基于社交媒體中文本信息的早期抑郁癥檢測
2022-05-18 07:23:40張夢娜王君巖張浩峰
中國生物醫學工程學報 2022年1期
張夢娜 王君巖 龍 洋 張浩峰 胡 勇
1(南京理工大學醫院預防保健科,南京 210094)
2(新南威爾士大學計算機科學與工程學院,悉尼 2052)
3(杜倫大學計算機科學系,杜倫DH1 3LE)
4(南京理工大學計算機科學與工程學院,南京 210094)
引言
抑郁癥是一種嚴重的情緒障礙,會影響患者的身心健康[1-2]。它通常包括長時間的強烈悲傷感,以及無助、絕望和毫無價值的感覺。抑郁癥不僅會導致對活動、疲勞和睡眠問題失去興趣,還會影響患者的感覺和思維方式。根據世界衛生組織的數據,各個年齡階段的總計超過3 億人都患有抑郁癥,這是年輕人自殺的主要原因[3-4]。在英國,據報道1/4 的人患有抑郁癥[5]。因此,抑郁癥被認為是全球范圍內主要的精神健康疾病。在臨床診斷中,心理醫生通過面對面的訪談,并將他們的評估結果與《精神疾病診斷和統計手冊》 (Diagnostic and Statistical Manual of Mental Disorders,DSM)中概述的9 種抑郁癥狀相對照,以診斷患有抑郁癥的患者[6]。如今,這種方式已被臨床醫生、研究人員和相關機構廣泛使用。DSM 的最新版本是第5 版,于2015年5月18日發布;它定義了9 種抑郁癥狀,并描述了日常生活中有助于診斷的獨特行為。根據這些癥狀和情況,臨床醫生進行評估并診斷出抑郁癥。通常,癥狀可概括為情緒低落和快感不足。在嚴重的情況下,患者可能會出現妄想,但較少出現精神病(如幻覺)等癥狀[7-8]。在典型情況下,癥狀包括記憶力差、易怒甚至有自殺念頭。通常,根據患者的情況和癥狀,由受過訓練的臨床醫生對患者進行診斷評估。但是,由于感到羞恥或不了解抑郁癥,抑郁癥患者通常不愿與心理學家會面來尋求幫助。因此,有必要尋找一種非直接接觸式的自動化檢測方法。
當前自動化抑郁癥的檢測方法主要是使用語音或者視頻特征來實現。Gratch 等[9]構建了一個苦惱分析訪談語料庫(Distress Analysis Interview Corpus,DAIC),包含臨床訪談,旨在幫助診斷焦慮、抑郁和創傷后應激障礙等心理困擾的狀況。該訪談由人類、人類控制的個體和自主的個體進行,參與者包括抑郁個體和非抑郁個體。收集的數據包括錄音和錄像以及廣泛的問卷調查,語料庫的一部分被轉錄和注釋為各種語言和非語言特征。該語料庫已被用來支持自動面試代理的創建,并用于心理困擾的自動識別。由于語音成為與抑郁癥患者的最主要交流方法,因此Srimadhur 等[10]利用了基于光譜程序的卷積神經網絡,對語音信號進行處理,并獲得了60%左右的準確率。考慮到樣本不平衡問題,Ma 等[11]提出了一種深層模型,即DeepAudioNet,用于編碼聲道中與抑郁癥相關的特征,將卷積神經網絡(convolutional neural networks,CNN)和長短時記憶(long-short term memory,LSTM)相結合,以提供更全面的音頻表示。此外,由于監督的樣本較少,Zhao 等[12]提出了一種新的交叉任務方法,將注意力機制從語音識別轉移到抑郁癥嚴重程度的測量,這種轉移被應用在一個反映語音自然層次結構的兩級層次網絡中。Vázquez-Romero 等[13]在預處理階段,將語音文件表示為一系列對數譜圖,并隨機采樣以平衡正、負采樣,然后再采用卷積神經網絡進行處理。Negi 等[14]利用一個人聲音的韻律特征(音高、音調、節奏),建立了一個檢測他是否患有抑郁癥的模型。然而,視頻也可以部分地反映出患者的一些狀況,因此Melo 等[15]利用基于視頻的方法實現抑郁癥的檢測;該方法根據被試的面部表情,提出了一種通過分布學習來精確預測抑郁水平的深度學習結構;該結構能夠利用數據分布,探索面部圖像和抑郁水平之間的順序關系,并且對噪聲和不確定的標記具有魯棒性。