基于OpenCV 和Tesseract-OCR 的表帶字符識別算法研究
2022-05-16 10:17:18徐陽
科海故事博覽 2022年13期
徐 陽
(安徽理工大學,安徽 淮南 232000)
1 研究背景及理論基礎
當下智能穿戴在人群中非常流行,專屬化以及個性化的服務讓人們有著滿滿的時尚感、科技感。人們在追求高品質生活的同時,對穿戴樣式及美觀需求更高,作為可更換的配件手表表帶,除了對材質要求外,對圖案樣貌以及一些專屬字符等也有需求。在生產車間里,用傳統方式面對字符檢測,耗時、耗力、效率低。所以為了更加簡潔快速地識別表帶字符,剔除劣質品,快速找到合格品[1],本文著重研究基于OpenCV和Tesseract-OCR 的表帶字符識別算法的實現。
OpenCV 創建之初,是為了提供來源優化過的基礎代碼,可以實現許多圖像處理的基礎算法,具有更強的可讀性、移植性且免費,支持C++,Python 等語言。二十世紀八十年代初開發的一個開源OCR 引擎在測試中精準度很高,經過不斷地改進后,結合Python 語言逐漸發展為Pytesseract 的模塊。它支持PIL 庫中各式各樣的圖片文件,也可以靈活地處理OpenCV 圖像,和NumPy 數組相互轉化,同時為了提高圖像轉對文本的處理能力,可以訓練自己的庫[2-3]。
2 表帶字符識別流程
本文將采集到的表帶圖像進行預處理,包括圖像灰度化、二值化,再進行定位,包括尋找字符輪廓、繪制輪廓等操作,將所需檢測部分進行截取,最后OCR 字符識別輸出結果。
1.獲取圖像。
2.預處理。
3.字符定位。
4.字符圖像提取。
5.OCR 字符識別。
3 表帶圖像預處理
3.1 圖像顏色空間轉換
在顏色空間轉換中,灰度圖像經過轉換后,彩色圖像中的所有通道都相同,其中CV_8U 類型圖像范圍在0 到255 之間,CV_16U 類型圖像范圍在0 到6535之間,CV_32F 類型圖像范圍在0 到1 之間。與之相反,彩色圖像轉換為灰色圖像,就要使用加權公式,如下:
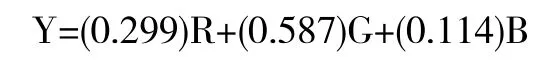
其中,R 代表彩色圖像中紅色部分(Red)的像素值,G 代表彩色圖像中綠色部分(Green)的像素值,B則代表彩色圖像中藍色部分(Blue)的像素值,加權的最終結果Y 代表灰度的像素值。
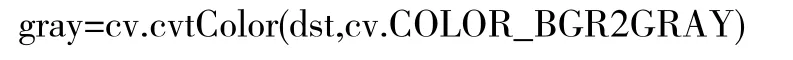
其中gray 代表處理之后圖像,COLOR_BGR2GRAY代表BGR 格式圖像轉化為GRAY 格式圖像。以下是得到的灰度圖像(見圖1):

圖1 字符灰度圖像
3.2 高斯濾波降噪
我們經常使用的圖像濾波算法包括:中值濾波、均值濾波、高斯濾波。中值濾波特點是計算模板內所有像素的中值,然后用計算出來的值分別代替該像素點的灰度值,這種方法能很好地保護邊緣信息,但是花費時間較長。均值濾波的特點是計算模板內所有像素的平均值,然后用計算出來的值分別代替該像素點的灰度值,對于目標圖像只能相對減弱噪聲,無法克服邊緣像素信息丟失部分。結合前兩種方法不同的優缺點,本文采用高斯濾波的方法去除噪聲,因為它對圖像鄰域內像素進行平滑時,不同位置的鄰域像素有著不同的權值,能夠更多地保留圖像總體灰度分布特征。一維零均值高斯函數:
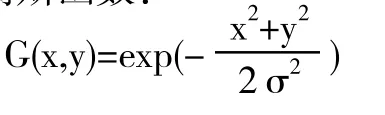
其中x2和y2分別表示的是鄰域內其他像素與鄰域內中心像素的距離,σ是標準差。σ值越大,函數圖形越寬,圖形越平坦,類似于平均模板。
σ值越小,分布越集中,圖形寬度越窄。
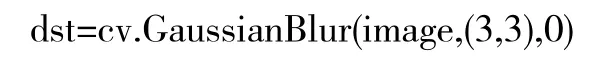
表帶圖像經過高斯濾波降噪處理后,如圖2 所示:

