基于SMOTE平衡數據集的BP神經網絡變壓器故障診斷
2022-04-28 12:58:20祁壽賢胡榮輝吳夢娣張玉勇
山東電力技術 2022年4期
祁壽賢,胡榮輝,王 偉,吳夢娣,張玉勇
(1.青海綜合能源服務有限公司,青海 西寧 810003;2.煙臺東方威思頓電氣有限公司,山東 煙臺 264003)
0 引言
變壓器是電能分配和電壓變換的核心設備,變壓器發生故障時不僅會影響電力系統的穩定運行,還會造成巨大的經濟損失。因此對變壓器的運行狀態進行實時監控和分析,盡早發現故障對保障電網的穩定運行具有重要的意義[1]。
當前電網中的變壓器以油浸式為主,其故障主要包括了內部的局部放電,高能電弧,溫度過高等。當變壓器內部發生這些故障時往往會導致變壓器中礦物油和其他固體絕緣材料發生劣化而產生不同的氣體[2]。因此,可以通過對變壓器油中溶解的氣體的組成成分和濃度分析來判斷變壓器的運行狀態是否正常或故障類型[3]。常見的溶解氣體分析法包括了IEC氣體比值法、羅杰比值法、杜瓦三角法等。這些方法雖然簡單可行,但當同時存在多種故障時這些傳統的方法故障診斷準確性難以保證[4]。而且這些基于比值編碼的方法還存在編碼缺損、編碼邊界過于絕對的問題[5]。
大數據挖掘和機器學習的快速發展使得基于數據驅動的變壓器的故障診斷方法成為可能。文獻[6]提出了一種基于模糊關聯規則挖掘的電力變壓器故障診斷方法,該方法通過建立故障特征量與故障之間的關聯規則來實現故障的可靠診斷。文獻[7]提出了一種基于多模型選擇性融合的變壓器故障診斷方法,該方法通過多模型決策融合來提高對多種故障類型的診斷準確性。文獻[8]提出了一種支持向量機(Support Vector Machine,SVM)與決策樹相結合的變壓器故障診斷方法,該方法能夠對多種類型的故障進行可靠識別。除了上述基于溶解氣體分析的方法外,一些基于溫度信號、振動信號和聲音信號挖掘的方法也被提出并取得了不錯的效果[9-11]。