考慮到不同模態會含有更多的有用信息,Yang 等[16-17]使用語音、視頻和文本混合的方法,認為基于文本的內容特征對于分析抑郁癥相關的文本指標也很重要;此外,為了提高抑郁癥自動評估系統的性能,還需要強大的模型,能夠模擬嵌入音頻、視頻和文本描述符中的抑郁癥特征,因此提出了新的文本和視頻特征,并從音頻、視頻和文本的描述符中混合了用于抑郁估計和分類的深度和淺層模型。另外,Qureshi 等[18]也利用聲學,文本和視覺模式,提出了一個新的基于多任務學習注意的深度神經網絡模型,它有助于多種模式的融合。特別地,使用這個網絡來回歸和分類抑郁癥的水平。然而,這些方法都需要面對面地采集受訪者的音頻、視頻以及文本信息,但面對面的采集通常會被患者所排斥,且標注的準確性也會受到影響。
在現代社會中,社交媒體的使用已在人們的日常生活中變得越來越不可或缺。人們越來越多地在Twitter、Facebook 以及微博等社交媒體上分享自己的感受和情感。如今,社交媒體不僅可以反映個人的日常生活,還可以反映他們的心理活動和健康狀況,包括抑郁癥患者在內的越來越多的人傾向于在微博等社交媒體平臺上分享自己的感受和情感。因此,研究人員已開始分析社交媒體上抑郁用戶的在線行為。例如,Park 等[19]提供的證據證明,社交媒體可以提供有意義的數據,用以捕捉用戶的沮喪情緒。在后續的工作中,他們與抑郁和非抑郁的用戶進行了面對面的采訪,發現非抑郁的用戶將Twitter 視為信息消費和共享的工具,而抑郁的用戶將Twitter 視為情感互動和社會意識的工具。先前的研究表明,可以通過社交媒體發現抑郁癥。因此,Choudhury 等[20]確定社交媒體具有檢測和診斷抑郁癥的潛力。Shen 等[21]收集了基于Twitter 數據的大規模數據集,并分析了抑郁和不抑郁的Twitter用戶之間的在線行為有何不同。這樣的研究帶來了分析社交媒體作為檢測抑郁用戶的手段的可能性。但是,現有的工作仍存在一些局限性:一是很少有工作分析社交媒體上的時間序列信息。大多數研究關注用戶的社交網絡信息,而每個用戶在不同社交媒體平臺上的活動各不相同,無法通過檢查一天的活動來檢測抑郁,所以應該有一個研究來更仔細地調查過去的信息。因此,可以肯定的是,時間序列信息對于抑郁癥的檢測很重要。二是很少有使用社交媒體(如Twitter)的抑郁癥檢測應用程序使用機器學習,同樣很少有應用研究抑郁癥的新出現癥狀。因此,有必要開發一種使用機器學習來分析抑郁癥狀的方法。
正是基于這樣的基礎,使采用機器學習方法、通過社交媒體數據發現抑郁癥成為可能。最近,機器學習已通過社交媒體用于抑郁癥的檢測工作中。但是,鑒于數據樣本的不平衡,并且大多數情況下來自非抑郁者,因此開展此類工作存在一些挑戰。此外,尚未有分析此問題中時序信息的工作。考慮到抑郁癥狀不會立即出現,早期的文本信息有助于判斷抑郁癥的傾向,這使得時序信息更加重要。針對這一問題,本研究提出一種非監督LSTM 多示例學習模型,通過提取一種新的文本數據特征,可以嵌入來自推文的時間序列信息。具體來說,使用無監督的LSTM 提取函數,可以提取包括來自先前推文消息的特征。此外,本研究還利用多示例學習進行分類,進而檢測抑郁與否;以通過時間序列特征為樣本,通過訓練分類器,實現每一條推文的分類;采用閾值方法,最終實現用戶是否存在抑郁癥的檢測。本研究所提出的方法根據時間序列信息,更好地利用了調查對象的病態發展信息,提升了檢測的準確率。
1 材料和方法
1.1 數據收集
為了通過Twitter 進行抑郁癥檢測,采用兩個標簽齊全的抑郁癥和非抑郁癥Twitter 用戶數據集MDDL,這些數據集已在線發布[21]。在此基礎上,采用基于啟發式規則的方法,從Twitter 成熟的API 構建兩個標記良好的抑郁和非抑郁數據集,具體的情況如表1所示。數據集的統計量可以總結如下:

表1 所用數據集簡介Tab.1 Summary of the employed dataset
1)抑郁數據集。基于2009—2016年之間的推文收集了抑郁癥數據集,從中篩選出100 個調查對象,選擇發布了的3 973 條推文數據。如果調查對象的推文中包含嚴格的模式,則將其標記為“抑郁”,例如“我被診斷為抑郁癥”。
