改進的KNN分類異常點檢測方法
2022-05-01 13:41:26朱林杰趙廣鵬康亮河
甘肅科技縱橫 2022年1期
朱林杰 趙廣鵬 康亮河
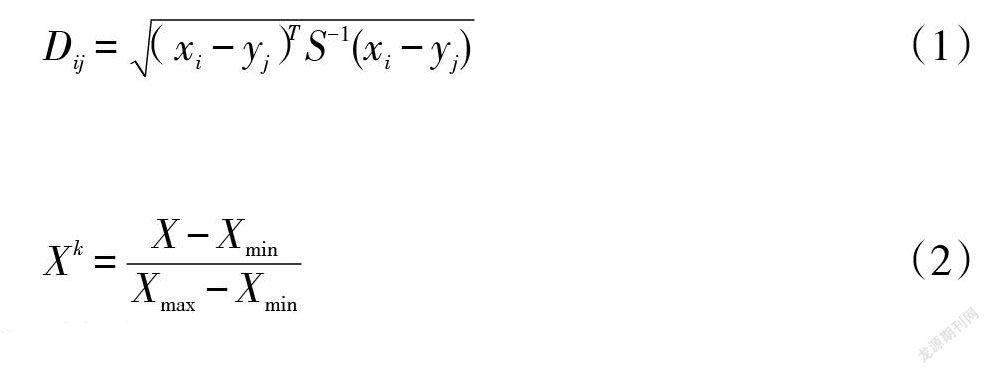


關(guān)鍵詞:特征選擇;孤立森林算法;NSL-KDD
中圖分類號:TP391
0引言
隨著信息技術(shù)的發(fā)展,在大數(shù)據(jù)時代,準確收集各方面的數(shù)據(jù)格外重要,然而數(shù)據(jù)容易被異常點污染,因此數(shù)據(jù)質(zhì)量的監(jiān)測被越來越多的學(xué)者重視。在異常檢測系統(tǒng)研究領(lǐng)域中,異常點檢測是其中一項非常重要的環(huán)節(jié)。在物聯(lián)網(wǎng)領(lǐng)域中,前人提出了許多方法處理研究數(shù)據(jù)異常值來保證檢測結(jié)果的準確性,例如SVM、KDE、聚類、貝葉斯、決策樹等方法,但是很少有方法是通過研究數(shù)據(jù)的相關(guān)性去進行異常點檢測研究。
通常我們收集的數(shù)據(jù)中,會包含因人為的或是因機器錯誤而導(dǎo)致的許多雜亂的、有噪聲的、異常的稀疏數(shù)據(jù),也會包含遠遠偏離大部分值的數(shù)據(jù)異常點,異常點檢測與估計通常用無類別標簽來找到某個區(qū)域的異常數(shù)據(jù)。由于網(wǎng)絡(luò)上的數(shù)據(jù)類型龐大且其處于不定時的變化狀態(tài)中,我們無法快速定位并準確查找到異常點,同時也增加了相應(yīng)研究的工作量。另一方面,由于存儲方面的限制,硬件代價比較高,導(dǎo)致目前獲得的有用算法比較少。因此,找到數(shù)據(jù)中的異常點檢測就顯得非常重要。
近年來,雖然利用距離方法度量兩個數(shù)組之間的距離有一定的優(yōu)勢,但目前有的度量方法仍存在一定的缺陷。在考慮數(shù)據(jù)之間的稀疏性與相互關(guān)聯(lián)的情況下,結(jié)合馬氏距離,發(fā)現(xiàn)兩個變量的相互關(guān)聯(lián)是顯而易見的,都會存在一定的相關(guān)性。計算兩個變量的協(xié)方差矩陣時,通過先處理數(shù)據(jù)幀,將數(shù)據(jù)平滑成一維數(shù)組,再計算兩個一維數(shù)組的馬氏距離。與多數(shù)據(jù)點相似,少數(shù)數(shù)據(jù)點有不同的特征,遠離多數(shù)點,先計算特征向量,再進行異常點打分,從而找出異常點。文章分析了該領(lǐng)域的研究方法,通過學(xué)習(xí)理解目前的研究,比較了幾種不同的異常點檢測方法。
1相關(guān)工作
