
面向智慧文博的知識圖譜構建綜述
2022-05-26 08:56:02張浩然
軟件導刊 2022年5期
趙 卓,田 侃,張 殊,張 晨,吳 濤,張浩然
(1.重慶中國三峽博物館文物信息部,重慶 400015;2.重慶郵電大學網絡空間安全與信息法學院,重慶 400065)
0 引言
隨著社會經濟的發展和生活水平的不斷提高,人們越來越重視精神生活,也更加有條件享受豐富多彩的精神文化產品。博物館是征集、典藏、陳列和研究自然遺跡和人類文化遺產的場所,擁有大量具有科學性、歷史性和藝術價值的物品,能夠為公眾提供知識、教育和公益性文化服務[1]。如何讓文物活起來,使博物館成為公共文化服務體系的重要載體,成為大眾終身學習的精神課堂,是近年來社會對博物館行業的普遍期望,也是博物館行業的重要工作方向。如何更好地挖掘傳播地區歷史文化、創建具有吸引力的文化產品以及提供良好的公共文化服務是博物館工作的重要訴求。
圍繞文博行業現狀以及社會實際需要,我國頻繁出臺文物保護和博物館建設的政策,使文博行業能更好地服務于國家文化發展需要,滿足人民群眾精神文化需求。2015年2 月,國務院發布了《博物館條例》,鼓勵博物館向公眾免費開放。2016 年3 月,國務院印發的《關于進一步加強文物工作的指導意見》倡導大力發展文博創意產業。2017年4 月,文化部出臺《文化部“十三五”時期文化科技創新規劃》,提出要實現我國文化、藝術與科技的融合。實際上,通過近20 年的信息化建設,博物館數字資源數量、質量穩步上升,藏品資源、藏品管理、多媒體展示、專用業務系統等均取得了不斐成績。然而,隨著大數據、人工智能等新興技術的出現,科技與文化融合成為博物館領域新的發展趨勢,智能化技術應用成為未來博物館發展的必由之路。
知識圖譜以結構化的形式描述客觀世界中概念、實體間的復雜關系,提供了一種高效組織、管理海量信息的方式。傳統的圖像、語音等人工智能領域主要關注感知智能,而知識圖譜的重點在于通過知識與模型的融合實現認知推理,支持高水平的知識表示與計算。目前,知識圖譜通過與問答、搜索、推薦等應用相結合已被廣泛應用于金融、醫療、電商等領域。為顯著提升文化遺產傳承能力,本文聚焦適合博物館的知識圖譜系統構建問題,首先對文博領域知識圖譜系統的構建過程和方案進行概述,然后介紹知識圖譜構建的主要流程和關鍵技術,最后對未來值得關注的研究方向進行初步探討。
1 文博知識圖譜研究現狀
知識圖譜在文化、博物館領域的應用處于起步階段,取得了一定研究成果。例如,張建星[2]研究了基于大數據環境的中國傳統文化知識圖譜構建框架,設計了由事件、人物、時間、地點、社會背景、文化領域六元組組成的中國傳統文化本體模型,構建了中國傳統文化知識庫;萬靜等[3]介紹了知識圖譜在國內外的研究應用情況,探討了其在智慧博物館建設中的初步應用設想;張娜[4]針對當前文物知識圖譜依賴于人工構建、缺乏自動化方法的問題,對文物知識圖譜構建過程中的文物關系自動抽取技術進行了研究,設計并實現了完整的文物知識圖譜構建與展示方案;劉芳等[5]設計了以藏品、多媒體、展覽、項目、人員、機構、文獻等實體為核心的知識圖譜,探討了知識圖譜在檢索優化、智能推薦、可視化展示和智能問答領域的應用方式;楊偉強[6]以山西博物院專家選取的100 件具有代表性的館藏文物作為構建知識圖譜的基礎性文物擴展相關知識節點,通過與領域專家合作,提出用于知識表達的本體模型和標準規范,采用構建文物知識圖譜的形式形象地展示文物知識的結構及其之間的聯系;劉紹南等[7]提出利用文物知識圖譜對不同來源、不同格式的海量文物數據進行分析、展示和利用,然后基于語義檢索、推薦和問答開發等典型應用支撐智慧博物館的建設。
2 系統架構與知識建模
2.1 系統架構