2)非抑郁數據集。收集者于2016年12月收集了一個非抑郁數據集,同樣從中篩選出100 個調查對象,選擇發布了的3 973 條推文數據。如果調查對象從未發布過任何帶有字符串“抑郁”的推文,他或她將被選入非抑郁數據集。
考慮到要驗證方法的可行性,將數據集劃分為兩個部分,一部分用于訓練,另一部分用于測試,訓練數據與測試數據的比率為8 ∶2。在訓練與測試過程中,將隨機分配樣本,并按照多次計算的平均結果來記錄最終數據。
1.2 分類方法
本研究提出一個多示例學習的模型,利用提取的時間序列特征來檢測用戶是否患有抑郁癥。基于現有研究的局限性,并根據Twitter 數據集,提出了一種無監督的 LSTM 多示例學習模型(unsupervised LSTM multi-instance learning,ULML),其總體思路是:
1)使用無監督的LSTM,從每個推文中提取時間序列特征,該LSTM 可以存儲每個用戶的推文信息,可以更好地反映來自潛在抑郁癥用戶的抑郁信息。
2)為了利用時間序列特征的效率,并解決數據集不平衡的問題,通過分析該特征來訓練多示例學習模型。鑒于多示例學習所特有的屬性,本研究提出的機器學習模型在抑郁癥檢測方面將會表現得很好。
首先,給出要研究問題的定義:設有N=Nd +Nu條標注的推文數據,包括Pd個抑郁癥患者的Nd條推文數據TD = {td1,td2,…,tdNd} 和標簽數據YD ={yd1,yd2,…,ydNd} ,以及Pu個非抑郁癥患者的Nu條推文數據TU = {tu1,tu2,…,tuNu} 和標簽數據YU={yu1,yu2,…,yuNu} ,其中T=TD ∪TU={t1,t2,…,tN},Y=YD ∪YU={y1,y2,…,yN} 。期望采用非監督方法對TD 和TU 分別抽取時間序列特征SD = {sd1,sd2,…,sdNd} 和SU = {su1,su2,…,suNu},其中S=SD ∪SU ={s1,s2,…,sN} ,并通過這些數據訓練二值分類器F,用于未來對其他相關人員進行抑郁癥的分類檢測。
該方法的總體框架如圖1所示。首先,基于給定用戶的時間軸推文T,將其標記化為可用的推文編碼X,然后使用無監督的LSTM,將每個推文編碼為時間序列特征S;然后,使用訓練好的二進制分類器,對每個時間序列特征進行分類,其中分類器由數據集中標記良好的抑郁或非抑郁的推文訓練;最后,利用多示例學習來檢測給定用戶是否患有抑郁癥。
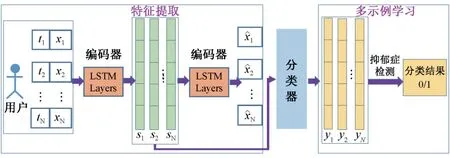
圖1 方法的總體框架Fig.1 Framework of the proposed method
1.2.1 特征提取
為了訓練出多示例學習模型,使用時間序列特征作為輸入,該特征基于每個用戶的時間軸推文。眾所周知,時間序列數據是指按時間順序索引的數據點序列,因此可用無監督的LSTM 作為從每個推文中提取時間序列特征的方法。在這種情況下,為了表示用戶時間軸推文中的時間序列信息,利用無監督的LSTM(也稱為LSTM 自動編碼器),從每個推文中提取了一組向量si。其中,自動編碼器是一種重建式的神經網絡,以無人監督的方式,從用戶那里學習每條推文的矢量化表示。
LSTM 自動編碼器至少需要兩個LSTM 層。以兩個LSTM 層模型為例,第一層可以視為編碼器,第二層可以視為解碼器。首先,模型通過第一LSTM層輸入矢量化的推文,以輸出形狀良好的向量;然后,將此向量作為輸入,以便通過第2 個LSTM 層,使輸出具有與輸入向量化推文相同的形狀;最后,將對模型進行優化,以使輸入和輸出盡可能相似。因此,LSTM 自動編碼器將來自輸入層的標記化推文xi壓縮為格式良好的代碼si,然后將代碼解壓縮為向量x^i的形式。如圖1中的特征提取部分所示,LSTM 自動編碼器的步驟如下:
1)推文標記化。由于詞干推文是一種字符串,因此自動編碼器的第一步是在輸入之前對推文進行標記化。最初選擇10 000 個流行的英語單詞,然后通過所選流行單詞的序列號對詞干推文中的每個單詞進行標記。為了使每個推文具有相同的尺寸,使用單詞嵌入方法。此方法首先計算推文的最大詞語數m,然后在tweet 向量前面嵌入0,以使每個推文具有相同的維數。通過這樣的方式,可以將推文T= {t1,t2,…,tN} 標記為X= {x1,x2,…,xN}。
