基于深度神經網絡的異常財務數據識別方法
2022-05-24 11:43:52馮華偉
電子設計工程 2022年10期
馮華偉
(河南省太康縣人民醫院,河南 周口 461400)
作為醫院財務系統的重要組成部分,醫療賬務支付系統承擔著醫院財務結算的重要任務,也是維持醫院正常運轉的關鍵。同時,支付系統也存在著較高的安全風險,例如信用卡套現、醫療保險詐騙以及賬目作假等。這些財務數據的造假行為嚴重影響了醫院財務系統的正常運轉,同時也影響了醫院以及社會的公共利益。而根據國外機構的調查,近年來通過金融詐騙而構成的財務系統損失可能超過機構年收入的5%[1-2]。因此,對財務異常數據的準確識別是保障財務系統正常運轉的重要途徑。
近年來,隨著醫院財務數據數字化進程的逐步加快,財務數據的整體特點也轉變為數據量巨大、數據增長速度快、數據類型復雜化等。傳統檢測方法使用數學的統計方法進行驗證,其優點是可以直觀快速地篩選出異常數據,但缺點是無法處理海量數據[3]。同時,傳統檢測方法也無法滿足當前的復雜檢測需求。而深度學習的出現引起了學者的廣泛關注[4],文中融合了隨機森林算法與神經網絡技術,提出了一種改進的異常數據檢測方法,并改善了當前算法中存在的復雜度較高、檢測誤差大以及檢測效率低等問題。
1 異常數據檢測模型
1.1 財務數據特征說明
對財務數據的兩個特征[5-6]作如下說明:
1)信息熵
信息熵是數據處理領域常見的衡量標準,該指標可用來判定數據樣本的不確定性。信息熵越大,代表樣本的確定性越小;信息熵越小,代表樣本的確定性越大。
信息熵計算公式如下:

式(1)中,D為樣本數據集,Ck為k屬性樣本。在這些樣本中,C0為異常類型的樣本,C1是正常類型的樣本。
2)信息增益率
信息增益率通常用來表示金融樣本數據的一種分類標準,即對于數據集合的屬性特征部分,可定義為:

金融數據還有時間特征,因此在對金融數據進行分析時還需考慮其時間特征。故此,結合時間特征的異常數據增益可定義為:

式(5)中,Ai為異常數據的特征信息,αm為時間影響因子,該參數用來表征過去數據對當前數據的影響。αm可以表示為:
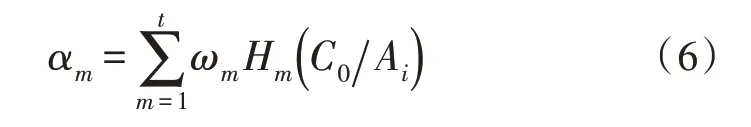
式(6)中,ωm為第m個時刻的權重因子,Hm表示異常數據類別劃分因子。該因子越小,即對數據類別的劃分越有利。
1.2 隨機森林算法
隨機森林算法[7-9]的本質是多項目決策算法,該算法最初是在二值樹算法基礎上進行改進的。其特征為算法樣本集合中的異常數據集合即稀疏矩陣集合,同時也是一種無監督的單一數據監測方法。隨機森林算法使用二值樹算法結構,將數據子集的每一個數據均作為二值樹中的節點。
該算法所需的數據不需要過多異常點,但同時異常點需要滿足數據特征與其他正常數據點以及數據特征隔離量較大的條件,算法才能建立多個森林樹。并通過隨機特征選取不同的分割點特征,進而構建完整的森林樹結構。隨機森林算法流程如圖1所示。

圖1 隨機森林算法流程
需要指出的是,文中森林樹的構建所需采集樣本無需過多,數據的異常構建公式如下:
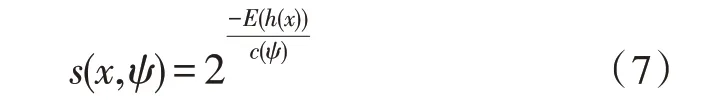
式(7)中,c(Ψ)是在數據采集量為Ψ的情況下,構建的二值樹無法進行搜索的總路徑長度。當路徑長度較長時,該參數值趨近于0;當路徑長度和c(Ψ)值大體相當時,該參數值趨近于0.5;當路徑長度為零時,該參數值趨近于1。但這種傳統森林算法,無法解決大量異常數據同時聚類的情況。
文中對隨機森林進行了改進,構建了方差隨機森林算法,并向隨機森林算法中加入方差特征值。這樣隨機森林算法可進行更優的聚類分析,算法構造函數如式(8)所示:

