基于深度學習和圖像識別的智能衣柜設計
2022-04-29 05:43:02祝景月呂曉晨姜穎道
科技創新與應用 2022年10期
祝景月,呂曉晨,姜穎道
(青島黃海學院,山東 青島 266000)
大部分盲人主要依靠觸感來挑選衣服。也有部分盲人依靠其他的幫助,通過有盲文的衣服或他人的幫助選擇衣服。但是,為盲人準備的有盲文的衣服明顯較少,因此他們很難獨立完成穿衣。因此,本文在對現有市場智能衣柜進行分析的基礎上,設計一種基于深度學習和圖像識別的物聯網智能衣柜。使用者挑選衣服,通過對話請求想要的功能。衣柜進行語音解讀和服裝拍攝等,根據要求將結果輸出到語音。執行這些功能的智能衣柜命名為“小璐”。
“小璐”通過多種功能支持用戶。第一,使用者打開衣柜門時,衣柜內部的LED燈照亮衣柜內部,并幫助拍攝時出現正確的衣服。第二,測量衣柜內部的溫度和濕度。濕度升高時,通過風扇換氣,降低衣柜濕度,防止衣服受損。第三,通過語音識別來執行各種功能。通過語音識別“小璐”來運行衣柜,并要求執行用戶想要的功能。最后對掛著的衣服進行深度學習和圖像識別,判斷衣服的信息。通過要求功能,廣角攝像機把拍攝的圖像傳送到云服務器,構建深度學習模型預測信息并通過揚聲器輸出服裝的顏色、種類、屬性等信息。
1 服裝信息識別的數據集
“小璐”智能衣柜最重要的功能是識別衣服的信息。為了識別衣服的信息,利用TensorFlow和Keras庫[1]建立了適用CNN算法的深度學習模型。另外,為了讓模型學習,利用香港中文大學多媒體研究所開發的通過信息采集收集的大規模服裝圖像數據的“DeepFashion DataSet”[2],如圖1所示。

圖1 類別和屬性預測數據