以文博知識圖譜構建為目標,聚焦人物、文物、遺跡、建筑、交通、書畫等數據,在收集相關古籍資料、研究成果、學術文獻、網絡資源等基礎上,綜合利用自然語言處理、數據挖掘、深度學習以及圖計算等技術進行數據分析與知識抽取,整體知識圖譜系統構建框架如圖1 所示。具體階段介紹如下。

Fig.1 Framework of knowledge graph cultural museum system construction圖1 文博知識圖譜系統構建框架
(1)數據存儲與訪問架構設計。數據采集平臺能夠獲得大量來自考古、交通、宗教等不同領域的文博數據,這些數據往往具有來源廣泛、規模龐大、種類繁多、非結構化等特征,現有平臺的存儲方式無法很好地支持如此復雜數據的高效查詢和分析。如果孤立地管理這些數據,會直接影響平臺運作效率和效果。因此,除了對每類數據單獨索引外,還需要對多源異構數據進行特征學習,建立混合式索引,以提高數據訪問效率。
(2)知識特征提取。針對考古、交通、軍事、宗教等不同領域的數據,通過自然語言處理、機器學習領域前沿理論模型,構建多源異構數據的知識特征提取與融合方法,進行文化數據的知識抽取,將多源異構數據轉化為統一的知識表達形式。
(3)知識庫構建。根據數據的結構特征,在數據庫知識抽取的基礎上,建立文化數據知識表達模型,對文物、環境、歷史文獻、考古資料、歷史事件等海量、多源、異構的文化數據進行規范化組織,使文物知識可檢索、可計算、可自動關聯,形成文化數據標準知識庫。
(4)文化知識圖譜構建關鍵技術研究。研究實體識別、關系抽取、實體鏈接、推理補全、語義消歧等理論與技術,為知識圖譜系統的構建提供理論與技術支撐。同時,分析面向知識圖譜構建文博數據的特性問題,展開針對性研究以突破技術瓶頸。
(5)知識圖譜系統構建。遵循統一、集約、高效、規范的原則,構建允許知識檢索、關聯挖掘、可視化呈現的知識圖譜系統,支持可移植、跨平臺、可配置的需求,自動抽取半結構化文本中的屬性和值,實現知識審核與校對,形成知識圖譜更新管理機制,建立運營管理體系。
2.2 知識建模
文博知識圖譜構建以古籍資源、學術文獻、文物信息等數據資源為依托。文物資源包含石刻、建筑、書畫、交通、軍事、考古等,各類文物有相關的金石著錄、發掘報告、研究論文、著作等材料對其進行描述介紹,每個文物都具有差異化的屬性、特質。古籍資源往往以神話傳說、歷史事件、民間故事等形式介紹歷史知識文化,具有故事差異性大、內容龐雜的特點。著名人物數據包含出生于或曾到過各個地區的書畫家、詩人,以及與之相關的交通、軍事事件等。文化旅游數據包含著名地點以及與之相關的歷史事件、名人等,涉及文物、古籍、歷史和名人等信息。基于以上內容分析,文博數據知識表達模型如圖2所示。

Fig.2 Cultural data knowledge representation model圖2 文博數據知識表達模型
2.3 數據組織與處理規范
為了進行文博題刻知識圖譜的構建,本文收集整理大量歷史文化數據,其中題刻數據示例如圖3 所示,其文字內容為:“涪江石魚,鐫于波底,現則歲豐。數千百年來,傳為盛事。康熙乙丑春正,水落而魚復出。望前二日,偕同人往觀之,仿佛雙魚莫蓂蓮隱躍。蓋因歲久剝落,形質模糊,幾不可問。遂命石工刻而新之,俾不至湮沒無傳,且以望豐亨之永兆云爾。時同游者舊黔令、云間杜同春梅川,州佐、四明王運亨元公,旴江吳天衡高倫,何謙文奇,西陵高應乾侶叔,郡人劉之益四仙,文珂奚仲。涪州牧旴江蕭星拱薇翰氏記略。”

Fig.3 Example of Xiao Xinggong reengraving double fish rubbing圖3 蕭星拱重鐫雙魚記拓片示例