雖然關(guān)于異常點檢測的研究已經(jīng)持續(xù)了許多年,但仍有很多需要改進的地方。Nonso Nnamoko等人[1]通過研究異常點和類之間的平衡提高了關(guān)于治療糖尿病預(yù)防方面的檢測率。PetraJ Jones等人[2]提出了新的異常點檢測方法,該方法通過減少異常點來改進kmeans,從多個方面來評估異常點,并獲得了不錯的結(jié)果。Henriqueo等人[3]分析了許多文獻,討論了許多現(xiàn)有的方法,比較了候選異常點求解方法。Zahra Gha?foori等人[4]提出無監(jiān)督的維數(shù)約簡技術(shù)和隨機的近鄰嵌入檢查,改進的維數(shù)約簡技術(shù)提高了異常點檢測的精度。Yacine Chakhchoukh等人[5]提出了一個有力的卡爾曼過濾增強異常點檢測和黑客攻擊的診斷方法。CarmonaJ等人[6]提出在高維數(shù)據(jù)集中,使用距離度量來檢測異常點,通過和四種方法比較,他的方法在低維和高維數(shù)據(jù)中適用。Mansoor Ahmed Bhatti等人[7]研究了采用機器學(xué)習(xí)方法在物聯(lián)網(wǎng)中檢測異常點的應(yīng)用,在精度、準確性、召回率、f-scores四個方面,達到了97.8%精度改進結(jié)果。PeterFilzmoser等人[8]分析了多變量異常點檢測方法,他們從全局、局部、組合等方面討論了不同數(shù)據(jù)格式的整合。John Wiley等人[9]用概率的方法有效的檢測了異常點。FarekLazhar[10]在文章中使用模糊聚類和半監(jiān)督的方法檢測異常點,實驗結(jié)果表明,使用該方法進行異常點檢測改進了分類器的性能。Javier Martinez Torres等人[11]通過對空氣污染數(shù)據(jù)質(zhì)量的異常值分析,用四個步驟概括了異常點檢測的重要性,并采取新措施改善了空氣質(zhì)量。RüdigerLehmann[12]使用均值漂移與方差波動法進行異常值檢測的比較研究。Yu Kangqing[13]設(shè)計了一個流算法用于在數(shù)據(jù)挖掘中檢測異常點增量。Ijaz Muhammad Fazal[14]研究了異常點檢測和過采樣方法在疾病處理中的影響。
2提出的方法
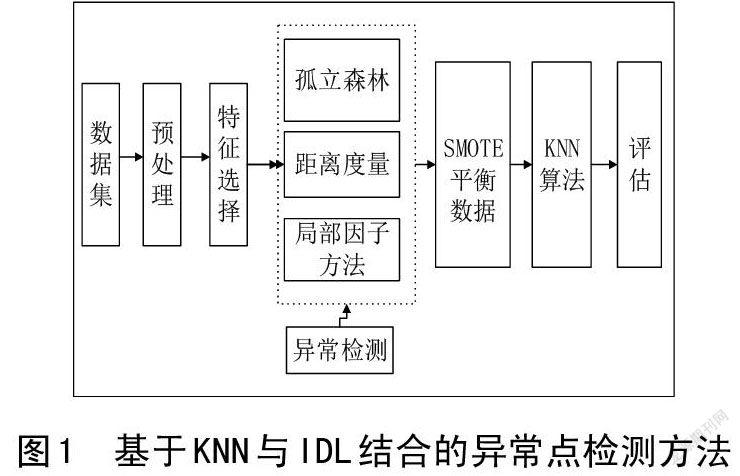
在計算異常點檢測時,會缺少相關(guān)的知識,異常點處理會受到影響,為了考慮到單一方法的局限性,采用isolationforest、距離度量和局部因子方法異常點檢測的方法,該方法首先采用馬氏距離計算兩個變量之間的距離,得到兩個n行n列協(xié)方差矩陣,然后擴展成多個變量,將變量轉(zhuǎn)換成不相關(guān)的空間,最后匯成距離向量矩陣;接下來根據(jù)距離與密度的關(guān)系找出離群點,觀察是否是密度小的數(shù)據(jù)區(qū)域,并且找出遠離線性關(guān)系的每一個樣本點;然后根據(jù)每個值的情況確定異常點,如果多數(shù)點相似,少數(shù)數(shù)據(jù)點既有不相似的特征,遠離多數(shù)點的這些數(shù)據(jù),從而得出異常點。