“DeepFashion DataSet”共有5個可執行的數據。“小璐”智能衣柜使用屬性預測數據來實現衣服信息識別模型。屬性預測數據共有28 922個服裝圖像和標有50個服裝類別以及1 000個服裝屬性標簽。但是標簽存在一些不正確的數據,導致準確度下降。因此,本文以衣服的種類,按照屬性分類學習數據,實現對衣服分類預測模型。衣服的屬性是將1 000個屬性分為5個屬性類型,只學習約200個屬性,實現屬性預測模型。最后以一套衣服、上衣、下衣區分的數據為基礎,實現上下衣預測模型。
2 識別服裝信息的算法
“小璐”智能衣柜通過卷積神經網絡(Convolutional Neural network,CNN)[3]算法實現識別模型。CNN是主要用于圖像分類的算法,是直接輸入圖像像素值,分類屬于哪一類的算法。
如圖2所示,CNN將圖像的邊緣分別進行整合,獲得強調邊緣的形象。之后通過整合或過濾獲得的特性地圖,通過活性函數激活后輸出,并通過Pooling技術減少特性地圖的大小。這些特性地圖再次重復前面的過程,將區域特性地圖打造成全面特性地圖,形成更高層次的特性。最后通過最終制作的特性地圖進行分類工作。
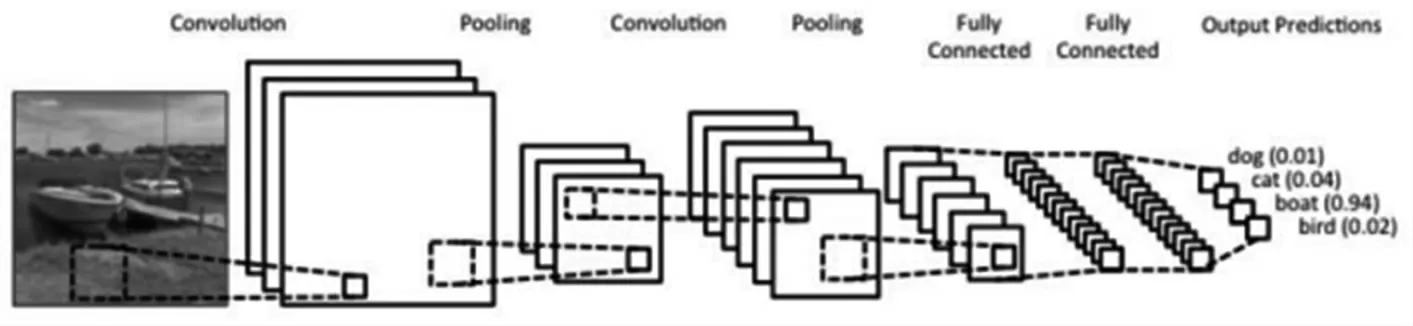
圖2 基于CNN的特征地圖提取
3 識別服裝信息的庫
本文采用TensorFlow和Keras庫來實現識別服裝信息的CNN模型。TensorFlow是谷歌開發的機器學習用引擎,是為了應用于深度學習而開發的開源軟件,并提供有關圖像處理的基本庫和學習的CNN算法。TensorFlow是執行Keras庫的基礎,而Keras是由Python語言編程的開源神經網庫。Keras能讓深度學習的實驗快速進行并以最小模塊擴展可能性為焦點的庫。“小璐”通過Keras提供的模型庫調用Sequential函數生成線性模型,使用Layers庫調用“Convolution2D、MaxPooling2D、Dropout和Dense”[4]等函數,進行深度學習模型的準確度提高的工作。
4 系統設計與實現
4.1 開發環境
