面向課后服務科普聊天系統的設計與實現
2022-05-25 01:53:48吳中其陳雋淇馬啟偉林芷泳黃貝苗
大科技 2022年20期
吳中其,陳雋淇,馬啟偉,林芷泳,黃貝苗
(華南師范大學軟件學院,廣東 佛山 528225)
0 引言
2021 年,中共中央辦公廳國務院印發《關于進一步減輕義務教育階段學生作業負擔和校外培訓負擔的意見》[1]。該政策結合了校外減負及校內減負兩個方面,能夠切實地進行減負工作。但與此同時,如何引導中小學生開展探究性學習活動成為當下需要考慮的重要問題。
本文圍繞本系統對系統的功能設計、深度學習模型、前端架構設計、數據庫設計與后端架構設計這五個方面進行闡述。使用Qt 設計前端界面,選用GPT-2 模型作為本系統對話模型,采用了Python Flask 框架構建后端系統進行本系統的設計。
1 系統模塊設計
科普聊天系統主要分為登錄/注冊、科普聊天、班級學習排名、班級學習情況統計和收藏夾5 個模塊。
(1)登錄/注冊:為滿足系統需要記錄用戶的學習情況并為其提供個性化服務,用戶訪問本系統都需要在該模塊進行登錄。若用戶沒有賬戶,需在該模塊進行注冊。
(2)科普聊天:用戶可以通過語音輸入或者文字輸入的方式與系統進行對話。在對話過程中,系統將通過對用戶輸入的內容進行分抽取,結合數據集中的科普背景知識生成流程的回答,通過多輪的對話讓用戶在無形中學習新知識。
(3)班級學習排名統計:該模塊以用戶在科普聊天模塊中所累計的積分為主,用戶的學習時長為輔,對每個用戶進行學習情況排名,以激勵用戶的學習熱情。
(4)學習情況統計:該模塊統計用戶當日的學習情況并實時展現給用戶,同時還將展現同組內其他用戶的當日學習情況,通過橫縱對比更加深刻的了解自己的學習情況。
(5)收藏夾:當用戶在和系統對話的過程中,如果用戶覺得系統科普的內容自己還未掌握或者科普內容值得再次查看即可直接右鍵點擊對話內容選擇收藏該對話,并在收藏界面進行查看,同時用戶還可以將不再需要的內容取消收藏。
2 深度學習模型與數據集
2.1 GPT-2 模型介紹
GPT-2 模型[2]由多層單向Transformer 的解碼器部分構成,本質上是自回歸模型。GPT-2 憑借其穩定、優異的性能吸引了業界的關注。GPT-2 在文本生成上有著驚艷的表現,其生成的文本在上下文連貫性和情感表達上都超過了人們的預期。使用GPT-2 作為我們系統的對話模型具有合理性。
2.2 KdConv 數據集介紹
