
級聯跨域特征融合的虛擬試衣
2022-05-07 07:08:18胡新榮張君宇劉軍平何儒漢
計算機應用 2022年4期
胡新榮,張君宇,彭 濤*,劉軍平,何儒漢,何 凱
(1.湖北省服裝信息化工程技術研究中心(武漢紡織大學),武漢 430200;2.武漢紡織大學計算機與人工智能學院,武漢 430200)
0 引言
近年來,網購服裝逐漸成為人們購買服裝的主要途徑之一,網購服裝的一大難點是缺少試穿的條件,消費者難以想象服裝穿著在自己身上的樣子。對于消費者,虛擬試衣技術可以大幅提升購物體驗;對于商家而言,該技術也能幫助他們節約成本。傳統的虛擬試衣方法使用計算機圖形學建立三維模型并渲染輸出圖像,由于圖形學方法需要對幾何變換和物理約束實現精確控制,這需要大量的人力工作和昂貴的設備來搜集必要的信息,以建立3D 模型和大規模計算。
近年一些基于圖像的虛擬試衣方法,如VITON(VIrtual Try-On Network)、CP-VTON(Characteristic-Preserving VITON)等,不需要用到昂貴的3D 計算,而是將虛擬試衣問題定義為一種條件圖像生成問題。給定目標人物的照片I
,以及一張目標服裝的照片c
,網絡的目標是合成一張新的圖片,由I
中的目標人物,穿著c
中的目標服裝。生成圖像的質量面臨以下挑戰:1)目標人物的體型和姿勢需保持不變;2)服裝的印花圖案,需要在新的體型和姿勢下,保持自然的、逼真的圖案;3)替換上的服裝和目標人體的其他區域,在連接處需要保持平滑;4)生成圖像的身體各部分不能產生不必要的遮擋。生成對抗網絡(Generative Adversarial Network,GAN)在圖像合成、圖像編輯等任務中展現了良好的效果。條件對抗生成網絡(Conditional Generative Adversarial Net,CGAN),通過對模型提供先驗信息(如標簽、文本等),使得生成結果具有想要的屬性,在圖到圖的轉換任務上表現良好。但是大多GAN 不具有明確地適應幾何形變的能力,VITON、CP-VTON 等工作中提到:在處理圖像間大規模形變時,添加對抗損失的提升很小;條件圖像與目標圖像并未很好地對齊時,GAN 傾向于生成模糊的圖像。
文獻[3-4]采用兩階段的策略:首先將目標服裝進行扭曲,使其對齊目標人體;然后將扭曲后的服裝與人體合成在一起。VITON 采用由粗到細的框架,使用薄板樣條插值(Thin Plate Spline,TPS)扭曲服裝。CP-VTON 引入直接學習TPS 參數的策略預測扭曲服裝,并在試衣合成階段采用U-Net生成器,預測服裝區域以外的人物圖像和合成蒙版,來合成最終的試衣圖像。合成蒙版的策略是保留服裝特征的關鍵,CP-VTON 因此獲得了保留服裝細節的能力;但由于合成蒙版難以擬合目標人體的服裝區域,又帶來了嚴重的遮擋問題。
為解決CP-VTON 這類采用合成蒙版策略的工作中容易產生嚴重遮擋的問題,本文提出一種新的關注服裝形狀的虛擬試衣模型。包括兩個模塊:1)服裝扭曲模塊,將目標服裝對準給定人的姿勢;2)試衣合成模塊,將變形服裝與目標人體合成。與CP-VTON 算法相比,本文引入了一種含注意力機制的解碼器,能更好地預測合成蒙版,從而改善結果中的遮擋問題。
1 數據預處理

1.1 著裝人體信息解析
為了盡可能保留人體的特征,并排除I
中原本服裝的影響,VITON 中提出表示人體信息的方法。如圖1 所示,解析出的人體信息P
包含三個部分,一共22 通道,分別為:
圖1 著裝人體信息解析P實現人體和服裝解耦Fig.1 Person representation information P to decouple human body and clothing
