基于多任務學習的測井儲層參數預測方法
2022-05-05 08:18:10邵蓉波肖立志廖廣志史燕青周軍李國軍侯學理
地球物理學報 2022年5期
邵蓉波, 肖立志*, 廖廣志, 史燕青, 周軍,, 李國軍, 侯學理
1 中國石油大學(北京)人工智能學院, 北京 102249 2 中國石油集團測井有限公司, 西安 710077
0 引言
隨著近年來數據科學和人工智能的發展,利用機器學習解決地球物理測井、地震勘探等方面的問題受到廣泛重視.相較于傳統方法,數據驅動的機器學習方法跳出領域知識,從全新的角度觀察數據,探索更大的函數空間,在物理關系未知的情況下對數據和目標進行映射,提供了在高維空間中表征變量之間關系的方法,減少了研究人員對地質地球物理及巖石物理學知識的需求(Bergen et al., 2019).地球物理和人工智能發展的另一個思路是將機理模型融入機器學習之中,既可以提升地球物理機器學習模型的可解釋性,又能夠更準確地對巖石物理關系進行映射(Reichstein et al., 2019; 肖立志, 2022).已有學者對神經網絡在地球物理中的應用展開研究,席道瑛和張濤(1994)使用反向傳播神經網絡自動識別巖性.近些年,Kohli等(2014)構建了數據驅動的神經網絡模型,根據不同偏移距井的測井資料計算滲透率.張東曉等(2018)將LSTM與串級系統相結合,提出串級長短期記憶神經網絡(CLSTM),實驗表明CLSTM更適用于生成序列式的測井數據.Sultan(2019)采用自適應差分進化(SaDE)方法優化人工神經網絡(ANN)的參數,有效地預測了總有機碳(TOC),與傳統的估算方法相比神經網絡方法更加高效精準.廖廣志等(2020)的研究表明卷積神經網絡可以用于預測儲層微觀孔隙結構,且優于單層神經網絡模型.Al-AbdulJabbar等(2020)利用人工神經網絡(ANN)根據鉆井參數預測儲層孔隙度,并取得較好的預測效果.Gao等(2020)利用井旁道數據與測井含氣性解釋結果建立卷積神經網絡模型,同時使用遷移學習方法緩解少標簽導致的過擬合問題.Liu等(2020)提出了一種基于局部深度多核學習支持向量機(LDMKL-SVM)的巖相分類方法,同時考慮低維全局特征和高維局部特征,自動學習核函數和SVM的參數,結合地震彈性信息預測巖性.Gao等(2021) 提出了一種基于多層感知器(MLP)的低電阻率低對比度(LRLC)儲層識別方法,MLP方法解決了LRLC儲層與水層的電阻率相似而無法有效識別的問題.金永吉等(2021)將遺傳神經網絡用于測井曲線重構,實驗表明相較于傳統方法生成的曲線質量更高.Zhang等(2021)提出了一種“常規測井資料-礦物成分預測-紋層組合類型識別”有監督組合機器學習方法,用于在地質數據有限的情況下預測具有高度垂直異質性的層狀頁巖的空間分布,構建測井數據與主要礦物成分的映射關系.白洋等(2021)使用分類委員會機器進行致密砂巖流體識別,使流體識別模型預測精度和泛化能力大幅度提高.Dong等(2022)提出了一種基于雙深度Q網絡(DDQN)的深度強化學習(DRL)方法,在三個常規試井模型中進行自動曲線匹配,結果表明DDQN比監督機器學習算法魯棒性更好.畢麗飛等(2021)提出了基于標簽傳播的半監督學習方法并應用于巖性預測,結果表明該模型可以提升小樣本類別的準確率.目前多名學者對人工智能和神經網絡在地球物理中的應用持樂觀態度(Kohli and Arora, 2014; 王昊等, 2020).
在自然語言處理和機器視覺等領域常使用多任務學習的方法提升預測效果.多任務學習可以將多個相關的任務放在一起學習,學習過程中通過一個在底層的共享表示(Shared representation)來互相分享、互相補充學習到的領域相關信息,提升泛化效果(Evgeniou, 2004).共享一般是基于參數(Parameter based)的共享:比如基于神經網絡的多任務學習和高斯處理過程;或者是基于約束(Regularization based)的共享:比如均值和聯合特征(Joint feature)學習(Jebara, 2011).多任務學習也被視為一種歸約遷移(Inductive transfer)(Dietterich et al., 1997).歸約遷移(Inductive transfer)通過引入歸約偏置(Inductive bias)來改進模型,使得模型更傾向于某些假設.在多任務學習場景中,歸約偏置由輔助任務來提供,使模型更傾向于那些可以同時解釋多個任務的解,從而提升模型的泛化性能(Dietterich et al., 1997; Argyriou et al., 2008).
機器視覺領域,Sun等(2014)提出了一種聯合訓練人臉確認損失和人臉分類損失的多任務人臉識別網絡DeepID2,網絡中共有兩個損失函數:人臉分類損失函數和驗證損失函數.Zhang等(2014)提出的TCDCN模型以檢測臉部特征點為主要任務,輔以4個分任務,相較于單任務模型,TCDCN模型的檢測更準確.目標檢測領域,Girshick(2015)提出的Fast R-CNN是一個快速物體檢測的多任務卷積網絡.自然語言處理領域,Collobert等(2008)將語義角色標注、語言模型、詞性標簽、語塊、命名實體標簽等任務統一到一個框架中,利用輔助任務中自動學習得到的特征提升語義角色標注的性能.
在地球物理應用中,桑文鏡等(2020)提出多任務殘差網絡,以疊前地震數據預測阻抗和含氣飽和度.孫永壯和黃鋆(2021)將多任務學習用于巖性預測和橫波速度預測,以橫波速度預測為主任務,使用巖性預測任務輔助橫波預測任務,從而提升橫波速度預測效果.
現有地球物理測井機器學習的研究主要是基于單任務學習,單任務學習的局限性在于面對復雜問題時需要將其分解為多個單一獨立的子問題,逐一解決再歸納合并,從而得到原始復雜問題的解(Caruana, 1998).然而地球物理測井中的許多復雜問題內部相互關聯,無法分解為單一獨立的子問題.此外,如果將儲層參數預測分解為單任務處理,會忽略儲層參數之間的關聯信息.因此相較于單任務機器學習,多任務學習在儲層參數預測方面更具優勢.本文將多任務學習方法應用于儲層參數預測任務,在學習共享多個儲層參數之間的信息,使模型具有更好的泛化效果,提升儲層參數預測精度.
1 方法
1.1 理論基礎
本文使用的多任務模型基于深度神經網絡(DNN),DNN可以看作是多層多維度的線性回歸和各種線性或非線性激活函數的組合,通過梯度下降等方式根據損失函數的數值調節模型內部的權重(Haykin, 1998; Goodfellow et al., 2016; Michael, 2015).在使用DNN模型進行回歸預測時,信息由輸入層到輸出層逐層運算,單個神經元的計算可以表示為:
(1)
其中,z為神經網絡中某一個神經元,xi為上一層第i個神經元,wi為對應的權重,b為偏置權重,m為上一層中神經元個數,W=[w1,w2,…,wm],X=[x1,x2,…,xm]T.W和b統稱為模型參數,參數初始化時一般隨機賦值.