可以看出,文博數據具有較強的歷史性和專業性特征,傳統的知識圖譜技術無法直接應用于文博數據處理,需要設計合理的文博知識圖譜構建方案。在查閱相關文博資料的基礎上,綜合分析不同數據組織形式的優缺點,設計用于文博知識圖譜構建的數據組織與處理規范,如圖4 所示。總體來說,基于關系型數據庫實現結構化數據的簡單、高效檢索,基于實體、關系與屬性抽取技術實現數據的結構化處理,基于圖數據庫實現復雜關聯數據的存儲與檢索。通過該數據組織與處理規范,可以對文博數據資源進行預處理和標準化存儲,以支撐數據的知識表達與高效計算。
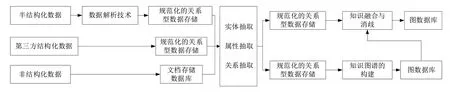
Fig.4 Data organization standard for the construction of cultural relic knowledge graph圖4 文博知識圖譜構建的數據組織與處理規范
3 文博知識抽取方法
3.1 命名實體識別
命名實體識別(Named Entity Recognition)又稱為實體識別,其對知識圖譜的構建具有重要意義。命名實體是一個詞或短語,命名實體識別是指在輸入文本中識別具有特定屬性的實體。在文本被識別為實體后,開發人員可以對不同類別的實體執行各種操作。傳統的命名實體識別方法主要包括基于規則的方法、知識庫方法、監督學習方法和半監督學習方法。早期由于計算能力限制,知識庫方法和基于規則的方法被廣泛使用,多通過維護專門的詞典庫或由專家根據專門詞匯的特點構建規則以識別命名實體。一般來說,每個規則都有一個權重,發生規則沖突時,權重最高的規則用于確定命名實體的類型。基于規則的實體識別系統通常需要使用實體字典進一步確認候選實體。當字典內容詳盡時,基于規則的系統運行良好。然而,基于特定領域和不完備字典的規則往往導致命名實體識別系統召回率低,且這些規則難以適用于其他領域。近年來,機器學習被廣泛應用于各種自然語言處理任務中,并取得了巨大成功。與知識庫和基于規則的方法相比,機器學習方法減少了大量人工干預,具有優越的可移植性。基于機器學習模型的命名實體識別方法會預先標記語料庫作為訓練集,并通過訓練模型學習相關特征識別實體。
知識圖譜命名實體識別中最具代表性的方法為BERT預訓練模型[8-9]和Bi-LSTM 與CRF 的融合模型[10-11]。Bi-LSTM 與CRF 的融合模型是在Bi-LSTM 的條件上加了一層條件隨機場作為模型的解碼層,以預測結果的合理性。同時,由于文博數據的專業性和特殊性,基于常見標記語料庫的實體識別模型無法完全有效識別數據中存在的文物、古籍、年號、官職等專業術語與歷史名稱。因此,本文通過爬蟲、文本分析等方法構建功名、官職、年號、節日等專有名詞庫,示例如圖5 所示。然后,結合基于知識庫和算法模型的方法進行命名實體識別,從而支撐文博領域實體信息的準確識別與發現。
3.2 知識圖譜關系抽取

Fig.5 Example of proper nouns for official positions圖5 官職專有名詞庫示例
關系抽取(Relationship Extraction)是指在命名實體識別之后,根據句子中的語義信息學習實體間的關系。準確的關系抽取有利于構造邏輯結構清晰的圖譜[12-13]。基于規則的關系抽取方法通過語言學知識對文本結構抽象出一個固定的模式集,并對給定的文本進行模式匹配以確定其中關系。總體上,傳統的關系抽取方法需要大量人力設計特征,難以應用于大規模的關系抽取任務。近年來,基于深度學習的關系抽取模型被提出,其可自動學習有效的關系特征。目前主流的深度學習關系抽取方法包括基于卷積神經網絡模型的關系抽取方法[14-17]、基于循環神經網絡模型的關系抽取方法[18-20]以及基于詞法句法模型的關系抽取方法[21-23]。然而,深度學習模型往往需要大量已標記訓練數據。為解決訓練數據短缺問題,降低模型訓練成本,遠程監督(Distant Supervision)模型方法被提出[24]。此外,為降低命名實體識別錯誤對關系抽取準確率的影響,實體關系聯合抽取方法[25-27]被提出。