圖2 高斯濾波處理后
4 表帶字符定位
為了使圖像定位更加準確,首先需要將圖像的輪廓清晰地表現出來,可以選用閾值分割法或者邊緣檢測的方法。
4.1 閾值分割法
簡單的圖像分割方法可以利用閾值來處理,圖像閾值化適用于背景和目標占據不同灰度級范圍的圖像,因為它計算量小,性能穩定,成為最廣泛的圖像分割技術。我們可以給出一個數組以及一個閾值,然后根據每個數組中的值與閾值進行比對,不管是高了還是低了分別進行相應的處理。給定原始圖像f(x,y),T 為閾值,則g(x,y)滿足下式:
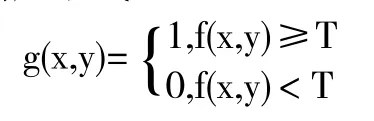
使用全局閾值方法進行閾值圖像處理:
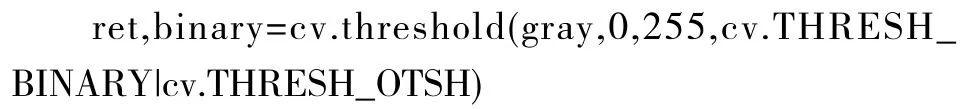
其中閾值類型THRESH_BINARY 中,可以將超過閾值部分取最大值,反之取0。THRESH_OSTH 遍歷所有可能的閾值,然后對每個閾值結果的兩類像素計算方差。OTSU 算法計算方差使下列表達式最小:
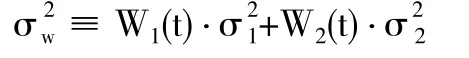
其中的W1(t)和W2(t)是根據兩種類型像素的數量計算的權重,表示兩類像素的方差。圖3 是經過全局閾值處理后的表帶圖像:

圖3 閾值化后的圖像
4.2 邊緣檢測
這些輪廓是通過將滯后閾值應用于像素而形成的,并且采用了兩個閾值。兩個閾值中分為較大的數值a和較小的數值b,像素的梯度被計算出后大于a 就接受,反之小于b 則舍棄,但如果介于a 與b 之間,那么接受它的方式只有它連接到一個高于閾值的像素時[4-5]。Canny 內部調用Sobel 算子,不但用了高斯平滑還有微分導數,來計算該圖像灰度函數的近似梯度[6]。
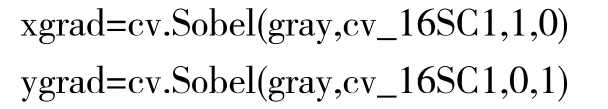
得到x 和y 方向的梯度后,對圖像進行Canny(xgrad,ygrad,50,150)操作后得到圖像(見圖4):

圖4 邊緣檢測后的圖像
4.3 兩種定位方法的比較
閾值分割是用于強調圖像中感興趣的部分的方法,經過二值化處理后,顯示出該目標的灰度值,強調主體本身具有灰度特性,使用閾值分割來表現。與之相似的,邊緣檢測重點在于利用算法表現邊緣的灰度特性,常用于發現物體的邊緣,特征更加明顯,方便后續操作[7-8]。
5 表帶字符圖像提取
將表帶中需要提取的部分定位好后,準備進行字符圖像提取,需要尋找輪廓并繪制輪廓:

其中cv.RETR_EXTERNAL 表示只檢測最外層的輪廓,cv.CHAIN_APPROX_SIMPLE 表示水平、垂直、對角線方向的元素被壓縮,只保留該方向的最終坐標位置。表帶字符的矩形外框只需4 個點來保存輪廓信息。執行結束后得到的圖像為(見圖5):

圖5 字符 圖像提取
6 表帶字符識別
6.1 預處理
由于使用Tesseract-OCR 有字符識別方面的要求,所以在字符背景和像素方面要進行一些處理。首先進行圖像預處理,去除干擾線與點,防止識別過程中出現錯誤[9]。
開操作是先腐蝕后膨脹的過程,它相當于一個幾何運算的濾波器[10]。

作為形態學中核心的API 函數morphologyEx(),cv.M ORPH_OPEN 可以代表開運算,kernel 是其中的內核,可以通過cv.getStructuringElement(cv.MORPH_RECT,(3,3))返回具有特定形狀和大小的結構元素。得到開操作后的圖像為(見圖6):

圖6 開操作后的圖像
6.2 Tesseract-OCR 字符識別
Tesseract 是一種開源OCR(光學字符識別),可以識別不同格式的圖像文件并將其轉換為文本。首先我們需要下載windows 下相應的安裝文件,Pytesseract是由Python 封裝,支持PIL 圖像或者NumPy 圖像,使用Image.fromarray(open_out)函數實現數組array 到image的轉換,使用OCR 模塊的API 的方法:

最后以字符串的形式返回結果(見圖7):

圖7 識別結果
7 結語
本文利用一些傳統的Opencv 圖像處理方式和目前較為流行的OCR 方法,主要是使用Python 語言,對表帶識別進行了初步的研究。對于一些簡單的圖像,處理迅速、識別準確。但是關于如何應對復雜場景下的字符識別、能否進行算法的擴充以達到提高識別準確率的效果,還需要更進一步的分析研究。
