基于隨機距離預測的高鐵客流需求研究
2022-05-30 04:29:42紀宇宣蔣秋華朱穎婷
計算機技術與發展 2022年5期
紀宇宣,蔣秋華,朱穎婷
(1.中國鐵道科學研究院研究生部,北京 100081;2.中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081;3.北京經緯信息技術有限公司,北京 100081)
0 引 言
高鐵線路增加,鐵路網規模擴大改變了原有路網的結構,拓展了大量新增客起訖點(Origin-Destination,OD)。了解不同OD之間旅客的真實需求量,挖掘熱門OD需求,分析城市之間客流出行的特征和規律一直是鐵路部門致力研究的重點內容之一。
近年來,一些學者已經開展了對不同交通方式下OD客流分析的研究。文獻[1]通過對滬寧沿線高鐵站點進行客流行為特征分析,建立了上下凈客流量模型,并分析了站點與客流量對周邊的影響和站點及中心城區的關系;文獻[2]利用層次聚類法對高速鐵路OD客流進行分類,構建了OD服務水平的量化指標體系;文獻[3]對空鐵聯運OD進行分類,根據客流數據建立了Logit模型,并給出空鐵聯運的服務特性指標取值方法;文獻[4]以單日OD概率矩陣為樣本,利用系統聚類和快速聚類法,將工作日劃分為五類,為行車計劃提供決策支持;文獻[5]針對鐵路OD客流受季節性因素影響的問題,提出了一種同時考慮周和月的季節指數計算方法,該方法為鐵路客運量預測提供了重要的理論依據。目前主要是針對OD的客流影響因素進行研究,而對于熱門OD客流特征的研究較少,并且目前的研究多數是以實際客運量或訂單量進行分析,在一定程度上存在著局限性,難以準確反映旅客的實際需求。而余票查詢[6]服務是旅客使用互聯網售票系統完成車票預訂、改簽的前置業務環節,由鐵路客運官方服務平臺12306提供,可以反映乘客對線路的需求程度。
此外,針對余票查詢服務的特征較多,如何抽取更有效的特征集合是亟需解決的問題。使用聚類算法[7]在處理高維數據時魯棒性較差,需要使用降維技術進行特征重構。文獻[8]針對交通客流路線設計問題使用了PCA K-means算法對交通路口數據進行聚類挖掘,然而使用PCA算法不能較好地保留樣本之間的距離信息。因此,為了盡可能真實地貼近旅客出行需求,該文準確地分析不同類別OD客流的特征,提出一種基于隨機距離預測的OD客流特征分析方法。以挖掘熱門OD的特征為目標,運用一種基于隨機距離預測(RDP)原理的神經網絡對原始數據進行特征重構,而后采用K-means算法對重構特征進行聚類,并對聚類結果進行特征挖掘。
1 OD客流特征分析模型構建
1.1 OD余票查詢數據提取
京滬高速鐵路是中國運量最大、運輸最繁忙的高鐵,線路縱貫京、津、滬三大直轄市和冀、魯、皖、蘇四省,具有良好的客流基礎。全線共設24個車站,其中始發站有五個,分別為北京、天津、濟南、南京、上海,其余均為中間站。截至2019年9月,累計發送旅客10.85億人次。京滬高速鐵路具有需求量大、旅客多、車次多、途徑熱門城市多、路網地位重要等特點,因此該文以京滬高速鐵路為例進行熱門OD挖掘。
1.2 數據預分類
旅客需求在普通日期和假期往往差距很大,圖1給出了普通日期一周和五一假期前后兩天的余票查詢數據,以天為統計單位。
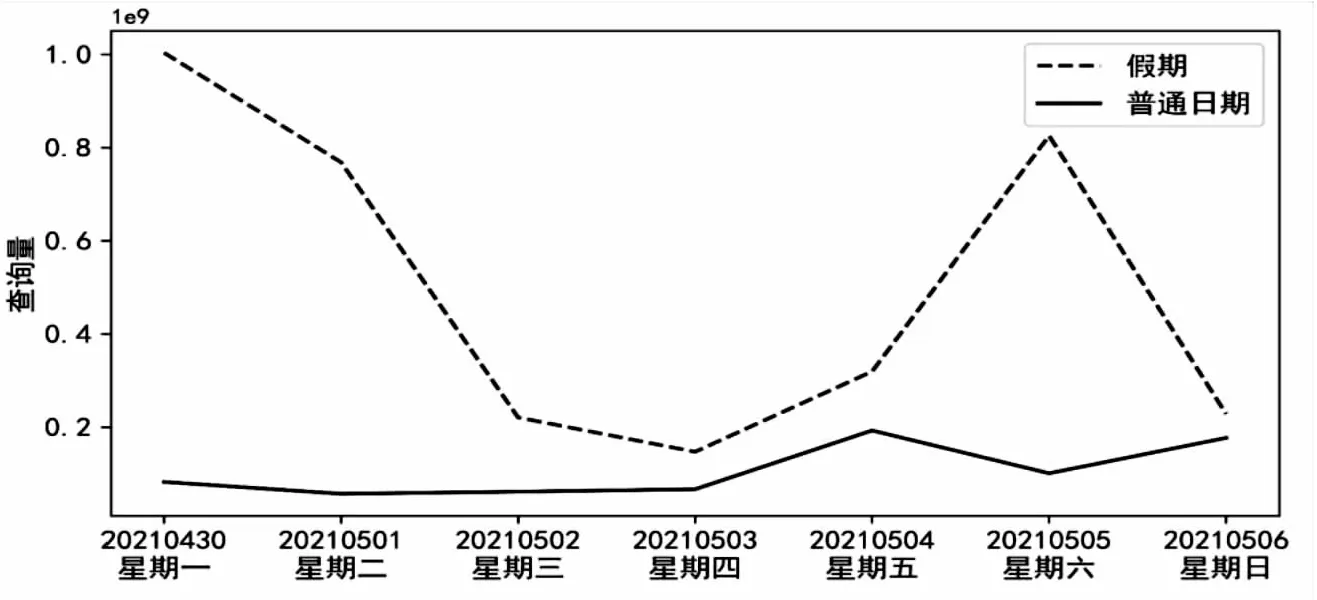
圖1 每日查詢量分布圖
從圖1可以看出,假期和普通日期余票查詢量走勢不同,假期的每日查詢量波動較大,普通日期相對平緩。普通日期查詢量在星期五和星期日達到高峰,點擊量在2×108左右,其他日期相對穩定,其點擊量基本為高峰期的1/2左右。假期余票查詢量高峰集中在假期前一天、假期第一天和假期最后一天,并且節假日的余票查詢量顯著高于普通日期查詢量,從兩者高峰期的數據來看,假期是普通日期的4~5倍。由此可見,應將旅客乘車日期按照假期和普通日期進行分類,對兩類數據分別進行聚類分析,并根據聚類分析結果分別表征不同乘車日期的OD客流特征。
1.3 聚類方法
1.3.1 原始聚類特征構建
12306客票系統在給旅客帶來便利的同時,也給第三方搶票軟件等互聯網黑商企業帶來商機。搶票軟件[9]通過不斷訪問余票查詢接口來刷票,導致部分用戶名或ip在短時間內訪問不同的OD,生成了大量余票查詢日志。因此單獨通過查詢量分析OD客流特征并不準確。需綜合考慮多種特征指標進行聚類分析從而劃分熱門OD。結合OD余票查詢日志數據和業務特點,選擇點擊次數、用戶名數、空用戶名數和ip數四類作為特征因素,其含義如表1所示。