上述方法雖然靈活性好,準確率高,但需要大量的數據支撐模型的訓練。但在實際生產中,變壓器不同故障的發生率有著明顯的差異,導致不同故障積累的樣本極不均衡。基于這些不均衡數據訓練的模型對小樣本故障進行診斷容易導致小樣本故障的誤判和漏判。為此,許多學者分別從算法和數據兩方面提出了解決措施。算法上主要是通過引入代價因子構建適用于小樣本或非均衡數據集的代價敏感分類器模型[12],或者采用遷移學習的方式來解決樣本數據不足的困境[13]。但這類方法存在一定的不確定性和較強的主觀性。在數據層面的研究則主要是通過重采樣或數據生成來增加少數類樣本的數據量,從而使故障樣本數據集達到均衡。如文獻[14]提出了一種基于近鄰成分分析和K 近鄰(K-Nearest Neigh?bors,KNN)算法相結合的小樣本故障診斷方法。文獻[15]提出了一種基于自適應樣本合成的變壓器故障診斷方法。但上述的樣本合成方法容易受到少數類噪聲和邊界處樣本數據的影響,使得合成的數據中包含更多的噪聲和模糊數據。
針對上述問題,提出一種適用于不平衡數據集的變壓器故障診斷方法。該方法首先利用托梅克鏈移除算法去除數據中的噪聲樣本,而后利用合成少數類過采樣技術(Synthetic Minority Over?sampling Technique,SMOTE)生成新的與原始少數樣本分布相似的新樣本,從而實現不平衡數據集的均衡化。在此基礎上,利用人工蜂群(Artificial Bee Colony,ABC)算法對BP 神經網絡所有節點間連接權值和閾值進行優化,以提高BP 神經網絡對變壓器故障診斷的準確性。最后基于實際的電力變壓器數據對所提方法的有效性進行驗證。
1 基于SMOTE的數據平衡
1.1 KNN分類算法
KNN 算法的基本原理是在特征空間中,如果一個樣本附近的k個最近樣本的大多數屬于某個類別,則該樣本也屬于這個類別。如圖1 所示,分別用三角和圓表示兩類不同的數據,圖中的五角星為待分類的目標樣本。根據最近鄰分類原理可知需要確定k的值,然后根據最近的k個樣本的類別來估計目標的類別。如圖所示當k=2 時,目標樣本應該歸屬于三角,而k=6 時目標被歸為類2。顯然,在KNN 中k值的選擇和樣本空間內的距離度量對分類起著決定性的作用。
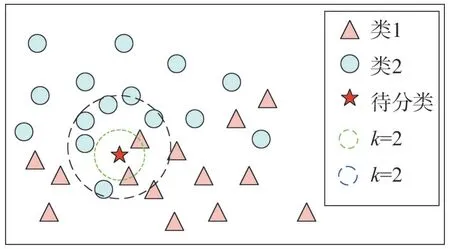
圖1 KNN分類原理
常用的距離計算公式包括閔可夫斯基距離、歐式距離、曼哈頓距離、余弦距離等。采用歐式距離對來計算樣本之間的距離,其計算公式為
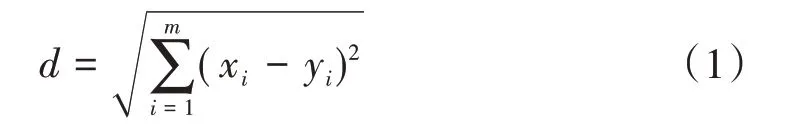