DNN模型的隱藏層后會連接激活函數δ(z),激活函數的非線性轉換使神經網絡的擬合能力進一步增強,使模型的預測結果不斷逼近真實值(Goodfellow et al., 2016).本文使用的激活函數除線性函數(公式(2)),還有非線性的ReLU函數(公式(3))和SoftPlus函數(公式(4)):
δlinear(z)=z,
(2)
δReLU(z)=max(z,0),
(3)
δsoftplus(z)=lg(1+ez).
(4)
ReLU的非飽和性潰瘍有效地解決梯度消失的問題,其單側抑制提供了網絡的稀疏表達能力.SoftPlus可以看作是ReLu的平滑.根據神經科學家的相關研究,softplus和ReLu與腦神經元激活頻率函數有神似的地方.也就是說,相比于早期的激活函數(如softmax,tanh等),softplus和ReLu更加接近腦神經元的激活模型(Ciuparu et al., 2020).
深度神經網絡多任務隱層參數共享分為硬共享與軟共享(Ruder, 2017; Liu et al., 2016).參數的硬共享機制可以應用到所有任務的所有隱層上,保留任務相關的輸出層,從而降低過擬合的風險(Caruana, 1993; Baxter, 1997).參數的軟共享機制中每個任務都有獨立的模型參數,對模型參數的距離進行正則化保障參數的相似(Duong et al., 2015).
研究表明,多任務學習從4個方面提升模型效果(Ruder, 2017):(1)噪聲:對主任務而言,相關任務中與主任務無關的信息視作噪聲,訓練過程中噪聲可以提高模型泛化效果;(2)逃離局部最優解:多任務學習中的不同任務的局部最優解常處于不同位置,在梯度傳播時相互影響從而可以有效避免模型陷入局部最優解;(3)權值更新:多任務學習中權值更新受多個任務的影響,相較于單任務學習提升了底層共享層的學習速率;(4)泛化:多任務學習有可能影響單個任務的擬合能力,但降低模型過擬合幾率,提升模型泛化能力.
總體而言,多任務學習中共享部分越多,噪聲與泛化的影響越明顯;參與學習的任務數量越多,逃離局部最優解與權值更新的效果越明顯.
本文提出的基于多任務學習的測井儲層參數預測方法將對幾種描述油氣藏的重要參數進行預測.傳統測井解釋方法中用自然伽馬(GR)曲線或自然電位(SP)曲線計算地層泥質含量;用泥質校正后的聲波時差(AC)、補償中子(CNL)和密度(DEN)計算地層孔隙度(POR);用電阻率測井值(RT)、孔隙度(POR)及泥質含量來計算含水飽和度(SW);用井徑(CAL)進行井眼校正;然后循環迭代,逐次逼近儲層參數真實值(雍世和等, 2002).因此選取聲波時差(AC)、井徑(CAL)、中子(CNL)、密度(DEN)、自然伽馬(GR)、電阻率(RT)以及自然電位(SP)作為輸入數據,以孔隙度(POR)、滲透率(PERM)與含水飽和度(SW)的預測作為任務,使用多任務學習模型同時對三種儲層參數進行預測,不必反復迭代校正儲層參數,相較于傳統測井解釋方法,多任務學習在簡化儲層參數預測流程,并提升神經網絡模型的預測效果與泛化能力.
下面將分析多任務模型損失函數的選取以及幾種不同類型的多任務模型,并給出其應用于測井儲層參數預測的具體方法.
1.2 多任務損失函數
多任務模型中損失函數的選擇需要綜合考慮每個任務的特點,并對每種任務分配合適的權重.若不同任務的量綱相同且數據分布區間大致重合或使用歸一化等數據預處理方式,可使用常見的均方誤差(Mean Square Error, MSE)、平均絕對誤差(Mean Absolute Error, MAE)等損失函數,然后根據模型訓練情況調整每種任務的權重.若任務間的差異較大或不方便進行數據預處理,適合使用受數據分布影響較小的損失函數,例如平均絕對值百分比誤差(Mean Absolute Percentage Error, MAPE).
地球物理測井中,儲層參數的數值分布區間不一致,根據本研究所采用的數據集統計得到:孔隙度大多分布于9.71±2.70%;滲透率大多分布于0.23±0.26(0.987×10-15m2);含水飽和度大多分布于66.61±16.75%.若使用MAE作為損失函數,模型訓練時損失函數將由含水飽和度MAE主導,導致參數優化時會忽略滲透率和孔隙度對模型的影響,使滲透率和孔隙度擬合效果較差;若對其設置權重,對每個任務損失函數設置合適的權重有一定困難.因此選擇MAPE作為損失函數,計算預測值與實際值誤差的百分比,將不同儲層參數的誤差以統一的尺度表示,既可以保證每個儲層參數在模型訓練過程中都能得到較為充分的訓練,又能避免損失函數權重設置不合理.
1.3 同架構多任務儲層參數預測模型
首先是泛化性能最強的同架構多任務儲層參數預測模型,其特點為除輸出層每個儲層參數獨立計算,其余各層均共享神經元,如圖1所示,記作multi_same_α.在multi_same_α中,多任務相互之間有較強的影響,當儲層參數之間相關性較高時,權值更新作用顯著,可以取得較好的預測效果;當儲層參數之間差異較大時,噪聲會導致預測效果不理想;由于每個任務沒有私有隱藏層,模型對單個任務的擬合能力可能較差.
在神經網絡模型中靠近輸入層的網絡提取的信息較為廣泛,靠近輸出層的網絡提取的信息與輸出值的關聯性更大.因此將multi_same_α進一步改造,得到另一種泛化性能稍弱,但對單個任務擬合能力更強的同架構多任務儲層參數預測模型,其特點在于靠近輸入層的隱藏層為共享層,靠近輸出層的隱藏層為結構相同的私有層,如圖2所示,記作multi_same_β.三個儲層參數共同影響共享層的訓練,多任務模型中的權值更新方式輔助提升廣泛信息提取的效果;每個儲層參數的私有層僅受當前儲層參數的影響,僅從共享網絡的輸出中提取與當前儲層參數有關的信息,減少其他儲層參數對當前儲層參數預測效果的影響.該模型的泛化性能和擬合能力取決于私有層結構,一般而言私有層越少泛化性能越好,私有層越多擬合能力越強.
1.4 基于異架構多任務儲層參數預測模型
為獲得更好的儲層參數擬合效果,進一步提出異架構多任務儲層參數預測模型,該模型的特點為靠近輸入層的隱藏層為共享層,每個儲層參數的私有層結構各不相同,如圖3所示,記作multi_diff.該模型保留了multi_same_β模型使用權值更新方式輔助提升廣泛信息提取效果的優點,并且靈活性更好,每個儲層參數可以根據自身特點定制不同的私有層從而更好地從共享網絡輸出的信息中提取信息.例如聲波時差、補償中子和密度與孔隙度呈近似線性的關系,輸入輸出之間的映射較為簡單,因此孔隙度私有層結構較為簡單;含水飽和度受地層電阻率、泥質含量、孔隙度等因素的影響,輸入輸出之間呈非線性關系,因此含水飽和度私有層結構相對復雜;滲透率與測井曲線之間的映射較難確定,因此滲透率私有層的結構最復雜.multi_diff模型的泛化能力取決于共享層結構,共享層層數越多泛化性能越好,反之亦然.