為進行文博數據中實體關系的準確抽取,本文提出基于規則的方法以及基于正反向迭代式消除的方法。文博數據中書名、字號等信息往往標識性強、規則清晰,在獲取人名、地名等實體的基礎上,基于簡單規則即可準確發現人物字號、官職等關系信息。而對于語句中的復雜關系,本文提出首先進行實體和屬性識別與消除、然后在剩余內容中正、反雙向識別語義關系的迭代式解決方案。
3.3 知識圖譜關系推理
知識圖譜關系推理(Relationship Inference)是指基于已有的知識圖譜結構和內容信息推理出新的知識或識別錯誤知識的過程,可解決文博領域數據稀疏的問題,并削減數據質量不高對知識圖譜準確率和完整性的影響。知識圖譜關系推理方法主要包括基于規則的方法、基于結構相似性估計的方法、基于結構建模的方法以及基于知識表示的方法。其中,基于規則的關系推理主要通過文博數據本體模型中的相關約束和規律進行推理;基于結構相似性估計的方法主要包括共同鄰居方法、資源分配方法、局部路徑法等;基于結構建模的關系推理方法借用網絡數據分析領域的模型算法,包括標記傳播(Label Propagation)方法、隨機行走(Random Walk)方法、圖神經網絡模型(Graph Neural Networks)等;基于知識表示的方法首先對知識圖譜中的實體和關系進行降維表示,然后基于表示結果直接計算實體之間存在關系的可能性。知識表示學習方法通過機器學習算法自動從數據中獲得知識表示,能夠根據具體任務學習到合適的特征。目前,最具代表性的知識表示方法包括TransE[28]、TransH[29]、TransR[30]以及TransD[31]。
本文提出不同顯著性的文博知識圖譜關系,采用結構相似性估計方法、圖神經網絡模型方法以及基于卷積特征表示的少樣本學習方法進行知識圖譜的關系推理。具體來說,對于局部性、顯著性強的潛在關系,采用結構相似性估計方法進行預測;對于大范圍的復雜結構關系,基于圖神經網絡模型方法進行結構建模和學習,然后利用學習到的結構模式指導潛在關系的推理預測。由于知識圖譜中的關系往往存在長尾現象,即關系數量主要集中在少數幾種類型上,其他類型的關系數量較少,不利于建模學習,本文提出基于少樣本學習的知識圖譜關系推理方法。
4 基于Neo4j的知識圖譜構建
知識圖譜數據應用的前提是關聯數據的有效表示和存儲,其數據模型主要分為三元組和圖模型兩種[32]。圖數據庫因其對節點間復雜關系的良好支持而成為多數知識圖譜的首要存儲選擇。
圖數據庫中,數據的基本元素包括節點集合與關系集合。關系型數據庫能夠較好地凸顯單條數據的內容和存儲情況,而圖數據庫以非結構化的方式存儲關聯數據,可以直接顯示數據的關聯特征,在知識圖譜關系查詢中效率更高。目前代表性圖數據庫包括Neo4j、JanusGraph、GraphDB、HugeGraph 等[33]。本文選擇能夠輕松表示關聯數據的Neo4j,其操作簡便靈活。基于Neo4j,本文構建的部分知識圖譜結果如下。
示例1:與“進士”相關的人物包括“劉心源”“趙熙”“寇凖”“陳文燭”“龐恭孫”等,其中每個人物又有相關的實體和關系。例如,人物“寇凖”涉及到書籍《十朋梅溪后集》以及官職“校書郎”,由此形成了以“進士”為中心的知識圖譜,具體如圖6所示。

Fig.6 Knowledge graph centered on"Jinshi"圖6 以“進士”為中心的知識圖譜
