基于集成學習的相似數據表推薦*
2022-05-10 07:28:24王成澤彭艷兵
計算機與數字工程 2022年4期
關鍵詞:文本
王成澤 汪 洋 彭艷兵
(1.武漢郵電科學研究院 武漢 430070)(2.南京烽火天地通信科技有限公司 南京 210019)
1 引言
日常工作中我們所處理的數據表數量眾多,且數據表名及數據項標準并不統一,導致在尋找相似數據表時并不能簡單的以表名去判別兩張表的內容是否相似,這就對我們篩選出相似表造成了極大的困難。同時,相似表的篩選也是有意義的:一是對于相似的數據表我們可以合并,使數據表總量減少,并擴充已有的數據表內容;二是便于我們對于贅余的數據表進行廢棄,提高工作效率;三是推薦出相似表的同時,進行表中相似字段的推薦,便于數據對標使用。因此,本文希望可以引入表識別、字段推薦等模型實現半自動化處理,為相似數據表識別及推薦提供一些幫助。
集成學習[1](Ensemble Learning)是一種優化算法,將多個學習器用某種策略結合起來,使得整體的泛化性能得到大大提升。其潛在思想是即便一個弱分類器得到了錯誤的結果,其他弱分類器也可將錯誤糾正。總體來說,集成的泛化能力是遠好于單個學習器的泛化能力。
目前國內外關于集成學習算法的應用研究已有很多。扈曉君[2]等用基于選擇性集成學習完成支持向量機的分類;劉擎超[3]等基于集成學習研究交通狀態預報的方法;張有強[4]等基于選擇性集成學習研究離群點的檢測;喬楨[5]等對集成學習的多樣性進行系統研究;林堅鑫[6]等基于AdaBoost算法對雷達剩余雜波抑制進行研究。
本文針對數據表的特點,將其類比成文本進行分析,提出了利用多種文本相似度算法進行集成學習,對數據表中的表名和字段項分別進行相似度計算,最終加權得出算法置信度并推薦出相似的數據表。基于互聯網爬取的原始業務表與核心表數據進行試驗,驗證所提算法的有效性。
2 數據表推薦算法
2.1 數據表推薦算法思路
數據表分為表名和字段名,其重要程度也不盡相同,且都有中英文兩種形式,所以相似度計算分為四個部分:中文表名,中文字段名,英文表名,英文字段名。
本文提供以下幾種思路:可以訓練表格領域的詞向量,通過大量數據表數據的詞向量訓練,最終構建出一套較為完整的詞向量詞表,然后利用詞向量之間的余弦距離計算相似性,這樣可以包含文本中的語義信息,而不是僅僅考慮字符層面的相似;從神經網絡的角度入手,可使用孿生神經網絡衡量兩個輸入的相似度,以一對樣本及標簽作為輸入輸出來訓練模型,通過表的上下文解析出語義信息;將表格數據映射成文本,且表格數據中的表名和字段項均為短文本,可以從短文本相似度的角度去進行表格之間的相似度比較。
整體步驟如圖1所示。
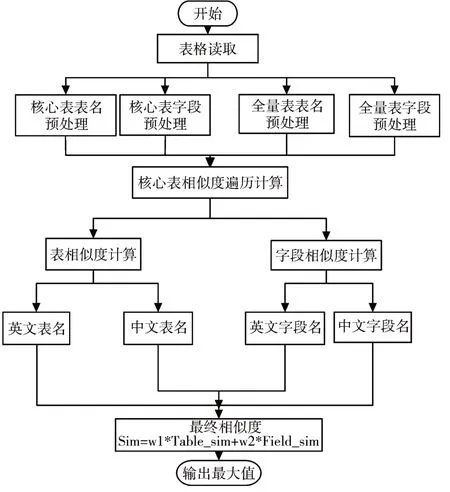
圖1 數據表推薦流程圖
2.2 相似度推薦算法