2.1特征選擇
卡方檢驗是一種使用頻率比較高的特征選擇方法。卡方檢驗可以測量隨機變量之間的相關(guān)性,消除與類別無關(guān)的特征。它能夠推斷出類別之間的特征依賴性,并計算特征信息值和卡方統(tǒng)計值[15]。
建立的模型如圖1所示。
2.2發(fā)現(xiàn)異常點
采用isolation forest、距離度量和局部因子方法,結(jié)合每一個算法的優(yōu)點查找異常值。然后使用馬氏距離度量[16],具體公式如下[17-18]。
其中,S表示協(xié)方差。根據(jù)得到的值,判斷其是否為異常值,通過這些方法獲取數(shù)據(jù)點,進行綜合判斷,得到最近鄰[19]。
3實驗結(jié)果與分析
基于距離的方法是一種簡單有效的快速計算距離的方法,在機器學(xué)習(xí)領(lǐng)域中,盡管這方面研究已經(jīng)持續(xù)了許多年,學(xué)習(xí)異常點檢測仍具有一定的困難,異常點通常出現(xiàn)在數(shù)據(jù)采樣處理之后,這就使得使用算法進行錯誤分類受到比較大的影響。因此,為了更好的檢測異常,結(jié)合了算法的優(yōu)點用于實驗,通過文章的實驗結(jié)果證明,相對于傳統(tǒng)方法來說,文章提出的算法在平衡召回率和精度方面有所改進,結(jié)合的檢測方法在分類效果上有一定的優(yōu)勢。
改進的異常點檢測方法在測試階段,采用公開數(shù)據(jù)進行測試時,測試誤報率明顯降低,相對于單一的檢測方法,混合的檢測方法有所改進。為了檢測和改進異常點檢測效率,使用結(jié)合的方法查找異常點,然后找到異常點后,再使用SMOTE算法使得數(shù)據(jù)達到平衡。
3.1數(shù)據(jù)集
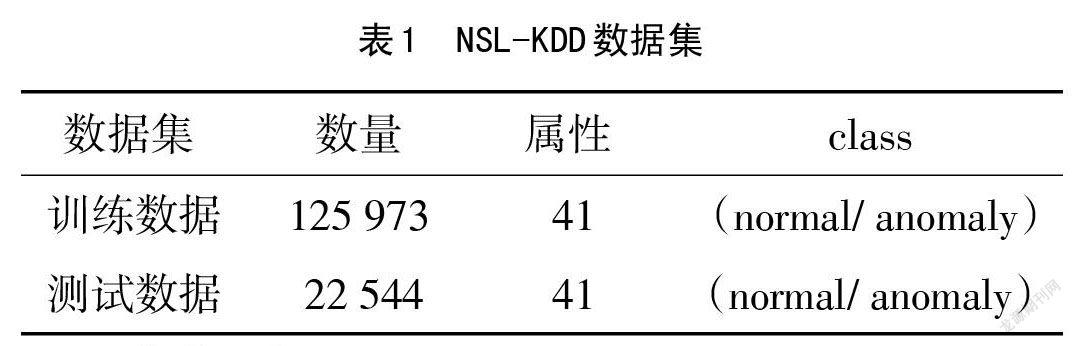
KDDtrain包含42個屬性,125973條數(shù)據(jù),分為正常和異常數(shù)據(jù),KDDtest包含42個屬性,22544條數(shù)據(jù),分為正常和異常數(shù)據(jù),見表1所列。
3.2實驗平臺
python3.7,intel(R)core(TM),i5-9400F,2.90GHz,8G內(nèi)存,windows10操作系統(tǒng)。
3.3參數(shù)設(shè)置
樹規(guī)模T=100。K=3。為了驗證混合異常點檢測算法的性能,分類性能被檢測使用以下方式。
TP(真陽性):預(yù)測為正樣本,實際為正樣本
FP(假陽性):預(yù)測為正樣本,實際為負樣本
TN(真陰性):預(yù)測為負樣本,實際為負樣本
FN(假陰性):預(yù)測為負樣本,實際為正樣本
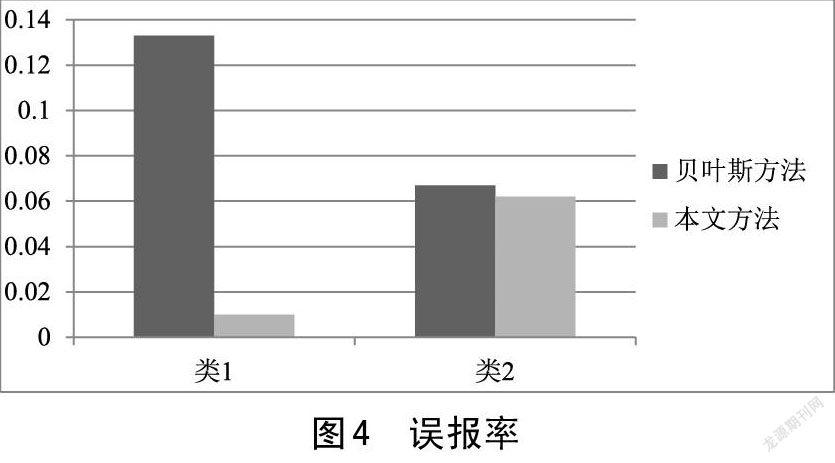