表1 余票查詢特征因素
一般情況下,鐵路車票預售期為15天,在預售期內,不同OD的特征因素分布不同,圖2給出了不同OD預售期查詢量占比分布圖。從圖中可以看出,不同OD在預售期內的需求量差異較大,如OD1主要在預售期后3天時查詢量達到高峰,而OD2在預售期前3天的查詢量占比較高,可見,在分析OD客流特征時,預售期特征因素不可忽略。

圖2 不同OD預售期查詢量分布圖
結合上述分析,將預售期每天點擊次數、用戶名數、空用戶名數和ip數作為聚類分析的原始特征。
1.3.2 特征預處理
在構建原始特征之后,需先對數據進行標準化預處理[10],原始特征中的點擊次數、用戶名數、空用戶名數和ip數等特征因素處于不的數量級,如果直接使用原始特征進行聚類分析,就會突出數量級大的特征在聚類分析中的作用,削弱數量級小的特征在聚類分析中的作用。因此,選取特征歸一化方法來對原始數據進行預處理,使不同量級的特征處于同一數值量級,并加快算法的收斂速度,其公式如下所示:
(1)
1.3.3 聚類分析流程
歸一化預處理后,使用RDP算法將數據的高層特征提取出來輸入到K-means算法中進行聚類,并對聚類結果進行評估,最后根據OD數據的聚類結果進行統計分析從而得到OD數據的客流特征。聚類分析流程如圖3所示。

圖3 聚類分析流程
1.3.4 RDP K-means算法
(1)隨機距離預測模型RDP。
隨機距離預測(RDP)模型于2020年由Wang等人[11]提出。該模型是通過訓練神經網絡逐步逼近目標映射的方式來學習數據的底層結構,從而獲取數據的重構特征,是目前較新的一種數據特征重構的方法。這種方法可以在保留原始數據之間距離信息的同時,降低數據的維度,獲得數據的高層特征表示。
該文參考RDP模型,構建高速鐵路余票查詢量的神經網絡模型,其模型架構如圖4所示。