1)臉和頭發:3 通道RGB 圖像,包含臉部和頭發部分。采用最先進的人體解析方法計算人體分割圖,并提取在試衣過程中不會改變,能體現身份信息的臉和頭發部分。
2)體型:1 通道,采用人體解析獲得覆蓋人體I
的二值化掩碼,人體區域用1 表示,其他部分用0 表示。為排除不同服裝對掩碼形狀的影響,先將掩碼進行下采樣到較低的分辨率,再通過上采樣恢復原先的分辨率。這樣獲得模糊的掩碼能粗略地覆蓋人體。由于減少不同服裝的影響,能更好地表示基本的體型信息。3)姿勢熱圖:18 通道的姿勢圖,每個通道以二值化表示,各包含有一個人體關鍵點信息,以關鍵點的坐標為中心,在11×11 的矩形范圍內填1,其他部分填0。18 個人體關鍵點由最先進的姿態提取器獲得。
1.2 服裝扭曲模塊
本文實驗采用兩階段的策略,采用CP-VTON預測幾何匹配參數的方法,設計服裝扭曲模塊。通過這個模塊,在人體信息解析P
的指導下,生成扭曲服裝c
。將c
輸入本文改進的試衣模塊,生成最終的虛擬試衣結果。本節將簡要描述服裝扭曲模塊,服裝扭曲模塊如圖2 所示。
圖2 服裝扭曲模塊Fig.2 Clothing warping module
分別將參考服裝c
,目標人體的人體信息解析P
輸入兩個由步長為2 的卷積層組成的編碼器來提取特征。再通過特征匹配將兩組特征融合,送入回歸網絡,預測50 個TPS 轉換參數θ
,并用θ
計算出扭曲后擬合人體的服裝c
。c
的標簽是從I
中通過人體解析獲得的解析服裝部分c
。在c
和c
之間計算L
1 損失:
c
。2 本文模型
服裝掩碼M′
是結合服裝與人體的關鍵,其生成效果的質量將很大程度上影響最終試衣結果的視覺效果。傳統的方法中,使用普通的U-Net 作為試衣合成模塊,生成的M′
不能很好地擬合對應的服裝區域,試衣結果在手臂、頭發處產生遮擋,在不同服裝區域的連接處產生了不自然的接縫。為了解決這類框架中容易產生的遮擋問題,受近年來帶有注意力機制的U-Net啟發,本文設計了一種改進的試衣合成模塊。圖3 為本文試衣合成模塊的框架。給定一張著裝人體圖像I
,將I
中的人體信息與服裝信息解耦,采用VITON 中構建人體信息解析的方法,構建出人體信息解析P
。P
中包含I
中人體的姿態、體型、臉和頭發等信息,但不包含I
中的服裝信息。通過服裝扭曲模塊,獲得大致與目標人體對齊的扭曲服裝c
。將c
與P
作為本文模型的輸入,輸入試衣合成模塊,生成對應目標人體的服裝掩碼M′
和中間人物圖像I
。使用M′
將I
和c
合成最終的試衣結果: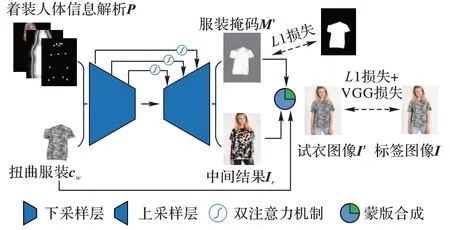
圖3 改進試衣合成模塊的框架Fig.3 Framework of improved try-on synthesis module
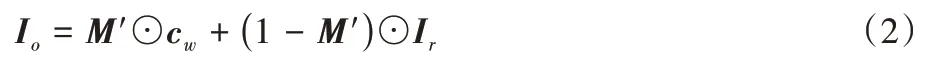
其中:運算⊙表示哈達瑪積。
2.1 改進的試衣合成模塊
試衣合成模塊主要結構是一個U 型網絡,如圖4 所示。編碼器主要由卷積核大小為3×3 的標準卷積函數,以及2×2最大池化的下采樣層組成。編碼階段共經歷四次下采樣,將編碼器的中間特征圖分為5 個尺度,每個尺度下最后一個卷積層的卷積核個數分別為64、128、256、512、1 024。解碼器主要由卷積核大小為3×3 的標準卷積函數,以及最近鄰插值法的上采樣層組成。通過四次上采樣,將解碼器輸出的特征圖分為4 個尺度,每個尺度下最后一個卷積層的卷積核個數分別為512、256、128、64。在編碼器的最后部分,通過一個包含四個卷積核,每個卷積核大小為1×1 的卷積層輸出最終結果。

