基于輕量級網(wǎng)絡(luò)的人臉檢測及嵌入式實現(xiàn)
2022-05-09 06:55:18張芳慧宗佳平岑翼剛張琳娜
圖學(xué)學(xué)報 2022年2期
張 明,張芳慧,宗佳平,宋 治,岑翼剛,張琳娜
基于輕量級網(wǎng)絡(luò)的人臉檢測及嵌入式實現(xiàn)
張 明1,張芳慧1,宗佳平1,宋 治2,岑翼剛1,張琳娜3
(1. 北京交通大學(xué)信息科學(xué)研究所,北京 100044;2. 深圳市光點智能科技有限公司,廣東 深圳 518000;3. 貴州大學(xué)機械工程學(xué)院,貴州 貴陽 550025)
盡管基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的人臉檢測器在精度上已經(jīng)有了很大提升,但所需的計算量和模型復(fù)雜度越來越高,如何在計算能力有限的嵌入式設(shè)備上應(yīng)用人臉檢測模型是一個很大的挑戰(zhàn)。針對320×240分辨率輸入圖像的人臉檢測在嵌入式系統(tǒng)上的應(yīng)用問題,提出了一種基于輕量級網(wǎng)絡(luò)的低分辨率人臉檢測算法。該算法使用注意力機制、結(jié)合了Distance-IoU (DIoU)與非極大值抑制(NMS)、使用Mish激活函數(shù),同時針對人臉特征比例設(shè)置合適的先驗框,實現(xiàn)了精度和速度的平衡,并部署到嵌入式平臺中。具體地,用深度可分離卷積替代普通卷積,并在卷積塊后加入注意力模塊(CBAM),使網(wǎng)絡(luò)更關(guān)注待識別的目標(biāo)物體;代替ReLU激活函數(shù),采用了Mish激活函數(shù)來提高模型推理速度;通過結(jié)合DIoU與NMS,提高模型對小人臉的檢測能力。實驗在WIDER FACE數(shù)據(jù)集的結(jié)果證明,該方法不僅能實時高精度地進行人臉檢測,而且在小分辨率輸入上,精度高于傳統(tǒng)算法。擴充數(shù)據(jù)集之后,模型在復(fù)雜光照下的泛化性得到提高。
人臉檢測;輕量級網(wǎng)絡(luò);注意力機制;激活函數(shù);非極大值抑制
人臉檢測是計算機視覺領(lǐng)域的重要研究方向之一,是人臉校準(zhǔn)、人臉識別、人臉驗證、人臉比對和跟蹤等應(yīng)用的基礎(chǔ)技術(shù)。近年來,人臉檢測已有了進一步地研究,并被廣泛應(yīng)用于安防監(jiān)控、面部表情識別、人機交互等領(lǐng)域。由于嵌入式設(shè)備內(nèi)存容量和計算能力有限,如何得到輕量且精準(zhǔn)的人臉檢測算法成為受關(guān)注的話題。