2)LSTM 自編碼器。根據圖1中的特征提取部分,編碼器部分包含輸入推文、LSTM 編碼層和推文表示。輸入層順序輸入標記化的文本序列xi,進入到LSTM 層中進行處理并編碼為序列編碼si,然后這些序列編碼再通過LSTM 層進行解碼為x^i。其中,LSTM 自動編碼器層旨在生成與輸入標記化推文具有相同形狀的矩陣。因此,可以將輸入和輸出之間的差定義為損失函數,有
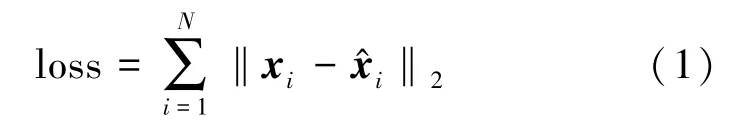
為了使輸入與輸出相似,該自動編碼器力求使損失函數最小化。其中,LSTM 自動編碼器采用了Adam 優化器[22]。這是一種優化算法,代替了經典的隨機梯度下降過程,根據訓練數據迭代來更新網絡權重。因此,此方法從所有標記化推文中迭代相同數量但隨機的項,以訓練LSTM 自動編碼器的模型,以便優化自動編碼器算法,最小化損失函數。
1.2.2 多示例學習
考慮給定的數據集,其中非抑郁的樣本數量大于抑郁的樣本數量。此外,根據標簽的規定,用戶的推文包含嚴格的模式,例如“我被診斷為抑郁癥”,才會被標記為抑郁。因此,多示例學習是一種合適的機器學習方法。另外,抑郁癥檢測問題是典型的二分類問題,分類模型用于估計二進制預測變量的概率。在這項工作中,抑郁癥檢測模型用來估算用戶抑郁癥的可能性。在機器學習領域,邏輯回歸和支持向量機是二進制分類領域的基本方法。因此,采用了這兩種方法來訓練分類器。
1)邏輯回歸(logistic regression,LR)。根據這一概念,邏輯回歸分類器f(si)可以定義如下:

式中,W、b為待學習的參數。
同時,為了測量二元分類器的邏輯回歸模型的學習損失,這里采用交叉熵損失函數,可以表示如下:
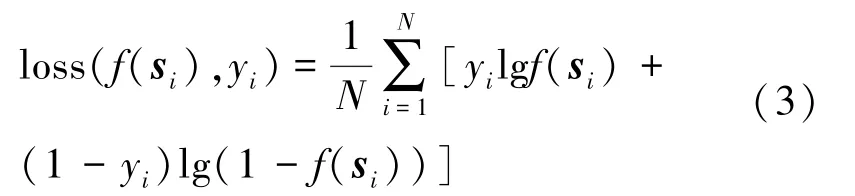
式中,yi為si所對應的真實標簽。
為了訓練分類器,采用了基本的優化器算法,即梯度下降法,該方法也稱為最速下降法,以尋找損失函數的最小值。在進行最終的實驗之前,本研究進行了一系列學習率不同的邏輯回歸實驗。根據這些實驗,本研究選擇了學習率為0.06 的分類器,該分類器具有最佳的性能。
2)支持向量機(support vector machine,SVM)。本研究還訓練了兩個具有不同內核功能的SVM 模型。根據Representer 定理[23],SVM 中的參數可以寫成訓練數據的線性組合,那么最終的分類器可以表示如下:
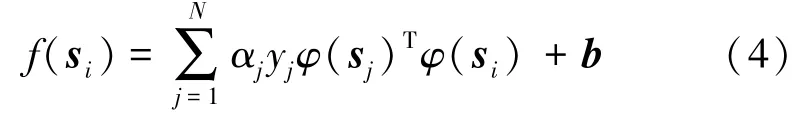
式中,φ(sj)Tφ(si)為核函數,也可以表示成K(si,sj)。
根據經驗,采用了線性核(L-SVM)和RBF 核(R-SVM)。其中,線性核的核函數可以表示為此外,RBF 核的核函數可表示為
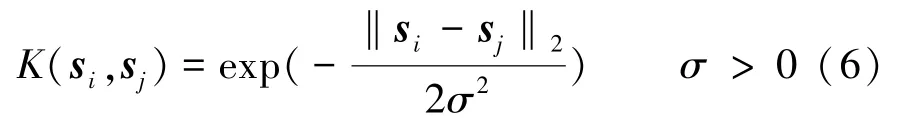

本研究選擇了LIBSVM 軟件包[24]作為實驗軟件。數據樣本是標記化的抑郁推文和標記化的非抑郁推文。根據經驗,這些實驗將時間序列特征維設置為128。根據損失和迭代圖,這些實驗選擇了無監督的LSTM 模型,該模型迭代9 000 次,以提取時間序列特征。對于L-SVM,采用默認參數的模型,其中C=1.0;對于R-SVM,選擇了軟件默認參數的模型,其中C =1.0,γ =10。
3)多示例學習。在訓練了檢測抑郁推文的模型之后,下一步就是預測Twitter 用戶是否患有抑郁。針對數據集不平衡的問題,采用多示例學習作為檢測模型來檢測Twitter 用戶。特別地,鑒于不平衡的數據集,本研究改進了該算法。該算法可分為兩部分,每一部分的詳細的結構如下:
(1)={s1,s2,…,sj,…,sn}為用戶ui的時間序列特征,其中單個n為用戶的推文數;采用選定的二進制分類器f(sj)來檢測每個推文的時間序列,輸出結果表示為={y1,y2,…,yj,…,yn},其中yj∈{0,1}。