數據表同文本數據類似,每個表字段項可以看成是文本的一部分,但表不同于文本的地方在于其每個字段及表名的字符長度較短,屬于短文本范疇。下面簡要介紹本文所嘗試的相似度算法[7~11]及選擇標準。
文本相似度算法包括三類算法:一是基于關鍵詞匹配的傳統算法,如N-gram[12]相似度,Jaccard[13]系數,Simhash[14],Bm25等;二是將文本映射到向量空間,再利用余弦相似度等方法進行計算,如LDA[15],WMD[16]等;三是基于深度學習的方法進行訓練,如孿生神經網絡[17]等方法。
神經網絡雖性能強大,算法效果顯著,但是比傳統算法計算代價高昂,通常神經網絡模型參數極大,而且存在非線性操作,因此需要大量樣本且保持樣本的獨立性。然而本文所用數據并不復雜且互相之間存在關聯,樣本的數據量也不符合神經網絡的要求,難以得到良好的泛化性;利用詞向量進行比較,可以融入語義信息,效果好于直接利用短文本相似度方法比較,但數據量層面來看,無法滿足詞向量的訓練要求,所以在使用詞向量訓練時,在詞表中加入了之前涉及的其他地市的數據表以達到擴充數據量的要求。最終主要采用基于關鍵詞匹配的相關算法應用于實際的表識別場景,同時加入基于詞向量的WMD(詞搬移)方法進行詞向量層面的嘗試。
基于關鍵詞匹配的算法較多,但側重點卻并不相同,jaro,jaro-winkler[18]以及edit distance(編輯距離)都是度量字符間距離的算法,jaro強調字符間的距離限制,而jaro-winkler則強調字符的公共前綴更為重要;simhash強調的是大規模數據的相似度比較,其核心思想是降維;Lcs(最大公共子序列)強調字符串中公共字符的個數;N-garm則強調字符的切分粒度。基于向量模型的LDA(文檔主題生成模型)強調語義與主題層面的相似,假設每份文檔都使用多個主題混合生成,同樣每個主題也是由多個單詞混合生成,即根據文檔得到主題分布,再根據分布選出對應單詞;WMD基于word2vec得到embedding向量,在此向量空間中,語義相似的詞間的距離相對較小,通過歐式距離用距離來表示文檔間的相似度,這與上文所說的度量字符間距離的算法不盡相同。
上文介紹了多種短文本相似度算法,對于實際情況來說,準確率也有所差異。本文相似度算法的選擇主要基于兩方面去考慮:一是算法應用于數據時的準確度;二是算法運行速度。所以對于不同算法分別應用于數據表表名和數據項字段進行這兩方面的考量,選出較為理想的幾種算法,再進行加權集成,達到更高的準確度。
2.3 相似度計算
本文從兩個角度進行數據表的相似度計算,一是對表名的相似度計算,基于算法選擇的標準,選出合適算法,加權集成,同時由于表名的特殊性以及防止過大數據量造成內存的損耗,人為規定兩張數據表表名必須至少有一個相同文字才進行相似度的比較,通過一次篩選,減少比較的數據量;二是對表字段項進行計算,對于兩張表的字段項分別進行遍歷計算,找出兩張表中最相似的字段對應,并推薦出最為相似的兩張表。