人臉檢測是目標(biāo)檢測領(lǐng)域的特殊分支,經(jīng)歷了從依賴手工提取特征到深度學(xué)習(xí)網(wǎng)絡(luò)的發(fā)展。盡管手動提取特征的方法能夠?qū)崿F(xiàn)較快的檢測速度,但嚴(yán)重依賴所提取的特征質(zhì)量,因不進行端到端的訓(xùn)練,導(dǎo)致檢測效果不夠魯棒。此后,基于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)的人臉檢測器取得了很大的進展,可分為單階段和兩階段法2類。兩階段法分為區(qū)域選擇和定位回歸2部分,主要是由Faster R-CNN[1]系列為代表。由于兩階段法延遲較高,出現(xiàn)了YOLO系列[2-5]、SSD (single shot MultiBox detector)[6]和RetinaNet[7]等單階段法。為了處理多尺度或小物體問題,YOLO系列提出了新的錨框匹配策略,并對物體的寬度和高度的回歸重新加權(quán);SSD使用多級特征圖組合結(jié)構(gòu);特征金字塔網(wǎng)絡(luò)(feature pyramid networks,F(xiàn)PN)[8]引入了特征金字塔結(jié)構(gòu)。
除了通用目標(biāo)檢測提出的新方法之外,其他領(lǐng)域的發(fā)展也促進了人臉檢測。非極大值抑制(non-maximum suppression, NMS)是目標(biāo)檢測常用的后處理方法,用來解決同一個目標(biāo)在檢測時預(yù)測框冗余的問題。提取置信度高的檢測框,抑制置信度低的檢測框,去除重復(fù)框,得到正確的檢測框。常用的NMS方法對于多個預(yù)測框重疊的情況下會導(dǎo)致錯誤的抑制,將DIoU[9]與NMS相結(jié)合,能夠進一步考慮2框中心點的位置信息,使預(yù)測框更符合實際。激活函數(shù)是深度神經(jīng)網(wǎng)絡(luò)中引入非線性的關(guān)鍵,目前神經(jīng)網(wǎng)絡(luò)中最常用的激活函數(shù)是ReLU (rectified linear unit)。但其會出現(xiàn)硬零邊界和過于簡單的非線性處理的問題,而Mish[10]激活函數(shù)較平滑且能有效地緩解硬零邊界問題。注意力機制在目標(biāo)檢測領(lǐng)域中,能將圖片數(shù)據(jù)中關(guān)鍵的特征標(biāo)識出來,通過學(xué)習(xí)訓(xùn)練,讓深度神經(jīng)網(wǎng)絡(luò)學(xué)到每一張圖片中需要關(guān)注的區(qū)域,從眾多信息中選出對當(dāng)前任務(wù)目標(biāo)更關(guān)鍵的信息。卷積塊注意模塊(convolutional block attention module,CBAM)[11]是一種簡單有效的用于前饋神經(jīng)網(wǎng)絡(luò)的注意力模塊。在給定中間特征映射后,沿著通道和空間2個維度依次推導(dǎo)出注意映射,再將注意映射乘到輸入特征映射上進行特征自適應(yīng)學(xué)習(xí)。
目前基于深度學(xué)習(xí)的人臉檢測面臨的主要難點是如何在有限的計算資源上應(yīng)用。這個問題主要是因為模型本身復(fù)雜度高和參數(shù)的冗余度大。為了解決該問題,用輕量級網(wǎng)絡(luò)設(shè)計和對模型參數(shù)進行剪枝、量化處理。輕量級網(wǎng)絡(luò)設(shè)計的主要思想是設(shè)計高效的卷積方式,從而在網(wǎng)絡(luò)參數(shù)減少的同時,不損失網(wǎng)絡(luò)性能。MobileNet[12]用深度可分離卷積替代傳統(tǒng)卷積,深度可分離卷積將標(biāo)準(zhǔn)卷積分解為一個深度卷積和一個點卷積,分別起到濾波和線性組合的作用,同時減少參數(shù)量和計算量。