式中,樣本特征集合為Q,cj為隨機系數,p為截距。截距表達方程如式(9)所示:
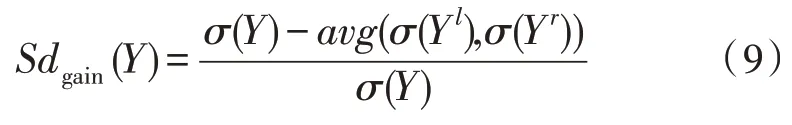
該改進算法在計算樹的路徑長度時,使用cj系數進行判斷,這樣可以使得p截距取最大值。
1.3 深度神經網絡異常數據監測模型
構建深度神經網絡模型對隨機森林算法數據進行訓練。文中使用RNN 網絡結構進行訓練[10-12],RNN 為循環卷積神經網絡,該網絡的模型示意圖如圖2 所示。
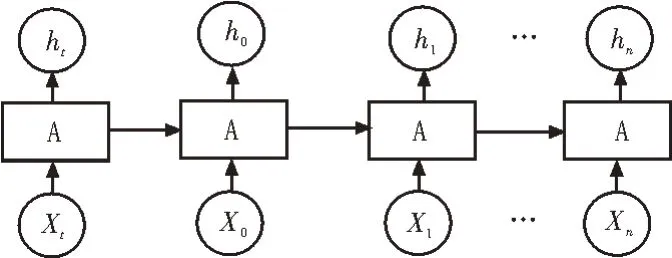
圖2 RNN模型示意圖
RNN 網絡單元的主要用途為序列數據的訓練與處理。該神經網絡的特點是每個單元的輸出層均可返回至輸入層作循環卷積。這種結構適合于時間結構,對隨機森林算法尤為適用,可有效地減少數據的訓練次數。文中神經網絡的損失函數L和梯度參數U的關系為:

文中算法的流程如圖3 所示。首先對樣本數據集合進行隨機森林算法驗證,這樣即可以對每一個異常值進行聚類和分析。然后根據預處理的數據對異常數據樣本進行篩選,將篩選完成的結果輸入至RNN 網絡中進行特征訓練。

圖3 文中算法流程
具體的實現過程如下:
1)通過方差隨機森林算法對樣本數據集進行異常數據檢測,同時對異常數據進行標記,得到標記子集為:
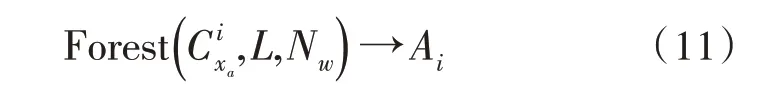
2)將異常數據子集Ai加入到異常樣本數據集合中,剩下的數據子集加入到正常樣本數據集合中,然后進行篩選,并將其加載至RNN 的入口。
模型實現過程的偽代碼如下:
Input:Forestree(D,h,emax),Forestree 為文中森林算法,h為森林樹的高度,hmax為森林樹的最大高度。
Output:子樹的數據集合。
1)Start;
2)設置hmax的值,大小為子采樣的對數;
3)ifh≥emax&D≤1 then;
4)return 前個樹節點;
5)else 對于任何的屬性樣本,計算當前時間序列的時間影響因子αm,然后計算信息增益比值,該值求得的最大值即為當前森林樹的分裂值;
6)D→filter(D),將篩選后的子集合傳遞至結果處;
7)返回節點;
8)end if。
1.4 數據檢測指標
隨機森林檢測系統是分類系統,因此文中使用分類效果參數對分類系統的效果進行評估。典型的參數值有準確率、召回率、F1 值[13-16]。
準確率一般是針對異常數據的評價標準,文中指算法可以成功識別異常數據的概率值,其計算公式為:
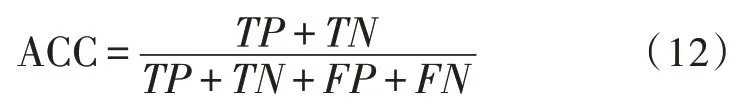
召回率的計算公式為:

F1 值綜合了準確率以及召回率,計算公式如下所示:

與此同時,為了直觀地觀測到分類特征,還運用了ROC 曲線進行驗證。該曲線的X軸坐標為假正率FPR,Y軸坐標為假負率TPR,該曲線值通常用來判斷二分類器性能的重要指標。與ROC 曲線關聯的還有AUC 值,該值用來表征ROC 曲線下方和坐標軸形成的面積大小。該面積可定量對模型的性能進行評估說明,AUC 值越大說明算法性能越優。
2 實證分析
2.1 實驗數據以及實驗環境
文中數據使用兩個訓練樣本集和一個測試樣本集進行實驗。訓練樣本集的來源為某調查機構提供的資金交易數據,交易數據集合屬性為交易賬戶信息、交易金額以及交易方向等金融屬性。最終訓練結果指向交易賬戶,將訓練測得的交易賬戶異常數據和真實的交易賬戶異常數據進行比較,進而對模型的算法準確性進行驗證。
訓練數據集共有數據樣本15 000 個,測試樣本集合為5 000 個,實驗數據環境配置如表1 所示。

