一種基于改進YOLOv5s的車道線檢測方法
2022-05-11 05:47:36舒小華楊明俊
湖南工業大學學報 2022年3期
韓 逸,舒小華,楊明俊
(湖南工業大學 軌道交通學院,湖南 株洲 412007)
0 引言
隨著城市交通的迅速發展以及圖像處理技術的逐漸成熟,應用在車輛上的輔助視覺功能被越來越廣泛地應用。智能駕駛逐漸成為當下的熱門技術與話題,其中圖像與視頻處理是其主要的研究對象。而在車輛對道路信息的收集中,車道線的信息收集尤為重要。它不僅可以為車輛導航提供參考,而且可以被應用于目標檢測和汽車預警等方面。在傳統算法方面,車道線檢測主要是提取圖像的邊緣信息,一般先用Canny算子或者Sobel算子對圖像進行邊緣檢測,然后用高斯算法或者最小二乘法進行擬合。而隨著機器學習的不斷發展,深度學習的方法也被應用到車道線檢測中。
目前,基于目標識別的深度學習方法主要分為兩種:一是two stage的R-CNN(region convolutional neural networks)系列,其框架精度較高,網絡結構較深,訓練時間較長;二是one stage的YOLO(you only look once)、SDD(system definition directive)系列[1],這種框架訓練速度快、結構簡單、檢測速度快,具有可實時檢測性[2]。YOLO系列至今已發展到YOLOv5系列。相較于之前的YOLOv3和YOLOv4系列,YOLOv5系列具有體積小、檢測速度快、檢測精度高等特點[3]。王灃[4]對YOLOv5框架進行了改進,增加了k-means++算法,對anchor先進行聚類,以提升檢測框的檢測率,并將GIoU(generalized intersection-over-union)損失函數改成CIoU(complete intersection-over-union)函數,改進后的框架對于安全帽的檢測率有所提高。林清平等[5]對于YOLOv5框架的改進方法體現在特征金字塔網絡(feature pyramid networkimage,FPN)結構上,其在FPN中增加了一個平衡系數,以增大小目標在相鄰特征層融合過程中保留的比例。崔文靚等[6]在YOLOv3框架上增加了k-means++算法進行先驗框計算,并用GPU(graphics processing unit)進行訓練和檢測,實驗結果表明該處理的檢測率提升了11%。楊曉玲等[7]在數據集方面進行了Mosaic增強,隨機選取訓練數據中的4張圖片,采用隨機縮放、隨機排布、隨機裁剪的方式進行拼接以豐富圖像數據,這種方法增加了數據的魯棒性,對于圖像中小物件對象的檢測率有所增加。Qu Z.等[8]將車道線的整體問題轉化成局部特征點與這個點關聯的特征點問題,并通過由粗到細的方法調整曲線,該方法可以嵌套到任意的深度學習網絡結構中。對車道線中心點進行高斯編碼,再用偏移量進行區域搜索,可擬合到其他特征點,連接這些特征點即可得到擬合曲線。周衛林等[9]基于GoogLeNet建立了一種端到端的車道線檢測網絡模型,先用YOLOv3框架對車道前方的障礙物進行識別檢測,再用長短期記憶網絡做決策,最后根據歷史編碼信息描繪車輛運動模式,結合當前狀態得到駕駛參數。
基于以上研究,為了提高車道線檢測的實時性與準確性,本研究在機器學習的框架下,提出了一種基于改進的YOLOv5s模型檢測算法。改進算法中,對于車道線的檢測,因為YOLO系列在神經網絡結構方面具有檢測速率較快、網絡架構較簡單、檢測精度較高等優點,故采用該系列的神經網絡進行實驗。又因YOLOv5是該系列中的新產品,在網絡結構上相較于前幾代具有創新性,檢測速率和準確率又有所提升,所以采用one stage的YOLOv5模型進行檢測。在回歸框損失函數方面,將其改進為EIOU(efficient input/output unit)損失函數;在數據處理方面,增加圖像預處理之后的二值化圖像參數進行參考,并且采用anchor-free,以提高先驗框的準確度。為了驗證改進算法的有效性,通過實驗,將得到的檢測結果與YOLOv5的檢測結果進行對比,發現改進算法的平均精度均值(mean average precision,mAP)增加了約11%,能夠實現較為準確的車道線檢測,并具有良好的魯棒性。
1 YOLOv5目標檢測算法
1.1 YOLOv5框架
YOLOv5分為S、M、L、X 4種模型,其中S模型網絡結構最為簡單,訓練和檢測速率最快;X模型網絡結構最為復雜,深度最深,但是檢測效果最佳。本研究采用L模型網絡結構進行訓練和檢測,在訓練速度和檢測效果兩者中折中取舍。相比于YOLOv3,YOLOv5的改進網絡結構如圖1所示。