本文提出一個針對輸入圖像分辨率在320×240、大小為1 MB左右的人臉檢測模型,并應(yīng)用到嵌入式平臺上。在原算法的骨干網(wǎng)絡(luò)中引入了注意力機制,使特征提取網(wǎng)絡(luò)提取有效的目標(biāo)信息并抑制無用信息,增強特征圖的表達(dá)和上下文描述能力。通過修改NMS方式和激活函數(shù),提高了模型精度的同時適當(dāng)增加模型復(fù)雜度,保證速度和精度的平衡。
1 本文工作
本文采用的輕量級網(wǎng)絡(luò)結(jié)構(gòu)包含6組卷積塊(block),每組卷積塊均包含不同數(shù)量的卷積和一個注意力模塊。block3~block6等4個模塊對應(yīng)著4個不同尺度的特征圖,形成不同尺度的預(yù)測,從而提高檢測精度。這樣做雖然降低模型的檢測速率,但能提高模型的檢測精度,在一定程度上可取得速度和精度的權(quán)衡。四分支對應(yīng)的檢測框個數(shù)分別為3,2,2,3,長寬比為1∶1,可加強對小人臉和大人臉的檢測能力。由于Mish函數(shù)圖像和導(dǎo)數(shù)圖像更加平滑,能夠更好地表達(dá)網(wǎng)絡(luò)深層語義信息,因此在本文網(wǎng)絡(luò)結(jié)構(gòu)中采用Mish激活函數(shù)。為了增強網(wǎng)絡(luò)對復(fù)雜背景下人臉信息的獲取,每組卷積塊后均增加了CBAM注意力層。在進行NMS運算時,結(jié)合了DIoU方法,與原IoU-NMS相比,加強了對小人臉的檢測能力,能夠小幅度提升檢測效果。其主干網(wǎng)絡(luò)的結(jié)構(gòu)如圖1所示。
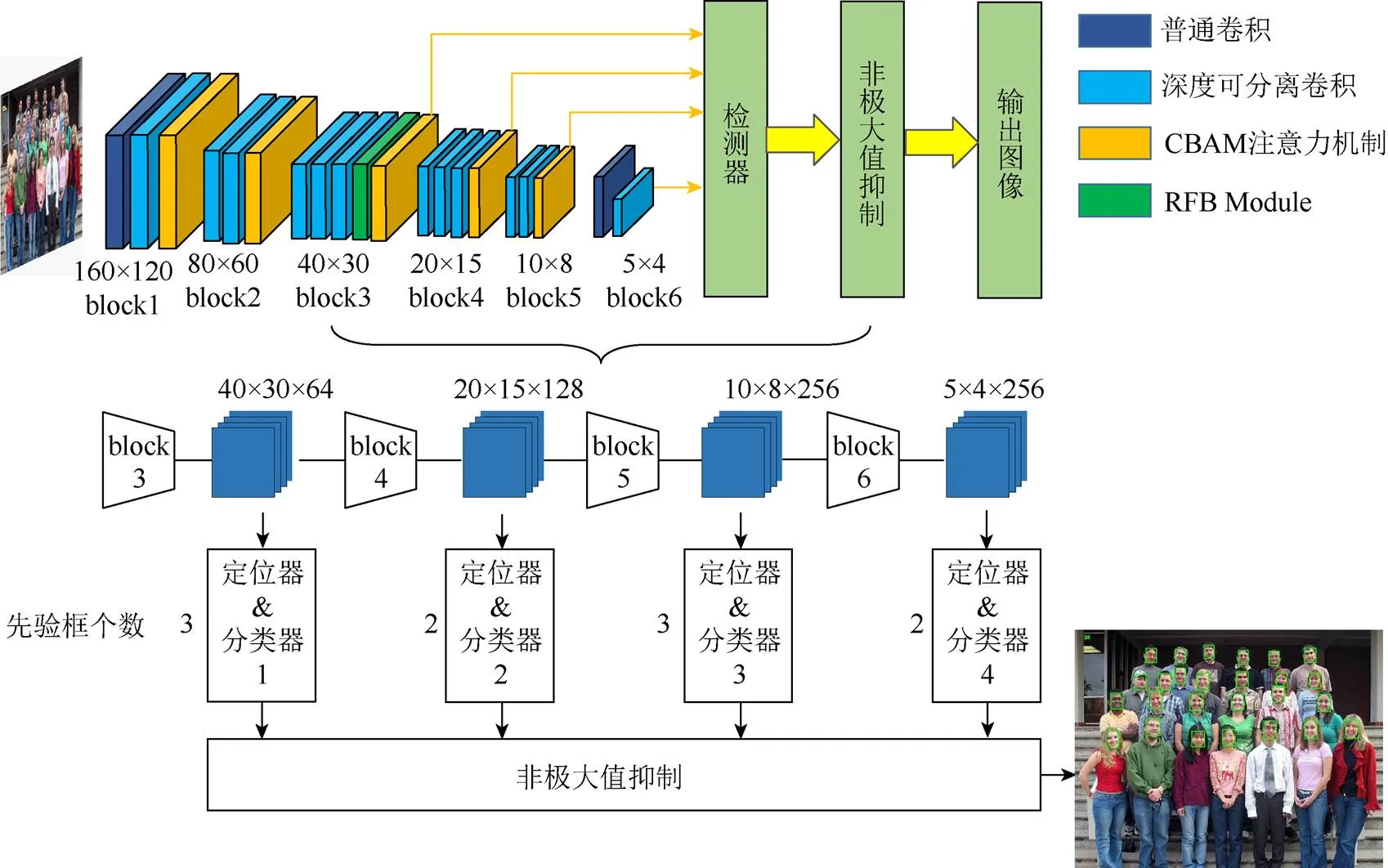
圖1 網(wǎng)絡(luò)總體結(jié)構(gòu)
首先將輸入圖像縮放為320×240,送入由6個block串聯(lián)而成的網(wǎng)絡(luò)結(jié)構(gòu)進行訓(xùn)練和檢測。選擇40×30,20×15,10×8和5×4等4種不同尺度的特征層上設(shè)置多個先驗框,加強對大、中、小目標(biāo)的檢測。網(wǎng)絡(luò)中每個模塊卷積層的具體參數(shù)設(shè)置見表1。其中,網(wǎng)絡(luò)中的感受野塊(receptive field block, RFB)[13]通過模擬人類視覺感受野加強網(wǎng)絡(luò)的特征提取能力,結(jié)構(gòu)上主要是在Inception的基礎(chǔ)上加入了dilated卷積層,從而有效增大了感受野,該模塊的具體結(jié)構(gòu)如圖2所示。圖1網(wǎng)絡(luò)總體結(jié)構(gòu)中的CBAM模塊的具體結(jié)構(gòu)如圖4(c)所示。
1.1 DIoU-NMS