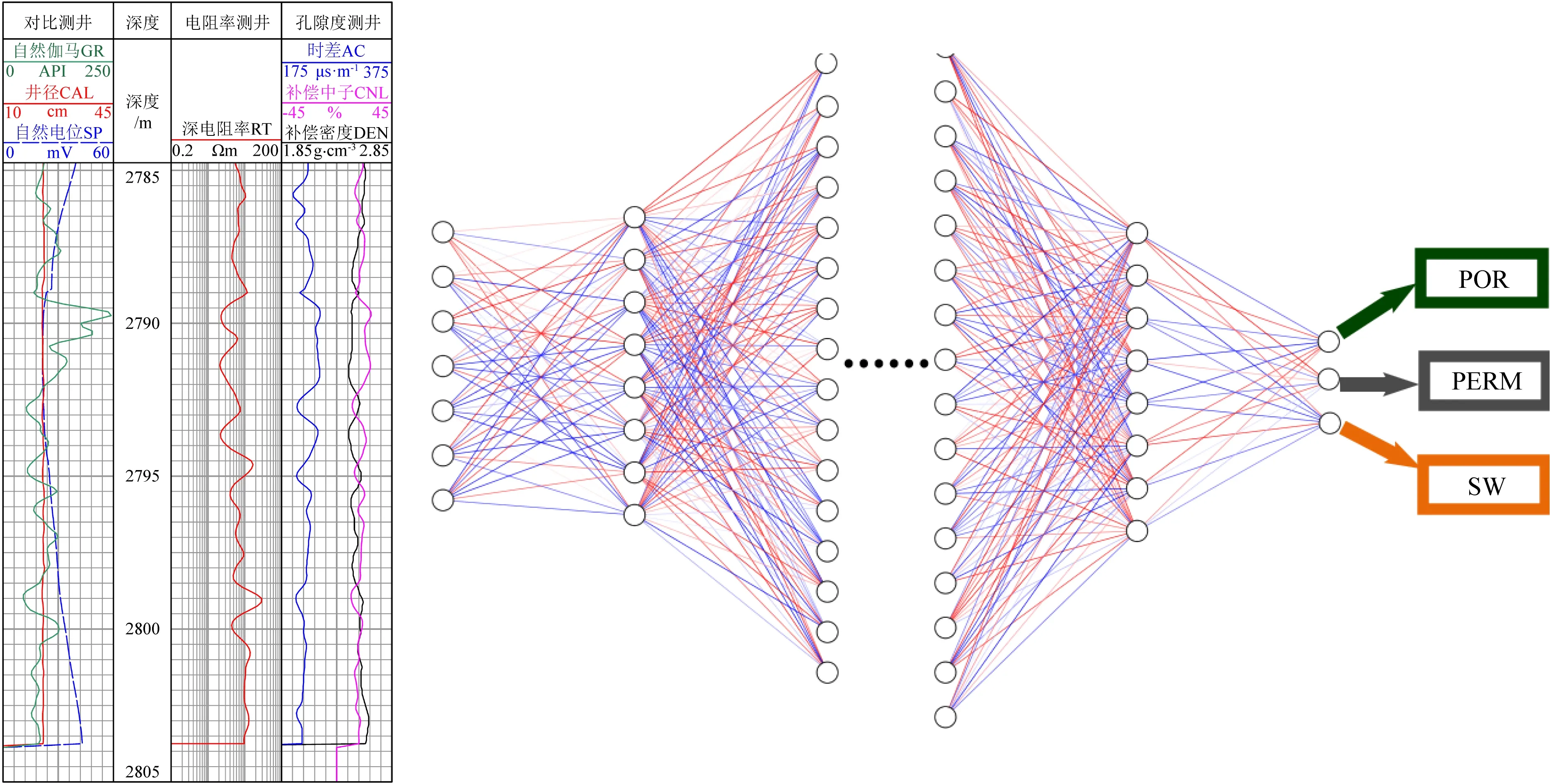
圖1 同架構多任務儲層參數預測模型α(multi_same_α)Fig.1 Multitask reservoir parameters prediction model α with the same structure(multi_same_α)

圖2 同架構多任務儲層參數預測模型β(multi_same_β)Fig.2 Multitask reservoir parameters prediction model β with the same structure(multi_same_β)
2 實例分析
2.1 數據描述與數據處理方式
實驗數據來自于某油田的64口井的常規測井數據,該區塊為致密砂巖儲層,低孔、低滲、低對比度.井眼環境校正和井間標準化等處理過程已由數據提供方完成,進行數據清洗和異常值校正后數據集共包含5571條數據,具體特征分布如表1所示.孔隙度、滲透率與含水飽和度為油田的常規測井處理結果,其交會分析圖如圖4所示,孔隙度與滲透率呈較強的正相關性,含水飽和度與孔隙度、滲透率之間均存在一定的負相關性.訓練集和測試集按8∶2的比例隨機劃分,訓練集中含有4456條數據,測試集中含有1115條數據.
2.2 實驗設計
實驗中使用的模型及編號如表2所示.三種多任務模型的結構與具體參數設置參見附錄表A1—A3,為驗證多任務模型儲層預測提升效果,構建單任務儲層參數預測模型進行對照實驗.單任務模型的輸入數據與多任務模型相同,僅輸出一個儲層參數的預測結果.多任務模型中的參數涉及多個任務的計算,而在單任務模型所有參數只涉及一個儲層參數的計算,多任務模型訓練速度相對緩慢.考慮多任務模型訓練速度下降影響,實驗中的單任務模型分別訓練3000輪和10000輪,多任務模型統一訓練10000輪.同架構單任務模型命名方式為“儲層參數_same_訓練輪數”,具體模型結構與參數設置參見附錄表A4.異架構單任務模型具體模型結構與參數設置參見附錄表A5.本次實驗的模型參數為隨機初始化,為保障實驗結論的可靠性,所有模型進行5次訓練.模型訓練使用Adam優化器,該優化方法是基于SGD改進得到的,可以代替經典的隨機梯度下降法來更有效地更新網絡權重,近些年已成為應用最廣泛的神經網絡優化算法之一.Adam優化器的優點有:計算效率高;內存需求少;梯度的對角線重縮放不變;適合大數據或大模型的訓練;適用于非固定目標;適用于非常嘈雜或稀疏梯度的問題;超參數調節方便(Kingma and Ba, 2014).
