英語測試命題中生詞率統計工具的開發與應用
2022-04-29 16:33:39王戰旗
中小學數字化教學 2022年6期
王戰旗


摘要: 在中小學英語閱讀理解命題生詞率控制方面,教師普遍缺乏簡單、高效的生詞率檢測工具,已有生詞率統計方式或者效率低、誤差大,或者流程復雜。為解決此問題,特編制一個專門用于生詞率統計的工具,內嵌人教版小學、初中、高中三套教材的單元詞表,直觀呈現閱讀理解題中的單詞以及生詞,避免因生詞量過大導致題目區分度下降、教學效果不明顯,以及學生學習積極性不高等。
關鍵詞:中小學英語;閱讀理解;測試命題;生詞率;統計工具
英語教學中,測試具有多方面的作用,比如幫助教師了解學生學習進度,為教師教學效果提供評價依據,幫助學生發現學習中的不足,指明下一步學習方向等。可見,測試在英語教學中占據非常重要的地位,并對教學產生重要影響。如果測試題的編制出現問題,不僅會導致師生無法很好地實現預期的測試目標,有時還會對教師教學產生不利的影響[1]。而測試出現問題,有時是因為教師缺乏理論指導,有時則是因為缺乏合理的手段和工具。
閱讀理解是中小學英語測試中的一種重要題型,它考查的是學生的閱讀能力。很多研究表明,影響學生閱讀能力的因素很多,文本中的生詞量則是影響閱讀理解效果的重要因素[2-4]。一項實證研究發現,在不借助詞典等工具閱讀虛構文本的情況下,當生詞率為20%時,被試的閱讀理解情況不佳;當生詞覆蓋率為5%和10%時,只有極少部分人的閱讀理解情況尚可,大部分人的閱讀理解情況依然不理想。經過對數據進行回歸分析,該研究認為只有當生詞率在2%以內時,閱讀者才能不借助任何工具順利地完成閱讀[5]。國內的一項研究也得出了類似結論[6]。
既然詞匯量對閱讀理解的影響如此之大,那么英語測試就要注意把生詞控制在合理的范圍內,以免學生覺得生詞過多、試題過難,出現“地板效應”。當然,也要避免應檢測的新學詞匯沒有呈現,使試題過于簡單,出現“天花板效應”。
那么,國內教師在英語測試閱讀理解命題中生詞率控制方面的觀念和做法如何呢?本研究首先對我國英語教師進行了問卷調查,發現教師普遍缺乏簡單、高效檢測生詞率的方法,然后介紹目前常見的生詞率統計方式,最后介紹本研究嘗試編制的計算機生詞率統計工具。
一、我國教師英語測試閱讀理解命題中生詞率控制現狀調查和結果分析
為了解國內教師在英語測試閱讀理解命題中生詞率控制方面的觀念和實際做法,筆者在2021年9月做了一次網絡問卷調查,共收到來自全國17個省(自治區、直轄市)的有效問卷708份。被調查者基本信息見表1。
調查結果表明,在708名英語教師和教研員中,54.9%的人(389人)參加過英語測試命題。在這部分被調查者中,99.2%的人(386人)認為“應該把閱讀理解題的生詞率控制在一定范圍內”。持此觀點的386人中,98.2%的人(382人)稱在英語試題編制時會對閱讀理解題的生詞率進行控制。但是在這382人中,63.1%的人(241人)控制生詞率的方式是“進行大致估計,不進行量化判斷”,只有36.9%的人(141人)“通過量化計算”來控制生詞率。其中,62.4%的人(88人)通過人工統計的方式計算生詞率,37.6%的人(53人,占參與過命題者人數的13.6%)使用計算機工具計算生詞率。
對于使用計算機工具控制生詞率的情況,調查問卷進一步提供6個選項(多選題):Word、Excel、安東尼(Anthony)開發的Ant Word Profiler、希特利(Heatley)等人開發的Range、自己開發的工具,以及其他情況。這些選項涵蓋普通的文字工具以及專業的詞匯分析工具,并提供自定義選項。由被調查者的選擇統計情況可知(如圖1),絕大部分人用的是非專業的文字處理工具,如Word、Excel等,使用Ant Word Profiler、Range等專業詞匯分析工具的人非常少,也沒有自主研發工具控制生詞率。
由本次調查可知,英語教師基本上都認為英語測試中的閱讀理解題需要控制生詞率,在實踐中也以某種方式實施。但是大多數教師只是憑感覺和經驗進行大致判斷,只有少數教師通過計算機工具進行量化統計。在使用的工具中,絕大部分教師用的是Word、Excel,只有極個別教師使用比較專業的詞匯分析工具,如Ant Word Profiler、Range等。那么,這些工具是否適用于英語測試題編制中的生詞率統計呢?下面對這些工具的使用方法進行分析。
