基于深度學習的車標檢測算法研究
2022-05-25 09:24:46薄純娟
大連民族大學學報 2022年1期
薛 超,薄純娟,王 欣
(1.大連民族大學 a.機電工程學院;b.信息與通信工程學院,遼寧 大連 116005;2.大連鐵路中學,遼寧 大連 116021)
目標檢測是計算機視覺領域的分支,主要工作是從圖像中找到特定的目標并進行準確地標注,根據選定數據集的不同,檢測算法可以檢測的目標也不同。一方面,車標作為日常生活中常見的目標,具有小尺度、形狀不定、受環境影響嚴重、種類繁多等特點,如何針對目標檢測算法進行改進以適應這些特點,是目標檢測研究的一項熱門課題,因此車標對于目標檢測具有一定的學術研究價值;另一方面,車標檢測對道路交通管理具有一定的幫助,通過結合車牌、車型、車標等重要特征,可以快速定位相應車輛,此外汽車廠商通過對交通錄像進行車標檢測,可以輔助計算汽車品牌曝光度,因此車標檢測具有一定的現實應用意義。
1 傳統車標檢測方法
傳統的車標檢測算法多基于圖像處理,主要步驟包括:圖像預處理、窗口滑動、特征提取、特征選擇、特征分類和后處理等。首先進行圖像預處理,包括歸一化、高斯濾波、灰度化處理、邊緣檢測和二值化等操作;其次需要選定特征,根據待識別車標的特征進行手動參數調整,目前常用的特征有Haar、LBP和HOG等;最后進行分類器的訓練。這類算法由于檢測效率較低,僅適用于靜態和簡單場景下的車標檢測,同時可檢測的類別也較少。卷積神經網絡[1]引入目標檢測領域后,深度學習目標檢測算法相比傳統算法檢測速度和精度均有所提升。根據算法過程的不同,目前深度學習目標檢測算法可以分為一階段算法(one-stage)和二階段算法(two-stage)。一階段算法直接進行候選框的分類與回歸,檢測速度較快但精度較低,如YOLO[2]、SSD[3]等;二階段算法首先會將候選框和背景相互分離,然后將對候選框進行分類與回歸,由于算法分兩個步驟進行,因此二階段算法檢測速度較慢但是精度更高,如Fast R-CNN[4]和Faster R-CNN[5]等。二階段算法在第二階段可以選擇性挑選樣本,因此正負樣本較為均衡,一階段算法則存在正負樣本不平衡的問題,Tsung-Yi等[6]提出Facal Loss方法,使得一階段算法能夠超越二階段算法。
1.1 YOLOv3算法分析
目前車標檢測算法主要是基于主流目標檢測算法進行改進,而一階段算法由于其快速檢測的特性,更加適合進行車標檢測,因此車標檢測算法主要是基于一階段算法進行改進。YOLOv3[7]算法由于其高檢測速度,在車標檢測領域被廣泛應用,如王林等[8]基于YOLOv3進行改進,將Darknet-53改換為層數更少的Darknet-19,同時減少預測層;阮祥偉等[9]基于YOLOv3提出NVLD算法,減少網絡層數的同時添加殘差學習模塊[10],最終在不增加參數的條件下提升網絡提取效果;LIU R K等[11]提出SSFPD算法,針對車標小尺度檢測效果較差的問題,首次提出約束區域檢測和復制粘貼策略;馮佳明等[12]基于YOLOv3提出改進算法YOLOv3-fass,一方面降低網絡通道數,另一方面添加尺度跳連結構,減少網絡參數的同時提升特征融合效果。
