基于輕量級圖卷積網絡的校園暴力行為識別
2022-04-29 01:34:50鄧耀輝
液晶與顯示 2022年4期
關鍵詞:動作
李 頎,鄧耀輝,王 嬌
(1. 陜西科技大學 電子信息與人工智能學院,陜西 西安 710021;2. 陜西科技大學 電氣與控制工程學院,陜西 西安 710021)
1 引 言
我國校園安全在依賴人工巡查的基礎上,逐步向智能化方向發展,有關人臉檢測[1]與人臉識別[2]系統應用已經非常廣泛,然而缺乏成熟的異常行為識別系統。深度學習中基于卷積神經網絡的暴力行為識別方法受圖像光照和顏色等因素影響較大,識別速度和準確率有待大幅提高[3]。人體骨架序列不受光照和顏色影響,可以表征人體關節點和骨架變化與人體行為的關聯信息,但基于骨架數據的圖卷積網絡的方法識別速度和識別率未能滿足實際應用,有望通過改進圖卷積網絡提高實時性和可靠性。
早期人體行為識別通過專家手工設計特征模擬關節之間的相關性實現[4]。Yang 和Tian 采用樸素貝葉斯最近鄰分類器(Na?ve-Bayes-Nearest-Neighbor,NBNN)實現了多類動作的識別[5],但手工提取和調參表征能力有限且工作量大;Li和He 等人通過深度卷積神經網絡(Convolutional Neural Network,CNN)提取不同時間段的多尺度特征并得到最終識別結果,但映射過程信息丟失、網絡參數量龐大[6];Zhao 和Liu 等人通過對原始骨架關節坐標進行尺度變換后輸入殘差獨立循環神經網絡(Recurrent Neural Network,RNN)得到識別結果,表征時間信息的能力增強,但易丟失原始關節點之間的關聯信息[7];Yan 和Xiong 等人首次提出用圖卷積網絡(Graph Convolutional Network,GCN)進行行為識別,避免了手工設計遍歷規則帶來的缺陷[8]。
基于人體骨架的行為識別受光照和背景等因素影響非常小,與基于RGB 數據的方法相比具有很大優勢。人體的關節骨架數據是一種拓撲圖,圖中每個關節點在相鄰關節點數不同的情況下,傳統的卷積神經網絡不能直接使用同樣大小的卷積核進行卷積計算去處理這種非歐式數據[9]。因此,在基于骨架的行為識別領域,基于圖卷積網絡的方法更為適合。從研究到應用階段的轉換,需要在保證準確率的同時實現網絡的輕量化:(1)需要在多種信息流數據構成的數據集上分別多次訓練,融合各訓練結果得到最終結果,增加了網絡參數量和計算復雜度;(2)輸入的骨架序列中,存在冗余的關節點信息,導致識別速度和識別率降低。
2 輕量級圖卷積網絡搭建
2.1 圖卷積網絡
以圖像為代表的歐式空間中,將圖像中每個像素點當作一個結點,則結點規則排布且鄰居結點數量固定,邊緣上的點可進行Padding 填充操作。但在圖結構這種非歐空間中,結點排布無序且鄰居結點數量不固定,無法通過傳統的卷積神經網絡固定大小的卷積核實現特征提取,需要一種能夠處理變長鄰居結點的卷積核[10]。對圖而言,需要輸入維度為N×F的特征矩陣X和N×N的鄰接矩陣A提取特征,其中N為圖中結點數,F為每個結點輸入特征個數。相鄰隱藏層的結點特征變換公式為:

其中i為層數,第一層H0=X;f(·)為傳播函數,不同的圖卷積網絡模型傳播函數不同。每層Hi對應N×Fi維度特征矩陣,通過傳播函數f(·)將聚合后的特征變換為下一層的特征,使得特征越來越抽象。
2.2 輕量級圖卷積網絡框架
為了使人體骨架序列中的動作特征被充分利用,且在識別準確率提高的同時實現動作識別模型的輕量化,本文提出了一種結合多信息流數據融合和時空注意力機制的輕量級自適應圖卷積網絡。以輸入的人體骨架序列為研究對象,首先融合關節點信息流、骨長信息流、關節點偏移信息流和骨長變化信息流4 種數據信息;接著構建基于非局部運算的可嵌入的時空注意力模塊,關注信息流數據融合后人體骨架序列中最具動作判別性的關節點;最后通過Softmax 得到對動作片段的識別結果,網絡主體框架如圖1 所示。
2.3 多信息流數據融合
現階段基于圖卷積的方法[11]多采用在多種不同數據集下多次訓練,根據訓練結果進行決策級融合,導致網絡參數量大。因此,在訓練之前對原始關節點坐標數據進行預處理,實現關節點信息流、骨長信息流、關節點偏移信息流和骨長變化信息流的數據級融合,減少網絡參量,從而降低計算要求。
人體骨架序列關節點的定義如公式(2)所示:
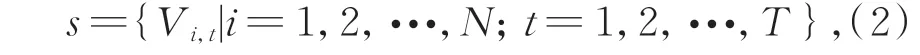
其中:T為序列中的總幀數,N為總關節點數18,i為在t時刻的關節點。融合多信息流之前,需要進行骨架序列s的多樣化預處理。關節點信息流由人體姿態估計算法OpenPose 獲取到的18 個關節點坐標得到,相對于動作捕獲設備成本大幅降低[12-13]。其他信息流數據定義如下。
骨長信息流(Bone Length Information Flow):將靠近人體重心的關節點定義為源關節點,坐標表 示 為Vi,t=(xi,t,yi,t);遠 離 重 心 點 的 關 節 點 定位 為 目 標 關 節 點,坐 標 表 示 為Vj,t=(xj,t,yj,t)。通過兩關節點作差獲取骨長信息流:

關節點偏移信息流(Joint Difference Information Flow):定義第t幀的關節點i的坐標表示為Vi,t=(xi,t,yi,t),第t+1 幀 的關節點i的 坐 標表示為Vi,t+1=(xi,t+1,yi,t+1),關 節 點 偏 移 信 息 流 可通過對相鄰幀同一關節點坐標位置作差獲得:
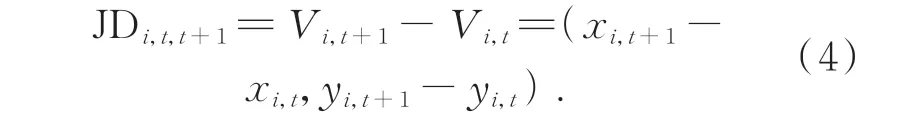
骨長變化信息流(Change of Bone Length Information Flow):相鄰兩幀中,同一節骨骼由于動作變化導致所表現出的長度不同,由公式(3)定 義 第t幀 的 骨 長 信 息 流 為Bi,j,t,則 第t+1 幀 的骨 長 信 息 流 為Bi,j,t+1,通 過 對 相 鄰 幀 同 一 骨 骼 長度作差獲得骨長變化信息流:

如圖2 所示,根據對關節點信息流、骨長信息流、關節點偏移信息流和骨長變化信息流的定義,將多數據流加權融合成單一的特征向量,骨架序列維度由4×T×J×C1變為1×T×J×4C1:
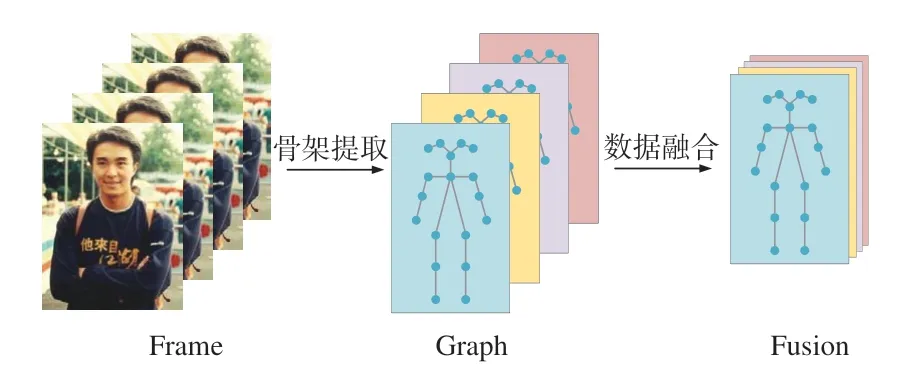
圖2 信息流數據融合Fig.2 Data fusion of information flow