在目標(biāo)檢測算法中,CNN獲取多個預(yù)測框之后,進行IoU計算,得到最優(yōu)候選框。但是IoU只考慮了重疊情況下的交并比,對于多個預(yù)測框重疊的情況下,將導(dǎo)致錯誤的抑制。DIoU的運算過程中,結(jié)合了預(yù)測框和真實框之間的交并比、距離、重疊率和尺度4個因素,結(jié)果更加準(zhǔn)確,計算函數(shù)見式(2)。因此本文使用DIoU作為NMS的標(biāo)準(zhǔn),記為DIoU-NMS。


其中,為預(yù)測框;B為真實框;為目標(biāo)框與真實框之間的重疊度;和b分別為錨框和真實框各自的中心點;為2個中心點之間的歐氏距離;為能同時覆蓋錨框和目標(biāo)框的最小矩形的對角線。DIoU-NMS能充分判斷重疊率較高的2個邊界框是否屬于同一個目標(biāo),從而有效地進行邊框抑制。

表1 網(wǎng)絡(luò)結(jié)構(gòu)
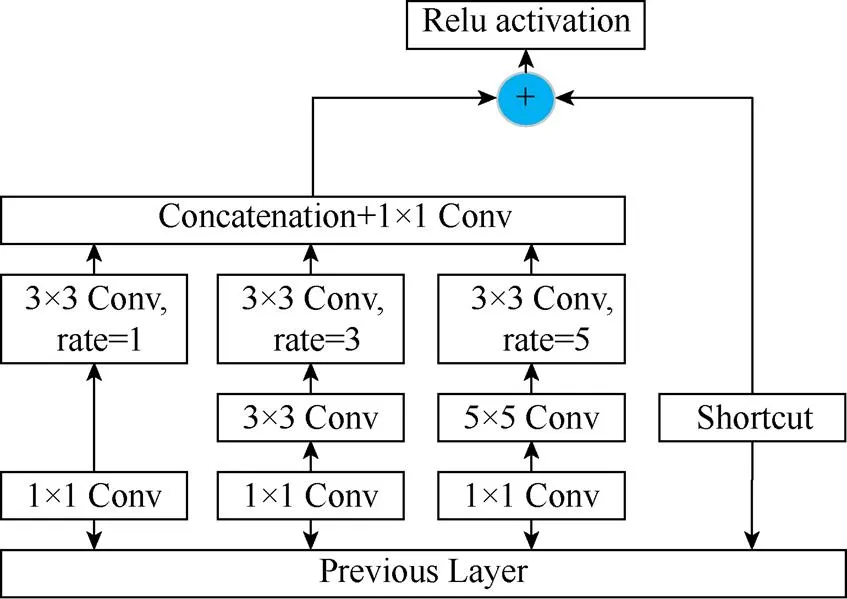
圖2 RFB結(jié)構(gòu)圖
1.2 Mish激活函數(shù)
在本文的CNN中采用Mish激活函數(shù)。Mish函數(shù)是一個無上界、有下界、平滑非單調(diào)的激活函數(shù),其函數(shù)和導(dǎo)數(shù)可表達(dá)為

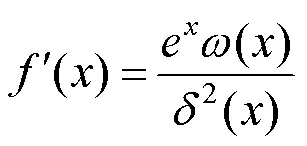
其中,()=4(+1)+42x+3x+e(4+6);()=2e+2x+2。
激活函數(shù)ReLU和Mish函數(shù)及導(dǎo)數(shù)示意圖如圖3所示。在圖3(a)中,2個函數(shù)的正值部分基本一致,負(fù)值部分Mish函數(shù)可以有更好的梯度流。當(dāng)輸入為負(fù)時,Mish函數(shù)不會產(chǎn)生梯度消失問題,如圖3(b)所示。并且Mish函數(shù)和其導(dǎo)數(shù)更平滑,能夠使更好的信息深入網(wǎng)絡(luò),從而達(dá)到更好的準(zhǔn)確性和泛化。

圖3 激活函數(shù)示意圖((a)函數(shù)圖;(b)導(dǎo)數(shù)圖)
1.3 注意力機制CBAM
注意力機制能使網(wǎng)絡(luò)在全局圖像中更多地關(guān)注在目標(biāo)區(qū)域、抑制其他區(qū)域,從而可在有限的資源條件下篩選出大量的高價值信息。常用的注意力機制的基本模塊有Non-local block[14],SENet[15]和CBAM等3種,如圖4所示。Non-local網(wǎng)絡(luò)使用自注意力機制建模遠(yuǎn)程依賴,主要利用位置信息。SE module是通道注意力機制網(wǎng)絡(luò),主要利用損失函數(shù)去學(xué)習(xí)特征權(quán)重,對不同通道進行權(quán)重標(biāo)定。CBAM是一種結(jié)合空間和通道的注意力機制,沿著通道和空間2個獨立的維度依次導(dǎo)出注意映射,再將注意映射與原特征映射相乘,對特征做自適應(yīng)調(diào)整。
