語義相似的詞匯,占用特征空間;使用四層卷積時,部分基礎語義相同但具有特征的詞匯如“鐵路損毀”“農田損毀”等被過濾,導致過擬合,影響關鍵詞提取的真實性。因此選擇三層卷積。具體卷積層和池化層的參數見表1。

表1 卷積層和池化層各參數設置
將“河南暴雨”微博評論數據詞向量矩陣數值化后,進行一次卷積和池化操作,得到尺寸為(8,8,256)的特征矩陣圖,對文本特征進行初步增強。對此特征矩陣圖進行卷積層Conv2、Conv3的特征融合,輸出特征矩陣圖尺寸為(4,4,128),降維處理Maxpool2層的輸出,得到(128,128)的二維矩陣。
輸出層對特征矩陣與詞矩陣匹配后輸出,關于“河南暴雨”的目標關鍵詞分類。該信息可分為負面積極、負面消極、正面積極、正面消極,但由于在現實生活中的表達習慣和客觀性,正面的事物普遍屬于積極一面,主要將處理后的數據分成3類,第1類表示對受災地區捐款,八方支援等的正面積極詞匯;第2類表示河南暴雨是一大地質災害,由于氣候變化對人類生活產生較客觀的負面影響;第3類則表示受災嚴重的地區受災情況等消極信息。關鍵詞分類結果見表2。

表2 關于“河南暴雨”部分關鍵詞分類表
2.5 “河南暴雨”數據結果可視化
繪制“河南暴雨”話題、分類結果矩陣散點圖,每個點對應1個詞2個維度的情感特征值。在重復訓練后,關于“河南暴雨”不同類別的情感特征值聚集,沒有散落的錯誤向量。采用WordCloud模塊生成“河南暴雨”文本數據的詞云圖,以直觀的精煉文字內容傳達信息。如圖4所示的詞云圖解釋了本次“河南暴雨”的發展態勢,讓用戶快速觀察到“河南暴雨”的關注點在于暴雨發生受災的具體地點、人們在暴雨中的應對方法、暴雨產生的原因和性質、暴雨的發展狀態等內容,體現了人們對極端突發事件的密切關注,展現國家以人民生命財產安全為先的堅定,同時用戶提出的一些負面的文本信息可以給相關部門以建議和啟示。

圖4 “河南暴雨”熱點詞云圖
研究PCA-CNN模型的優化程度,將支持向量機算法、TextCNN算法的中文模型與PCA-CNN模型對相同的微博話題“河南暴雨”短文本數據集進行關鍵詞抓取后的情感分類,其中TextCNN模型的卷積參數與PCA-CNN模型保持一致。模型情感聚類結果見表3及圖5,各類計算值的后綴1、2、3,分別代表正面積極、負面積極、負面消極3類文本,Accuracy表示短文本分類的準確率。
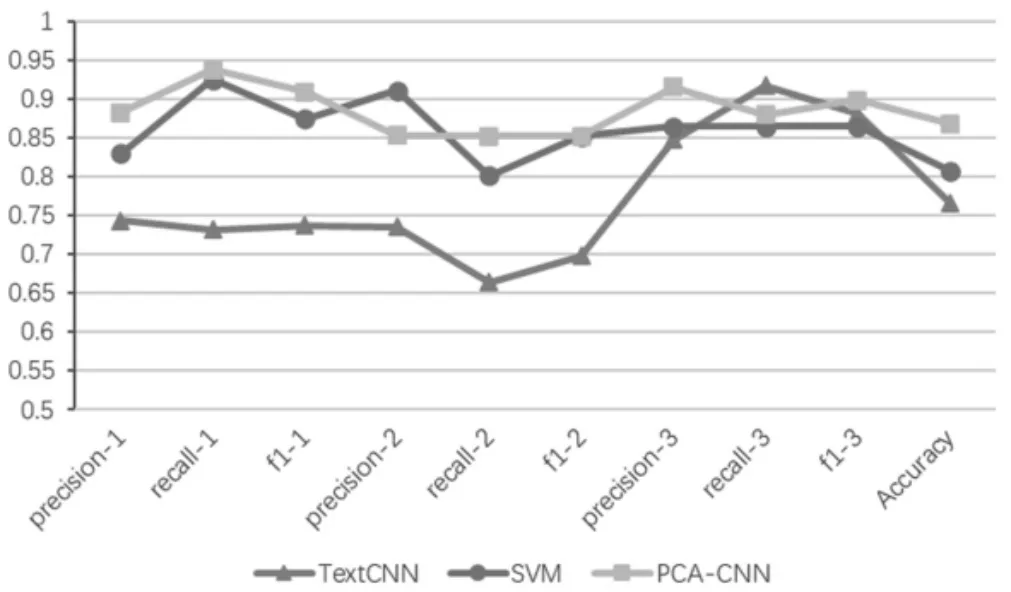
圖5 “河南暴雨”的TextCNN,SVM,PCA-CNN模型情感聚類結果

表3 TextCNN,SVM,PCA-CNN模型測試結果
對照圖表中數據對比,TextCNN模型分類的準確率最低,SVM模型次之,PAC-CNN模型的準確率最好。PCA-CNN模型的短文本情感分類性能最好,主流關鍵詞準確度達86.85%,實現了對“河南暴雨”微博短文本數據的準確分類及關鍵詞抓取。較之傳統的TextCNN模型,添加了PCA對詞特征降維后準確率提升了10.14%,對SVM增加了更深層學習的CNN模型后準確率提升了6.11%。
3 結束語
隨著科技的發展,人們頻繁通過閱讀新聞、電子書、新媒體平臺等方式獲取信息。針對實時話題,在繁雜多樣化的數據信息中提取關鍵信息,借助網絡爬蟲技術獲取中文短文本數據,PCA算法降維處理數據,數據特征初步提取后,結合CNN模型進行情感分析及文本分類,構建了PCA-CNN模型,在語義分析的基礎上加強了詞句情感把控,該模型結果的準確率高于TextCNN和SVM模型,達到86.85%。通過反饋目標事件的最新發展狀況和大眾關注點,讓用戶快速獲取信息,抓住情感重點,節省時間,提高閱讀關注度。動態短文本的研究在當今快節奏的生活中促進了人們的生活效率和生活水平的提高。智能閱讀也會在未來擁有更好的發展條件和環境,并不斷完善和提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