其中:權重ω1~ω4由關節點偏移度σ1(σ1∈[0°~360°])和骨長變化度σ2(σ2∈[0~100%])決定,σ1為前一 幀 坐 標 點Vi,t與 后 一 幀 坐 標 點Vi,t+1分 別 和 坐標原點所構成直線的夾角,σ2如式(7)定義:

式中:絕對值運算代表骨骼長度,當σ1≥30°且σ2≤50%時,ω1和ω3權值為2,ω2和ω4權值為1;當σ1≤30°且σ2≥50%時,ω1和ω3權值為1,ω2和ω4權值為2;當σ1和σ2都小于閾值時,權值均為1;當σ1和σ2都大于閾值時,權值均為2。通過計算關節點偏移程度以及骨長變化程度,為變化程度大的信息流數據賦予了更高的權重,從而增強了信息流對動作的表征。再使用融合后的單一特征向量表示多信息流數據,將訓練次數由4 次減少為1 次,降低了總體參數量,從而提高網絡運算速度。
2.4 時空注意力模塊構建
在保證網絡運算速度提升的基礎上,也要保證動作識別的準確性。一段人體骨架序列包含時間域和空間域的所有信息,但是只有對拳打、腳踢和倒地動作具有判別性的關節點關聯信息值得關注,注意力機制大多只是去除無關項而關注感興趣動作區域,但真正的冗余信息來自兩個方面:(1)拳打動作發生時,只有肩膀、手肘和手腕3 個關節點相互之間相關性強;腳踢動作發生時,只有髖、膝蓋、腳踝跟3 個關節點相互之間相關性強,這些關鍵關節點與其他關節點相關性弱或不相關。(2)受到暴力拳打或腳踢而倒地后,各關節點偏移幅度較小,前后幀的各關節點相關性幾乎不變,無需對后一幀骨架信息進行提取。
將每個關節點偏移度σ1≥30°的關節點定義為源關節點,每次選取一個源關節點,其他關節點則為目標關節點,神經網絡中的局部運算方法只能對目標關節點遍歷后單獨計算兩兩的相關性,使源關節點丟失全局表征能力。為了表征所有目標關節點對源關節點的相關性,如圖3 所示,將非局部運算(Non-local operations)的思想融入時空注意力模塊,并在特征輸入后添加尺寸為2×2、步長為2 的最大池化層(Maxpool layer),以保證壓縮數據和參數數量的同時盡可能保留原有特征。

圖3 時空注意力模塊Fig.3 Spatio-temporal attention module
時空注意力模塊(Spatio-temporal Attention Module,STA)包含一個空間注意力模塊和時間注意力模塊,其中空間注意力模塊(Spatial Attention Module,SA)捕獲幀內關節相關性,時間注意力模塊(Temporal Attention Module,TA)捕獲幀間關節的相關性,最終二者與輸入特征相加融合。時空注意力模塊輸出特征的維度和輸入相同,因此可以嵌入圖卷積網絡的網絡結構之間。模塊功能的實現分為4 個步驟:
(1)輸入特征X的維度為T×N×C,其中T、N和C分別對應幀、關節和通道的數目,將空間注意力模塊的輸入特征表示為zs=[z,z,...,z]∈RT×N×C。
(2)將特征嵌入到高斯函數(θ和φ,卷積內核尺寸1×1)中計算任意位置兩個關節i和j的相關性,由j進行枚舉,得到關節點i的加權表示:

其中:z和z分別表示關節點i和j的特征;函數g用來計算關節點j特征表示,g(z)=Wz,W是待學習的權重矩陣;高斯函數f定義為:
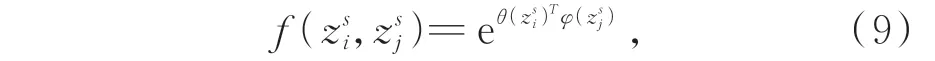
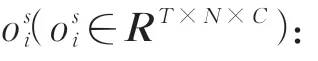


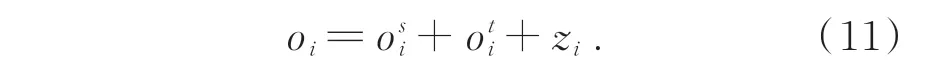
通過基于非局部運算的注意力機制得到具有判別性的關節點時空關聯信息,去除了動作區域無關項和輸入的冗余關節點信息的干擾,減少了不必要的計算,從而提高了準確率。
2.5 時空特征提取模塊構建
為了提取骨架序列在空間和時間維度上的特征,首先利用時空圖卷積網絡和空間劃分策略對動態骨架進行建模,原始表達式為:
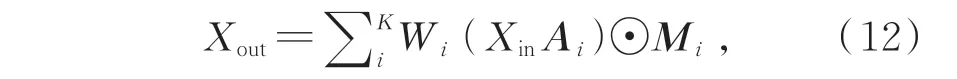
其中,Xin和Xout分別為圖卷積輸入和輸出特征,K為空間域卷積核尺寸,Wi為權重,Ai為關節點i的鄰接矩陣,⊙代表點乘,Mi為賦予連接權重的關節點映射矩陣。
使用預先定義好的骨架結構數據無法對所有未知動作準確識別,因此需要設計一種具有自適應性的鄰接矩陣Ai,使得圖卷積網絡模型具有自適應性。因此,為了在網絡學習中改變骨架序列圖的拓撲結構,將式(12)中決定拓撲結構的鄰接矩陣和映射矩陣分成Ai、Hi和Li,自適應圖卷積模塊框圖如圖4 所示,輸出特征重新構造為:

圖4 自適應圖卷積模塊Fig.4 Adaptive graph convolutional module
Xout=∑i KWi Xin(Ai+Hi+Li). (13)
圖4 中θ和φ即式(9)中高斯嵌入函數,卷積內核尺寸為1×1;第一部分Ai仍為關節點i的鄰接矩陣;第二部分Hi作為對原始鄰接矩陣的加法補充,能通過網絡訓練不斷迭代更新;第三部分Li由數據不斷驅動更新來學習連接權重,關節點相關性可由式(8)計算得到后與1×1 卷積相乘得到相似性矩陣Li:
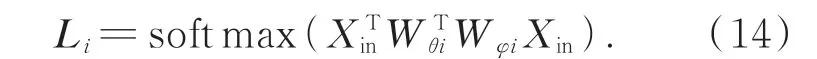
通過以上計算,構建出具有自適應性的圖卷積模塊,接下來對骨架序列包含的時空信息進行提取。
本文提出的時空特征提取模塊如圖5 所示。在每次完成卷積操作后通過BN(Batch normalization)層將數據歸一化,再通過ReLU 層提高模型表達能力。可嵌入的時空注意力模塊STA 已在2.4 一節中搭建完成,將特征輸入提取模塊后對感興趣動作關節點進行提取。接著通過具有自適應性的GCN 在空間維度上獲得骨架數據中同一幀各關節點的相關性,通過時間卷積網絡(Temporal Convolutional Network,TCN)在時間維度上獲得相鄰幀同一關節點的關系。丟棄層(Dropout)減少隱層結點的相互作用避免了圖卷積網絡的過度擬合,參數設置為0.5,同時為了增加模型穩定性進行了殘差連接。
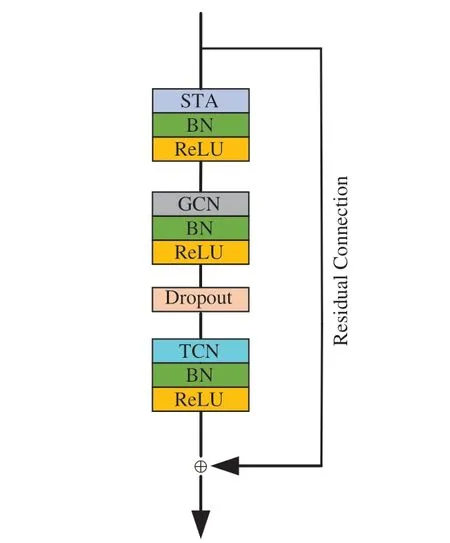
圖5 時空特征提取模塊Fig.5 Spatio-temporal feature extracting module
2.6 整體網絡結構搭建
如圖6 所示,將9 個時空特征提取模塊B1~B9進行堆疊,從特征輸入X到行為標簽Label 輸出方向上,BN 層用于骨架圖輸入后進行標準化,B1~B3輸出特征維度為Batch×64×T×N,B4~B6輸出特征 維度為Batch×128×T/2×N,B7~B9輸出特征維度為Batch×256×T/4×N,其中通道數分別為64,64,64,128,128,128,256,256,256。在空間和時間維度上應用全局平均池化操作(Global Average Pooling,GAP)將樣本的特征圖大小進行統一,最終使用softmax層得到0~1 的數據進行人體行為的識別。

