基于深度學習的移動端安全帽檢測系統設計與實現
2022-05-23 10:24:04楊雪陳剛
江蘇通信 2022年2期
楊 雪 陳 剛
中通服咨詢設計研究院有限公司
0 引言
近年來,隨著我國基礎設施的大量建設,工地上工人的安全問題也日益凸顯。據統計,在工地安全事故中,由于工人未正確佩戴安全帽,高空墜物撞擊引起的死傷事故時有發生。為改善這一情況,在工地上對工人進行安全帽的檢測,對保障工人的生命安全具有重要意義。
目前,許多專家學者提出各種方法對工地上工人是否佩戴安全帽進行檢測。有人提出基于ResNet50-SSD的安全帽佩戴狀態檢測,但該方法精度欠缺,誤報率較高。有人提出的基于改進Tiny-yolov3方法能對工人是否佩戴安全帽進行識別,但是受人體復雜運動的影響,導致檢測率也較低。還有人提出基于改進Yolov4-Tiny網絡模型的安全帽檢測,但受光線、目標大小因素影響較大,準確率同樣有所欠缺。且以上系統都不具備便于移動的特點。
針對以上問題,考慮到施工環境的復雜性,本設計提出一種基于YOLOv4的移動端安全帽檢測系統,在公開數據集上訓練YOLOv4網絡,將訓練好的權重網絡移植到嵌入式移動端平臺,最終實現安全帽的佩戴檢測。
1 YOLOv4介紹
1.1 網絡結構
YOLOv4相較于YOLO系列的前幾代版本,其速度更快,精度更高。這得益于YOLO網絡結構的不斷優化與改進。YOLO目標檢測算法衍生到第四代版本YOLOv4,其網絡結構主要由主干特征提取網絡(CSPDarknet53),空間金字塔池(SPP),路徑聚合網絡(PANet),YOLOv3檢測頭組成。
(1)CSPDarknet53
CSPDarknet53是在YOLOv3主干提取網絡Darknet53基礎上,借鑒CSPNet(Cross Stage Paritial Network)的經驗而形成的新的網絡結構。該結構共有72層卷積層。包含5個CSP模塊,每個CSP模塊前面的卷積核大小都是3*3,步長為2。因此可以起到下采樣作用。CSPNet模塊結構如圖1所示。基礎層的特征映射按照通道維度拆分為兩部分,然后通過跨階段層次結構進行拼接。該結構可以獲取更豐富的梯度融合信息以增強網絡的學習能力,同時在保證精度的情況下降低計算量。
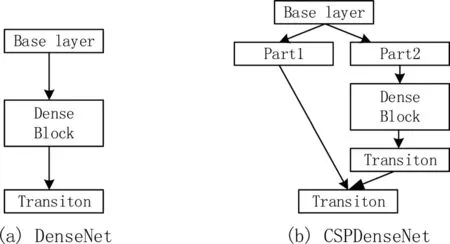
圖1 CSP模塊
(2)空間金字塔池
空間金字塔池(SPP)結構能夠實現局部特征和全局特征的融合,有效增加感受野,豐富最終特征圖的表達能力。YOLOv4的SPP結構如圖2所示,在輸入圖像大小為608*608的情況下,經過CSPDarknet53特征提取網絡,得到最終特征圖大小為19*19。對該特征圖層進行最大池化(maxpool),卷積核大小分別為13*13、9*9,5*5、1*1。池化時采用padding操作,移動步長為1,以保證池化后的特征圖大小仍為13*13。然后將不同池化大小得到的特征圖進行拼接。
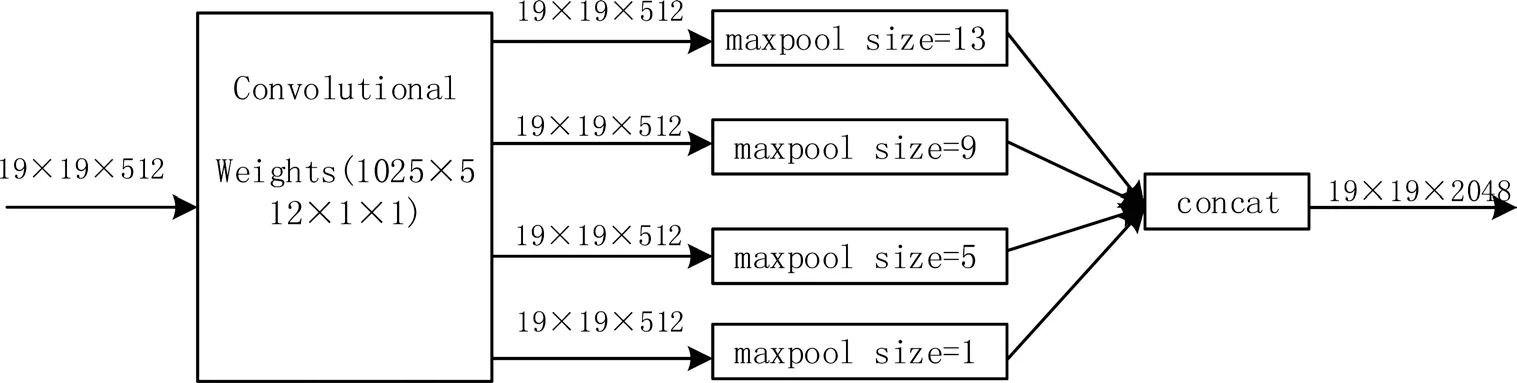