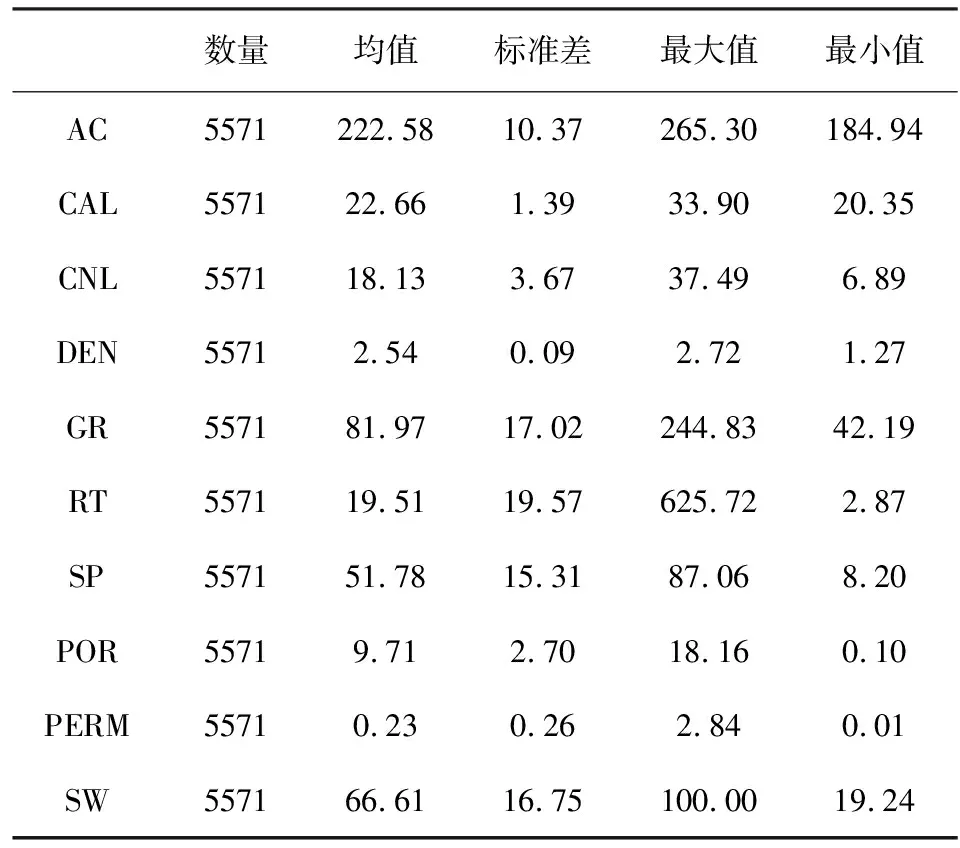
表1 實驗數據統計分析Table 1 Statistical analysis of experimental data
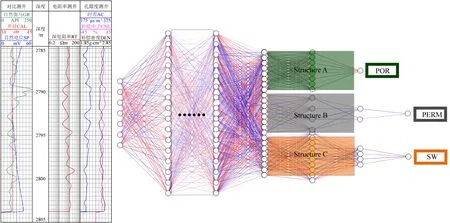
圖3 異架構多任務儲層參數預測模型(multi_diff)Fig.3 Multitask reservoir parameter prediction model with different structure(multi_diff)
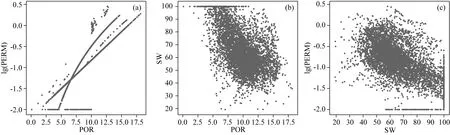
圖4 孔滲飽交會分析圖 (a) 孔隙度-滲透率交匯圖; (b) 孔隙度-含水飽和度交匯圖; (c) 滲透率-含水飽和度交匯圖.Fig.4 Cross analysis Figure of porosity, permeability and water saturation (a)Porosity-permeability cross plot; (b) Porosity-water-saturation cross plot; (c) Permeability-water-saturation cross plot.
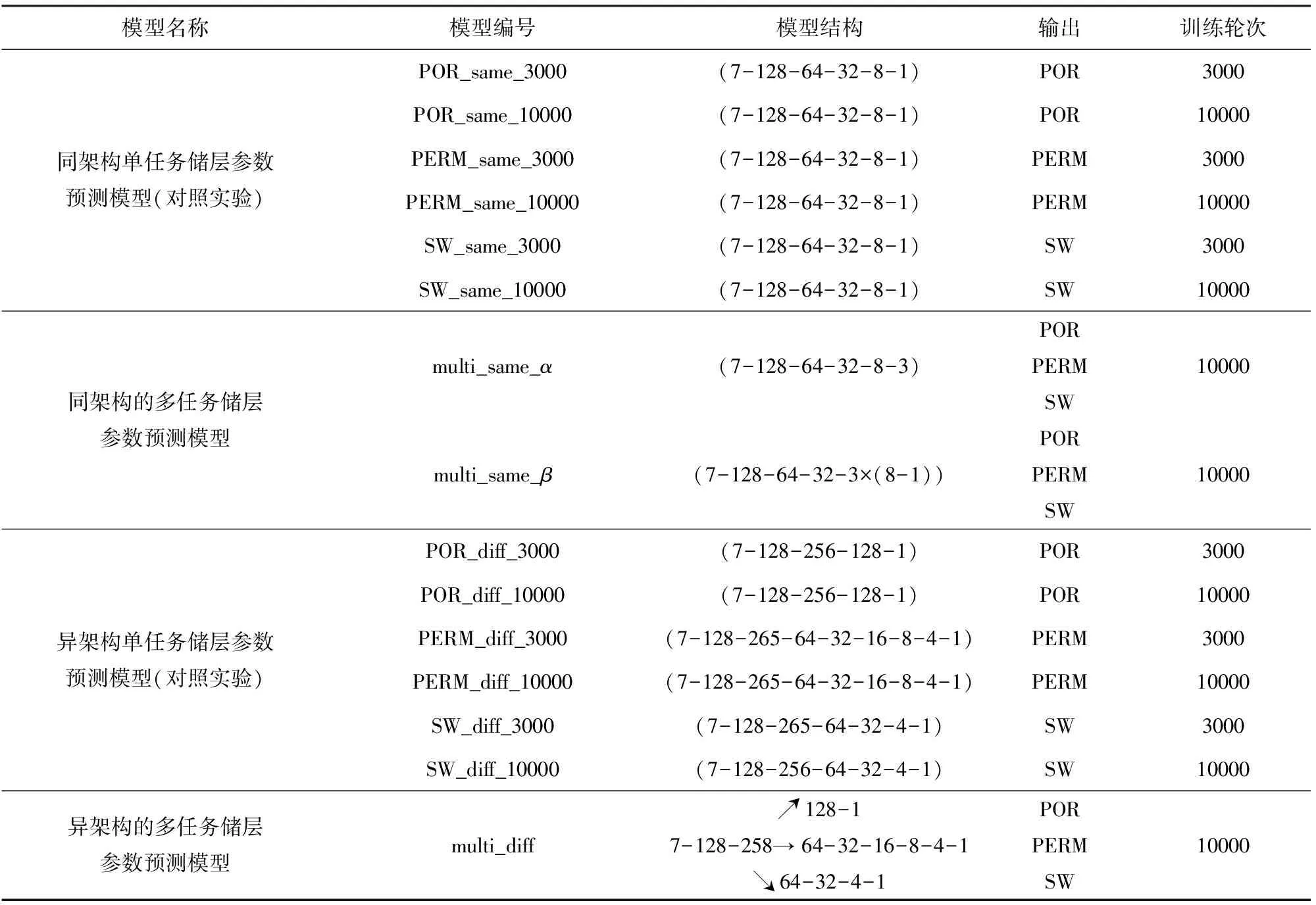
表2 實驗模型統計與編號Table 2 Statistics and numbering of experimental models
模型評價指標使用平均相對誤差(MAPE)和平均絕對誤差(MAE),誤差越小模型表現越好,取5次測試結果評價指標的最大值、最小值與中位數綜合衡量儲層參數預測效果.由于多任務模型同時輸出三種儲層參數,無法分割,在計算最大誤差值、最小誤差值和中位誤差值時使用三種儲層參數的誤差總和.從訓練效果看含水飽和度的MAE與孔隙度和滲透率的MAE存在量級上的差別,因而使用MAPE作為模型主要評價指標,MAE用于輔助單個儲層參數預測效果的評價.