圖6 整體網絡架構Fig.6 Overall network architecture
3 實驗結果與分析
3.1 實驗配置
實驗平臺的配置為8 代i7 CPU,64 G 內存,4 TB 固態硬盤存儲,顯卡為RTX2080Ti。深度學習框架為PyTorch1.3,Python 版本為3.6。優化策略采用隨機梯度下降(Stochastic gradient descent,SGD),每批次訓練樣本數(Batch size)設置為64,迭代次數(Epoch)設置為60,初始學習率(Learning rate)為0.1,Epoch 達到20 以后學習率設置為0.01。
3.2 行為識別實驗
3.2.1 校園安防實景測試
本文面向實際應用,對校園馬路、操場和湖邊等不同場景制作了12 000 個視頻片段,拳打、腳踢、倒地、推搡、打耳光和跪地6 種典型動作各2 000 個,單個時長不大于5 s。所有人員身高、體重和身體比例等方面有所差異,以增強模型的泛化能力。根據實驗配置進行訓練,圖7 為模型的訓練損失與綜合測試準確率的變化曲線。
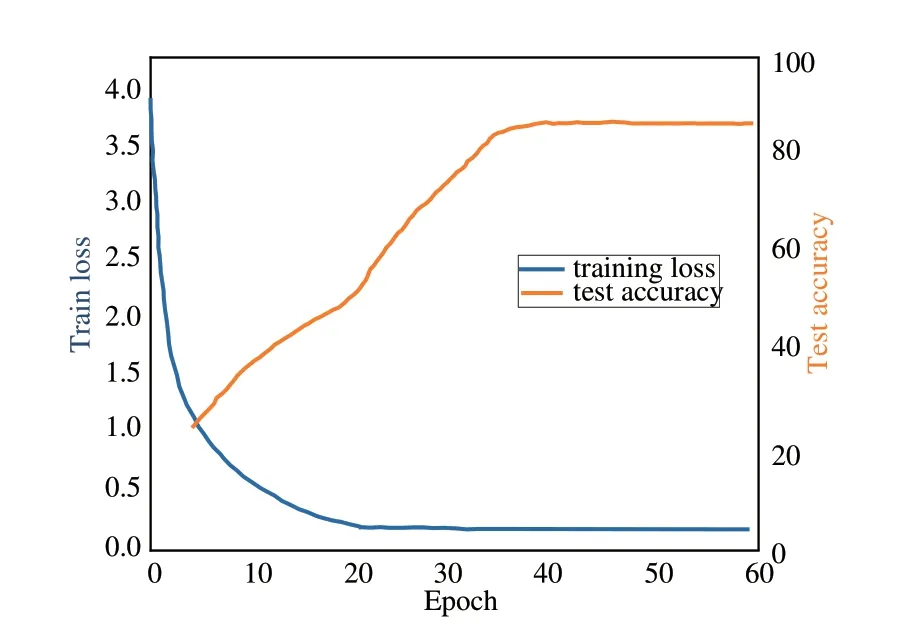
圖7 模型訓練損失與測試準確率變化圖Fig.7 Variation diagram of model training loss and test accuracy
可以看出隨著迭代次數的增長,模型的訓練損失逐漸下降。當epoch 在20 左右時,由于學習率的下降,測試準確率開始大幅提高;當epoch 超過35 之后,訓練損失與測試準確率幾乎保持不變。使用訓練好的模型分別對6 類動作對應的測試集進行測試,主要識別過程如圖8 所示。