式中:d為樣本之間的距離;m為樣本特征數;x和y代表了不同的樣本。KNN 的分類本質是一種多數表決機制,在實際應用中,k值一般選擇一個較小的奇數值,并采用交叉驗證或其他優化方法來選擇最優的k值。
1.2 SMOTE過采樣原理
SMOTE 算法的基本原理是利用相鄰的少數樣本,通過隨機線性插值的方式來合成新的接近原始數據分布的少數類樣本[16]。設存在少數類樣本集合:
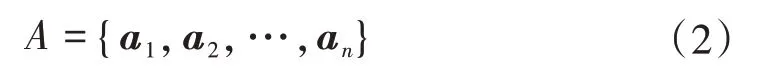
式中:an為第n個少數類樣本的特征向量。
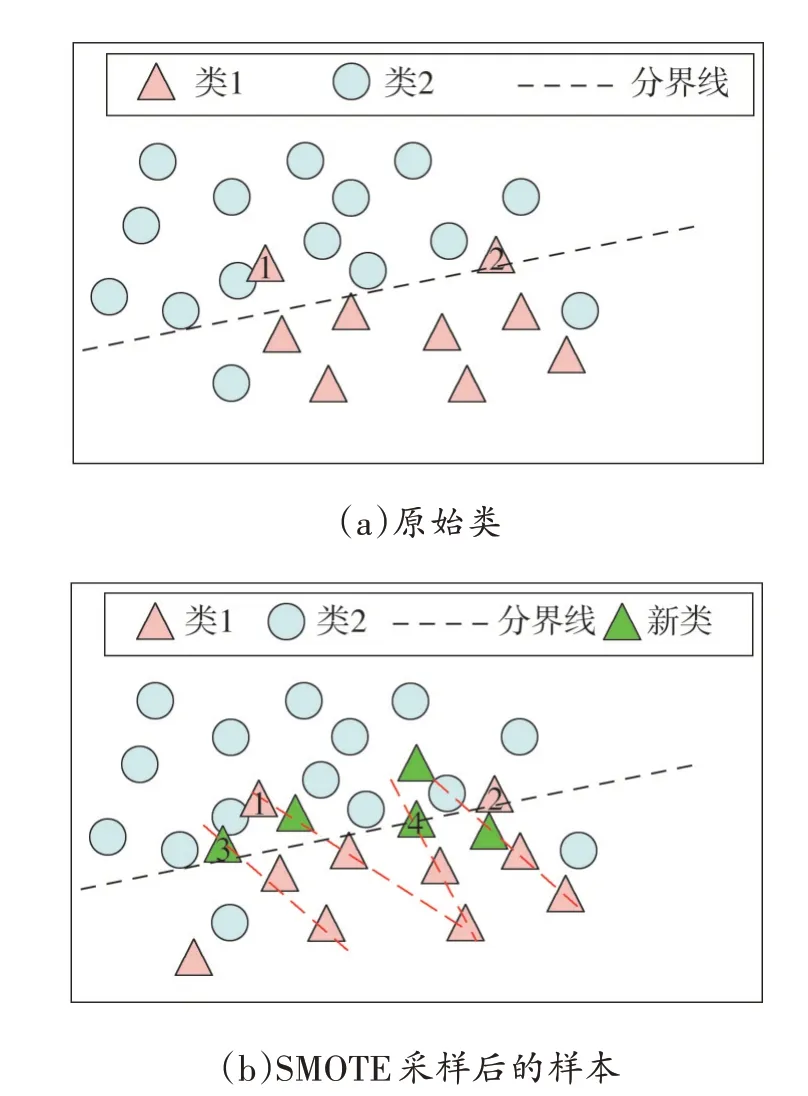
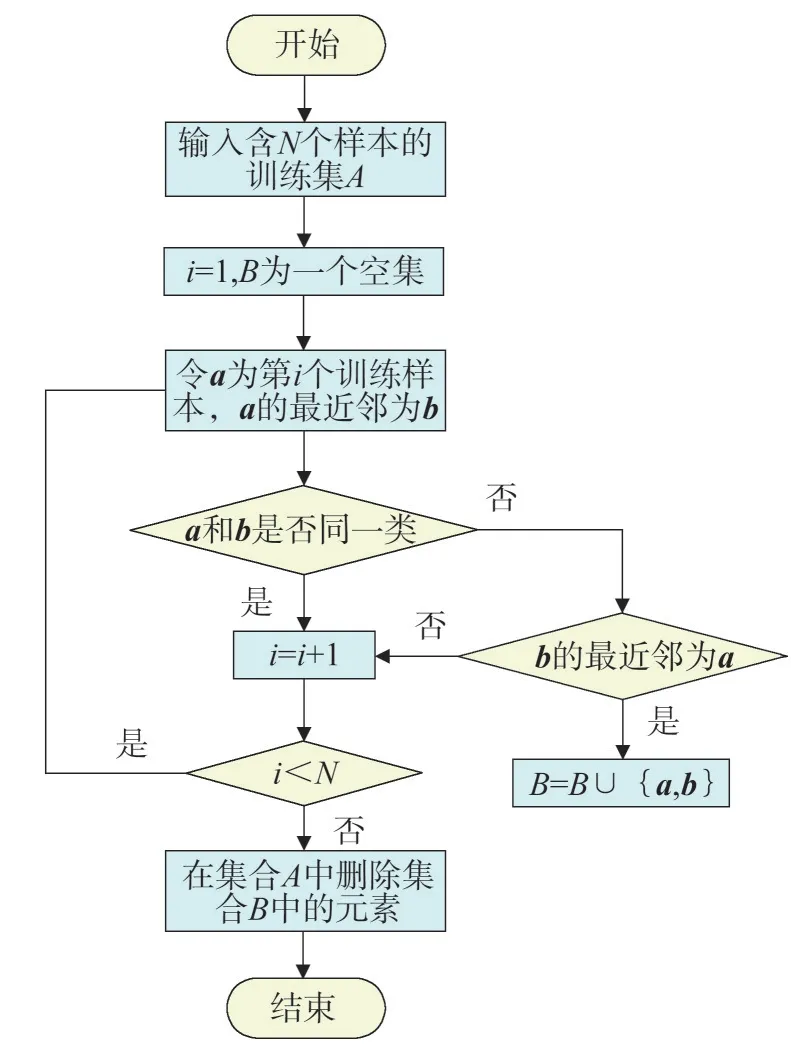
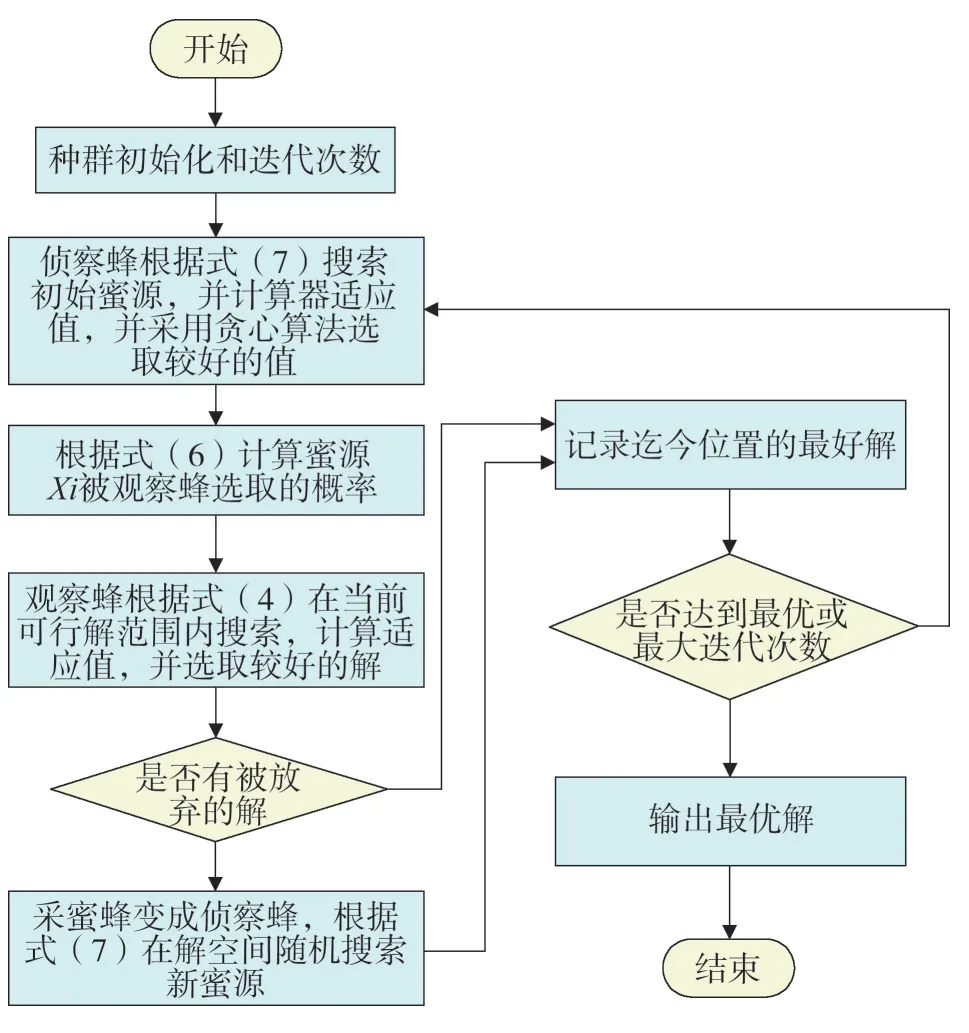
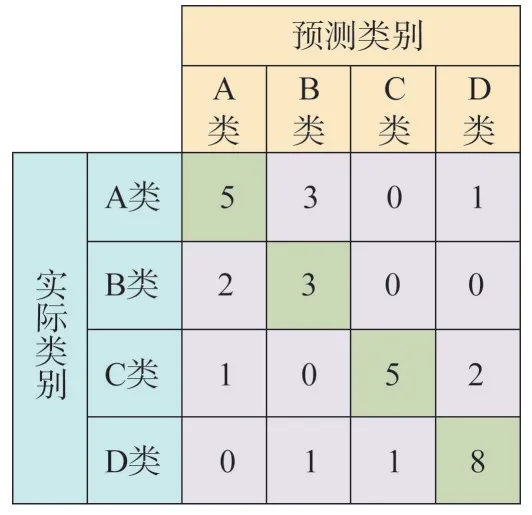
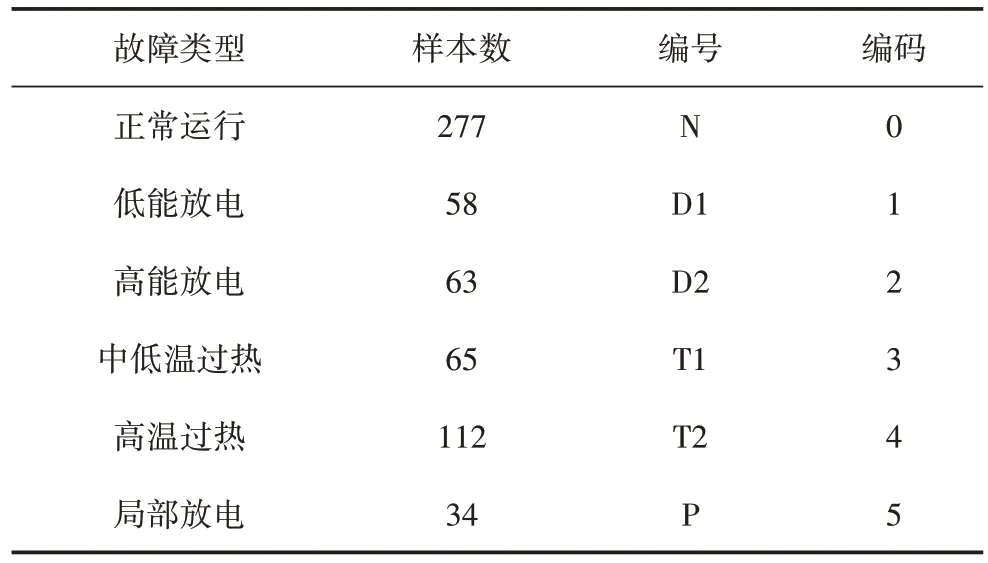
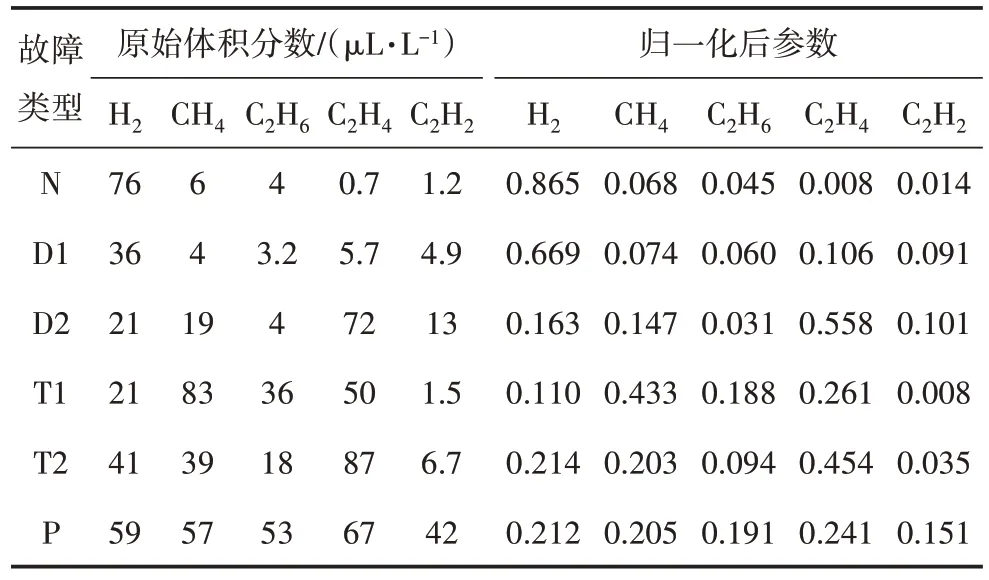
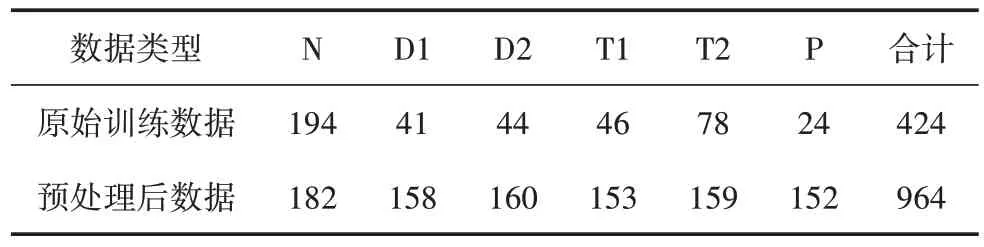
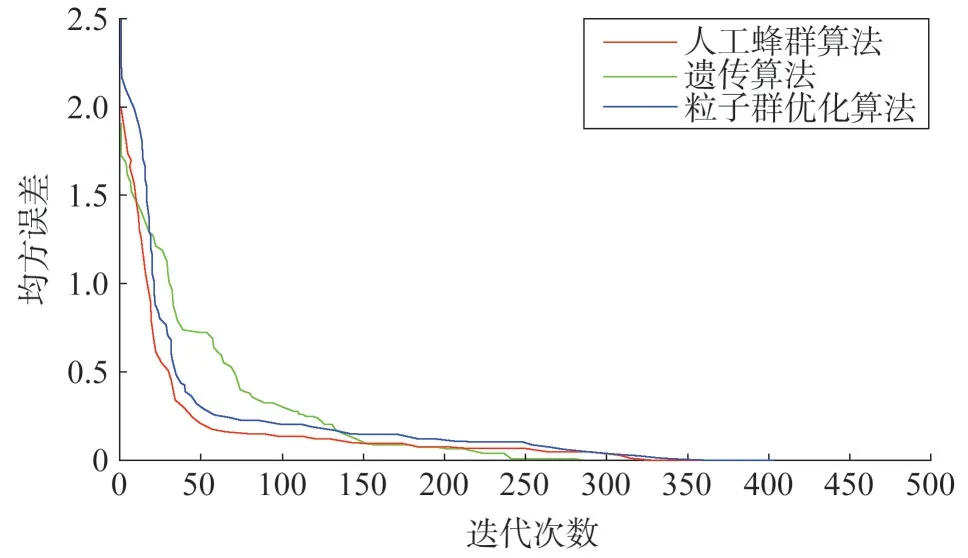
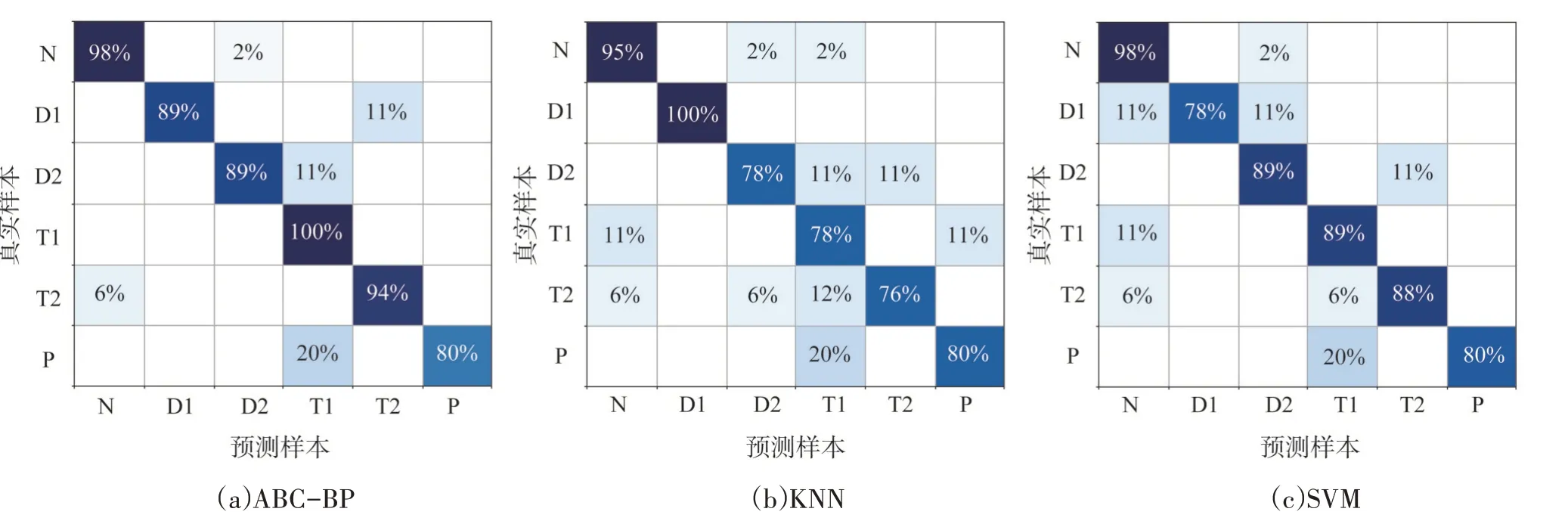
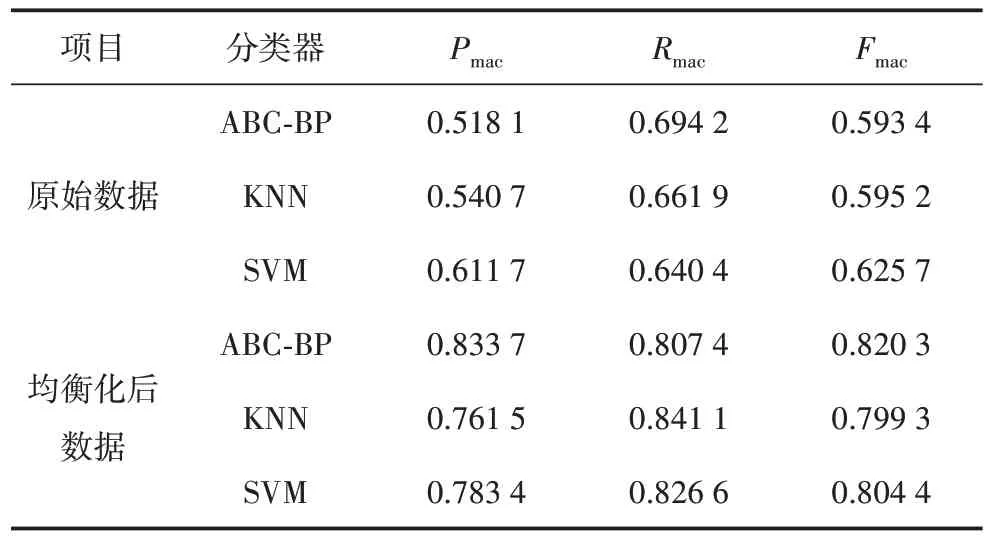
SMOTE 算法的第一步是通過KNN 算法確定其中一個少數類樣本an的k個近鄰;然后選取這k個近鄰樣本中的h個樣本(h 式中:α是一個0~1之間的隨機數。 通過SMOTE 算法可以增加少數類樣本的數量,從而增加分類模型的準確性。但是在隨機線性插值的過程中,合成的新樣本是基于所有的少數樣本,這其中包括了噪聲樣本和邊界上的樣本,如圖2(a)中的樣本1和樣本2所示。因此直接基于原始類樣本進行合成,容易產生如圖2(b)中的樣本3和樣本4這類在邊界上的樣本點,這些樣本點容易導致邊界模糊和分布邊緣化問題[14]。因此在利用SMOTE 算法合成新的少數類樣本之前有必要去除樣本中的噪聲和邊界處的樣本。 