圖4 改進的試衣合成模塊主要結構Fig.4 Main structure of improved try-on synthesis module
每個尺度下編碼器輸出的特征圖,通過跳躍連接和低分辨率的解碼器塊融合,捕捉更多的語義和空間信息。在融合時,本文提出級聯的雙注意力解碼器,將在2.2 節描述。
2.2 解碼器的級聯注意力機制
如圖5 所示,通過跳躍連接傳來的特征圖d
,首先通過一個通道注意力路徑,再通過一個空間注意力路徑,且計算注意力時,都要結合解碼器上采樣得到的特征圖g
的信息。
圖5 級聯的雙注意力機制Fig.5 Cascaded dual attention mechanism

g
,與通道注意力路徑的輸出結果d′
,分別通過1×1 卷積輸出單通道的特征圖,兩個特征圖相加之后送入ReLU 函數,再通過1×1 卷積和Sigmoid 函數,獲得通道為1、分辨率和d′
相同的參數矩陣β
,與d′
相乘,作為注意力模塊的輸出結果d″
。每一層解碼器的最終輸出結果F
為:
x
)為卷積核大小為3×3 的卷積函數;cat(x
)為通道連接操作。2.3 試衣合成模塊的損失函數
通過人體解析,從參考圖像I
中得到的服裝區域的掩碼M
,作為服裝掩碼M′
的ground truth,訓練時通過最小化L
1損失,減小M′
和M
的差異:
I
與I
之間的差異,計算Perceptual損失和L
1 損失。Perceptual 損失定義如下:
φ
(I
)表示圖像I
在視覺感知網絡φ
的第i
層的特征圖;φ
是在ImageNet上預訓練的VGG19網絡;i
≥1 表 示conv1_2、conv2_2、conv3_2、conv4_2、conv5_2。試衣合成模塊的總體損失函數為:
3 實驗與結果分析
3.1 數據集
在Wang 等使用的數據集上進行實驗。包含16 253 張正視圖女人圖像和正面服裝圖像對,圖像大小為256×192。分為14 221 組訓練集對和2 032 組測試集對。將測試集打亂排列為未配對的圖像對用于進一步評估。
3.2 定量評價方案
在相同實驗設置的條件下,比較本文方法與CPVTON、ACGPN的試衣結果。其中,CP-VTON 需重新訓練,ACGPN(Adaptive Content Generating and Preserving Network)則采用在Github 網站上提供的訓練好的模型(https://github.com/switchablenorms/DeepFashion_Try_On)。
在打亂排列的測試集上,對試衣結果計算FID(Fréchet Inception Distance)評分。由于打亂排列的測試集上獲得的試衣結果沒有對應的ground truth,對一一配對的測試集的試衣結果計算結構相似性(Structure SIMilarly,SSIM)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)評分和VGG 誤差(VGG Error)評分。通過記錄網絡的參數量,來衡量網絡的空間復雜度。

2)SSIM:從亮度,結構和對比度三個方面,計算合成圖像和ground truth 之間的相似性,值域從0 到1。SSIM 值越高越好。
3)PSNR:越大越好。
4)VGG Error:衡量兩者之間的感知損失,越小越好。
3.3 實施細節
在所有實驗中,訓練階段設置λ
=λ
=λ
=1。訓練服裝扭曲模塊和試衣合成模塊各200 000 步,batch size 設置為4,使用Adam 優化器,β
=0.5,β