圖1 YOLOv5改進網絡結構框圖Fig.1 YOLOv5 improved network architecture block diagram
圖1中,每個結構框層后面都連接著一個CBL(conv + BN + LeakyReLU)層,其作用是添加一個BN(batch normalization)層和一個激活函數,具有神經網絡的功能。 Backbone是YOLOv5的主體部分,其中Focus層是YOLOv3和YOLOv4兩者所不具備的,它的功能是進行切片操作,即將圖像切片后進行下采樣操作。雖然其步驟比其他下采樣算法復雜,但能保持信息較為完整。CSPNet(cross stage partial network)層進行局部跨層融合,通過每層的特征信息來獲得更加豐富的特征圖[10];Neck部分采用FPN+PAN(perceptual adversarial network)結構,FPN是自頂向下的,將高層的特征信息通過上采樣的方式進行傳遞融合,得到進行預測的特征圖。FPN主要應用了分治法(divide-and-conquer)解決目標檢測問題[11]。PAN是自底向上,將底層的特征信息通過下采樣方式進行傳遞融合。兩者相輔相成,從不同的主干層對不同的檢測層進行特征聚合;在錨框擬合方面,YOLOv5采用GIoU損失函數,現將其改為EIOU函數,相較而言,EIOU將目標框的寬和高分別進行處理,回歸速度更快、效果更好。
1.2 YOLOv5數據增強
YOLOv5在數據增強方面采用的是Mosaic(馬賽克)增強,即將數據集中的3張或4張圖片通過旋轉、翻轉、平移等一系列圖像變換操作后,融合成一張新的圖像,新圖像中的目標作為一副新的圖像數據與原數據集一起進行訓練,達到擴大數據集的效果,增強對目標物體的識別能力。
這種方法是由YOLOv4首先提出來的,現已被很好地運用于YOLOv5中。Mosaic算法將原數據集的圖片進行融合,相當于變相地增加了batch_size,這樣在訓練過程中能減少顯存的消耗,讓顯存不是很大的GPU也能進行訓練。
2 算法改進
2.1 圖像數據
一般的車道線檢測數據集大多是對彩色圖像信息的采集,而在數據信息復雜度較高且對應圖像數量較少的情況下,訓練效果不明顯,會導致檢測時產生漏檢或者誤檢的現象。針對這一問題,本研究提出加入黑白圖像信息通道,將彩色圖像對應的預處理后的二值化圖像一起加入數據集中進行訓練,以提高檢測準確率。
2.2 損失函數
YOLOv5采用的損失函數為GIoU函數,GIoU函數是交并比(intersection-over-union,IoU)函數[12]的改進版。IoU函數用于計算預測檢測框和真實檢測框的相交占比,可以反映兩個框的檢測效果,其表達式為

式中:A為預測檢測框;
B為真實檢測框。
IoU函數存在的問題是,當A和B兩個框并沒有相交時,即A∩B=0時,則IoU不能體現兩者之間的距離,且loss=0無法回歸,無法進行訓練。為了解決這一問題,提出了GIoU函數,其先計算兩個框的最小閉包區域面積Ac,再計算出IoU;然后計算閉包區域中不屬于兩個框的區域占閉包區域的比例;最后,用IoU減去計算所得比例值得到GIoU,具體的計算公式如下:

式中U為兩個框的重疊區域。
當兩個框完全相交時,GIoU=1;而兩個框不相交時,距離越遠,GIoU越接近-1。它的缺點是在兩者出現圖2情況時,GIoU會退化成IoU,無法體現出兩者的相對位置。
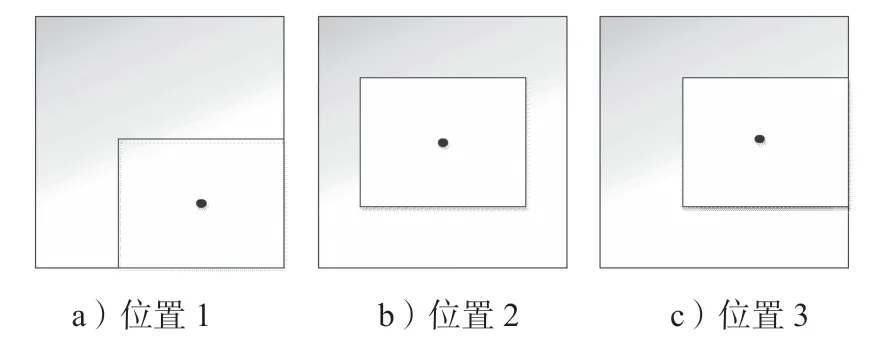
圖2 預測框與真實框位置關系示意圖Fig.2 Position relationship between prediction frame and real frame
為了解決這個問題,提出了DIoU損失函數,其表達式如下:

式中:b、bgt分別為預測框和真實框的中心點位置;
p為兩點之間的歐氏距離;
c為能包含兩個框的最小閉包區域的對角線距離。
引入損失函數后,不僅能反映兩者完全包含情況下的位置距離,并且DIoU可以直接最小化兩個框的距離,比GIoU的收斂速度更快。
CIoU則是在DIoU的基礎上,考慮了Bounding box的縱橫比,因而進一步提升了其回歸精度,CIoU的表達式如下:

式中:α為trade-off參數,其計算式為

v是用來衡量長寬比一致的參數,其計算式為

其中,w和h分別為錨框的寬和高。
CIoU loss的梯度在寬高比屬于[0, 1]區間內時會爆炸,因為w2+h2的值會很小,所以令這個值等于1即可[13]。CIoU考慮的東西最全面,相較而言是目前比較好的一種損失函數[14]。
而EIOU[15]則是在CIoU的基礎上,將縱橫比因子拆開分別計算目標框的長和寬,其計算式如下:

式中:Cw、Ch分別為覆蓋兩個BOX的最小外界框的寬度和高度。
圖3是GIoU和EIOU在同一數據集訓練下的收斂效果圖。

圖3 GIoU與EIOU的收斂效果圖Fig.3 Convergence effect diagrams of GIoU and EIOU
圖3中橫坐標為訓練輪數,縱坐標為損失(loss)。由圖可以得知,EIOU的收斂效果比GIoU的收斂效果更好。
2.3 錨框機制
在YOLOv5s中,對于anchor先驗框的計算,是通過k-means聚類方法進行的。人工標注之后的檢測框通過k-means聚類得到先驗框,將其與真實框進行對比、更新等一系列操作后,得到新的數據框。這一操作太過復雜,計算量較大,在車道線的標注上體現得不是很好。根據這一問題,提出anchor-free的錨框算法。
現有錨框機制主要有anchor-based和anchor-free兩種。YOLOv3、YOLOv5系列都是用anchor-based直接在特征圖上對錨框進行回歸和預測,這樣能避免重復的卷積運算,加快檢測速率。但是會降低檢測精確度,對于小物體目標的檢測效果不顯著。
anchor-free檢測器以兩種不同的方式檢測物體,一種是首先定位到多個預定義或自學習的關鍵點,然后約束物體的空間范圍,稱為Keypoint-based方法;另一種是利用中心點或中心目標區域來定義正樣本,然后預測其到目標4個邊的距離,稱為Center-based方法。這種方法能讓檢測流程進一步精簡,減少許多超參數的存在,提高系統的泛化能力。
根據車道線在目標檢測中的錨框標定,采用Center-based方法進行檢測。將圖像分為S×S個網格,只要車道線的中心點落在網格內,則用這個網格負責本車道線的檢測。通過計算中心點到網格4個端點的距離來進行檢測和錨定[16]。
2.4 數據增強算法
在1.2中介紹過Mosaic的數據增強算法,其優點是能夠增強神經網絡對目標的學習能力,而且能讓機器不太依賴batch_size的大小,讓顯存小的GPU也能很好地進行訓練。該方法仍然是在數據集上進行工作。
而mixup數據增強,則是一種與數據無關,更為簡單的數據增強算法[17],相較Mosaic算法而言,其計算量更小、操作更簡單。其操作如下:在樣本中隨機抽取兩個樣本,讀取它們的樣本標簽數據,進行融合計算后得到一個新的樣本標簽數據,再將該數據加入樣本中進行訓練。mixup數據增強的計算公式如下:

式中:λ為權重,根據α與β兩個超參數的貝塔分布計算獲得;
x1、x2分別為兩個圖像樣本;
y1、y2分別為對應的兩個樣本標簽。
這樣,就獲得了一個新的圖像樣本和一個新的標簽數據。根據文獻[17]中的實驗數據,α和β的超參數無論怎么設置,其期望都不會超過0.5,這可能是因為權重在訓練過程中期望近似0.5,所以將α和β都設置為0.5時,效果會比較好。
為了能保證GPU訓練最大化,并豐富數據特征,本研究采用Mosaic和mixup算法相結合的方式,一起進行數據增強。
3 實驗及結果分析
3.1 實驗流程
1)從Tusimple數據集中挑選3 000張公路圖像,這些圖像具有一定的標志性(如不同的天氣狀況、不同的道路信息狀況等),然后用labelimg軟件進行標注,生成xml文件。
2)將這3 000張公路圖像轉換為二值化圖像,并進行標注,生成label文件,然后與原圖像和原標簽文件匯總成新的數據集。
3)將YOLOv5s中的autoanchor改為center_based算法,將GIoU算法改為CIoU算法,并加入mixup算法,與Mosaic一起進行數據增強。
4)設置對應的超參數,以及訓練代碼中的batch_ size大小,然后輸入圖像大小,進行訓練。
5)保存訓練后的結果權重文件,并進行檢測實驗,得出結果。
3.2 實驗數據準備
實驗的數據集采用Tusimple數據集中的3 000張隨機圖像,將其壓縮為320*180的圖像,這樣的圖像訓練完成后,能在實際應用中增加識別小目標的準確度。在labelimg軟件中對每一張圖像的車道線信息進行標注,然后將每張圖像進行圖像預處理后的二值化圖像加入數據集中,增加參考量。
Tusimple數據集如圖4所示,a圖為天氣良好的情況,b圖為光照條件不好的情況。由圖可知,不同場景結合下的訓練效果魯棒性較好。


圖4 Tusimple數據集Fig.4 Tusimple data set
3.3 實驗平臺及參數設置
實驗在CPU為Intel(R) Core(TM) i5-9300H CPU@ 2.40 GHz,GPU為NVIDIA GeForce GTX 1650,CUDA為11.0版,Cudnn為8.0版的配置上完成,并使用pytorch軟件,調用opencv庫,搭建TensorFlow框架,完成實驗。
設置的訓練參數如表1所示。

表1 訓練參數設置Table 1 Training parameter setting
3.4 實驗結果分析
下面主要對于上文論述的相關內容進行消融實驗,表2是加入二值化圖像前后的對比實驗結果。

表2 不同圖像數據處理方式的實驗結果對比Table 2 Image data processing comparison %
由表2中的數據可知,加入二值化圖像數據后,mAP數值上升了2.8%,但準確率基本保持不變,說明加入二值化圖像對于車道線信息的識別準確率具有一定的提升效果。
表3是選用YOLOv5s時,采用不同損失函數的檢測結果。

表3 不同損失函數下的檢測結果對比Table 3 Comparison of detection results under different loss functions
由表3中的數據可以得知,EIOU的檢測效果更好,且收斂效果也比GIoU的效果更加顯著。
表4為對YOLOv5s修改錨框機制前后的mAP與準確率檢測結果對比。