在網(wǎng)絡(luò)結(jié)構(gòu)中分別引入以上3個注意力模塊,使用Grad-cam[16]進行網(wǎng)絡(luò)可視化,得到的結(jié)果如圖5所示。紅色和藍(lán)色分別代表模型高和低關(guān)注度。第1~3行分別為Non-local block,SE module和CBAM的可視化結(jié)果,能夠看出,在該網(wǎng)絡(luò)中,Non-local block和SE module更關(guān)注圖像中的人體部分,而CBAM注意力機制能夠更關(guān)注人臉而非背景區(qū)域,因此能夠得到更好地檢測結(jié)果。
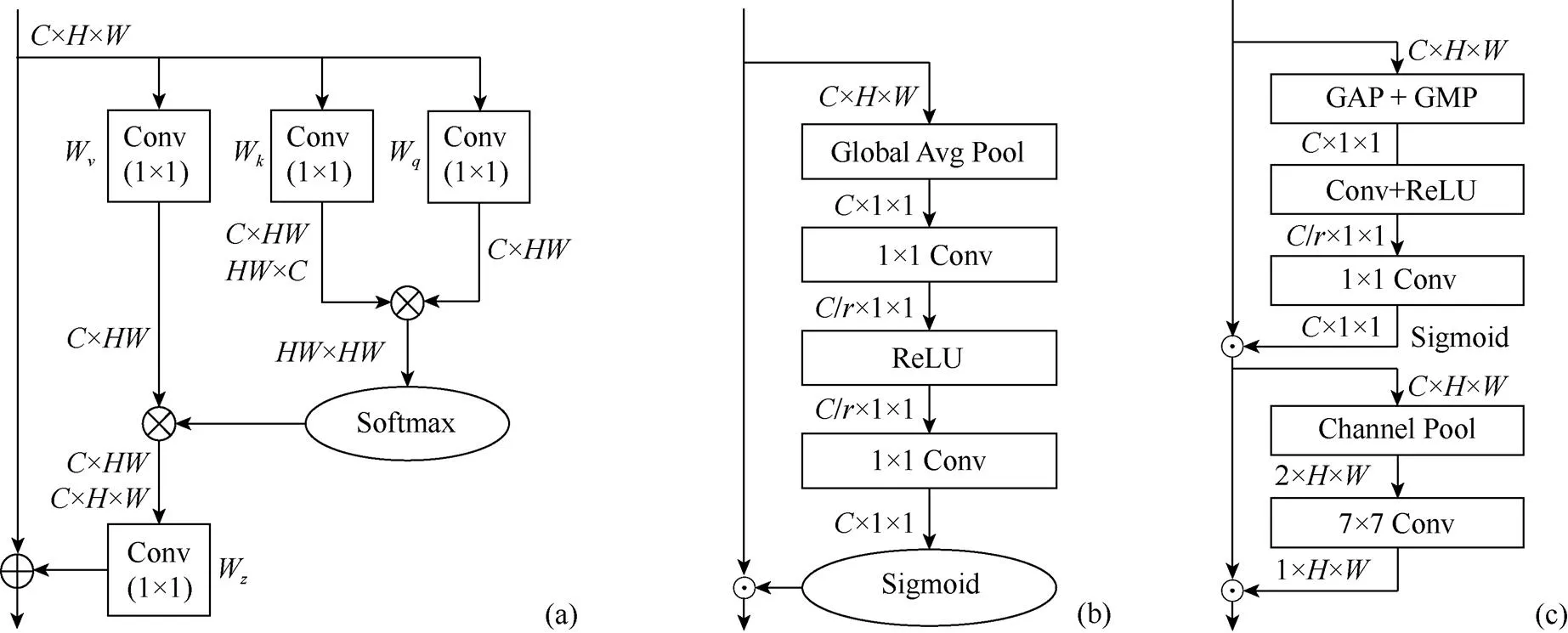
圖4 不同注意力模塊結(jié)構(gòu)圖對比

圖5 Grad-cam網(wǎng)絡(luò)可視化結(jié)果
2 實驗與結(jié)果分析
2.1 數(shù)據(jù)集
本文采用5個人臉關(guān)鍵點的WIDER FACE數(shù)據(jù)集[17]。該數(shù)據(jù)集是目前已知最大的人臉檢測數(shù)據(jù)集,共有32203張圖片,包括393703張臉,其在尺度、姿態(tài)、遮擋、光照等方面均有很大的變化范圍。通過從61個場景類別中隨機抽樣,根據(jù)4∶1∶5的比例將該數(shù)據(jù)集分為訓(xùn)練集、驗證集和測試集。
2.2 模型訓(xùn)練
本文在Ubuntu16.04系統(tǒng)、一塊NVIDIA GTX1060顯卡、顯存為6 GB的筆記本上進行實驗。并采用PyTorch深度學(xué)習(xí)框架進行網(wǎng)絡(luò)訓(xùn)練,之后再將其部署到嵌入式平臺上,搭建人臉檢測系統(tǒng)。該嵌入式平臺采用勘智K210芯片,搭載Sipeed_OV2640攝像頭,輸入圖像分辨率為320×240。
在網(wǎng)絡(luò)訓(xùn)練過程中使用隨機梯度下降優(yōu)化,動量為0.9,權(quán)重衰減為0.000 5,批處理尺寸為6×4。學(xué)習(xí)速率從0.001開始,經(jīng)過5個輪次后上升到0.01,第95和第150次除以10。訓(xùn)練過程在250個輪次結(jié)束。分類和回歸損失分別為交叉熵和SmoothL1損失函數(shù)。
2.3 實驗結(jié)果分析
表2展示了模型在WIDER FACE驗證集上的AP、模型大小和推理速度。其中,驗證集根據(jù)邊緣框的檢測情況劃分為easy,medium和hard等3個難度等級。單尺度測試的Baseline模型在驗證集中分別可得到77.9%,69.1%和41.7%,依次添加CBAM,Mish和DIoU-NMS模塊進行測試,實驗結(jié)果表明,同時添加3個模塊后檢測器的精度分別提高了2.5%,2.6%和3.5%,模型大小增加了0.18 MB,推理速度雖有降低,但仍達(dá)到了實時檢測的要求。