2.3 實驗結果
2.3.1 同架構模型測試結果
同架構的單任務與多任務儲層參數預測模型在測試集上的測試效果如表3所示.
根據各項評價指標,訓練10000輪的單任務模型預測效果優于訓練3000輪的單任務模型;multi_same_α與multi_same_β模型的預測效果優于訓練10000輪的單任務模型;multi_same_β模型的預測效果略優于multi_same_α模型.與對照實驗中訓練10000輪的同架構單任務模型在測試集上的MAPE相比,multi_same_α模型的孔隙度預測效果提升超過30%,滲透率預測效果提升約22%,含水飽和度預測效果提升8%左右;multi_same_β模型的孔隙度預測效果提升超過30%,滲透率預測效果提升約24%,含水飽和度預測效果提升超過10%.
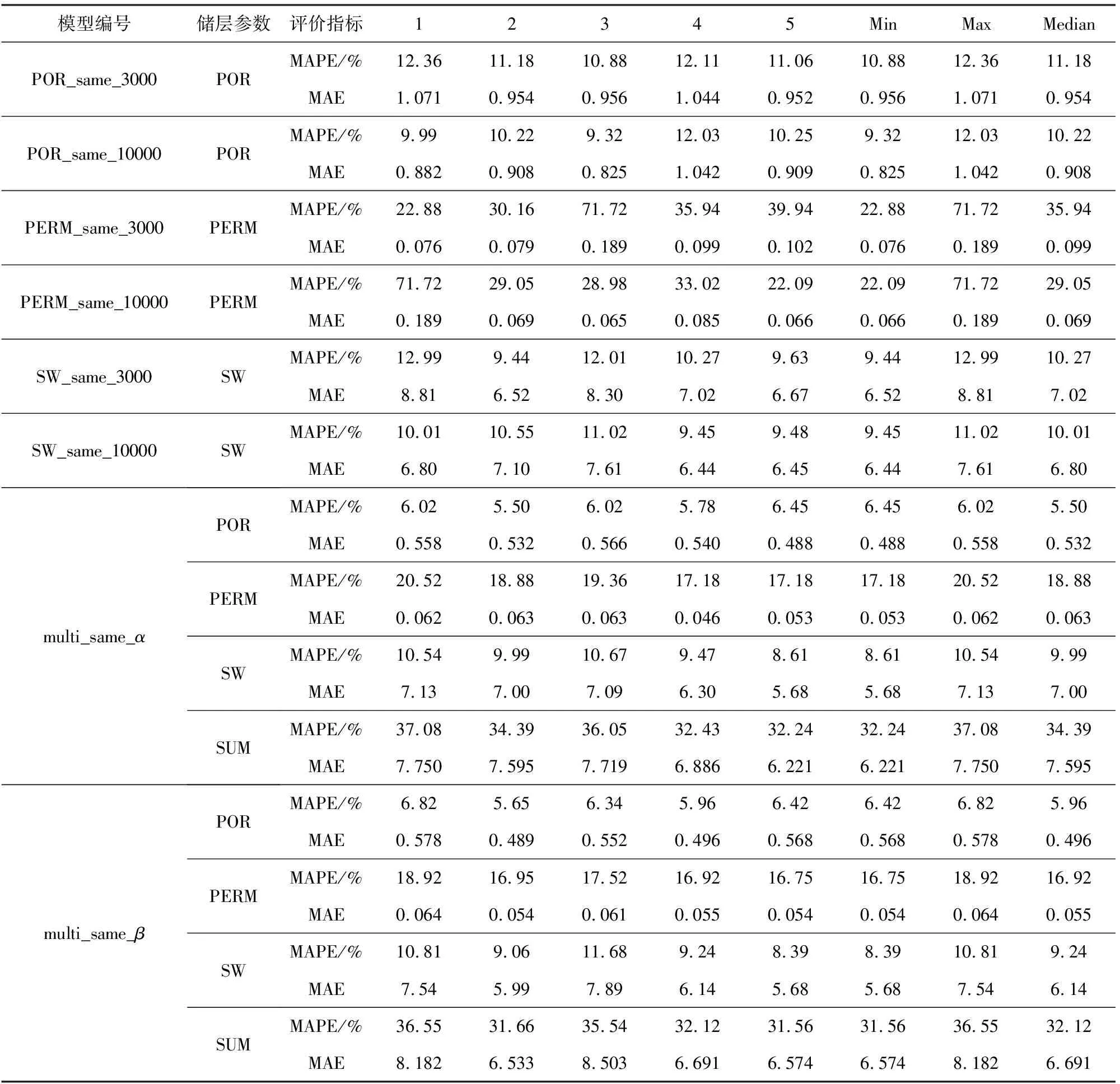
表3 同架構的單任務與多任務儲層參數預測模型測試結果Table 3 Test result of single-task and multitask reservoir parameters prediction models with same structure
2.3.2 異架構模型測試結果
異架構的單任務與多任務儲層參數預測模型在測試集上的測試效果如表4所示.
在對照實驗中,POR_diff_10000模型在測試集上的MAPE明顯低于POR_diff_3000模型,若繼續訓練,該模型或許還有性能提升空間.其余兩種儲層參數預測模型訓練3000輪和10000輪的MAPE差距較小,說明這兩種模型已到達性能極限,無法通過訓練提升模型性能.對比訓練10000輪的對照實驗模型在測試集上的預測效果,multi_diff模型孔隙度預測效果基本沒有提升,滲透率預測效果提升超過60%,含水飽和度預測效果提升超過10%.
從測試集上的表現來看,異架構多任務儲層參數預測模型的綜合預測效果優于同架構的多任務模型,就每個儲層參數而言:
(1)multi_diff模型、multi_same_α模型和multi_same_β模型中孔隙度的預測效果差別不大,MAPE在6%左右.
(2)multi_diff模型的滲透率在測試集上的MAPE在13%左右,multi_same_α和multi_same_β模型的滲透率在測試集上的MAPE在17%左右.
(3)multi_diff模型的含水飽和度在測試集上的MAPE在6%左右,multi_same_α和multi_same_β模型的含水飽和度在測試集上的MAPE在9%左右.