圖2 SMOTE采樣示意 為了移除兩個樣本周圍的噪聲和位于類邊界區域的模糊樣例,數學家提出了托梅克鏈接來移除這些可能會影響分類結果的危險樣本。對于已知的樣例a和b,它們能構成托梅克鏈接的3個條件為: 1)a和b是最近鄰; 2)b和a是最近鄰; 3)a和b屬于不同的類別。 當樣本滿足了托梅克鏈接,則可以基于圖3 給出了托梅克鏈接移除算法處理流程。 圖3 托梅克鏈接移除算法流程 ABC 算法是一種模擬蜜蜂采蜜行為的群體智能優化算法,它通過各工蜂個體的局部尋優,最終使群體的全局最優得以凸顯。相比其他的優化算法,ABC算法需要設置的參數少,且具有較好的收斂速度和魯棒性。 在蜜蜂的采蜜體系中包括了采蜜蜂、觀察蜂、偵察蜂3 種類型的蜜蜂。采蜜蜂利用已知蜜源信息尋找新蜜源并與觀察蜂分享信息;觀察蜂根據采蜜蜂分享信息尋找新蜜源;偵察蜂則在蜂房附近隨機的尋找新的蜜源。如果將蜜蜂的采蜜行為與優化問題相對應,則每個蜜源代表了問題的一個可行解,蜜源的花蜜量對應了該可行解的適應度。假設優化問題是D維,采蜜蜂與觀察蜂的個數均為Nb,則第l個蜜源對應的采蜜蜂尋找新蜜源的搜索公式為 式中:l=1,2,…,Nb;d=1,2,…,D;?id是一個隨機數,取值范圍為[-1,1],xl,d和xk,d分別表示第l和第k個密源的第d維取值,表示更新后的第l個密源的第d維取值。 為了使優化結果更好,ABC 算法中會采用貪婪算法在新的可行解和舊的可行解Xl中保留一個最好的解,如式(5)所示。 此外,每個觀察蜂會以一定的概率選擇一個蜜源,概率計算公式為 式中:fl是可行解Xl的適應值。 當所有的采蜜蜂和觀察蜂都搜索完整個空間,若一個蜜源的適應值在給定步驟內沒有提高,則舍棄該蜜源,同時與該蜜源相對的采蜜蜂變成偵察蜂,該偵察蜂繼續根據式(7)搜索新的可行解為 式中:r是[0,1]之間的隨機數;分別為d維空間的上下限。 ABC算法的流程如圖4所示。 圖4 ABC優化算法流程 利用ABC 算法對BP 神經網絡各層之間的連接權值和節點的閾值進行搜索尋優,可以提高模型分類的準確性。假設ABC 算法中蜜源的位置向量X的元素為BP 神經網絡節點間連接權值和閾值,則優化的適應度函數可以取BP 神經網絡的均方誤差(Mean Square Error,MSE)為 式中:N為訓練樣本總數;C為輸出節點總數;是網絡輸出的期望值;yp,q為網絡的實際值。 