由于TinaFace[18]是目前先進、強大而簡單的人臉檢測器,RetinaFace (MobileNet-0.25)[19]和輕量快速的人臉檢測器(light and fast face detector, LFFD)[20]在模型大小上和本文模型相近,性能比較更為直觀,因此將本文算法與上述3個算法進行對比,實驗結(jié)果見表3。從表3可看出,相比于RetinaFace (MobileNet-0.25)和LFFD,本文模型從精度和速度上均取得了更好的性能。與TinaFace相比,本文模型在hard子集的精度上相差較小,而在easy和medium子集上精度差距較大,但是本文模型采用的骨干網(wǎng)絡(luò)比TinaFace小得多,生成的模型也更小,在實際應(yīng)用中的可行性更強。實際檢測效果對比如圖6所示,能夠看出,雖然本文的檢測方法相比于TinaFace略有下降,但是和模型大小相似的RetinaFace和LFFD方法相比,本文的具有明顯優(yōu)勢。

表2 模型在WIDER FACE數(shù)據(jù)集上的AP性能、大小和推理速度
注:加粗?jǐn)?shù)據(jù)為最優(yōu)值;√為本模型使用的結(jié)構(gòu);-為本模型未使用的結(jié)構(gòu)

表3 不同模型的性能對比
注:加粗?jǐn)?shù)據(jù)為最優(yōu)值

圖6 本文方法與TinaFace,RetinaFace和LFFD檢測效果對比
雖然WIDER FACE數(shù)據(jù)集種類多、數(shù)量大,但在復(fù)雜光照條件下的圖像數(shù)量較少,訓(xùn)練得到的模型檢測性能較差,因此為了提高模型的魯棒性,本文建立了一個新的人臉檢測數(shù)據(jù)集。該數(shù)據(jù)集共18 907張圖像,包括WIDER FACE數(shù)據(jù)集訓(xùn)練集和驗證集共16 078張不同亮度的圖像,通過開發(fā)板攝像頭收集的1 337張亮度不均勻圖像,通過實驗室USB攝像頭收集的823張亮度不均勻圖像,以及從darkface數(shù)據(jù)集中篩選的178張低光照圖像,從UFDD(unconstrained face detection dataset)數(shù)據(jù)集的Illumination類別中篩選的491張光照變化劇烈的圖像。
表4分別在2個不同的數(shù)據(jù)集上進行訓(xùn)練,然后在本文建立的驗證集上進行測試的結(jié)果。實驗結(jié)果表明,用WIDER FACE數(shù)據(jù)集訓(xùn)練得到的模型對于光照的泛化性能較低,精度只有0.493,使用自建數(shù)據(jù)集訓(xùn)練的模型精度可以達(dá)到0.515,提升了2.2%。部分實驗結(jié)果如圖7所示,可以看出,在光照復(fù)雜情況下,根據(jù)本文建立的數(shù)據(jù)集所訓(xùn)練的模型對于人臉的檢測效果更好,但是對于亮度很弱的圖像,檢測精度的提高有限。

表4 不同的數(shù)據(jù)集訓(xùn)練后模型的檢測精度對比(%)
模型訓(xùn)練完成后,本文將其部署到嵌入式平臺上。由于該平臺不支持PyTorch模型,所以需要對其進行模型轉(zhuǎn)換。先將訓(xùn)練好的模型轉(zhuǎn)換為ONNX模型,再進行量化處理,最終轉(zhuǎn)換為開發(fā)板所需要的kmodel格式。攝像頭捕捉320×240分辨率的圖像之后,對其進行檢測處理,將其結(jié)果展示在有機發(fā)光顯示器(organic light emitting display,OLED)上,部分檢測結(jié)果如圖8所示。由于嵌入式平臺計算資源的局限性,本文算法在該平臺上能夠達(dá)到4 FPS。