(2)由于檢測分類的準確性無法達到100%,因此將算法添加一個權重參數ω,如果該用戶預測的推文被判定為抑郁的比重大于所有時間軸推文的權重ω,則可以將其診斷為抑郁。因此,該算法的第二步(即最終結果)可以定義如下:
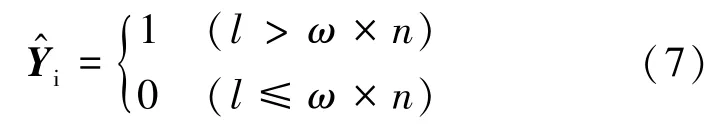
式中,l為推文中被分類為抑郁的推文數量。
1.3 驗證方法
為了驗證所提出的機器學習方法對利用文本信息進行抑郁癥分類的有效性,從以下幾個方面進行研究。
1)為了證明所提出方法的先進性,對比4 種傳統的機器學習方法,包括樸素貝葉斯(naive bayes,NB)、隨機決策森林(random decision forest,RDF)、多重社交網絡學習(multiple social network learning,MSNL),以及多模式抑郁詞典學習(multimodal depression dictionary learning,MDDL)。
2)為了證明所提出的方法中的各個模塊性能以及不同的參數設置對最終性能的影響,對訓練中所采用不同的分類器、不同的時間序列特征、不同的特征維度進行研究。
3)采用4 種評測準則來研究所提出方法的有效性,包括準確率、召回率、精度、F1 分數等。
1.3.1 對比方法
為了驗證所提出的機器學習方法的性能,比較了4 個傳統的基本方法,分別是樸素貝葉斯、隨機決策森林、多元社交網絡學習和多模式抑郁字典學習。
1)樸素貝葉斯。在機器學習中,樸素貝葉斯是一種基于貝葉斯定理的簡單概率分類器算法。它的思想基礎是對給定的項目進行分類,解決條件下每個類別的概率,在給定的項目中考慮最大值[25],其基本定義如下:
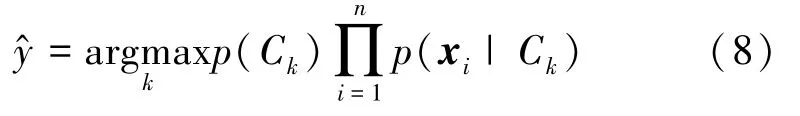
在機器學習中,樸素貝葉斯有3 種類型,分別是高斯樸素貝葉斯、多項式樸素貝葉斯和伯努利樸素貝葉斯。由于伯努利樸素貝葉斯特別適合于短文本的分類[26],因此選擇此事件模型進行比較。
2)隨機決策森林。在機器學習中,隨機決策森林是包含多個決策樹的分類器,其輸出類別由各個樹狀結構的輸出類別的模式編號(分類)或均值預測(回歸)確定。這種算法最早是由Tin 等在1995年提出的[27],然后被廣泛用于分類、回歸和其他任務。為了防止過度擬合,本項目根據經驗,將最大深度的參數設置為2,將隨機狀態的參數設置為1。
3)多重社交網絡學習。Song 等[28]提出了一種名為MSNL 的新型模型,它可以對源置信度和源一致性進行建模,特別是可使用線性系統的逆函數來獲得封閉形式的解決方案。此外,他們提出了一種社交網絡中數據丟失的方法。學習模型定義如下:
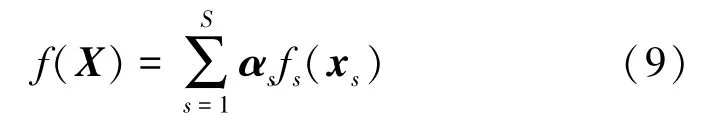
式中,權重向量αs表示代表來自第s個社交網絡的訓練好的模型權重,則損失函數定義如下:
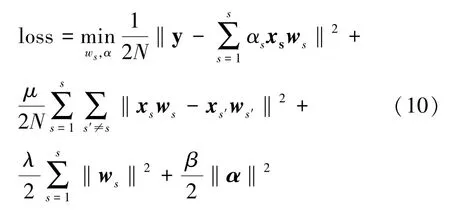
式中:β為正則化參數,在模型函數和損失函數中eTα= 1;此外,根據經驗和參數調整,將正則化參數λ設置為0.01,β設置為10-5,μ設置為0.1,以獲得該模型的良好性能。
4)多模式抑郁詞典學習。Shen 等[21]提出了一種抑郁用戶分類器,通過多模型字典學習來學習稀疏表示。它使用了6 種不同的特征,然后利用字典學習來學習一組潛在字典D= [d1,d2,…,dD] 和一個潛在稀疏表示A= [a1,a2,…,an] ,有
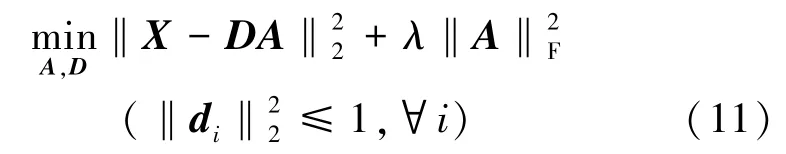
式中,λ為平衡參數。
然后,根據得到的稀疏表示,訓練了一個邏輯回歸分類器,該分類器使用潛在的稀疏回歸來檢測用戶是否患有抑郁癥,有
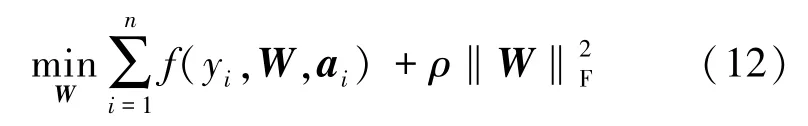
式中,ρ為平衡參數,W為訓練中需要學習的回歸參數矩陣,f(yi,W,ai)為訓練中的分類器損失函數,表示為
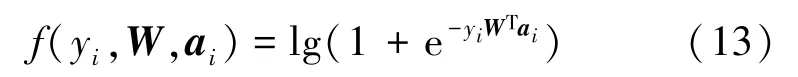