二、教師常用生詞率統計工具比較
(一)利用Word統計生詞率
用Word進行生詞率統計,基本流程如下:教師準備一份截至目標檢測單元已學單詞的詞表,對閱讀理解題的語篇逐詞查看并判斷,對生詞進行特殊標記,比如用某種顏色突出顯示;對語篇全部完成標記后統計生詞數量;然后利用Word的“字數統計”功能得出總單詞數(在“審閱”選項卡“校對”區,對英文單詞數的統計是統計信息中的“字數”,注意不是“字符數”),生詞總數除以總字數,即可得出生詞率。
(二)利用Excel統計生詞率
使用Excel統計生詞率的流程比較復雜。以下是其中一種統計生詞率的方法。這種方法同樣要求教師準備如前所述的詞表,并且對于任何截至目標單元學生應該掌握的英語屈折變化形式都要包括進來。首先,利用Word的查找替換功能把要檢測生詞率的閱讀理解語篇用空格替換為回車符,使文本呈現一個單詞一行的格式,去掉無關的標點符號;然后,選擇全部文本,粘貼到Excel表格的一列中(比如A列);接著,把準備好的詞表按一個單詞一行的方式放至另一列(比如B列),之后在另一個空列(比如C列)用函數功能對比A列每一個單詞是否出現在B列中,如果出現代表學生學過該詞,未出現則代表這是一個生詞。具體實現對比的函數可以有不同的方式,一種方式如“IF(ISERROR(MATCH(A1, $B$1:$B$X, 0)), "", A1) ”,注意把函數中的X替換為詞匯表的實際長度,即把該公式輸入C列第一行單元格,然后通過快速單元格復制到和語篇列表具有同樣的數量。這個公式利用了Excel的三個函數嵌套實現對比,并把詞表中包含的詞寫入C列,然后計算C列的空格數,除以A列總單詞數,即可得到語篇的生詞率。
(三)利用Ant Word Profiler統計生詞率
除了用常見的文字和電子制表工具統計生詞率外,教師還可用專業的詞匯分析軟件計算生詞率。可以實現該功能的軟件有安東尼編制的Ant Word Profiler[7]和希特利等人編制的Range[8]等。
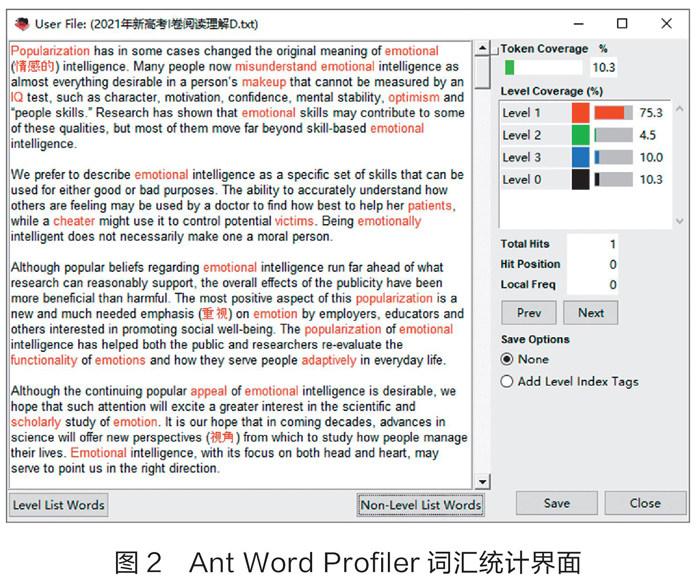
使用Ant Word Profiler統計生詞率,和運用Excel統計生詞率方法一樣,需要準備同樣的詞表,然后按照軟件要求的格式對詞表進行處理(每個單詞的原形形式獨立一行,每個屈折變化形式另起一行后加TAB符后列出),最后把詞表放入一個文本文件。接著,把要分析的閱讀理解題放入另一文本文件并保存。在軟件主界面,清空左下角的分級詞表列表,選擇前面做的詞表文本文件作為詞匯分析的基礎詞表。之后,在左上角的用戶文件區點擊“Choose”按鈕選擇要分析的閱讀語篇文本文件加載,單擊下邊列表框中列出的相應文件,點擊“View”按鈕,彈出新窗口,點擊“Non-Level List Word”,在右上角的“Token Coverage”中顯示的數字即為該語篇的生詞率(如圖2)。
通過對以上三種生詞率統計方法的介紹,我們可以很明顯地看出它們各有優缺點。用Word統計生詞率流程簡單,但是判斷生詞時需要人工,耗時耗力,效率極低,誤差大。用Excel統計生詞率準確率高,但是操作復雜:一是須和Word軟件配合使用;二是需要準備復雜的詞表;三是需要掌握Excel函數的使用方法。用Ant Word Profiler統計生詞率的流程比較簡單,但同樣需要準備復雜的詞表,而且詞表需要按照軟件要求格式處理,對使用者的能力要求較高。實際上,制作已學詞表耗時費力,且不同的單元都需要做新的詞表,對于教師而言過于繁雜。
由上述分析可知,目前教師使用的生詞率統計方式或者效率太低、誤差大,或者流程復雜,且需要教師制作多個已學詞表(如果是以單元檢測為目的,每個單元都需要編制一個詞表)。這或許也解釋了本研究問卷調查中發現的一個有趣的現象:教師普遍接受需要控制生詞率這一理念,但在實際操作中對生詞率只進行大致估計,而不進行量化。為了解決此問題,筆者編制了一個專門用于統計生詞率的工具,內嵌人教版小學、初中、高中三套教材的單元詞表,使用者只需簡單的操作就能快速便捷地計算出閱讀理解題語篇的生詞率,從而根據生詞率情況進行相應調整,如用簡單的詞改寫、括注生詞等。下面對該工具的編制及使用進行說明。
三、生詞率統計工具的開發與應用