MSE 越小表明神經網絡的誤差越小,說明蜂群搜索的性能越好。當適應度值達到最小時的蜜源位置即BP 網絡最佳參數。基于ABC 算法訓練的BP 神經網絡流程為: 1)根據給定的輸入、輸出訓練樣本集,設計神經網絡的輸入層、隱含層和輸出層節點數,確定網絡拓撲結構。 2)對蜂群進行初始化,設置最大迭代次數,并根據式(7)給蜜源一個初始位置。 3)根據BP 神經網絡前向算法和適應度函數計算每個蜜源的適應度值,并選取式(9)所示的Sigmoid函數作為BP神經網絡的激活函數。 4)對每個新蜜源的適應度函數值與舊的蜜源適應度函數值進行比較,選取適應度函數值最小的蜜源作為當前最優蜜源。 5)根據蜂群算法的更新公式對蜜源進行位置更新,并重復上述的步驟3)和4),不斷對當前的解進行更新。 6)檢驗是否滿足優化結束調節,判斷迭代次數達到最大值或者滿足最小誤差要求,若滿足其中一條則停止迭代,輸出最優解。 為了驗證BP 神經網絡分類器的性能,分別采用混淆矩陣和宏平均指標對分類器的性能進行評估。混淆矩陣又稱為可能性表格,它可以直觀顯示分類中的錯誤,圖5 展示了混淆矩陣示意,它的每一列代表了預測類別,每一行代表了實際類別,表中的數字代表了分類的數量結果。 圖5 混淆矩陣示意 宏平均常用于評估多分類結果的準確性,它是基于二分類的精確率和召回率推導而來。對于二分類問題的樣本分類情況有四種:真陽性(True Positive,TP),即正類被正確預測為正類的數量;真陰性(True Negative,TN),即負類被預測為負類的數量;假陽性(False Positive,FP),即負類被預測為正類的數量;假陰性(False Negative,FN),即正類被預測為負類的數量。根據式(10)可計算上述每一類分類結果的精準率P和召回率R。 式中:PT為真陽性;PF為假陽性;NF為假陰性。 精準率反映了被預測為正的樣本中實際為正樣本的比例,召回率反映了實際為正樣本中被預測為正的比例。基于精準率和召回率可進一步推導F1-score指標F1為 可以發現F1是P和R的調和平均,F1的取值范圍為[0,1],值越大模型的性能越好。