表1 數據環境配置
2.2 實驗數據預處理
由于樣本數據集存在著屬性缺失或屬性造假的情況,因此需要對實驗數據進行預處理。其預處理步驟為:
1)數據篩選
首先對原始數據的屬性不完整數據進行清除,然后對造假的數據進行清除。例如,該數據中存在金融開戶戶主和銀行卡卡主姓名不一致的情況,刪除此類數據。
2)數據特征分類
數據的屬性有交易賬戶信息、交易金額以及交易方向等,按照數據特征進行數據分類。
3)數據歸一化
將數據的分類值轉換成特征值,將數據均做成長度相同的歸一化數據,便于算法的訓練。
2.3 實驗設計以及結果分析
為了驗證文中算法檢測異常數據的性能進行對比實驗。文中使用多個對比算法對測試數據集合進行處理,對比算法處理后的準確率、召回率以及F1值指標。文中使用隨機特征選擇算法(Ram)、基本隨機森林(Forest)算法、ADA 同步算法(ADAsync)3種對比算法,表2 為對比實驗指標結果。
由表2 可看出,文中算法的綜合F1 值是最高的。雖然隨機特征選擇算法的召回率較高,但準確率較低。這是因為該算法在進行樣本處理時,會有跨文本處理的風險,因此并不適用于金融數據處理。而文中算法具有更優的特征選擇能力,可有效地提升分類器的分類性能,算法的F1 值相較其他算法均有2%以上的提升。
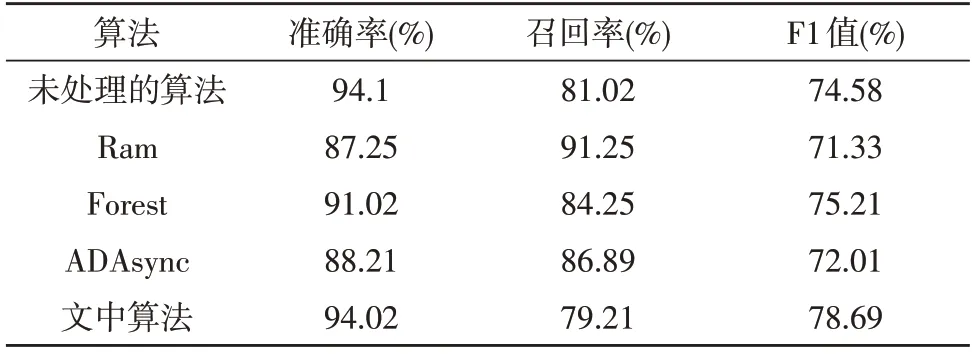
表2 實驗結果
ROC 曲線可以對分類特征進行直觀地檢測,使用統計軟件對文中算法處理結果進行ROC 曲線的繪制,曲線如圖4 所示。
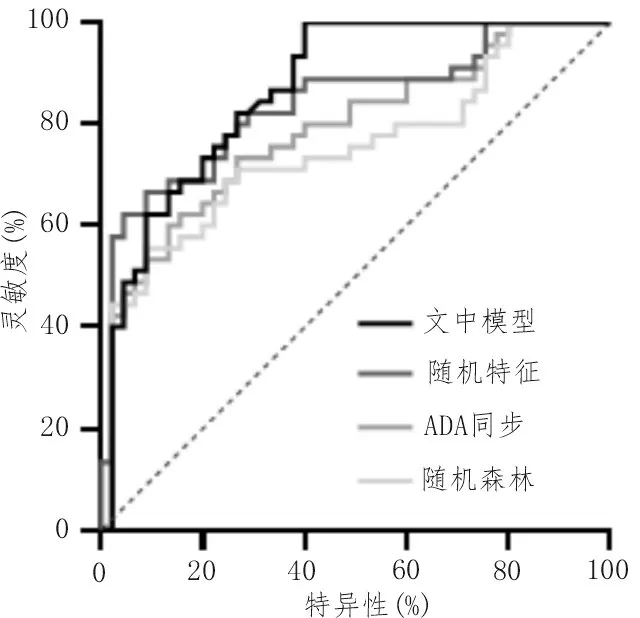
圖4 算法的ROC曲線
由圖4 可以定性的看出,各個算法的分類性能大體相當,文中算法相較其他算法有所提升。而為了定量的判斷算法的分類性能,對AUC 值進行了估算,AUC 值計算結果如表3 所示。

表3 AUC值計算結果
從AUC 計算結果可知,文中算法的AUC 值最高。表明文中算法對金融異常數據的檢測有良好的效果。
3 結束語
傳統檢測方法無法用來檢測當前海量的財務數據。文中提出了基于深度神經網絡的異常數據檢測方法,有效改善了當前算法中存在的復雜度較高、檢測誤差大以及檢測效率低等問題。實驗結果表明,文中算法F1 值以及AUC 值相較其他算法均有不同程度的提升,表明該算法對財務異常數據的檢測有較為理想的效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