算法的側重點不同,置信度并不統一,首先需要進行歸一化,再進行算法的調參。算法歸一化采取的Z-score標準化,使結果落到[0,1]區間,公式如下:

其中μ為樣本數據中算法置信度的均值,σ為其方差。
得到表名相似度和字段項相似度之后,加權后的數據表相似度計算公式如下:
其中Table_sim為表名的相似度算法置信度,Field_sim為表字短信的算法置信度,w1,w2分別為其權重。
3 實驗驗證
3.1 實驗數據集和實驗環境
本文驗證數據來自互聯網爬取的地市對標采集的全量表數據和根據標準制定的業務核心表。該數據包含中英文表名、中英文表字段名、相似字段對照等信息。通過采集并篩選出對標結果為核心表的全量表數據作為本次實驗的數據集。本文算法采用的是語言Python 3.6,在Windos系統下運行,計算機CPU為Intel Core i5-7500@3.4GHz,內存大小為8G。
3.2 實驗過程
3.2.1 數據預處理
本文數據選取的是互聯網爬取的各地市對標采集的共1600張業務數據全量表,以及150張業務應用廣泛的核心表,其中446張原始全量表經專家進行篩選后可對應在業務上應用廣泛的核心表;409張原始數據表有中英文表名,37張原始數據表僅有英文表名。
原始數據表的表名和字段名是包含通用字段的,例如旅館信息記錄表,我們所關注的是旅館,而信息記錄表這些字段對判斷相似沒有幫助,在進行表名的推薦時應去掉這些通用字段,通過我們對1600張原始數據表及核心表的人工預研,去掉字段如表1所示。
同時,對于數據表中的字段項我們也需要進行預處理,去掉其中無意義的字段,以提高之后算法推薦的準確度。同時由于字段項不同于數據表的表名,每張數據表的字段項較多,其形式也會更加多樣,還可能會出現一些符號,例如人員_數量,類似這種帶有特殊符號的字段項,預處理時需要考慮全面,首先去掉特殊符號,再進行通用字段的刪除。預研之后去掉的數據表通用字段項如表2所示。

表2 數據項通用字段刪除
這些字段與數據表的主體內容并不相關,可能會導致推薦時的偏差,這里我們的選取原則是對1600張數據表中的字段進行統計,選取出現次數Top20的字段進行人工判研,最后篩選出15個頻次出現較高的通用字段項進行刪除,以提高相似表的推薦精度。
3.2.2 確定最優參數與算法
上述介紹的算法各自側重點不同,本文在選擇合適算法時,先分別對數據表名和字段項相似度采用上述算法,對比專家預設結果,選出準確率較高且運行時間相對較短的算法作為集成學習的單個學習器。各算法在表名相似的準確率如表3、表4所示。

表3 數據表中文表名算法準確率
