層次聚類算法的改進研究
2022-04-29 19:52:32何雨軒
計算機應用文摘 2022年21期
何雨軒
關鍵詞:層次聚類;聚類;改進算法;連通度
1引言
聚類是一種常用的無監督機器學習方法,在模式識別、數據挖掘、計算機視覺、自然語言處理等方面都有廣泛的應用。聚類算法的種類較多,原理也各不相同。例如,有基于密度、劃分、層次、圖論、網格、深度學習的聚類。每種聚類算法都有自己的特點和適用場景。層次聚類就是其中一種較為典型的算法,它常用于財務分析[1]、社區健康管理、醫學研究、時間序列預測等。
與其他類型的聚類算法相比,層次聚類具有許多優點。首先,它具有檢測“嵌套類簇”的能力。其次,它構建了一個樹狀的聚類層次樹,可以顯示連續步驟的聚類過程。由于類簇可以在二維圖中可視化,因此,用戶可以直觀且容易地理解數據集的底層結構。再次,利用樹狀圖也可以很容易地檢測出異常值。最后,它不需要預先指定類簇的數量,這是一個非常重要的優勢,因為確定簇的數量是聚類中最難的問題。
層次聚類的特點是聚類過程體現了聚類數量的漸變,一共有兩種漸變方式:一是聚類數量從小到大,從最初所有的樣本屬于同一個類簇,逐漸分裂成兩個、三個類簇,一直分裂到每個樣本屬于一個單獨的類簇;二是聚合的方式,最初每個的樣本都各自屬于一個不同的類簇,然后將其中最相似的兩個類簇合并成為一個類簇,接著逐步聚合,直到所有的類簇合并為一個類簇[2]。
層次聚類主流的聚類方式是聚合,當前代表性的算法包括AgglomerativeClustering,BIRCH,CURE,ROCK,Chameleon。這些經典的層次聚類算法不僅有自己的優點,也有明顯的缺陷。例如,非球形的數據集聚類準確性較差,以及時間復雜度比較高。后來,有一些學者對經典層次聚類做了改進,如周維柏等[3]提出了一種改進的模糊層次聚類算法:張春英等[4]提出了一種面向不完備數據的集對粒層次聚類算法:王志飛等[5]提出了凝聚中心猶豫度恒定的模糊層次聚類算法。這些算法雖然部分解決了層次聚類的問題,但是效果并不是非常好。
本文提出了新的改進算法,在各個類簇合并的過程中,通過綜合判斷各個相鄰類簇的相似性,并在不同的階段使用不同的計算方法,從而提升聚類精度的聚類效率。
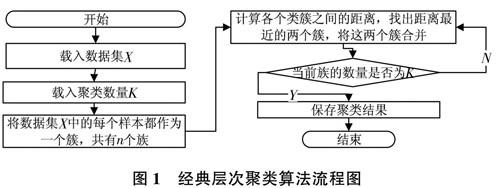
2經典層次聚類算法
目前,常用的層次聚類算法都是用聚合的方式進行聚類[6],如Python下常用的一些層次聚類算法:scipy.cluster.hierarchy.linkage,sklearn.cluster.AgglomerativeClustering。這些算法對包含N個數據的算法的流程如圖1所示。
各個類簇之間距離的計算方式較多,其中包括單鏈接、全鏈接、平均鏈接。具體而言,假設有兩個類簇Ci,Ci,它們之間的距離用不同方法計算,結果分別不同。
因為單鏈接方法只考慮兩個類簇中最近的樣本,不考慮其他樣本,所以會導致相似性較差的樣本聚合在一起。全鏈接方法只考慮兩個類簇中最遠的樣本,導致它只適合球形數據的聚類。平均鏈接方法是這兩種方法的折中。
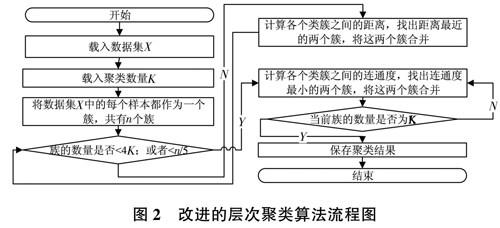
3改進層次聚類算法