圖2 SPP結構
(3)路徑聚合網絡
YOLOv4中采用路徑聚合網絡(PANet)替換YOLOv3中的特征金字塔網絡(FPN)進行多通道特征融合。FPN算法中,淺層的特征傳遞到頂層要經過幾十甚至一百多個網絡層,顯然路徑太長會丟失部分淺層特征。在PANet中,淺層信息從P2沿著自下而上的路徑增強傳遞到頂層,該自下而上的路徑增強的層數不到10層,極大縮短較低層與頂層之間的信息路徑,能較好地保留淺層特征信息,使得網絡學習到更加復雜以及具有不變性的特征。如圖3所示。
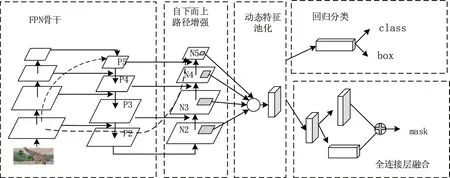
圖3 PANet結構
1.2 損失函數
圖片輸入到網絡后會分成S*S個網格,每個網格產生B個候選框,每個候選框最終會得到相應的bounding box。在這過程中,需要利用損失函數確定具體的bounding box計算誤差更新權重。YOLOv4的損失函數LOSS由回歸損失Lciou,置信度損失Lconf,分類損失Lclass三部分構成,具體如公式(1)所示。

2 實驗
2.1 數據集
數據集采用roboflow上的開源安全帽數據集,該數據集是由東北大學提供,共包含7035張圖片。均在工地拍攝采集。本設計只區分工作場所中遵守安全規則的工人和不遵守安全規則的工人,因此標注安全帽(helmet)和人頭(head)兩類標簽。訓練集圖片劃分5628張,測試集圖片劃分1407張。該數據集的示例如圖4所示。

圖4 示例圖片
2.2 模型訓練
該YOLOv4網絡模型的訓練采用Darknet深度學習框架,訓練平臺為GPU。GPU配置信息為GeForce GTX 1080 Ti,擁有11GB GDDR5X顯存。網絡訓練輸入圖片大小為416*416,每次迭代訓練圖片64張,分16批次。網絡其他參數配置如表1所示,在網絡達到訓練次數為20000次時,學習率調整為0.0001,在達到訓練次數為30000時,學習率為0.00001。
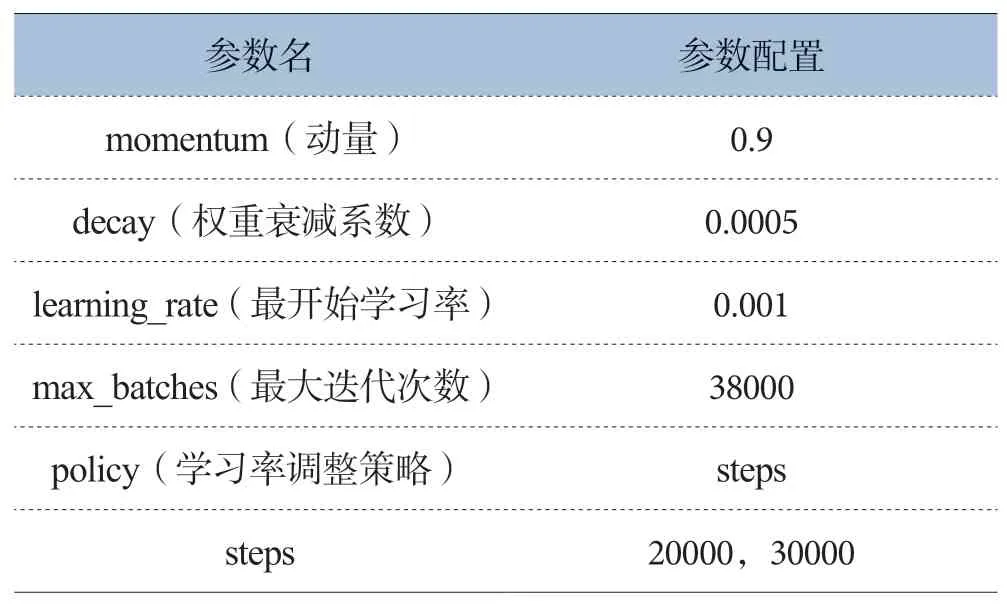
表1 網絡模型訓練參數配置表
2.3 模型過程可視化
將安全帽數據集制作完成與網絡參數配置完成后,在Darknet深度學習框架下訓練YOLOv4網絡。將訓練過程中的日志保存,根據保存的日志信息繪制損失值變化。損失值是衡量預測值與真實值之間的距離,損失值計算如公式(1)所示,其值越小,表示網絡的預測值越接近真實值。訓練過程損失值變化如圖5所示。隨著網絡迭代次數的增加,損失值不斷減少,在網絡迭代到35000次后,損失值穩定在0.3左右,模型已經開始收斂,直至迭代到38000次,并保存迭代38000次后的網絡權重值。最終網絡的mAP為88.2%。
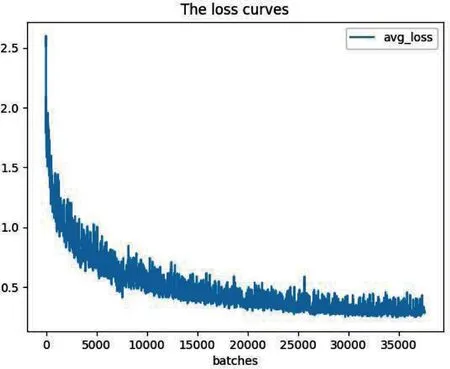
圖5 訓練過程損失函數
3 嵌入式平臺實驗
3.1 Jetson Nano介紹