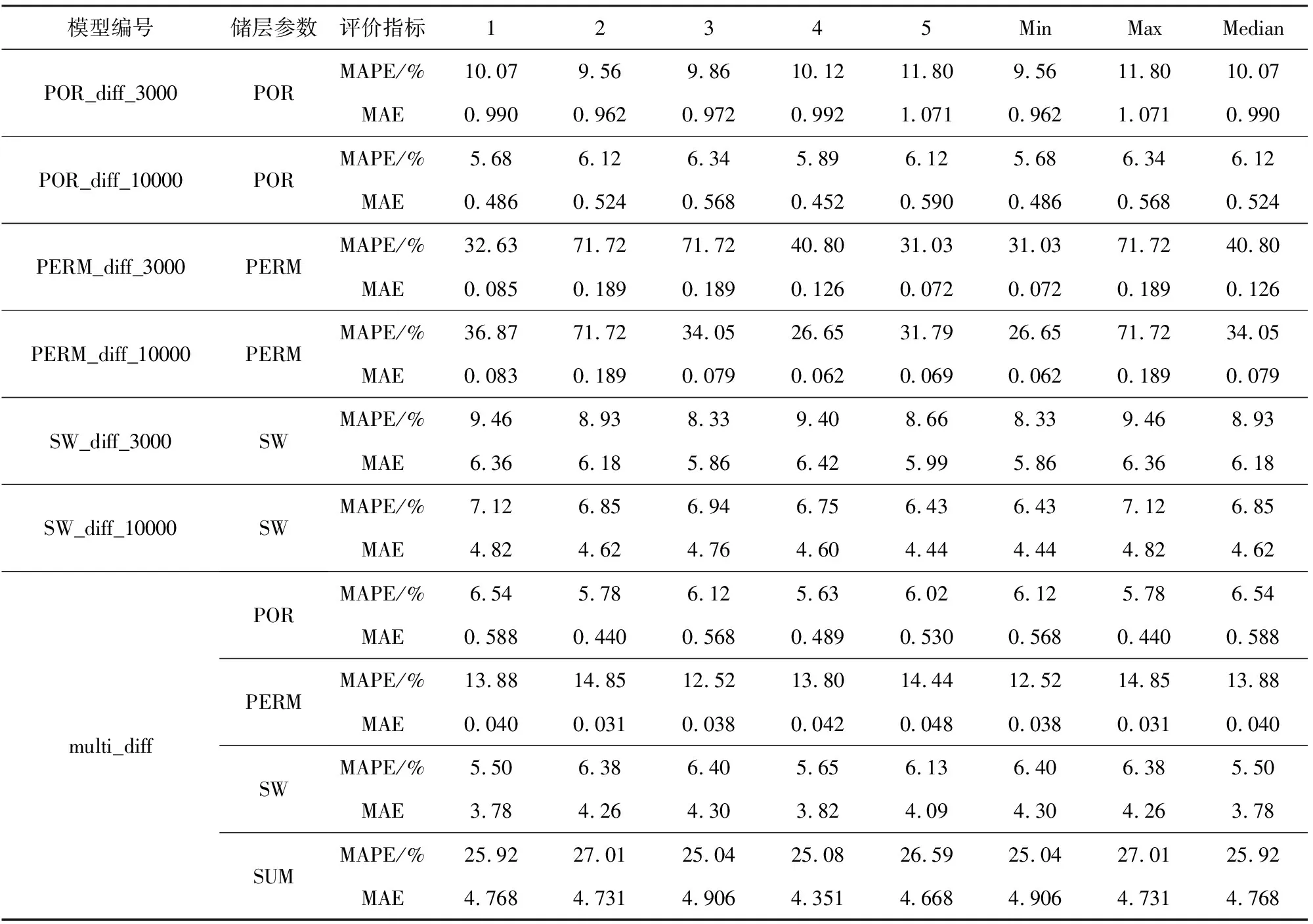
表4 異架構的單任務與多任務儲層參數預測模型測試結果Table 4 Test result of single-task and multitask reservoir parameters prediction models with different structure
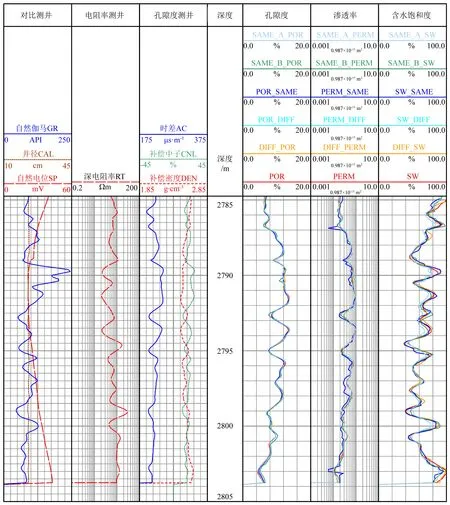
圖5 不同網絡預測實際應用效果對比圖Fig.5 Comparison of practical application performance of different network
實驗中使用的各個儲層參數預測模型的預測效果圖如圖5所示.其中,POR、PERM、SW為儲層參數標簽數據;SAME_A_POR、SAME_A_PERM、SAME_A_SW為multi_same_α模型預測的孔隙度、滲透率和含水飽和度;SAME_B_POR、SAME_B_PERM、SAME_B_SW為multi_same_β模型預測的孔隙度、滲透率和含水飽和度;DIFF_POR、DIFF_PERM、DIFF_SW為multi_diff模型預測的孔隙度、滲透率和含水飽和度;POR_SAME、PERM_SAME、SW_SAME分別為POR_same_10000、PERM_same_10000和SW_same_10000模型的預測值;POR_DIFF、PERM_DIFF、SW_DIFF分別為POR_diff_10000、PERM_diff_10000和SW_diff_10000模型的預測值.從總體預測效果來看孔隙度預測值與標簽值最接近;PERM_same_10000模型預測的滲透率與標簽值的誤差較大,其余模型預測的滲透率和標簽值相差不大;三種儲層參數中含水飽和度的預測值和標簽值差距最大,但總體趨勢和標簽值相吻合.
3 結論
多任務測井儲層參數預測模型可以有效提升單任務儲層參數預測模型的預測效果,效果提升幅度與模型結構有關.多任務模型不僅節省計算資源,還簡化了儲層參數獲取流程.
異架構的多任務儲層參數預測模型總體預測效果最好,具有可以針對每種儲層參數單獨設計私有層架構的特點,有良好的研究前景.
我們還進行了遷移學習測井儲層參數預測的研究,以孔隙度預測模型作為基礎模型對滲透率預測模型和含水飽和度預測模型進行參數遷移.兩項實驗使用同一個數據集,對比兩項實驗的結果可以發現,異架構多任務模型的滲透率和含水飽和度預測效果優于遷移學習的滲透率和含水飽和度預測效果(邵蓉波 et al., 2022).多任務學習和基于相關性的遷移學習均是利用儲層參數之間的相關性影響模型參數的更迭,從而提升神經網絡模型的預測效果.在遷移學習中這種影響是單向的,孔隙度可以影響滲透率預測模型的訓練,而滲透率無法對孔隙度預測模型產生影響,使用遷移學習可以控制信息流動的方向.在多任務模型中這種影響是相互的,孔隙度在影響滲透率預測的同時孔隙度的預測也受到滲透率的影響,無法對信息流動方向進行人為限制.因此兩種方式各有利弊,可根據實際情況選擇合適的模型.根據實驗中發現的問題,下一步研究還將從以下幾個方面展開:
(1)探究不同類別激活函數之間的適配性對多任務儲層參數預測模型效果的影響.