為了彌補經典層次聚類的缺陷,本文提出了一種改進的算法。改進算法也是以聚合的方式進行聚類,在聚類的過程中,前期使用單鏈接的方法判斷兩個類簇是否可以合并。事實上,在聚類前期,類簇內包含的樣本數量較少,使用單鏈接或者全鏈接方式基本沒有差別。當聚類的數量小于樣本的1/5或者達到目標類簇數量K的4倍時,聚類使用新的方法判斷兩個類簇是否可以合并。這個新的方法就是連通度。
連通度是兩個類簇之間的距離和密度的綜合衡量,其中距離計算用類簇之間樣本的最小距離表示。至于密度計算,首先以計算出類簇之間最小距離的中心點作為圓心,然后用三倍最小距離作為半徑來計算該圓形內部的樣本數量。
4實驗
為了驗證改進算法的有效性,本文設計了相關實驗進行驗證。實驗環境的配置如下:計算機的操作系統為Windowsl0:計算機的CPU為Intel Core i3-9IOOF3.6GHz;硬盤為2TB;內存為8GB。
改進的層次聚類算法采用Python3.6編程實現。實驗中,用于對比的經典層次聚類算法使用sklearn. cluster. AgglomerativeClustering函數,并分別用單鏈接、全鏈接、平均鏈接的距離計算方法聚類。
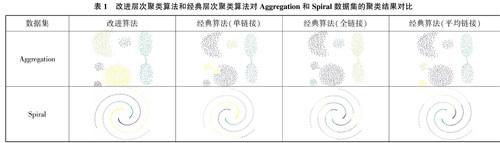
4.1模擬數據集的聚類實驗
實驗用的模擬數據集選用Aggregation和Spiral。本文提出的改進層次聚類算法和經典層次聚類算法的單鏈接、全鏈接、平均鏈接方法對Aggregation和Spiral的聚類結果如表1所列。由表1可知,本文提出的層次聚類改進算法效果最好。經典層次聚類算法使用的單鏈接方法和全鏈接方法對兩個數據集的聚類結果都較差,使用平均鏈接方法對Aggregation聚類效果尚可,對Spiral的聚類效果較差。
本文提出的改進層次聚類算法和經典層次聚類算法對數據集Aggregation和Spiral的聚類結果F值如圖3所示。通過對比兩個數據集上各種算法的聚類F值可知,改進算法比經典算法的效率至少提高了18.5%。
4.2真實數據集的聚類實驗
真實數據集采用了UCI(University ofCalifornialrvine)提供的公開數據。這些數據是通過在真實世界的測量、收集而獲得,所以更具有參考意義。在UCI數據集中,本文選擇了Abalone和Segmentation。
聚類結果評價指標見表2,其中包括調整蘭德系數(ARI,Adjusted Rand index)、標準互信息素(NMI,Normalized Mutual Information)、F值、準確率(Accuracy)。
通過對比表2中的各個聚類指標可知,在單鏈接、全鏈接和平均鏈接方法方面,改進層次聚類算法明顯優于經典層次聚類算法。這說明在真實數據集上,改進層次聚類算法的聚類效果更好。
5結束語
層次聚類是一種應用廣泛的經典算法,但是其自身也有明顯的缺陷,如對非球形數據聚類效果較差。本文提出了一種改進算法,通過在聚類的不同階段使用不同的類簇合并策略來改進算法,在聚類的開始階段,使用單鏈接的方法;在聚類的后期,使用連通度的方法。通過對模擬數據集Aggregation和Spiral的聚類實驗,以及對真實數據集Abalone和Segmentation的聚類實驗,驗證了改進算法的有效性。