1.2 YOLOv4算法分析
YOLOv4是Bochkovsky等[13]在2020年提出的一種對YOLOv3進行改進的算法,從輸入端到輸出端都應用了大量技巧性算法,這些算法可分為兩類:一類是僅增加訓練成本的算法(Bag of freebies),例如數據增強、標簽平滑等;另一類是增加少量計算成本的算法(Bag of specials),例如增強接收域、空間注意力模塊等,性能上不論是訓練階段還是檢測階段,YOLOv4相比YOLOv3都有一定提升。
YOLOv4預測部分共有三個不同尺度的輸入層,有助于提升多尺度目標檢測效果,然而車標檢測面對的目標大部分為中小尺度目標,對于多尺度敏感性較低;此外,車標數據集圖片分辨率通常較低,對于層數較多的網絡結構,車標特征相對難以學習,同時過于復雜的網絡結構會增加大量計算成本,降低檢測速度。針對上述問題,本文針對YOLOv4算法進行改進,使其更好地應用于車標檢測。
2 算法設計
2.1 網絡結構設計
現實場景中車標通常為小尺度目標,同時考慮車標數據集分辨率不高的情況,本文選取層數較少的Tiny-Darknet作為改進算法的特征提取網絡。Tiny-Darknet的優勢是網絡層數少、檢測速度快,相比CSP-Darknet53的104層網絡結構,它只有22層,擁有更少的模型參數,更快的檢測速度。本文對兩種網絡結構進行了對比實驗,結果見表1。

表1 網絡結構對比實驗結果
補充FPS與mAP@0.75的含義。從表1可以得知,Tiny-Darknet相比CSP-Darknet53檢測速度增加兩倍,精度僅下降4.81%,因此本文選擇Tiny-Darknet作為本文算法的特征提取網絡。
輸入圖像經過多層卷積后,選擇26×26和52×52兩種尺度的特征圖進行融合操作。首先對26×26特征圖進行上采樣操作,然后與52×52特征圖進行向量拼接,得到拼接后的52×52特征圖作為預測層之一;上一步拼接后的52×52特征圖經過卷積降維后與26×26特征圖進行向量拼接,作為預測層之一。經過自底向上和自頂向下兩次特征融合操作后,形成PAN網絡[14],提升特征圖所含的特征信息,最后選取中尺度(52×52)和小尺度(26×26)特征圖進行預測,滿足現實場景中車標的特點,改進后網絡結構如圖1。
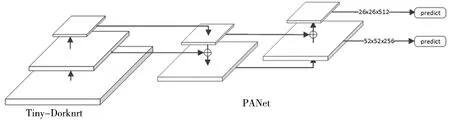
圖1 改進后網絡結構圖
2.2 改進損失函數
模型訓練過程中會產生許多預測框,算法會根據預先設定好的閾值計算預測框與真實框的交并比(Intersection over Union ,IoU),大于閾值為正樣本,小于閾值為負樣本。實際上,負樣本的數量往往遠多于正樣本,根據本文改進后的網絡模型,當輸入圖像尺寸為416×416時,會產生10 140個先驗框,而對于車標數據集,每張圖片通常只包含一個目標,多數預測框不包含目標,正樣本的數量遠低于負樣本,正負樣本不平衡的問題更加嚴重。Focal loss[6]可以通過調整權重參數,降低負樣本的損失權重,因此本文在損失函數中添加Focal loss調整負樣本比例,從而改善車標訓練過程中正負樣本失衡的問題。YOLOv4中引入Focal loss的損失函數如公式(1):