類1表示正常的類別,類2表示異常的類別。
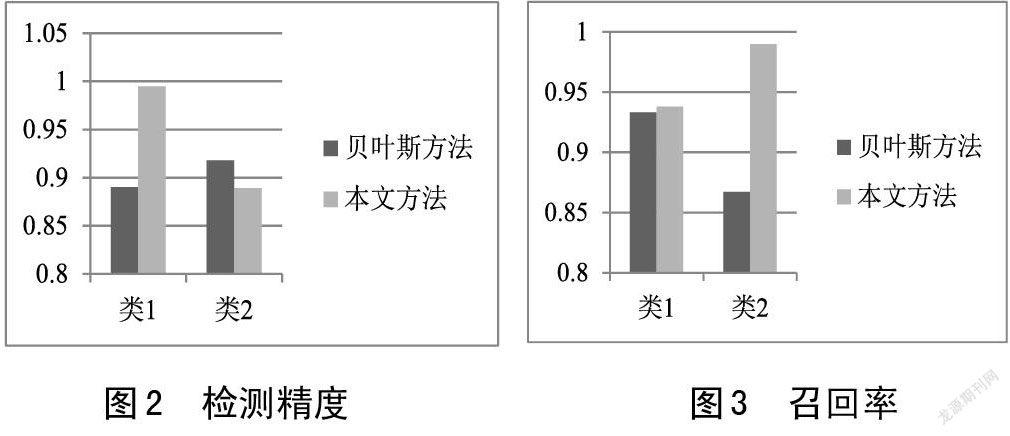
從圖2中實驗結(jié)果可以看出,通過與貝葉斯方法比較,文章提出的方法對正常類別的檢測精度比較高,錯誤類別的檢測精度略低于貝葉斯方法,分析其原因,在于實驗采樣的樣本規(guī)模仍較少導(dǎo)致。但根據(jù)分析情況,能夠看出找出異常點,總體上檢測能力遠遠提高,從召回率方面來看,如圖3所示,文章提出的方法在召回率結(jié)果上明顯優(yōu)于貝葉斯估計方法。正常檢測率達到93.8%,異常檢測達到了99%,文章所提出的方法改善效果顯著,可以較好的表現(xiàn)出異常點檢測的效果。另外從誤報率結(jié)果來看,如圖4所示,實驗結(jié)果中發(fā)現(xiàn)出現(xiàn)的誤報率比較小。達到了6.2%的誤報檢測性功能,通過本文提出的方法檢測到異常點并處理后,通過k值選擇,同貝葉斯方法比較后可以明顯的看出采用本文方法進行異常點檢測有所改進、檢測精度略有提高、誤報率得以降低。從整體結(jié)構(gòu)看,雖然檢測到的樣本稍微有些變化,但總體趨于平穩(wěn),整個檢測系統(tǒng)的效果優(yōu)于經(jīng)典的方法。
4結(jié)論
異常點檢測是數(shù)據(jù)挖掘領(lǐng)域一個重要的過程。文章提出了改進KNN與異常點檢測算法相結(jié)合來處理數(shù)據(jù)的方法,該方法有助于查找并識別異常點,保證攻擊的數(shù)據(jù)在數(shù)據(jù)挖掘領(lǐng)域中得到正確檢測,通過實驗證明,本文提出的方法能夠有效的處理異常點。在現(xiàn)實生活中,有許多系統(tǒng)數(shù)據(jù)需要處理異常點,因此異常點檢測是關(guān)鍵部分。異常點因為數(shù)據(jù)的稀疏等因素數(shù)量一般超出給定數(shù)據(jù)集中多數(shù)相似點的個數(shù),識別它往往會有一定的困難,有時,異常值對于我們分析數(shù)據(jù)有一定的影響,如果系統(tǒng)沒有識別出異常值,會導(dǎo)致預(yù)測結(jié)果不準確;如果異常值太多,又會影響系統(tǒng)的準確性,通過采用消除變量方式把特征向量降低,消除異常值的影響,通過系統(tǒng)檢測并標記異常值,得到異常值的大小后計算,使預(yù)測性能得到提高。總之,從實驗結(jié)果進行分析文章方法在數(shù)據(jù)量比較大的情況下,精度與召回率大幅度提升,誤報率有所下降,這樣充分說明,本文方法對于入侵攻擊由較強的檢測能力。相對與貝葉斯方法,較好的提升了分類精度。另外,在將來在大數(shù)據(jù)時代,數(shù)據(jù)量越大,數(shù)據(jù)的維數(shù)也越高,同時會導(dǎo)致出現(xiàn)更復(fù)雜的情況。因此,消除維數(shù)方面的影響,會減少系統(tǒng)的運作成本。