圖8 6 種典型動作識別過程Fig.8 Six typical action recognition processes
圖8 中處理的5 組動作片段從左至右分別為拳打和腳踢、倒地、推搡、打耳光及跪地,圖8(a)是原視頻;圖8(b)是對輸入的含有拳打和腳踢動作的視頻片段使用OpenPose 進行人體關節點提取,正確匹配各關節點后得到人體骨架;圖8(c)是將骨架序列輸入本文改進的時空圖卷積網絡得到動作片段的識別結果。改進后模型的處理速度最大可達20.6 fps,對校園安防實景中拳打、腳踢、倒地、推搡、打耳光和跪地6 種典型動作識別準確率分別為94.5%,97.0%,98.5%,95.0%,94.5%,95.5%,測試結果如表1 所示。

表1 6 種典型動作識別結果Tab.1 Six typical action recognition results
為了驗證不同體型(身高、體重和肩寬表示)人員對識別準確率存在影響,選取參與數據集制作的1~6 號實驗人員,每次使用由單一實驗人員獲取的6 種典型動作片段作為訓練集,將由其他5 個實驗人員獲取的6 種動作片段作為測試集,并記錄對所有動作的平均識別準確率,實驗參數及結果如表2 所示。
由表2 數據可知,使用單一實驗人員所拍攝的6 類動作片段作為數據集進行訓練,并分別對其他人員的動作片段測試,測試結果最佳僅為85.6%,而使用所有實驗人員視頻片段識別準確率在94.5%以上,說明了不同人員體型的差異性可以增強模型的泛化能力,即魯棒性。
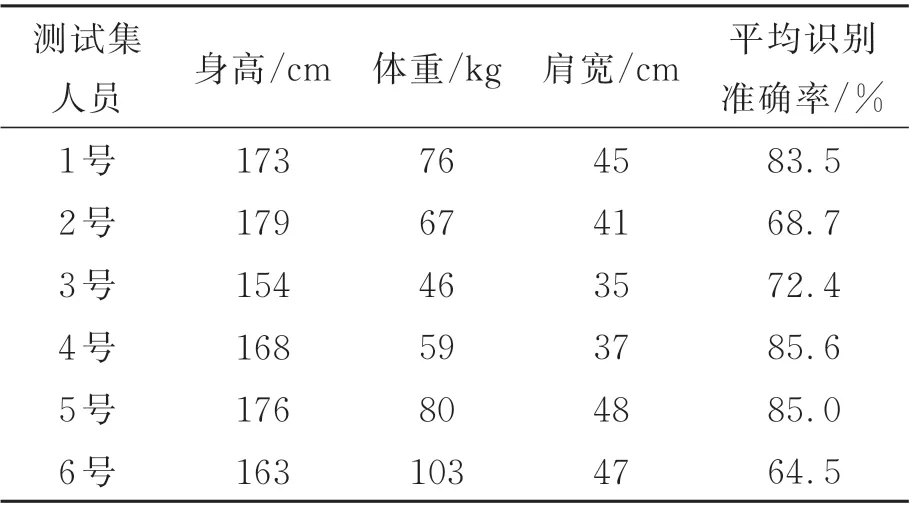
表2 不同體型人員動作識別結果Tab.2 Action recognition results of personnel with different body types
表2 的1~6 號 實 驗 人 員 中,2 號 的 體 型 為179 cm/67 kg,身材過瘦;3 號的體型為155 cm/46 kg,身材矮小,但身高體重比例正常;6 號的體型為163 cm/103 kg,身材肥胖;1 號、4 號和5 號體型基本正常。不同體型的人做同一種動作時,姿態檢測算法獲取的18 個人體骨骼點坐標有差異,從而骨長也會產生差異,關節點信息流、骨長信息流、關節點偏移信息流和骨長變化信息流4 種數據信息也有區別。因為2 號過瘦,各關節點坐標較為集中,而6 號過胖,各關節點坐標較為分散,導致2 號和6 號的平均識別準確率最低,僅為68.7%和64.5%;而3 號身材比例正常,但身高過于矮小,也導致了關節坐標點分布不均勻,72.4%的準確率低于其他正常體型。
綜上,在數據集的制作過程中所有人員體型差異的多樣性可以增強模型的泛化能力,實驗結果也表明本文方法可快速有效地識別出校園暴力的典型動作。
3.2.2 方法對比實驗