數據集方面,本文選取了Zhou 等學者[3]在知識驅動的中文多輪對話數據集KdConv 一文中構建的數據集。由于KdConv 數據集結構與GPT-2 模型的所需的輸入有所不同,因此本文提取了該數據集中的有效數據,并進行了適應性修改。
經訓練后,模型具備了在流暢應答的前提下進行科普的能力,可以滿足大多數場合中的對話需求。
3 聊天系統的實現
3.1 前端架構設計
QT 具有良好的跨平臺特性,能夠支持Microsoft Windows95/98、Microsoft Windows NT、Linux、Solaris、SunOS 等眾多操作系統。除此之外,Qt 具有良好的封裝機制,具有良好的可重用性,能為開發人員提供遍歷。基于上述理由,本文使用Qt 技術來實現系統的前端模塊。
本項目使用組件化開發,減少代碼冗余,將整個前端項目分成頁面邏輯層、數據請求層和路由轉發層。頁面邏輯層負責進行響應,接收用戶提供的文本數據;數據請求層負責接收并向后端發送文本數據,獲取請求結果;路由轉發層則負責進行頁面跳轉,以及在每次跳轉時驗證用戶信息,阻止無權限訪問。用戶使用軟件流程圖如圖1 所示。
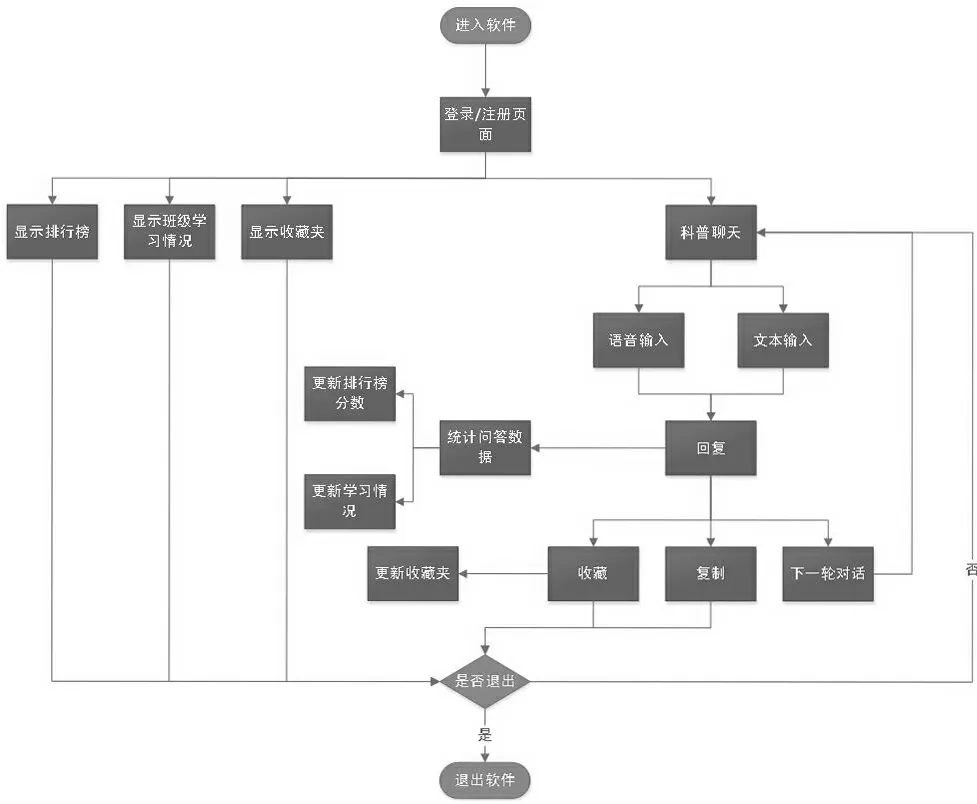
圖1 用戶使用軟件流程
3.1.1 登錄/注冊模塊設計
(1)注冊過程。注冊模塊通過前端獲取用戶注冊信息,對信息加密后傳輸到系統的后臺服務器中。服務器進行數據合法性驗證后,通過查詢數據庫數據判斷用戶的注冊信息是否重復,若不重復則動態生成SQL 語句將用戶信息插入數據庫表中,注冊模塊工作流程如圖2 所示。
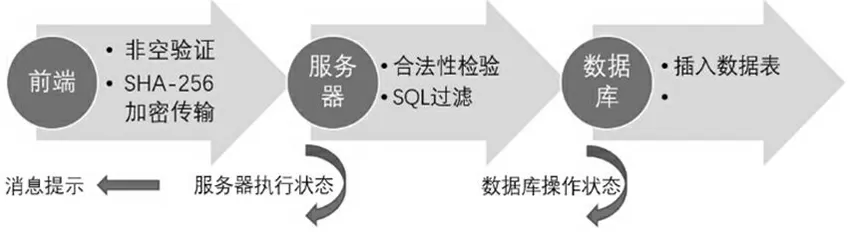
圖2 用戶注冊模塊工作流程
(2)登錄過程。注冊模塊通過前端獲取用戶登錄信息,并將其輸入信息上傳至后臺服務器。服務器進行數據合法性驗證后,通過查詢數據庫數據判斷用戶的賬戶信息是否存在,及登錄口令是否正確,若存在且正確,根據用戶名簽發token,默認狀態下有效期為3h,超過3h 后token 失效,需要重新登錄。圖3 為用戶登錄模塊工作流程。

圖3 用戶登錄模塊工作流程
3.1.2 語音模塊設計
語音模塊使用Python Pyaudio 工具庫進行基本功能的實現,并根據程序需求封裝為utils/audioManager 模塊。該模塊內實現了申請音源輸入設備、申請音源輸出設備、寫音頻文件及讀音頻文件。其中utils/audioManager.recording 方法實現了自動錄音,可根據讀取音頻流的能量大小,動態判斷語音輸入是否結束。