(2)嘗試不同模型架構,探究在多任務模型中模型架構對提升儲層參數預測效果的影響.
(3)考慮使用參數軟共享方式進行多任務學習.
(4)測井數據有較強的序列性,可以考慮將基于異架構多任務儲層參數預測模型推廣至循環神經網絡模型中,例如LSTM和GRU.
(5)借鑒圖像處理方式處理測井數據,并將基于異架構多任務儲層參數預測模型推廣到卷積神經網絡模型中.
致謝外審專家對本文提出了建設性的修改意見,課題組郭云龍幫助本文繪圖,在此一并致謝!
附錄

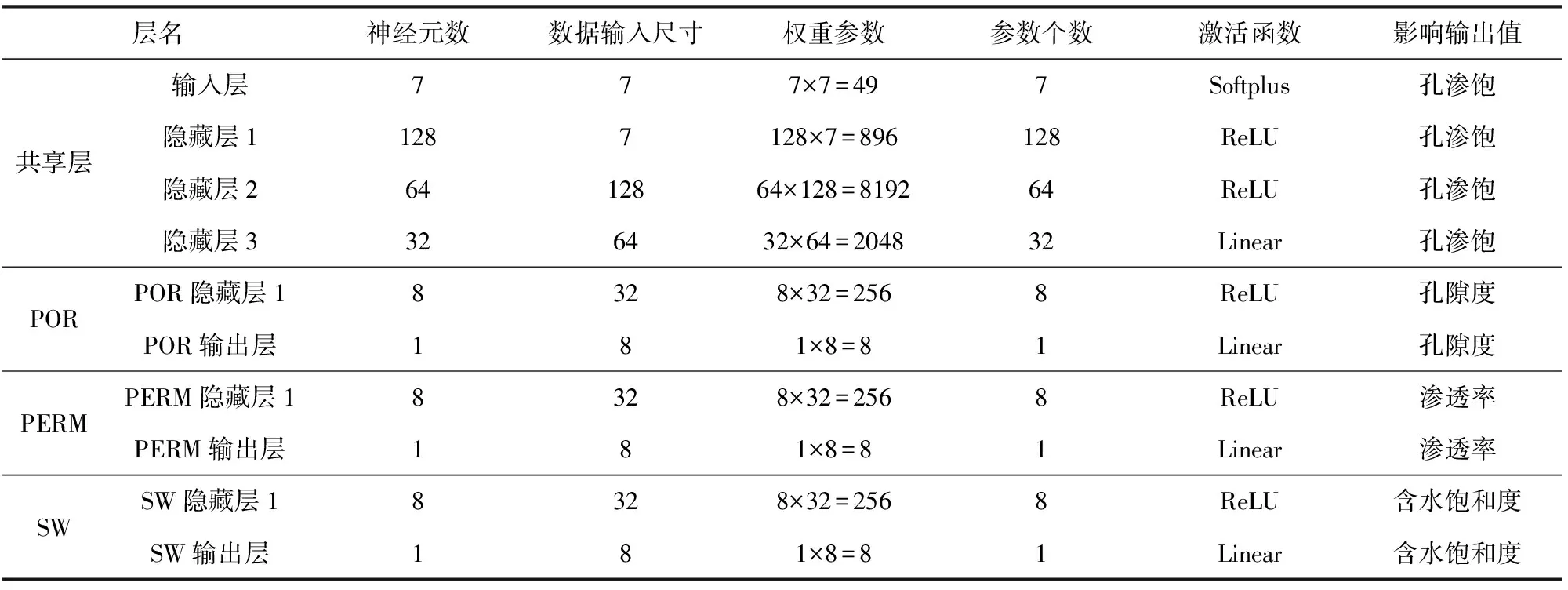
附表A1 同架構多任務儲層參數預測模型α構造與參數Appendix Table A1 Parameters of multitask reservoir parameters prediction model α with the same structure
附表A2 同架構多任務儲層參數預測模型β構造與參數Appendix Table A2 Parameters of multitask reservoir parameters prediction model β with the same structure
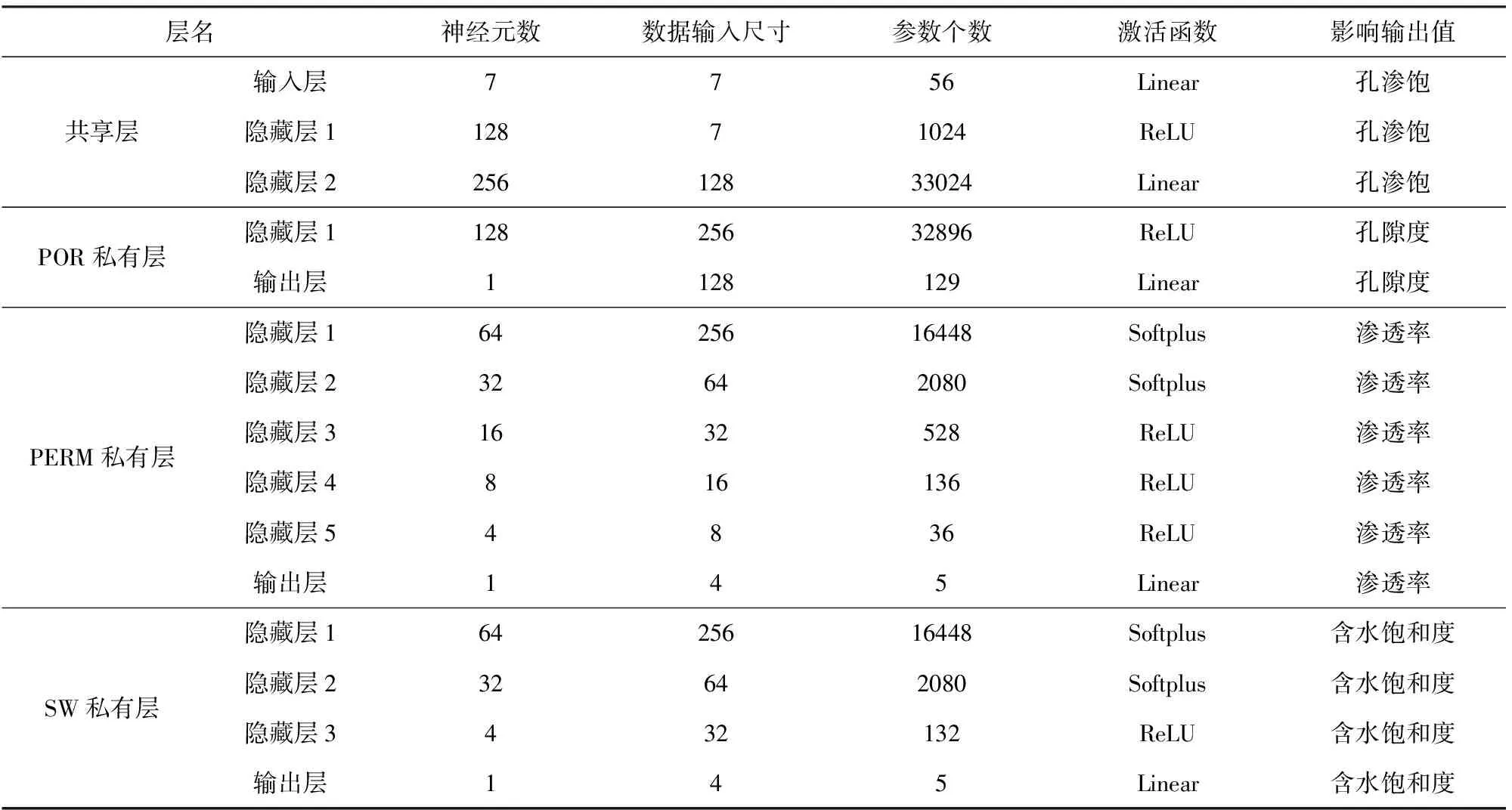