圖7 對于光照不均勻圖像2個模型檢測效果對比((a)原模型;(b)使用擴充后的數(shù)據(jù)集訓(xùn)練的模型)

圖8 嵌入式開發(fā)板檢測人臉效果((a)人臉數(shù)量較少;(b)人臉數(shù)量較多但有序;(c)人臉數(shù)量多且無序)
3 結(jié)束語
本文提出了一種兼顧精度和速度的輕量級人臉檢測算法,并將其部署到嵌入式平臺中。在實現(xiàn)過程中,引入注意力模塊提升特征;采用Mish激活函數(shù)提高整體網(wǎng)絡(luò)的精確度和魯棒性;使用DIoU-NMS代替?zhèn)鹘y(tǒng)NMS對檢測框進行后處理,對小人臉的檢測更加精準(zhǔn)。實驗結(jié)果表明,本文方法在模型尺寸較小的情況下,能夠得到較高的精度和較短的延時,是邊緣器件的理想選擇。但是嵌入式平臺上的計算資源遠(yuǎn)少于筆記本電腦,因此網(wǎng)絡(luò)推理速度較慢,難以達(dá)到實時性,因此在之后的工作中,還需對檢測網(wǎng)絡(luò)作進一步的優(yōu)化。此外,通過在數(shù)據(jù)集中加入復(fù)雜光照下的人臉圖像,能夠提高模型對于復(fù)雜光照情況的泛化性,在后續(xù)工作中可以考慮構(gòu)造更加完備的復(fù)雜光照人臉數(shù)據(jù)集,考慮更加全面的光照情況。
[1] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[2] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 779-788.
[3] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6517-6525.
[4] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2018-08-08]. https://arxiv.org/abs/ 1804.02767.
[5] BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2020-08-23]. https:// arxiv.org/abs/2004.10934v1.
[6] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 21-37.
[7] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 2017: 318-327.
[8] LIN T Y, DOLLáR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[9] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993-13000.