3.1.3 對話模塊設計
采用GPT-2 模型實現我們的對話系統模塊,以這種方法構建對話系統,則可以在生成高信息量同時又不失流利的回復。對話模塊可視化頁面如圖4 所示。
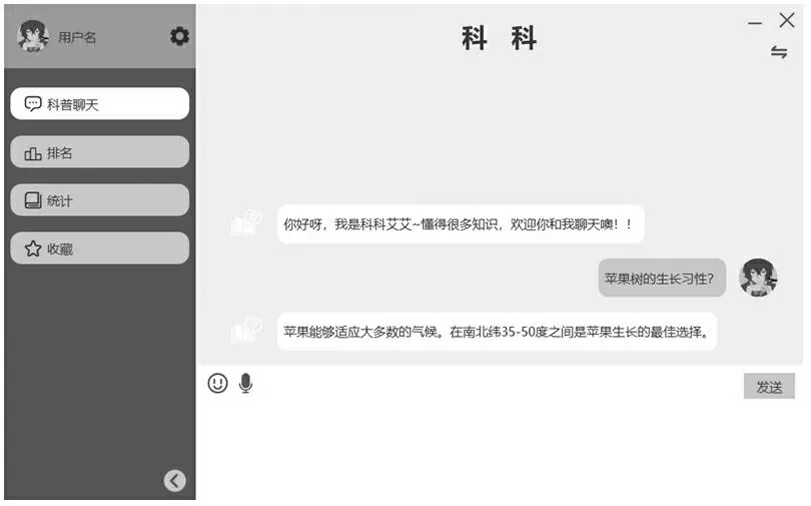
圖4 用戶聊天界面
用戶可以通過在輸入框中打字與機器人聊天。如果語句中出現好的知識點,可以點擊語句進行收藏,收藏后的語句將會存儲在收藏模塊中。此外,每次對話都將會累計得分,并將得分的變化存儲在班級學習情況中。如果使用教師賬號進行登錄,還能夠查看班級學習排名。
3.2 數據庫設計
本文采用MySQL 關系型數據庫對系統的進行設計。在該系統的數據庫中,本文以學生、教師對象是系統的主體,在數據庫中以用戶名作為唯一標識符,并通過用戶名與對話、組(班級)以及收藏進行對應。對話設計為弱實體,依賴于學生實體而存在,屬性包括了一句對話輸入、一句對話輸出以及對話發生的時間等。科普聊天系統數據庫的E-R 圖如圖5 所示。整個系統實體的數據冗余程度在可接受的范圍內,基本兼顧了查詢效率和存儲性能。
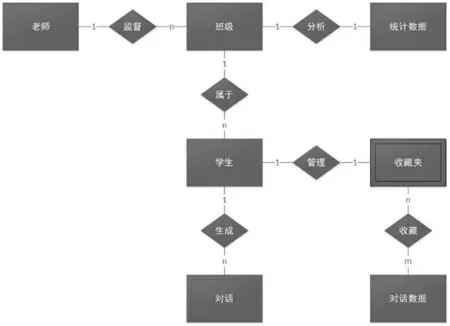
圖5 科普聊天系統數據庫的E-R 圖
3.3 后端架構設計
在后端框架中,本系統可以分為四個部分:數據傳輸層,數據處理層,數據庫接口層和安全層。其中,數據傳輸層負責獲取和提交前端數據;數據處理層負責請求數據庫數據以及對數據進行處理;數據庫接口層實現對數據庫的訪問接口;安全層負責驗證用戶合法性以及攔截惡意請求等功能。
系統的實現采用了Python Flask 框架,同時配合使用Flask 中的SQLAlchemy 擴展進行ORM 映射,將數據庫表映射為Python 中的實體。
安全層中實現了用戶的Token 驗證模塊。前端獲取服務時需要帶上Token,本模塊會驗證Token 是否過期。對于合法發放Token 并且Token 有效的請求,后端才會響應。
4 結語
國家“雙減”政策的全面推行,對中小學校教育教學質量和服務水平的要求進一步提高,填補課后服務需求缺口成為學校的一項重要工作。本文設計了能夠為中小學生提供優質的、富有趣味的科普知識資源的系統,填補中小學校在課后服務資源方面的需求和缺口。我們在后續將會繼續改進該系統,讓本系統在更大程度上更加能貼合個性化發展需求,進而促進個人的全面發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