(1)
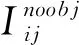
2.3 K均值重構初始Anchors
基于錨框的檢測算法為加快邊界框回歸速度,在訓練之前需根據數據集的不同手動設置初始先驗框。針對本文采用的數據集,實驗前采用K均值聚類算法計算不同聚類數量下對應的平均交并比,具體結果如圖2。
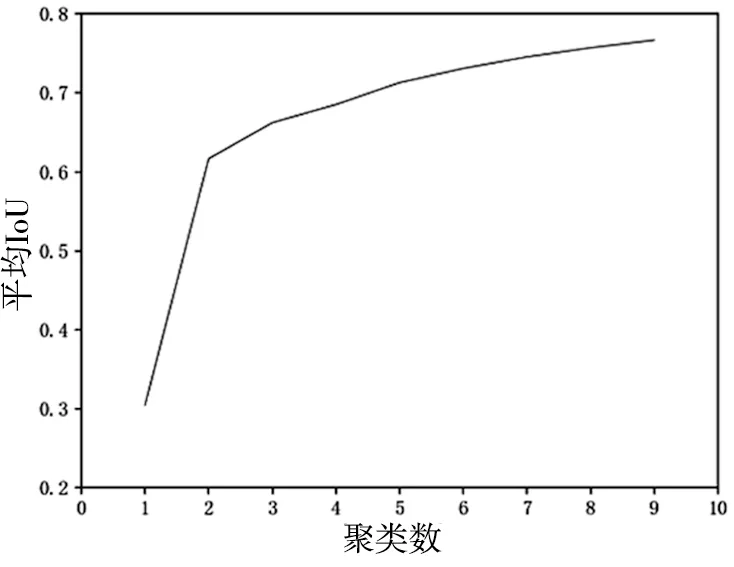
圖2 聚類數量與IoU變化圖
從圖2可以看出,平均IoU值在聚類個數為3之后增長逐漸放緩,因此本文實驗選擇聚類個數為3,初始Anchor Boxes設為:(11,12);(16,21);(29,30)。
2.4 調整邊界框過濾規則
基于錨框的算法在最終檢測階段會產生許多分數不同的邊界框(Bounding Box),對于一個檢測目標可能會檢測出多個邊界框,而最終檢測結果只需其中一個。Neubeck等[15]提出非極大值抑制算法(Non-Maximum Suppression,NMS)可以過濾掉多余邊界框,僅保留精度最高的邊界框作為檢測結果。NMS先計算邊界框之間的IoU值,然后手動設定閾值進行過濾。為解決上述問題,本文算法采用DIoU_NMS[16]作為邊界框過濾策略,DIoU是在IoU的基礎上添加邊界框中心點信息,當兩個邊界框IoU值較大而中心點距離較遠時,DIoU_NMS不會將其過濾,從而避免漏檢的情況。DIoU_NMS計算公式如下:
(2)
(3)
式中,d和c分別表示兩個邊界框的中心點距離和斜對角距離,通過調整β可以控制d和c的比值大小。當β值趨近于+∞時,DIoU逐漸轉為IoU;而β值等于0時,與目標中心點不重合的邊界框會都得到保留,因此β的選擇將直接影響最終檢測結果。
2.5 數據集
本文實驗采用車標數據集VLD-45-B[17],該數據集共有45個類別,如圖3。每個類別含有1 000張照片,共45 000張照片,所有圖片均采用現實場景中的車標圖片,因此該數據集可以較好地模擬現實中車標檢測場景。本次實驗將數據集劃分為3 6000張訓練圖片和9 000張測試圖片。

圖3 VLD-45-B數據集 車標類別圖片
3 實驗與分析
3.1 實驗平臺
實驗硬件環境為:CPU,Intel i5-10400F;GPU,NVIDIA Geforce RTX 2070;軟件環境為DarkNet框架,Cuda 10.1,cuDNN 7.6.5,OpenCV 4.3.0。
3.2 實驗設計與結果分析
實驗共分為三個階段。
(1)輸入尺寸對比實驗。實驗選取320×320、416×416和512×512三種輸入尺寸作為變量,測試模型精度與檢測速度,實驗結果見表2。
表中BFLOPs(Billion Float Operations)表示模型需要計算十億次浮點運算的個數,可表示模型參數的復雜度。從表2可以看出,320×320的輸入尺寸雖然模型參數較少,檢測速度最快,但精度較差;當輸入尺寸為512×512時,BFLOPs相比320×320增加近一倍多,檢測速度同時降低,最終檢測精度最高,但是mAP@0.75相比416×416輸入尺寸僅僅提升1.4%,BFLOPs卻增加51%,為平衡檢測準確率和檢測速度,本文算法采用416×416作為模型輸入尺寸。