本論文以Arduino和樹莓派(Raspberry Pi)作為“小璐”的硬件部分。另外,根據衣柜門的開/關狀態,利用磁性傳感器來管理衣柜內LED燈光狀態。同時,通過溫濕度傳感器測量衣柜的濕度并控制衣柜的濕度。其硬件與功能、軟件開發環境分別見表1、表2。
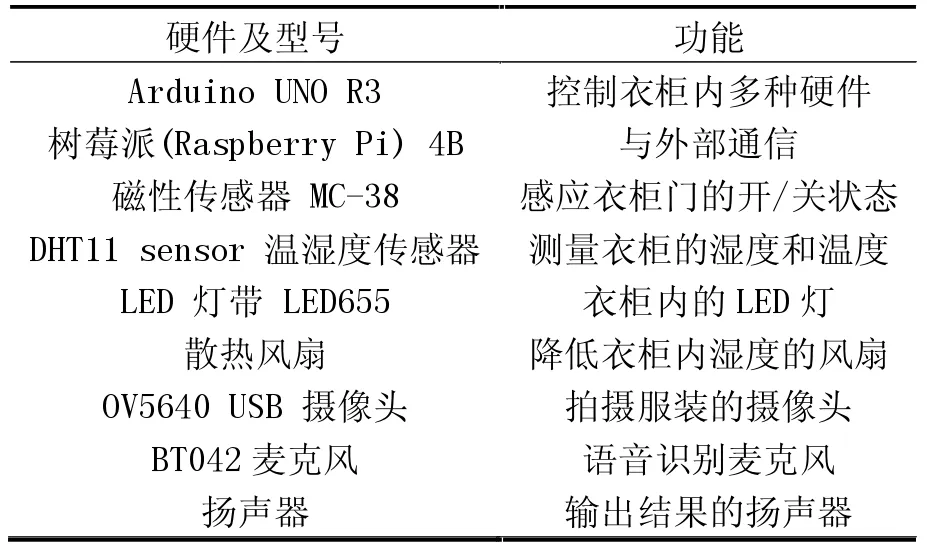
表1 硬件與功能
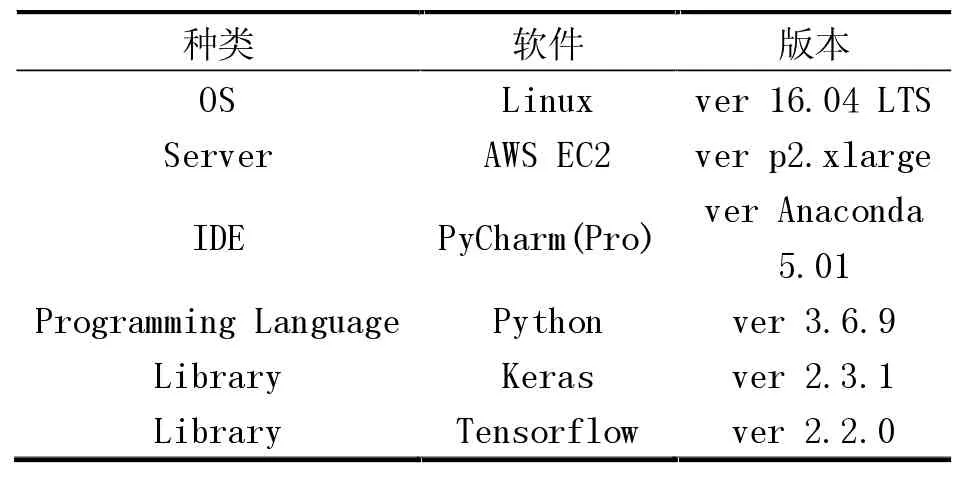
表2 軟件開發環境
4.2 系統設計
系統由多個傳感器連接的Arduino UNO R3、樹莓派4B和存儲深度學習模型的服務器組成。Arduino UNO R3通過樹莓派4B、串行(Serial)通信和I2C通信,樹莓派和服務器是利用Socket通信來接收數據,硬件與軟件系統設計圖如圖3所示。
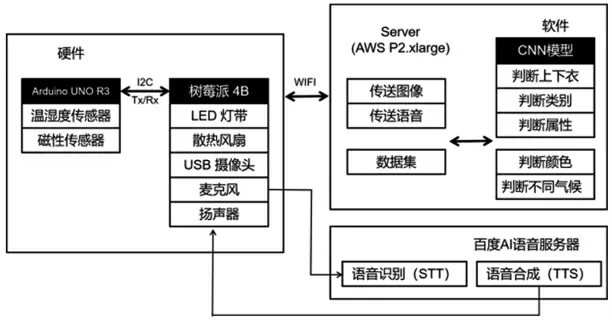
圖3 硬件與軟件系統設計圖
硬件通過Arduino UNO R3進行衣柜內部管理,通過樹莓派與外界進行通信,管理攝像頭、麥克風、揚聲器等。軟件在服務器上執行利用CNN算法對衣服的種類、顏色、圖像等進行識別。另外,Speech-To-Text和Text-To-Speech功能將利用百度AI來進行。
4.3 服裝信息識別模型
本文中,服裝識別模型大致分為2種:通過拍攝的圖像識別模型和通過CNN算法識別衣服信息的深度學習模型。“小璐”的服裝圖像識別模型用于衣服顏色識別。圖像顏色識別模型不使用深度學習,而是通過像素值提取圖像顏色。服裝顏色識別的執行過程如圖4所示。
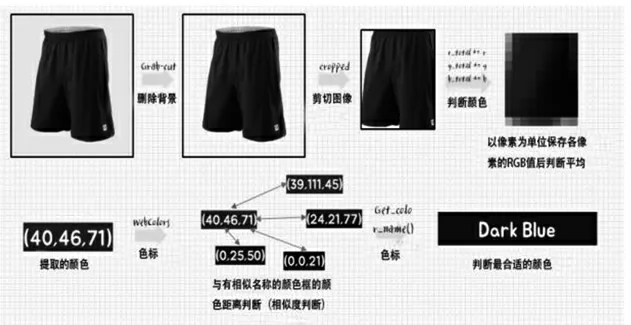
圖4 服裝顏色識別圖
拍攝的照片,通過圖割(Grap-cut)算法[5]去除背景后,剪切保留衣服圖像清晰的中間部分。之后以像素為單位存儲為RGB值,判斷平均RGB值。之后通過WebColours[6],將平均RGB和存儲名字的顏色RGB之間的距離利用歐氏距離測量[7],判斷最相似的顏色。