(一)詞表的編制
要編制具有生詞率統計功能的軟件工具,首先要解決的是詞表問題。有了詞表,才能用編程手段對比并統計生詞率。現行國家課程標準對義務教育階段及高中階段學生應該掌握的詞匯有明確的規定,教材是以課程標準的規定為依據編寫的[9],詞匯也是根據課標規定系統安排的,并在學段結束時完成相應課標詞匯的呈現和復現。因此,編制英語測試題對詞匯的考查也應結合教材及教學進度進行。也就是說,制作詞表需要統計教材各單元依次呈現的所有課標詞匯。這里說的“所有課標詞匯”,既包括單詞原形,也包括按照教材編寫中相應單元要求學生掌握的單詞的屈折變化形式,如名詞單復數變化,動詞的原形、第三人稱單數、過去式、過去分詞、現在分詞,形容詞和副詞的原形、比較級、最高級等。
基于上述分析,本研究編制了包含33568個英語詞條(lemma)的普通單詞詞表,加上單詞的屈折變化形式共72221個詞型(word type),如詞條take包含原形take、動詞第三人稱單數takes、動詞過去式took、過去分詞taken及現在進行時taking共5個詞型。為了更好地識別專有名詞,本研究還編制了包含17677個人名的人名詞表和包含549個常見地名的地名詞表,然后收集了人教版小學英語(PEP)、初中新目標英語,以及2019年版普通高中英語的全部文本,編制軟件提取出各單元的課標詞匯。
(二)工具的編制和說明
1.工具的編制思路
本研究編制的生詞率統計軟件的工作原理很直觀:首先,使用者輸入文本并指定教材和目標單元信息,即檢測的是哪套教材的哪個單元(如果是期末檢測,選擇最后一個單元即可);其次,運用計算機程序調入對應教材對應單元的課標詞表,并把使用者提供的文本去掉無關符號后切分為一個一個的單詞,然后將每一個詞與詞表做對比;最后,統計出所有不在詞表里的單詞數量,除以文本總字數,即可得到生詞率。
2.工具的操作說明
考慮到國內一般使用者的需求,本研究編制的生詞率統計軟件工具以視窗(Windows)系統為目標平臺。由于本工具解決的首要問題就是易用性,這也是目前國內教師面臨的最大挑戰,因此在用戶交互界面設計方面盡量簡潔。本工具的開發以計算機語言C#實現,程序主界面左側上邊是使用者操作區。使用者只需把編制好的閱讀理解題放入特定文本文件,點擊“打開文件”,選擇該文件,即可把文件里的文本載入右邊的文本框(使用者也可從其他文本編輯界面把要分析的內容直接拷貝并粘貼到該文本框)。然后,使用者選擇測驗針對的教材和目標單元,點擊“開始統計”,該文本的生詞率即可很快顯示在信息輸出區。本工具能自動識別出已學的課標詞匯和人名、地名等專有名詞以及生詞,將其分別列在“已學+排除詞”和“未學詞”兩個列表中。實際應用中,如果出現一些未包含在軟件詞表中的人名、地名,或者已經括注了的生詞,或者教師認為學生根據學習過的構詞法知識能夠理解的派生詞,可以手動把這些詞調整到右側的“已學+排除詞”列表,生詞率也會實時自動重新計算。
3.工具使用過程說明
本工具開發完成后,筆者挑選了現有的一些閱讀理解題,首先人工仔細計算生詞率,然后用本工具進行統計,對比結果表明,該工具效率高,準確性也很可靠。下面以2021年全國新高考英語試卷I的一篇閱讀理解題為例說明使用該工具統計生詞率的過程,并提出一些統計的基本原則(如圖3)。
首先,點擊“打開文件”導入該篇閱讀理解題,在“選擇測試目標”部分選擇“高中”,并勾選“畢業考試”,接著點擊“統計”按鈕。運用統計工具進行統計后,在下面列出文本中需要使用者判斷的同形異義詞。這里列出的同形異義詞是軟件無法根據拼寫自動判斷的詞,比如does可以表示助動詞do的第三人稱單數形式,也可以表示名詞doe的復數形式,因此需要人工手動判斷。使用者選擇判斷后,點擊下邊的按鈕確認,列表中被判定為義務教育和高中課標詞表以外的詞和其他直接被軟件對比判斷為義務教育和高中課標詞表以外的詞一起被列出,使用者可根據具體情況調整。