由于某些數據無法在社交網絡功能中進行標準化,因此在此模型中刪除了6 種數據類型。它們是狀態計數、關注者計數、朋友計數、列出計數、收藏夾計數和轉發計數。根據原始的論文設定,將字典維設置為135,將正則化參數α設置為3×10-5,將ρ設置為1×10-6。
此外,為了驗證所提出方法的有效性,在此實驗中,選擇了Pytorch 作為深度學習軟件平臺,并采用一臺NVIDIA GTX1080Ti 作為硬件平臺。根據經驗將時間序列特征維設置為128,并根據損失和迭代圖選擇了無監督的LSTM 模型,該模型迭代9 000次,以提取時間序列特征。
1.3.2 對比特征
基于所提出的多示例學習算法的概念,從推文中提取的任何特征都可以用作所提出算法的輸入。根據提取的特征,從每個推文中提取主題特征,并且幾乎可以肯定,抑郁推文的主題和非抑郁推文的主題可能會有所不同。因此,做了一組實驗,利用主題特征來訓練多示例模型。
1)主題特征(latent Dirichlet allocation,LDA)。該實驗采用了25 維LDA 特征,可以將其定義為來自每個Twitter 用戶的每條推文中前25 個主題的概率。
2)時間序列特征(time series,TS)。根據先前的實驗,該實驗選擇了128 維無監督LSTM 特征來表示時間序列特征。
1.3.3 評測準則
在二元分類領域,數據的統計主要采取4 種方法:TP (true positive),表示實際值是抑郁的,而預測值也是抑郁的;TN (true negative),表示實際值是非抑郁的,而預測值也是非抑郁的; FP (false positives),表示實際值為非抑郁,而且預測值為抑郁的;FN (false negative);表示實際值為抑郁的,而預測值為非抑郁的。
借助于以上4 個統計數據,通過比較準確率、召回率、精度和F1 得分,評價比較方法和比較特征的識別性能。
1)準確性:這是正確預測的值與總值的比率。幾乎可以肯定,準確性是最直觀的性能指標,有

2)召回率:也稱為靈敏度,是正確預測的正值與實際值中所有值的比率,有
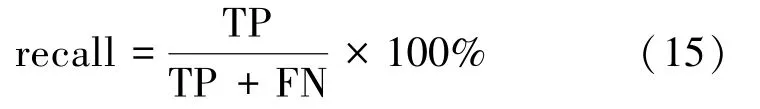
3)精度:也稱為正預測值,是正確預測的正值與總預測的正值之比,有
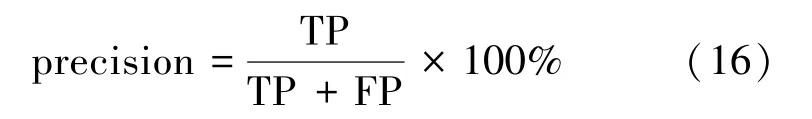
4)F1-分數:這是精度和召回率的加權平均值。通常,它表示精度和召回率的和諧平均值,有
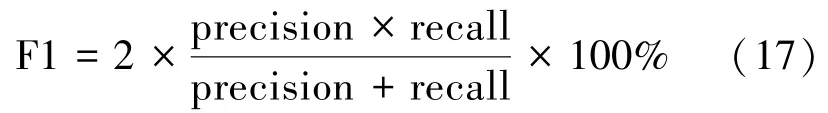
2 結果
2.1 不同方法的比較
首先,本研究進行了一系列實驗,以驗證提出的多示例學習模型的性能。為了訓練這些方法,在開始此實驗之前,已將提取的特征格式化為相同的維度。這些方法需要使用的特征是社交網絡特征、情感特征、主題特征和領域特征,每個特征都可以視為模態。由于方法自身的特殊性,僅采用時間序列特征作為輸入數據來預測抑郁癥。根據先前的實驗,該實驗選擇了尺寸為128 的無監督LSTM 特征。
表2顯示了4 個基本方法與所提出的方法(ULML)之間的性能比較。可以看出,MSNL 的準確性和精度最高,而ULML 的召回率和F1 得分最高。這表明,由于ULML 的召回率較高,因此在檢測到用戶有抑郁癥時,提出的多示例學習具有較好的性能。這也意味著,如果有關于用戶的更多信息,則機器學習模型可能具有更高的準確性。另外,MDL模型的性能不好,因為無法提取配置文件特征和視覺特征,因此這兩種方式可能對該模型產生更大的影響。此外,當NB 和RDF 具有更多模態時,性能會更好。
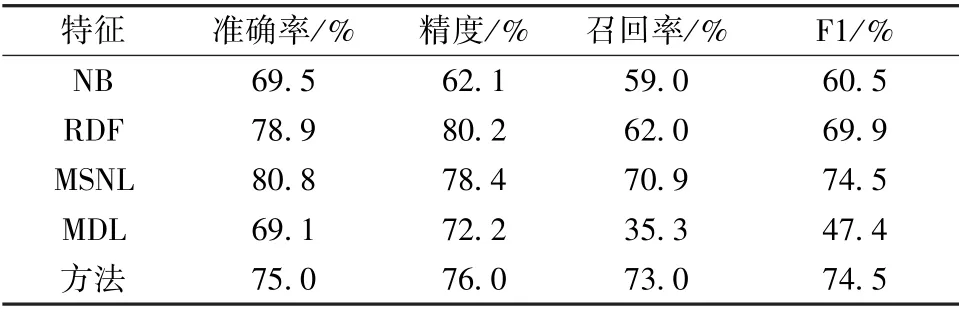
表2 不同方法的性能Tab.2 Performance on different methods
2.2 時間序列特征的比較
首先,進行了一組實驗,以檢驗在提出的多示例學習模型中非監督LSTM 功能的情況。由于MSNL 和MDL 必須利用多種模式,因此本實驗僅使用樸素貝葉斯和隨機森林作為比較基準。與以前的實驗一樣,該實驗評估的時間序列特征的維度為128。如表3所示,所提出的具有時間序列特征的多示例學習模型,明顯優于具有時間序列特征的樸素貝葉斯和隨機森林。這意味著時間序列可能更適合于所提出的多示例學習模型,并且也證明選擇多示例學習是因為其機器學習模型正確。