“小璐”的深度學習服裝識別模型利用CNN算法識別服裝。深度學習服裝識別模型在各層將節點個數以倍數為單位增加,見表3。另外,每層增加Dropout層和Maxpooling2D層,防止學習時可能發生的過擬合問題。

表3 服裝識別的模型級結構
5 實驗及結果
本文為了確認使用者對拍攝照片的認識學習模式是否正確執行,通過改變模型層數量、Dropout的調整、Maxpooling調整進行了實驗。在建立模型時,模型的層數從1層開始,以逐層遞增的方式構建,并每層都采用了Maxpooling。通過這樣的構建、比較的過程,對準確度高的模型,將Dropout逐層添加,完成了模型構建。采用早期停止回調選項,在進行15次學習期間,如果測試集的準確度不高,就停止學習,保證了準確度。通過上述過程進行了70次學習時出現了最合適的準確度和損失度。根據服裝信息識別模型的層數和Dropout程度來表示模型的準確度,見表4。
從表4中可以看到,測試集和訓練集的準確度確認上升到了0.80。在表4中確認的模型中,運用測試集準確度較高的模型進行了實際測試。
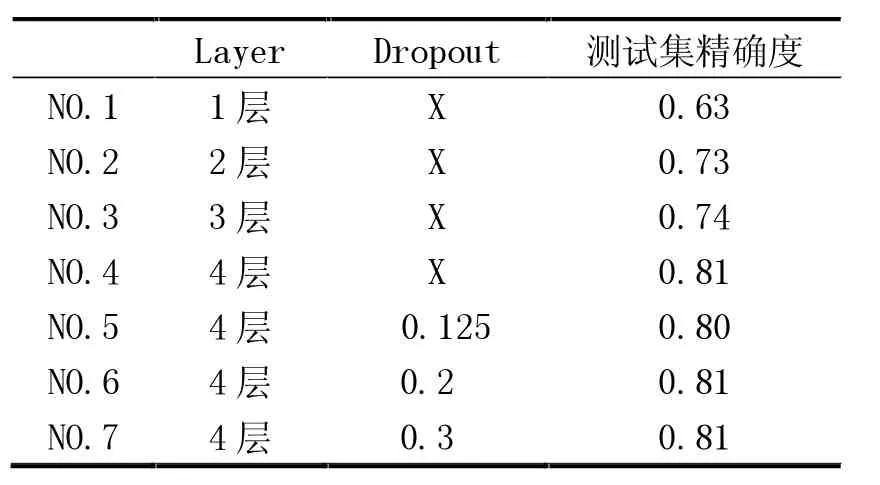
表4 按層和輟學測試集的準確性
6 結論
現有開發的智能衣柜大部分都是以非殘疾人為焦點,管理衣服本身的功能為重點的智能衣柜。本文所設計的“小璐”智能系統通過語音識別、服裝信息識別等多項功能,幫助盲人獨立的穿衣生活。特別是對服裝的種類、圖案、材質、上下衣、顏色等的識別模型,實驗結果準確度高達0.80。同時,為了在識別衣服的過程中提高準確度,調整模型層的數量和Maxpooling。同時,為了保證準確度,采用早期停止回調,Dropout防止過擬合。本文所提出的制作模型的方法不僅可以識別衣服,還可以幫助多種領域的圖像識別深度學習模型的生成研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