英文表名的比較效果準確度相對較低,原因在于各地市對標數據與核心表所提供的英文表名方式不一致。各地市的英文表名存在多種情況,如對應的中文表名首字母,拼音與英文混搭,甚至存在多張表英文名相同,僅通過編號區分的情況,而核心表統一為英文簡寫,所以算法的結果準確性偏低,本文不再考慮此維度。
算法在數據表字段項相似方面準確率如表4所示。
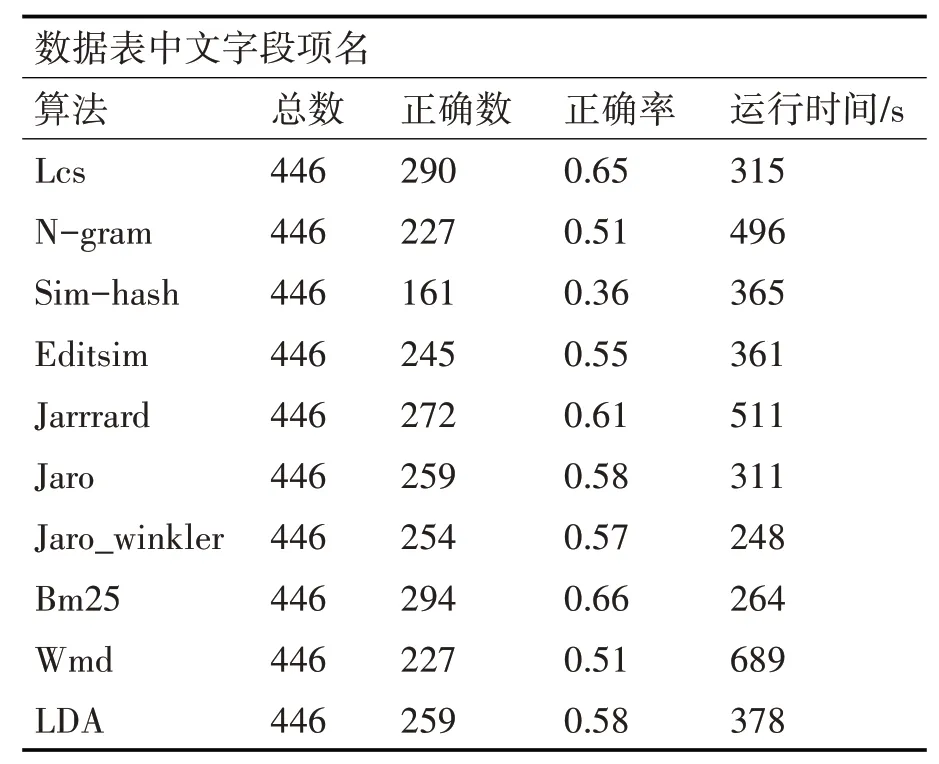
表4 數據表中文字段項名算法準確率
在英文字段項上的對比與表名類似,由于各字段英文表達方式的不同,表示同一字段的英文相去甚遠,導致算法的準確率并不理想,因此本文不對此方面進行過多考慮。
單個算法的數據表推薦效果一般,所以本文對于中文表名和字段項均采用效果較好的三個算法進行集成學習,若選擇算法過多反而會導致計算量龐大且效果并不明顯。參數優化采取了隨機搜索優化參數,即通過固定次數的迭代,采用隨機采樣分布的方式搜索合適的參數。其為每個參數定義了分布函數,并在該空間中進行采樣,本文次數設置為500,經500次迭代后,最終各算法的權重如表5所示。
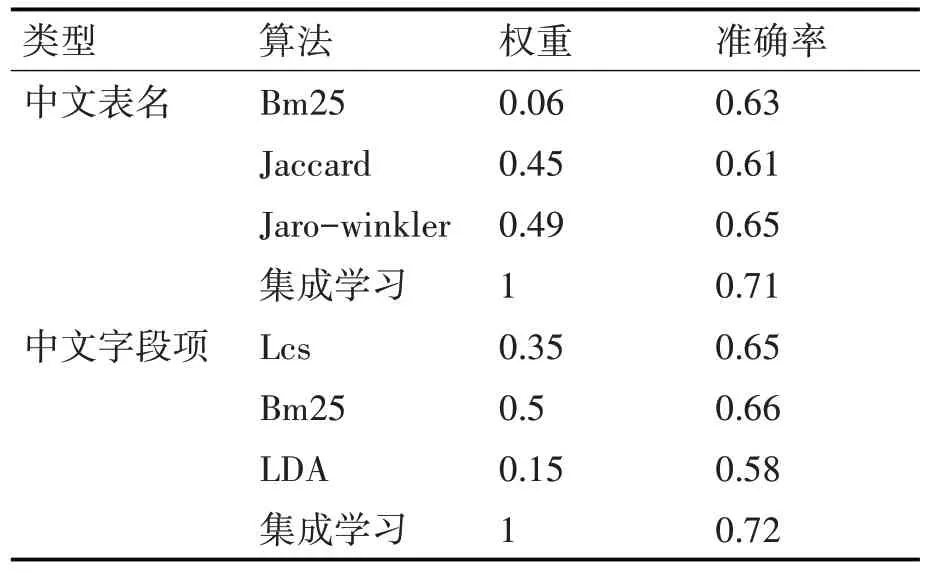
表5 各算法權重分布
3.3 實驗結果分析
中文表名和字段項分別經過集成學習后準確率均提高了6%左右,中文表名比較時總數為409張,因為提供的數據中有部分沒有中文表名,為了除去此影響,不將其納入中文表名的比較中。分別計算完表名和字段名的相似度,最后將兩個部分調參后的結果加權求和得到最終的表識別相似度,經過隨機采樣分布多次調試后,表識別準確率結果如表6所示。
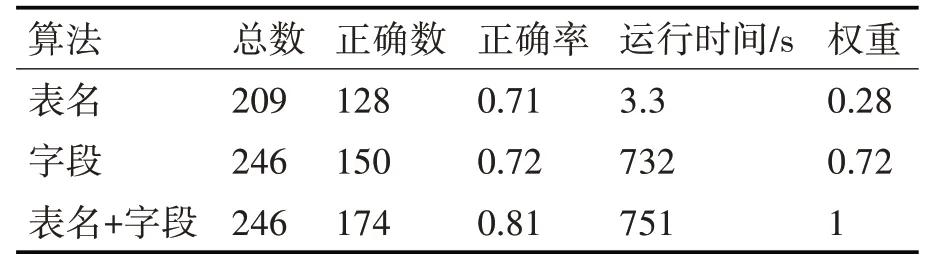
表6 集成學習算法權重分布
表名和字段名的權重設為0.28和0.72,其中對于無中文表名的數據表,僅利用字段進行判別。加權求和后,準確率上升了10%。
同時考慮到在進行數據表字段項識別時,我們已經通過相似度算法簡介推薦了核心表每個字段的最相似字段,按照此思路,優化表識別的功能,請相關人員標注了部分核心表中字段項的核心字段,通過核心字段,可以推薦出全量表與其相似的字段,便于我們分析該張全量表是否是業務需要的。
4 結語
本文提出了一種基于集成學習的相似數據表推薦算法。以采集的地市對標數據作為實驗數據來源,運用集成學習將多種短文本分類算法運用到相似度比較中,從表名和字段項兩方面對不同方法實驗后,選擇準確度較高且運行時間較短的方式,選取合適的權重,最終得到推薦的相似結果。對比有經驗的專家人工給定的對標結果,算法成功率達到81%。實際上,在相似度比較過程中,會遇到英文字段的表達方式不統一,數據表中部分字段缺失以及沒有中文表名等問題,給本文算法的判斷帶來了困難。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