表4 不同神經網絡下的檢測效果對比Table 4 Comparison of detection effects under different neural networks %
由表4可知,將anchor-based改為anchor-free后,對車道線的檢測mAP與準確率均約提高了1%,且不用進行k-means聚類預選錨框,節省了實驗步驟。
表5給出在YOLOv5s增加了mixup增強算法前后的mAP檢測結果。

表5 增加混合增強算法前后的檢測結果對比表Table 5 Comparison table of hybrid enhancement algorithms %
由表5 可知,當在YOLOv5s中加入了mixup后,進一步對數據集進行了數據增強,因此數據集的mAP和準確率都得到了提升。
最終的實驗結果測試標準采用mAP因子,并參考召回率和準確率,三者結合進行分析。本實驗分別用YOLOv3[17]、YOLOv5s以及改進方法進行對比實驗。在實驗之前,由于YOLOv5s的深度和寬度是YOLOv3的1/3,所以,為了確保實驗的準確性,將YOLOv3的深度和寬度修改為與YOLOv5s一樣。得到的訓練效果圖見圖5,其中a圖為YOLOv3的訓練結果,b圖為YOLOv5s的訓練結果,c圖為改進算法的訓練結果。從圖5中可以看出,YOLOv3的整體檢測率較低,且存在較多的誤檢情況,改進之后的方法相較于YOLOv5整體上的檢測率有所提高,錨框機制也有所改進。


圖5 不同算法的實驗效果對比圖Fig.5 Comparison of experimental results of different algorithms
SSD(single shot detection)因其網絡結構簡單,檢測速率快,也經常被用來識別目標,故加入一組SSD+VGG(Visual Geometry Group)16的對照實驗,不同算法的實驗結果數據見表6。

表6 不同算法的實驗結果數據對比表Table 6 Comparison table of experimental results %
由表6中的數據可以得知,對比YOLOv3,YOLOv5s在速度和準確率上均有大幅度提升;在改進了損失函數以及加入了二值化通道后,相較而言,約增加了6%的準確率。
由表6還可以得出,相較其他方法,改進方法在準確率和mAP上都有明顯提升,召回率也有所提升,改進之后的模型檢測效果明顯提升。且相較于SSD+VGG16的網絡結構,YOLO系列在檢測精度上都大大提升。
表7給出了YOLOv3、YOLOv5s與改進后的YOLOv5s訓練后的模型大小,以及檢測速率的結果對比。

表7 YOLOv系列網絡的模型性能對比Table 7 Model performance comparison of series YOLOv networks
結合表6和表7可以得出,對YOLOv5s進行改進之后,訓練后得到的模型大小與原來相比是一樣的,雖然檢測速率下降了一些,但仍在可接受范圍內。在僅犧牲約0.05%的檢測速率后,得到了比較明顯的準確率提升,并且mAP提高了近11%,準確率提高了13%,可見改進方法模型更加適用于車道線的檢測。
4 結語
在目前的深度學習算法中,YOLO系列由于其結構簡單、訓練速度快等特點,能夠實時完成一些視頻流的檢測,具有較好的魯棒性與實時性。其最新的YOLOv5大大增加了檢測速率和準確率,使用起來十分方便。通過對YOLOv5s和YOLOv3的比較,在車道線檢測方面,YOLOv5s的提升效果十分明顯,不僅訓練速度約是YOLOv3的3倍,準確度也得到了明顯的提升。目前傳統的模型縮放方法是改變模型深度,即增加更多的卷積層[19],所以在增加準確度的同時,訓練速度也會有所減緩。因此結合二者的特性進行改進,并選擇了YOLOv5s模型進行訓練。同時采用了EIOU損失函數,以加快其收斂速度,提高檢測準確性。在數據準備階段,采用了anchor-free,使錨框更加符合車道線的錨定框。增加了二值化通道,以提高道路信息不太明確時的檢測準確度。改進方法相比YOLOv5s原模型而言,其準確率約提升了13%,mAP值提升了11%左右,且達到了80%以上的準確率。
由于本研究使用的是Tusimple數據集,道路信息大多十分明顯,所以在車道線信息冗雜、缺失的情況下,還需要進一步研究改進后的檢測效率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