[10] MISRA D. Mish: a self regularized non-monotonic neural activation function[EB/OL]. [2019-08-23]. https://arxiv.org/ abs/1908.08681.
[11] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[12] HOWARD A G, ZHU M L, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704. 04861.
[13] LIU S T, HUANG D, WANG Y H. Receptive field block net for accurate and fast object detection[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 404-419.
[14] WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7794-7803.
[15] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7132-7141.
[16] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128(2): 336-359.
[17] YANG S, LUO P, LOY C C, et al. WIDER FACE: a face detection benchmark[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 5525-5533.
[18] ZHU Y J, CAI H X, ZHANG S H, et al. TinaFace: strong but simple baseline for face detection[EB/OL]. [2020-11-26]. https://arxiv.org/abs/2011.13183.
[19] DENG J K, GUO J, ZHOU Y X, et al. RetinaFace: single-stage dense face localisation in the wild[EB/OL]. [2019-05-02]. https://arxiv.org/abs/1905.00641.
[20] HE Y H, XU D Z, WU L F, et al. LFFD: a light and fast face detector for edge devices[EB/OL]. [2019-08-24]. https://arxiv. org/abs/1904.10633.
Face detection and embedded implementation of lightweight network
ZHANG Ming1, ZHANG Fang-hui1, ZONG Jia-ping1, SONG Zhi2, CEN Yi-gang1, ZHANG Lin-na3
(1. School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China; 2. Shenzhen Bryture Co. Ltd., Shenzhen Guangdong 518000, China; 3. School of Mechanical Engineering, Guizhou University, Guiyang Guizhou 550025, China)
In recent years, face detection based on convolutional neural networks (CNN) has dominated this field, and the detection results on the public benchmark set have also been significantly improved. However, the computational cost and model complexity are on the rise. It remains a challenge to apply face detection model to embedded devices with limited computing power and memory capacity. Aiming at the application of face detection of 320×240 resolution input images in embedded systems, a low-resolution face detection algorithm based on lightweight network was proposed. The backbone network employed the attention module, combined Distance-IoU (DIoU) and Non-Maximum Suppression (NMS), and adopted the Mish activation function. Meanwhile, an appropriate a priori box was set for the face feature ratio. In doing so, the balance could be achieved between precision and speed, and it could be deployed to the embedded platform. Specifically, deep separable convolution was used to replace ordinary convolution, and an attention convolutional block attention module (CBAM) was added after the convolution block to keep the network’s focus on the target object to be recognized. Instead of the ReLU activation function, the Mish activation function was used to improve the model inference speed. By combining DIoU and NMS, the algorithm’s detection accuracy for small faces was enhanced. The results of experiments on the WIDER FACE dataset prove that the proposed method not only can detect human faces with high accuracy in real time, but also has higher accuracy than traditional algorithms in small resolution input. After expanding the dataset, the proposed model also improves the detection accuracy under complex illuminations.
face detection; lightweight network; attention module; activation function; non-maximum suppression
TP 751.1
10.11996/JG.j.2095-302X.2022020239
A
2095-302X(2022)02-0239-08
2021-07-01;
2021-10-29
中央高校基本科研業(yè)務(wù)費(2021YJS025);國家自然科學(xué)基金項目(62062021,61872034,62011530042);北京市自然科學(xué)基金項目(4202055);廣西自然科學(xué)基金資助(2018GXNSFBA281086)
張 明(1997–),女,碩士研究生。主要研究方向為目標(biāo)檢測、模型壓縮。E-mail:19120318@bjtu.edu.cn
張琳娜(1977–),女,副教授,碩士。主要研究方向為工業(yè)產(chǎn)品缺陷檢測、機器視覺等。E-mail:zln770808@163.com
1 July,2021;
29 October,2021
Fundamental Research Funds for the Central Universities (2021YJS025); National Natural Science Foundation of China under Grant (62062021, 61872034, 62011530042); Beijing Municipal Natural Science Foundation under Grant (4202055);Guangxi Natural Science Foundation under Grant (2018GXNSFBA281086)
ZHANG Ming (1997–), master student. Her main research interests cover object detection and model compression. E-mail:19120318@bjtu.edu.cn
ZHANG Lin-na (1977–), associate professor, master. Her main research interests cover industrial product defect detection, machine vision, etc. E-mail:zln770808@163.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環(huán)保(2016年3期)2017-01-20 08:15:32
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