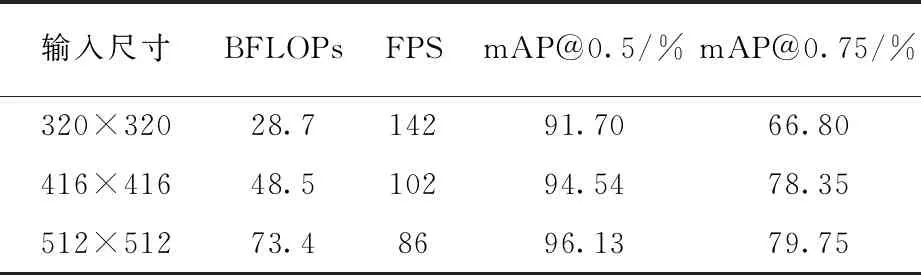
表2 輸入尺寸實驗結果
(2)邊界框過濾策略對比實驗。實驗分別采取NMS和DIoU_NMS兩種過濾策略,同時對DIoU_NMS計算公式(3)中的參數進行調整,根據結果選擇最佳的邊界框過濾策略,實驗結果如圖4。

圖4 NMS對比實驗結果圖
從圖4可以看出,當采用DIoU_NMS過濾策略時,mAP@0.75相比普通NMS提高約1%,表明DIoU_NMS可以明顯提升模型精度;當參數值設定為0.2時,可以達到最佳的檢測精度,此時相比普通NMS過濾策略mAP@0.75提升接近2%。因此本文算法選取DIoU_NMS作為算法邊界框過濾規則,同時調整值為0.2。
(3)經典算法對比實驗。本文實驗選取了YOLOv3、YOLOv4、SSD300、Faster R-CNN和RetinaNet五種經典算法與本文改進后的算法進行對比測試。
對比實驗中,Faster-RCNN和RetinaNet兩種算法均采用ResNet-50作為特征提取網絡,同時添加FPN[18]進行特征圖增強;YOLOv3-SPP是YOLOv3添加SPP層[19]之后的模型,本次實驗也將其作為對比算法;SSD300采用300×300作為輸入尺寸,其余算法均采用416×416作為輸入尺寸;訓練輪數統一設置為90 000輪,batch size設置為16,最終實驗結果見表3。
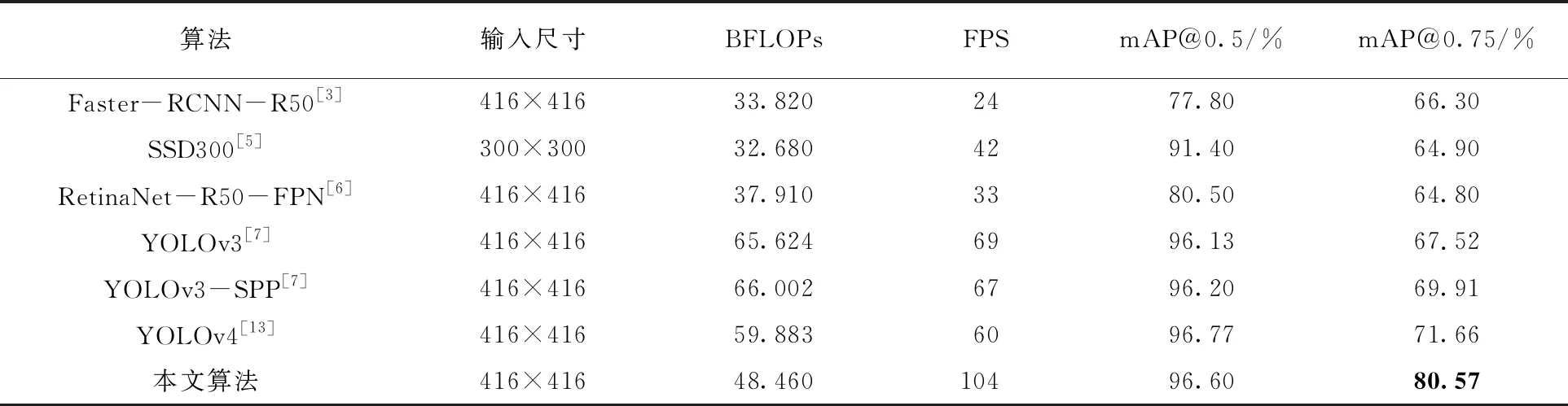
表3 車標檢測算法對比
從表3可得知,YOLOv4相比YOLOv3在車標檢測精度上有少量提升,模型參數卻更少,得益于層數更少的特征提取網絡和減少的輸出層,本文算法參數計算量較YOLOv4有所下降,最終檢測速度高于其他算法;通過對特征圖多次融合豐富特征信息、預設先驗框、改進損失函數和調整邊界框過濾規則操作后,本文算法雖參數更少,但精度仍保持較高水平,其中閾值要求更嚴格的mAP@0.75達到80.57%,準確率提升較為明顯。部分檢測效果如圖5。

圖5 部分檢測效果圖
4 結 語
本文提出一種基于YOLOv4的改進型車標檢測算法,采用層數較少的網絡結構,并對特征圖進行多次跨緯度融合,極大地豐富了預測層特征圖語義信息,選擇中尺度和小尺度特征圖輸入到檢測層;改進損失函數以緩解正負樣本不平衡問題;預設更加適合車標數據集的先驗框,從而加快模型收斂速度;選擇最優邊界框過濾規則并手動調整參數進一步提高模型精度。實驗結果表明,改進后的算法相比經典算法檢測速度大幅提升,同時也提高了檢測準確率。由于本文算法更加注重檢測中小尺度車標,隨著目標尺度增大,檢測效果會逐漸降低,之后的研究將在增加多尺度車標數據集的同時,進一步改進算法使其更好地適應多尺度車標檢測。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