附表A3 異架構多任務儲層參數預測模型結構與參數Appendix Table A3 Parameters of multitask reservoir parameters prediction model with different structure
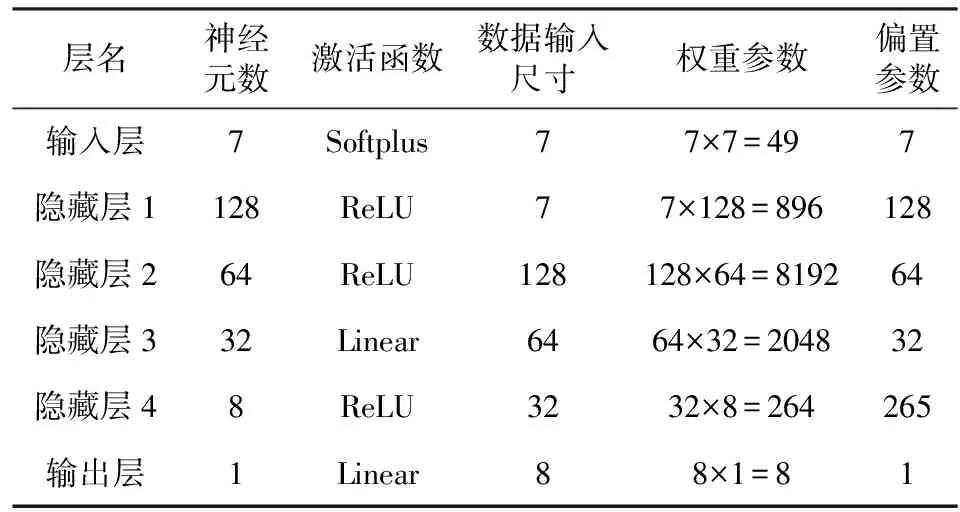
附表A4 同架構單任務儲層參數預測模型構造與參數Appendix Table A4 Parameters of single-task reservoir parameters prediction model with same structure
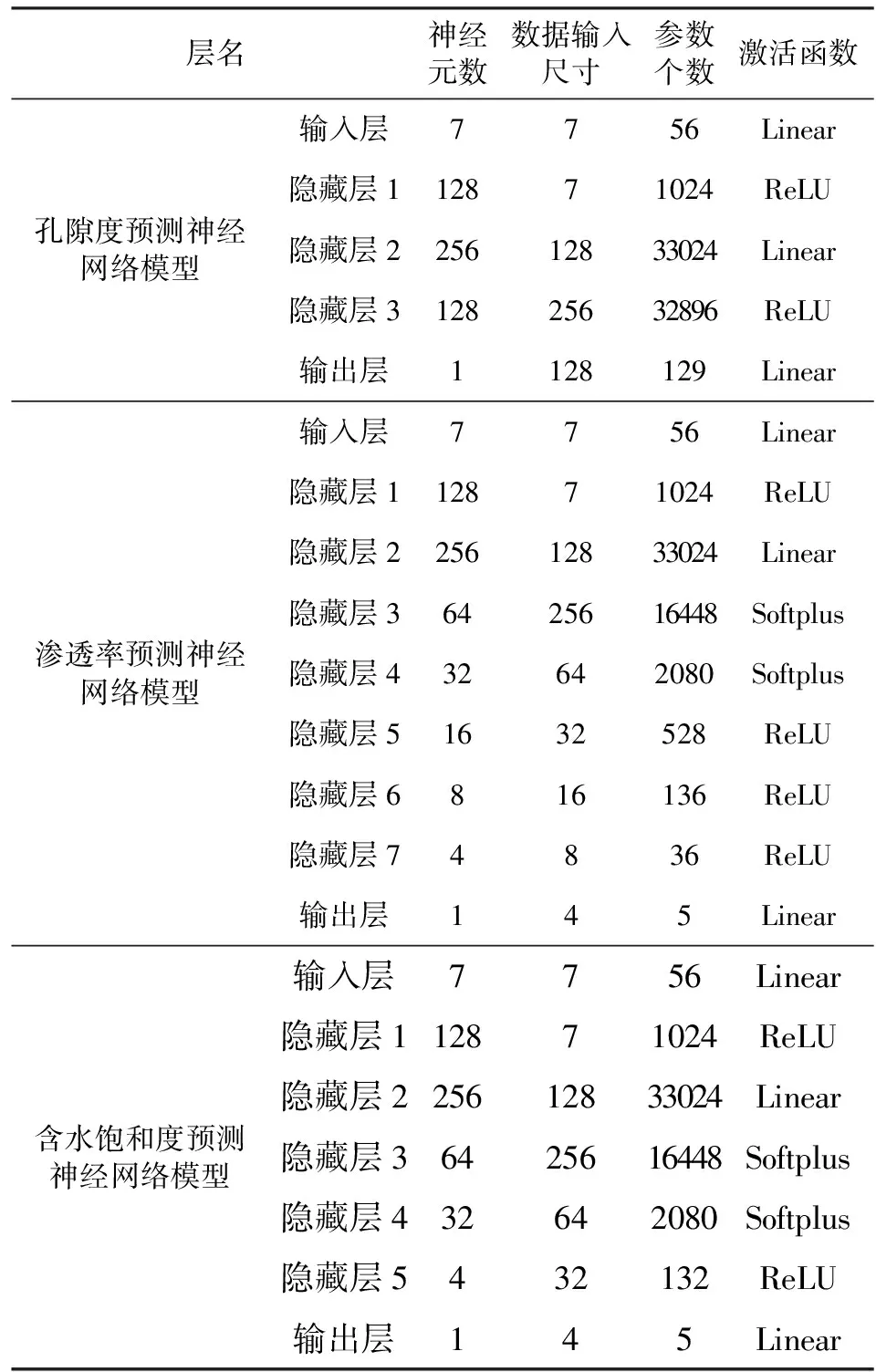
附表A5 異架構單任務神經網絡模型結構與參數Appendix Table A5 Parameters of single-task reservoir parameters prediction models with different structure
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫藥科學(2015年19期)2015-02-27 12:33:11