由于多分類模型可以看作多個二分類的集合,因此通過對每類樣本的P值、R值取平均針即可得到宏P值和宏R值,在此基礎上可進一步得到多分類的宏Fmac得分,其對應的計算公式如式(12)所示。 式中:Pmac為宏P值;Pp為第p個樣本的P值;Rmac為宏R值;Rp為第p個樣本的R值。 基于溶解氣體分析的電力變壓器故障診斷常用的特征氣體包括了氫氣(H2),甲烷(CH4),乙烷(C2H6),乙烯(C2H4),乙炔(C2H2),一氧化碳(CO),二氧化碳(CO2)等。由于CO 和CO2的體積分數通常不可靠,因此本文僅考慮前5 種特征氣體,并以其含量來判斷變壓器的運行狀態。為了便于模型的訓練,需要對這5 種氣體體積分數進行歸一化處理,歸一化公式為 式中:φ(H2)、φ(CH4)、φ(C2H6)、φ(C2H4)、φ(C2H2)分別代表了5 種特征氣體的體積分數;φH和φC分別表示氫烴總量和總烴量。根據IEC 60599標準可以將變壓器的故障按照溫度和放電能量劃分為6 種不同的狀態,各種狀態及其對應的編碼如表1所示。 表1 變壓器故障類型編碼 表1 中還給出了使用的變壓器溶解氣體的各類樣本的數量,這些變壓器溶解氣體含量數據由國家電網有限公司提供,共有609 條。分別從上述的6 種類型樣本中提取1 條氣體成分數據進行歸一化處理,表2 展示了這些氣體體積分數數據歸一化前后的值。 表2 歸一化前后氣體體積分數 通過表1 可以發現,最多的正常樣本的數量占了總樣本數的45.48%,而樣本數據最少的局部放電數據卻僅占了總樣本的5.58%。利用這種嚴重不平衡數據集訓練的模型進行故障診斷時,容易導致故障類型數據被誤判為正常數據,因而需要先采用托梅克鏈接移除算法和SMOTE 算法對訓練數據進行預處理。在利用SMOTE 對數據進行均衡化處理時,KNN 的k值基于交叉驗證法進行選擇。此外,將訓練數據集和驗證數據集按7:3的比例進行劃分。表3給出了對訓練數據集均衡化處理前和處理后各類樣本的數量。可以發現基于SMOTE 處理后的各類樣本數據接近平衡,總的訓練樣本得到了擴充。 表3 訓練樣本預處理前后對比 為了直觀體現采樣前后訓練數據的變化差異,對各類數據采樣前后的數據進行主成分分析,并選取前3 個主成分對不同類型數據采樣前后的數據進行可視化,如圖6 所示。從圖中可以看出6 種不同類型的數據在采樣前后的分布特征和變化趨勢大致相同,這表明本文采用的SMOTE 算法在重采樣時能夠很好地保留原始數據的分布特征。 