=0.999。學習率在前100 000 次迭代中設置為0.000 1,在剩下的100 000 次迭代中線性衰減到0。輸入和輸出圖像的分辨率都是256×192。服裝扭曲模塊中,人體信息圖像和服裝圖像采用相同結構的特征提取網絡,包含4 個2 步長卷積層,2 個1 步長的卷積層,卷積核的數量分別為64、128、256、512、512。回歸網絡包含2 個2 步長的卷積層,2 個步長為1 的卷積層和一個全連接輸出層。卷積核的數量分別為512、256、128、64。全連接層階層預測50 個TPS 參數。
3.4 定量結果
表1 是本文模型與CP-VTON、ACGPN的比較結果。其中:↑表示越高越好,↓表示越低越好。

表1 三種模型的定量結果對比Tab 1 Comparison of quantitative results among three models
與CP-VTON 相比,本文模型的PSNR 提高了10.47%,FID 減小了47.28%,SSIM 提高了4.16%。與ACGPN 相比,本文模型在FID 評分上較差,一定程度上是由于ACGPN 能更好地保留褲子、手部等非換裝區域特征;但本文模型的網絡參數量相較于ACGPN,減少約87.34%,同時在PSNR 和VGG Error 上取得最好的結果,也能說明本文模型的先進性。
3.5 定性結果
圖6 展示了本文模型與CP-VTON 服裝掩碼M′
生成效果的對比結果。當M′
能對應目標服裝在目標人體的服裝區域時,認為M′
達到了較好的生成效果。中間結果I
的主要作用在于生成臉部、褲子、手臂等非換裝區域。由圖6 可以看出,本文模型取得了更好的效果,并且在最終的試衣結果中,改善了遮擋現象。
圖6 本文模型與CP-VTON的服裝掩碼M′生成效果對比Fig.6 Comparison of generation effect of clothing mask M′between proposed model with CP-VTON
圖7 展示了本文模型與CP-VTON、ACGPN 之間的視覺效果對比結果。與CP-VTON 模型相比,本文模型都取得了更清晰的結果;與ACGPN 相比,本文模型和ACGPN 都能生成清晰的圖像結果:ACGPN 的結果優勢在于能更好地保留褲子的特征(圖7 第2、3 行),并在手部的細節保留上有優勢(圖7 第1、2 行),本文模型的優勢在于能更好地保留服裝的細節(圖7 第1 行領口部位),不會在手臂出現缺少像素的情況(圖7 第2、3 行左臂)。

圖7 本文模型與CP-VTON、ACGPN的視覺效果對比結果Fig.7 Visual effects of proposed model compared with CP-VTON and ACGPN
CP-VTON 的缺陷在于,試衣合成模塊獲得的組成掩碼M′
不能很好地對齊身體的上衣部分。而M′
生成的質量不佳,將導致服裝與手臂和頭發等部位產生大量的遮擋。生成M′
的同時,試衣合成模塊同時生成中間人物圖像I
,I
會承擔一定的全局優化作用,由于遮擋問題的存在,I
不得不承擔更多的調節遮擋功能,與此同時,I
的主要功能、恢復圖像清晰度以及調節服裝花紋的能力將遭到減弱。實驗結果表明,相較于CP-VTON,本文方法能獲得更少遮擋的結果,生成更清晰的圖像,更好地保留服裝細節。
4 結語
本文方法在U-Net 解碼器上添加級聯的注意力機制,能夠使模型更好地注意到目標人體的服裝區域,生成了更符合人體特征的服裝組成掩碼,并且進一步提高了圖像的生成質量。但本文所提試衣方法,在面對復雜的服裝印花時,依然有較嚴重的失真現象。在很大程度上,是由于服裝扭曲階段獲得的結果不能很好地擬合人體。在未來的工作中,將在服裝扭曲階段進行改進,獲得更好的扭曲服裝結果后,能夠更好地發揮本文中提出的試衣合成模塊的性能。