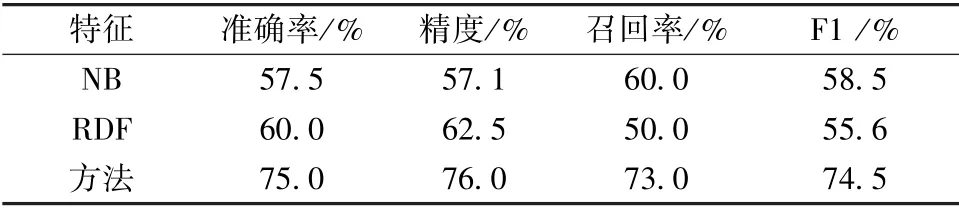
表3 每個模型上時間序列特征的性能Tab.3 Performance of time series features on each model
2.3 不同分類器的比較
表4所示為這3 個分類器之間的性能比較。可以看出,所有分類器均具有良好的性能,其中帶有RBF 內核的SVM 的分類器在所有4 個指標上均優于其他分類器。這些實驗證明,無監督的LSTM 功能可用于檢測抑郁癥的推文并表現良好。由于RBF 內核SVM 具有最佳性能,因此時間序列特征可能是線性不可分的特征,這也意味著當尺寸不是太大并且樣本為中等大小時,RBF 核方法比線性核方法更好。
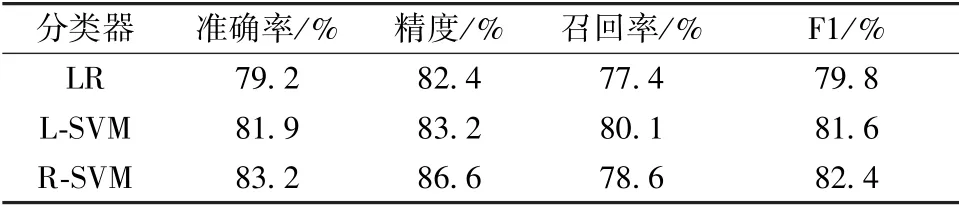
表4 不同分類器下的性能Tab.4 Performance with different classifiers
2.4 不同參數的比較
根據方法論中提到的RBF 核函數,為了更好地反映無監督的LSTM 功能,針對參數γ與C的不同組合進行了一組實驗,以找到最合適的分類器組合。其中,C為懲罰系數,γ表示映射到新要素空間后的數據分布。此外,這些實驗根據經驗,將時間序列特征維設置為128,并使用了無監督的LSTM 模型,該模型反復進行9 000 次,提取時間序列特征。
表5所示為分類器在不同參數組合之間的性能比較。可以看出,當參數γ=10 且參數C=10 時,相關的RBF 核分類器是最合適的分類器。根據該表,可發現性能的趨勢隨著C值的變化,在開始時是上升的,然后緩慢下降。這證明,如果C值越高則越容易擬合,如果C值越小則越容易擬合不足,因此,當C值太大或太小時,泛化能力都變差。

表5 不同參數下的模型性能Tab.5 Performance with different parameters
2.5 不同特征維度的比較
在以前的實驗中,由于經驗,采用了128 維無監督LSTM 功能。為了驗證無監督的LSTM 功能可以用于多示例學習,進行了一系列不同維度的無監督LSTM 功能的實驗。當提取256 維特征時,會發現損失值無法降低,這可能是因為尺寸太大而無法收斂。因此,這些實驗的設置尺寸d= {16,32,64,128}。根據維度列表,針對每個維度進行一組實驗,如圖2所示,其中多示例權重ω∈[0.05,0.24]。
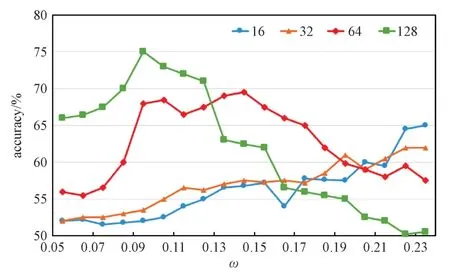
圖2 不同維度下的準確率隨權重變化Fig.2 The relationship between accuracy and weight under different dimensions
表6所示為在這些維度中多示例學習的性能。可以看到,尺寸128 可獲得最佳性能,并且隨著尺寸的增加,性能會變得更好。然而,隨著尺寸的增加,損失變得難以減少,這能證明更高的維度可以存儲更多有關時間序列的消息。因此,對于建議的多示例學習算法,維度128 可被視為最合適的維度。
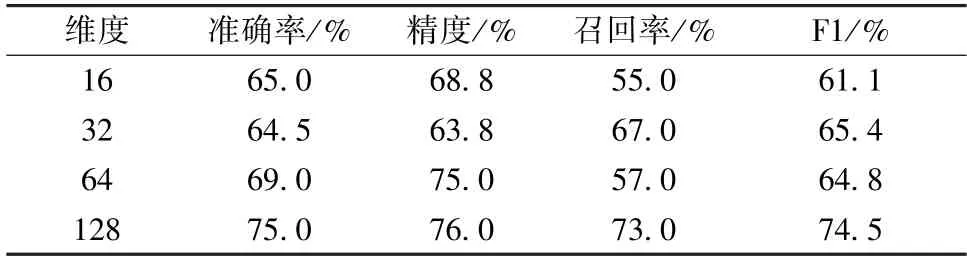
表6 不同維度的性能表現Tab.6 Performance with different feature dimensions
2.6 不同特征的比較
表7所示為所提出的具有不同特征的多示例學習模型的性能。可以看出,與主題特征(LDA)相比,時間序列特征(TS)獲得了最佳性能。這表明與主題特征信息相比,時間序列信息能更好地反映Twitter 用戶的抑郁傾向,也意味著所提出的機器學習模型可用于檢測Twitter 用戶的抑郁情緒。

表7 不同特征下的性能Tab.7 Performance with different features
3 討論