圖6 均衡化前后不同類的樣本數據分布趨勢 首先對ABC 算法的優化效果進行驗證,并將之與常用的粒子群優化算法、遺傳算法進行了對比,其中的參數設置如下:設置ABC 算法中蜜源的位置設置為50,搜索空間的區間為[0,1];粒子群優化算法的種群設置為20,學習因子c1和c2均取值為2,粒子的速度上限和下限分別為0 和1;遺傳算法的交差概率為0.6,變異概率為0.15;所有優化算法的迭代次數均為500。設置BP 神經網絡的輸入層節點數為5,輸出層節點為1,隱藏層節點數根據經驗公式設置為12。基于上述不同的優化算法對BP 神經網絡的連接層權值和閾值進行尋優,圖7給出了3種不同優化算法訓練時的BP 神經網絡的均方誤差隨迭代次數的變化曲線。 從圖7 中可以看出人工蜂群算法的尋優效率比其他兩種方法高,僅經過56 次迭代即將誤差從最初的2.176降到0.2以下,期間雖有波動,當整體趨勢平緩。粒子群優化算法雖然前期收斂速度快,但后期比較平緩,可能已經陷入局部最優。遺傳算法前期的收斂速度較慢慢,且中間存在停滯階段,雖然后期通過變異也達到與前兩種優化算法達到相同的效果,但整體效果相比另外兩種方法稍差。 圖7 不同優化算法的誤差曲線 進一步,基于驗證數據集對所提方法的故障檢測準確率進行驗證。同樣,采用KNN 和SVM 算法構建分類模型與本文所構建的模型進行對比。圖8 和圖9 分別給出了訓練數據均衡化前后基于不同模型分類的混淆矩陣,從圖8 可以發現基于原始數據訓練的模型,使得許多故障被診斷為正常狀態,尤其是局部放電故障(P類),幾乎全被視為正常狀態。相反,從圖9 的混淆矩陣的對角線可以看出,利用均衡化之后的數據訓練的模型其故障的準確性有了明顯提高,尤其是本文所提出的蜂群算法與BP 神經網絡相結合的故障診斷模型誤診比例明顯少于另外兩種模型。這表明基于優化過的BP 神經網絡模型在對不同類型故障的診斷準確性上比KNN和SVM高。 圖8 基于原始數據的測試結果 圖9 基于均衡化數據的測試結果 表4 分別給出了基于驗證數據集的不同模型故障診斷準確性的綜合評估指標。可以看出以原始數據作為訓練數據時,3 種模型的分類效果并不理想。3 種模型的宏平均F1指標分別為0.593 4,0.595 2,0.625 7。