為了驗證本文方法的有效性,采用具有挑戰性的UCF101 數據集進行行為識別對比實驗。該數據集有101 類動作,13 320 段視頻,在人員姿態、外觀、攝像機運動狀態、和物體大小比例等方面具有多樣性。
按照6∶2∶2 的比例,參與訓練和驗證的視頻數據10 656 個,測試視頻2 664 個,使用表3中5 種方法進行對比實驗,在當前配置下對視頻片段處理速度由9.2~15.5 fps 最大提高至19.3 fps,對數據集中101 類動作平均識別準確率以及參數量變化對比結果如表3 所示,并在表4 中給出了數據集中6 種動作的識別準確率。
表3 數據表明:本文方法(無注意力模塊)相對于兩種卷積神經網絡的方法,參數量分別減少約92.6%和94.7%,而識別準確率提高21.4%和4.0%;相對于改進前時空圖卷積網絡的方法,參數量減少約59.6%,而準確率提高1.2%。說明本文的多信息流數據融合方法可有效減少網絡參數量,實現網絡輕量化。其中,使用基于非局部運算的時空注意力機制相對于未使用時參數量減少約37.6%,準確率提高2.9%,說明改進后的時空注意力機制可有效減少冗余關節點信息,提高了特征的利用率,從而提高了識別準確率。表4 數據列出了改進后方法在UCF101 數據集中6 種動作的識別準確率。由于該數據集中動作片段來源于不受約束的網絡視頻,存在相機運動、部分遮擋和低分辨率等影響導致視頻質量差,實驗中在OpenPose 進行人體關節點提取階段csv 文件中所存的關節點坐標有部分缺失,因此相較于表1 中實測數據集識別準確率均偏低。

表3 不同識別方法的對比結果Tab.3 Comparison results of different recognition methods
綜上,本文方法在保證準確率提升的同時實現了網絡的輕量化,從而提高了可靠性與實時性。
4 結 論
針對校園智能安防識別速度和識別率不高導致可靠性和實時性差的問題,本文提出了一種基于輕量級圖卷積的人體骨架數據的行為識別方法,通過多信息流數據融合與自適應圖卷積相結合的方式,同時通過嵌入時空注意力模塊提高特征的利用率,在校園安防實景中對拳打、腳踢、倒地、推搡、打耳光和跪地6 種典型動作識別準確率分別為94.5%,97.0%,98.5%,95.0%,94.5%,95.5%,識別速度最快為20.6 fps,且驗證了模型的泛化能力。同時在行為識別數據集UCF101 上驗證了方法的通用性,可以擴展至人體其他動作,在參數量比原始時空圖卷積網絡減少了74.8% 的情況下,平均識別準確率由85.6% 提高到89.7%,識別速度最大提高至19.3 fps,能夠較好地完成校園實際安防中出現最多的典型暴力行為識別任務。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