在傳統的臨床診斷中,心理醫生需要通過與來訪者進行面對面的訪談來診斷其是否患有抑郁癥以及病情的程度。然而,這種方法會有很多潛在的問題。鑒于有抑郁傾向的患者更愿意向社交媒體傾述自己的心情及狀態,所以借助計算機輔助方法,并利用社交媒體中的文本信息,提出了基于時間序列特征以及多示例學習的早期抑郁癥檢測方法。把被診斷人的社交媒體的文本信息進行LSTM編碼,產生時間序列特征,然后用多示例學習的方法對其進行二分類,從而判斷被診斷人是否具有早期抑郁癥傾向。
Islam 等[29]在Facebook 上搜集了一些社交媒體數據,構建了21 列的情感信息數據,包括7 145條數據,其中58%被標注為抑郁,而42%被標注為非抑郁;采用傳統的手工特征提取的方式,提取社交媒體特征,最后采用決策樹、K-近鄰和SVM 來實現抑郁癥的分類。Cacheda 等[30]利用文本、語義以及寫作相似度來定義特征,并采用隨機森林的方法實現抑郁癥的分類。這兩種方法均屬于傳統的手工特征方法,從本研究的結果中可以發現,采用傳統的特征均不如基于深度學習的序列特征的效果好,說明序列化的深度特征可以更多地保存患者的多個時間信息,能夠進一步提升分類效果。
然而,深度學習的優異表現主要是通過大量的有標注數據集的訓練而獲得的[31],目前專注于用文本信息進行抑郁癥識別的數據集較少,Shen 等[21]采用的這個數據集相對來說是一個適用于模型訓練的數據集。然而,這個數據集包含了太多的冗余信息,使其不能直接用于模型訓練,因此從中整理了100 個抑郁患者和100 個非抑郁患者合計7 946條推文數據。從結果上來看,雖然取得了75%的準確率,但還是遠遠不夠的,其原因之一就是訓練數據集不夠大,能夠學習到的知識是有限的。本研究的主要目的是通過實驗驗證LSTM 特征,以及多示例學習的有效性,證明其可以用于早期抑郁癥的診斷,比傳統的算法模型要好,后期可以通過擴大數據集進行模型效果的提升。Gui 等[32]同樣也通過強化學習的方法,驗證了LSTM 序列特征的優越性。
此外,根據特征比較實驗,對于提出的多示例學習模型,128 維無監督LSTM 是最合適的時間序列特征,說明特征的維度越高,可以保存的有效信息就越多。研究結果還表明,基于RBF 內核的SVM分類器是該算法最合適的二進制分類器,這意味著時間序列特征是線性不可分的特征。而且,與從每個推文中提取的其他特征相比,時間序列特征可以更好地反映抑郁信息,因此證明用其可以通過社交媒體中的文本信息進行診斷抑郁癥檢測。
根據不同的模型比較實驗的結果來看,ULML在召回指標中表現最佳。可以看出,對于檢測抑郁用戶,所提出模型的性能優于比較的基準模型。但是,該模型的準確性和精確度不如其他多模態模型好。這是由于這些多模態模型利用了來自用戶的更多信息,而所提出的模型僅采用了時間序列特征。然而,在實踐中召回率較高,即發現抑郁癥的陽性病例是有非常價值的[21]。
此外,對推文數據的編碼訓練采用高維標簽碼并作為輸入,其實這樣的標簽之間是沒有關聯意義的,這也是影響性能的一個關鍵因素。Word2Vec(word to vector)是一個基于維基百科的詞向量模型[33],可以把對文本內容的處理簡化為向量空間中的向量運算,計算出向量空間上的相似度,以表示文本語義上的相似度。因此,為了將同一條推文數據之間的單詞有意義化,未來可以采用Word2Vec先對詞語向量化,并采用雙重LSTM 進行編碼學習[34],使特征中包含更多的原始語義信息,以進一步提升模型的性能。
4 結論
針對傳統的面對面交談來檢測抑郁癥存在的問題,本研究利用患者在社交媒體上所發布的文本信息來檢測早期的抑郁傾向。提出利用時間序列特征和多示例學習檢測模型,使用無監督LSTM 提取時間序列特征,使用訓練分類器實現二值分類,使用多示例學習模型解決不平衡樣本問題,并在一個通用標注數據集上進行了測試,以驗證所提出方法的有效性和先進性。鑒于當前方法中所用的數據集較小,使訓練得到的模型不夠完美,所以下一步將整理更多的數據以供訓練。此外,考慮到當前文本數據的表示采用標簽碼的形式,單詞之間缺乏聯系,下一步將引入Word2Vec 來實現文本信息的編碼,增強單詞之間的關聯性,以提升模型的整體性能。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