經過SMOTE 算法擴充了少數類樣本之后,3 種模型的宏平均F1指標分別為0.820 3,0.799 3,0.804 4。評估指標也證明了所提的人工蜂群算法與BP 神經網絡相結合的故障診斷模型具有較好的準確性。 表4 基于不同模型的性能測試結果 針對變壓器的故障診斷中不平衡數據導致少數類故障識別準確率低的問題,從數據角度提出來一種基于托梅克鏈接移除算法和合成少數類過采樣技術相結合的數據均衡化方法,該方法能夠在保留少數類樣本分布特征不變的情況下有效擴充數據的規模。從算法方面提出了人工蜂群優化算法和BP 神經網絡相結合的故障診斷法方法來對不同類型變壓器故障進行診斷。基于實際的電力變壓器油樣監測數據,對所提方法的有效性進行了驗證,實驗結果表明本文所提的方法的故障診斷準確性比基于KNN 和SVM的故障診斷模型更高。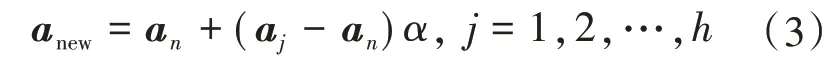
1.3 托梅克鏈接移除
2 基于ABC的BP神經網絡算法
2.1 ABC優化算法
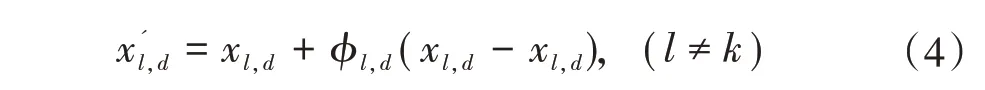
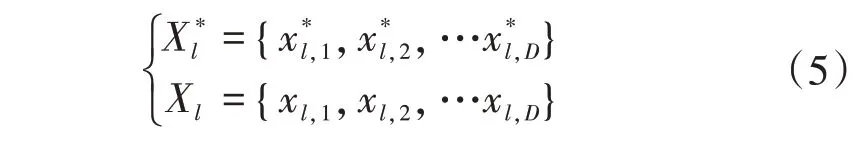

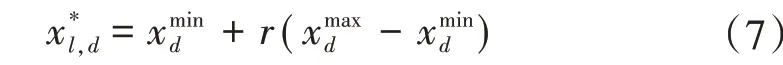
2.2 BP神經網絡參數優化
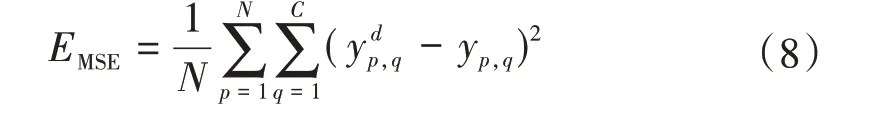

2.3 模型的評價指標
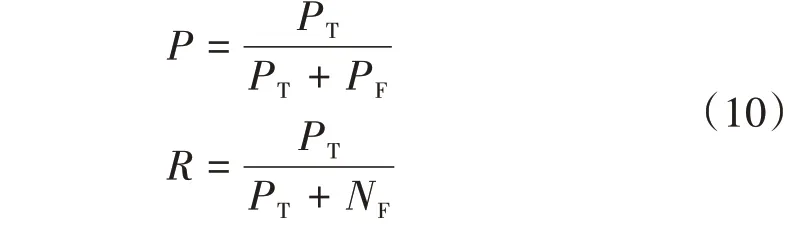

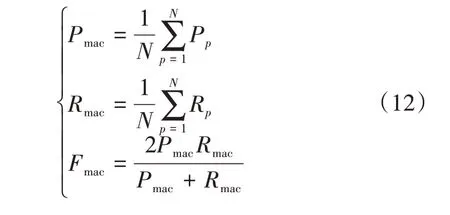
3 算例研究
3.1 故障特征的選取與標簽分類
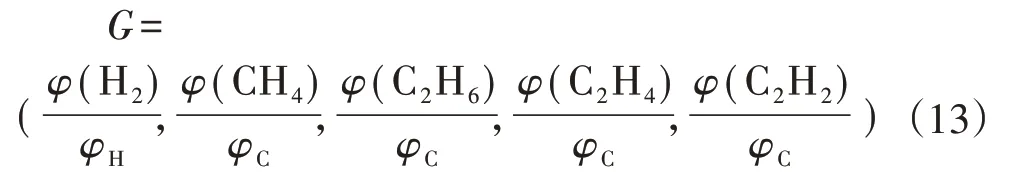
3.2 不平衡數據的處理

3.3 故障診斷

4 結語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
通信電源技術(2018年3期)2018-06-26 06:33:30
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