Jetson Nano嵌入式平臺是NVIDIA公司發布的一款主打低功耗的人工智能計算機。該平臺采用CPU+GPU異構結構,CPU為四核Cortex-A57,GPU采用規模最小的Maxwell架構顯卡,擁有128個CUDA單元。同時該平臺還擁有4GB LPDDR4內存。該嵌入式平臺可以提供472 GFLOPS的浮點運算能力,能并行運行神經網絡,因此,該平臺可以運用到圖像分類、目標識別、分割、語音處理等領域。為了快速構建AI項目,NVIDIA公司為該平臺提供一套開發者套件JetPack,該套件中包括Ubuntu18.04操作系統和TensorRT。可以根據開發者需要安裝Darknet、Caffe等深度學習框架進行AI項目的開發。
3.2 實驗結果
將訓練完之后的網絡權重文件部署到Jetson Nano移動端平臺上,配置該平臺深度學習環境。進行安全帽識別的實驗,如圖6所示。

圖6 在Jetson Nano嵌入式平臺實現場景
圖7展示了安全帽部分測試集在Jetson Nano移動端平臺的檢測效果,選取的場景包含檢測角度不佳、目標過小、目標密集等不同的復雜場景。從檢測效果來看,YOLOv4網絡在嵌入式平臺表現出良好的檢測性能,能夠準確區分工人是否正確佩戴安全帽,預測一幀圖片也只需0.33s,能夠滿足工地實時性要求。

圖7 檢測結果
3.3 實驗結果比較
本設計提出的基于Yolov4的檢測方法mAP達88.2%,相較于文獻提出的基于ResNet-SSD算法的mAP,本方法mAP提高了9.7%;相較于文獻提出的基于改進yolov3-Tiny算法的mAP,本方法mAP提高了44%;相較于文獻提出的基于改進yolov4-Tiny算法的mAP,本方法mAP提高了8.7%,準確率達到一定的提升,結果如表2所示。且其他文獻提出的安全帽檢測系統都是基于PC端實現,不能較好落地,本設計不僅在PC端實現安全帽檢測,也成功移植嵌入式平臺,實現每幀圖像0.33s的檢測速度,也為后續目標識別算法的移植提供參考。
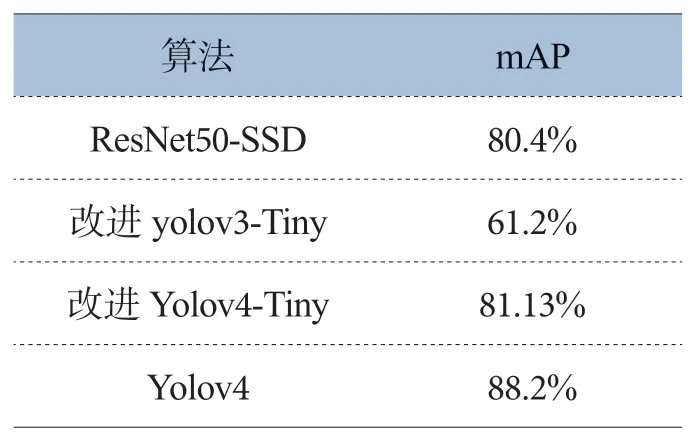
表2 各算法檢測結果比較
4 結束語
本設計提出一種基于嵌入式平臺的安全帽檢測系統,便于移動與裝卸。試驗結果表明,YOLOv4網絡的損失值穩定在0.3左右,mAP達到88.2%。將網絡部署在Jetson Nano嵌入式平臺上,該平臺能夠準確實時地識別工人是否佩戴安全帽。該系統可用于施工場地工人安全帽佩戴情況的檢測。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
鐵道通信信號(2018年2期)2018-04-18 12:18:23
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電鍍與環保(2016年3期)2017-01-20 08:15:32
海峽科技與產業(2016年3期)2016-05-17 04:32:12
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