在尚未處理未學詞列表的時候,我們可以看到統計結果顯示的生詞率是15.85%,但在這些列出的未學詞里,有些是可以根據構詞法規則和上下文推斷其意義的。實際上,課程標準明確要求學生應掌握一定的構詞法知識,包括合成法、派生法、轉化法、縮寫和簡寫等[10]。《義務教育英語課程標準(2011年版)》設定的語言技能目標也要求學生能根據上下文和構詞法推斷與理解生詞的含義。因此,對于課標詞的常見合成詞、派生詞等,應視為對學生構詞法知識的考查,所以要從未學詞表中排除。具體方法是在界面上的未學詞列表中選中該詞,點擊下邊的按鈕,下方統計區會實時顯示重新計算的生詞率。在上述例子中,首先排除閱讀語篇注釋過的詞emotional、perspective等,然后排除課標詞的簡單派生詞,如accurately、cheater、re-evaluate等,以及基于常見的合成法構詞規則構成的單詞,如makeup、skill-based等。排除后可以看到調校后的生詞率是4.58%。這個比例基本符合外語教育領域研究者對合理生詞率的研究結論[11][12]。如果需要輸出統計信息,可點擊下方的“輸出結果至剪貼板”,在其他文本編輯器中按Ctrl+V即可把總單詞數、生詞率、排除的和未排除的詞、目標單元(或學段)的課標詞等信息輸出至編輯區。
另外,軟件里還內置了課標詞的4280個常見派生詞,如果勾選了未學詞表下邊的“自動設定已學課標詞的派生詞為已知詞”復選框,程序可以自動排除截至目標單元/學段已學課標詞的派生詞。比如上述應用案例中,accurately、cheater等7個未學詞匯因被判斷為課標詞accurate、cheat等的派生詞,在勾選了復選框后,被自動認定為已學詞匯。當然,使用者要一一核對軟件自動排除的單詞,以確保無誤。
本研究編制的生詞率統計工具嘗試解決目前教師缺乏高效生詞率統計工具的問題。它可以使教師方便地把握閱讀理解文本在詞匯方面的呈現情況。首先,教師可以直觀地看出閱讀理解題中呈現出哪些單詞,方便實時調整。其次,教師還能直觀地看到試題中有多少生詞。如果生詞比超過合理范圍,教師就要考慮對其中個別生詞進行適當處理,如改寫、括注等,從而降低生詞率,避免生詞量過大導致題目區分度下降、測驗無法很好體現教學效果以及打消學生學習積極性等不良后果。
注:本文系人民教育出版社課程教材研究所“計算機輔助英語教材詞表制作軟件的研制及應用”(課題批準號:KC2020-022)的階段性研究成果。
參考文獻
[1] Hughes A. Testing for Language Teachers[M]. UK: Cambridge University Press,1989:1-6.
[2][6]王金巴.生詞密度對大學英語閱讀理解的影響研究[J].外語界,2015(3):33-40.
[3] 楊穎,范向陽.農村初中英語閱讀理解的實驗研究——不同生詞密度與主題熟悉性對閱讀的影響[J].貴州師范大學學報:自然科學版,2007(4):29-34.
[4][5][11]?? Hu M, Nation P. Unknown Vocabulary Densityand Reading Comprehension [J]. Reading in a Foreign Language,2000(1):403-430.
[7] Anthony L. Ant Word Profiler: version 1.5.1[CP/OL].(2021-03-04)[2021-09-12].https://www.laurenceanthony.net/software/antwordprofiler/.
[8] Heatley A, Nation P, Coxhead A. RANGE and FREQUENCY Programs: version 1.32[CP/OL].(2005-02-07)[2021-09-12].https://www.wgtn.ac.nz/lals/resources/paul-nations-resources/vocabulary-analysis-programs.
[9][10]中華人民共和國教育部.普通高中英語課程標準:2017年版2020年修訂[S].北京:人民教育出版社,2020.
[12]Laufer B. What Percentage of Text-lexis is Essentialfor Comprehension[M].Special Language: From Humans Thinking to Thinking Machines,1989:316-323.
(作者系人民教育出版社課程教材研究所英語課程教材研究開發中心主任編輯)
責任編輯:孫建輝