示例2:與“蕭星拱觀石魚記”直接相關的人物包括“蕭星拱”“陳曦震”等,其中每個人物又有相關的實體和關系。例如,人物“蕭星拱”涉及到書名《清蕭星拱傳記》以及官職“郡守”,以“蕭星拱觀石魚記”為中心的知識圖譜如圖7所示。
5 文博知識圖譜的應用與管理
5.1 知識圖譜的應用

Fig.7 Knowledge graph centered on"Xiao Xinggong view stone fish"圖7 以“蕭星拱觀石魚記”為中心的知識圖譜
知識圖譜是融合數據與算法的新型知識表達形式,其可將數據中的知識組織成<主,謂,賓>三元組的形式以表征客觀世界中實體之間的關系[34]。基于知識圖譜的可視化技術可以構建直觀的數據展示系統,優化用戶交互體驗;基于知識圖譜的推薦系統可以利用圖譜中的關系推理用戶的興趣偏好,同時支持對推理過程和推薦結果的解釋;基于知識圖譜的搜索避免了傳統機械的關鍵詞匹配搜索形式,能夠根據人們的思考習慣檢索查詢相關信息,給出直接的答案;基于知識圖譜的問答系統能夠將問題邏輯解析到知識圖譜中,通過推理計算直接給出問題答案。
文博知識圖譜構建的主要目標是解決長期以來文博領域舊拓資料散落各地而無法形成一套完整體系的問題。收集、整理特定主題的數據資料,通過數據清洗、整合以及知識圖譜構建,自動化形成較為完整的知識體系,有助于文化遺產的科學發掘[35]。同時,通過知識圖譜構建以及可視化展示,能使觀眾直觀地了解歷史文化知識,提升其觀感體驗,更好地傳播歷史文化知識。具體示例如圖8所示。

Fig.8 Example of visualization for cultural knowledge graph圖8 文博知識圖譜可視化展示示例
5.2 知識圖譜的運營管理
知識圖譜的運營管理是指在知識圖譜初次構建完成后,根據用戶的使用反饋以及不斷出現的新知識進行知識圖譜演化和完善的過程,更新過程中需要保證知識圖譜的質量可控以及內容豐富衍化。
知識圖譜的運營管理是一個體系化工程,覆蓋了知識獲取到知識計算的整個生命周期。知識圖譜的運營主要有兩個關注點:一個是基于增量數據的知識圖譜構建過程監控,另一個是通過知識圖譜的應用發現知識錯誤和新的業務需求,例如錯誤的實體屬性值、缺失的實體間關系、未識別的實體、重復實體等問題。總體來說,知識圖譜運營管理需要用戶反饋、專家修正、運行監控、算法調整更新等相結合,是一個人機協同、領域專家與算法相互配合的過程。
6 結語
作為人工智能的重要應用之一,近年來知識圖譜受到各個領域的廣泛關注。文博系統是國家精神文明建設的重要領域,如何結合前沿科技實現文化創新成為其當前面臨的重要問題。文博領域數據資料體量龐大且零散,文博知識圖譜的構建對于博物館的智能化建設、智慧文化產品開發具有重要支撐作用。然而,相關學者雖然對知識圖譜的理論與應用問題進行了研究,但針對文博知識圖譜構建的研究仍然較少。
本文剖析了文博知識圖譜的背景、內涵及發展現狀,提出了基于多源文化數據進行文博知識圖譜構建的系統架構、知識模型以及組織規范,基于實體識別、關系抽取、關系推理等關鍵技術展示了基于圖數據庫的知識圖譜構建方法,然后介紹了知識圖譜的應用以及現實運營管理問題。需要注意的是,由于文博領域數據的專業性與稀疏性,直接應用常規知識圖譜關鍵技術往往不能獲得滿意結果。例如,前期本文進行了DeepDive 等知識圖譜構建工具的測試,但結果并不令人滿意。因此,文博知識圖譜構建需要結合文博數據特征進行針對性的理論與技術研究。為了面向文博知識圖譜的特征提出針對性解決方案,同時保留進一步創新優化的可能性,本文給出了文博知識圖譜構建的初步技術并基于相關前沿算法進行了實現與優化,未來將在此開放式方案的基礎上進一步優化與提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