圖4 RDP模型架構
其中,RTargetNet為目標映射網絡,由一個簡單的全連接層表示;RNet為學習網絡,由兩個全連接層和中間的Dropout層構成。
OD客流特征數據訓練過程如下:將兩個歸一化后的OD特征xi和xj輸入到目標網絡RTargetNet得到高層的重構特征η(xi)和η(xj),再將xi和xj輸入到學習網絡RNet,得到與目標網絡輸出維度相同的兩個特征φ(xi;θ)和φ(xj;θ),分別計算兩類重構特征的內積為η(xi)·η(xj)和φ(xi;θ)·φ(xj;θ),將內積差的平方作為RDP模型的訓練損失函數,如公式(2)所示,通過學習網絡逐漸逼近目標網絡,使學習網絡獲得目標網絡的映射關系。
Lrdp=(η(xi)·η(xj)-φ(xi;θ)·φ(xj;θ))2(2)
此外,為了更好地保留OD數據的全局特征信息,引入自編碼器作為模型的輔助訓練,自編碼器的損失函數計算公式為:
Laux=(X-φ'(φ(X;θ);θ'))2
(3)
模型最終訓練的損失函數計算公式為:

η(xj))2+(X-φ'(φ(X;θ);θ'))2
(4)
通過不斷降低損失函數完成對RNet模型的訓練,最終RNet的輸出結果即為RDP模型輸出的重構特征。
(2)K-means算法。
將獲得的重構特征輸入K-means算法進行聚類分析,選擇合適的K值為各OD數據打上類別標簽,即將各OD數據劃分為相應的類別。
2 實 驗
2.1 實驗環境與數據
數據分析及算法軟件環境為Python3.7,深度學習框架應用Pytorch1.8.1。數據源于鐵路12306客票系統大數據集群,運用spark-sql腳本分別抽取京滬高速鐵路普通日期一周(星期一-星期日)和五一高峰期(2021.4.30-2021.5.6)的余票查詢日志數據作為OD客流特征分析的基礎數據。
2.2 RDP模型參數選取
以普通日期數據為例,原始數據集經特征歸一化處理后輸入RDP模型。RDP模型的輸入與OD原始數據集的特征維度相同,輸出維度主要通過訓練時的損失函數曲線和聚類結果進行選取,不同數據輸出維度不同,普通日期選取輸出特征為7。優化方式使用隨機梯度下降算法,學習率設置為0.01,Dropout值設置為0.03,用以防止模型過擬合。數據集的總訓練輪次(total_epoch)設置為500,每個輪次將數據隨機分為15個批次(epoch_batch),每個批次訓練200條OD數據(batch_size)。
2.3 K-means參數選取
將RDP模型訓練后的特征輸入到K-means算法中,分別設置不同的K值,并計算出簇內誤方差(SSE)值后繪制曲線(如圖5所示),依據手肘法[12]選取K=6作為簇個數。

圖5 SSE曲線
2.4 聚類方法評估
評判聚類算法的性能主要通過聚類算法的評價指標進行評判。聚類評價指標[13]主要分為內部評價指標和外部評價指標,其中外部評價指標需要使用已知真實標簽數據和聚類結果進行對比從而評判模型;而內部評價指標則通過數據集自身屬性特征進行評判,如簇間平均相似度或簇內平均相似度。該文數據未涉及真實標簽,適用于內部評價指標進行評價。論文選取Calinski-Harabasz(CH)指標、輪廓系數(Silhouette Coefficient)和戴維森堡丁指數(Davies-Bouldin Index)這三種內部評價指標來評判聚類結果。
其中CH指標通過計算類中各點與類中心的距離平方和來度量類內的緊密度,通過計算各類中心與數據集中心點距離平方和來度量數據集的分離度,CH指標越大則代表類自身越緊密,類間越分散,聚類效果越好。
輪廓系數分別通過計算樣本到簇內其他樣本的平均距離和樣本到其他簇所有樣本的平均距離來評判簇內相似度和簇間分離度。輪廓系數越大表示簇內樣本緊湊、簇間距離大,聚類效果越好。
DB指標用類內樣本點到其聚類中心的距離估計類內緊致性,用聚類中心之間的距離表示類間分離性。DB指標越小,聚類效果越好。
依據上述三種指標,分別對RDP K-means、PCA K-means、K-means、層次聚類[14]、密度聚類DBSCAN[15]等幾種算法進行評判,每個算法重復計算10次取評價指標均值,其中模型輸出類簇均相同,PCA輸出維度與RDP輸出維度相同,評估結果見表2。

表2 各方法聚類結果對比
從表2可以看出,RDP K-means算法的CH指標和輪廓系數均為最大且DB指標最小;相比于層次聚類算法和密度聚類算法,K-means算法的評價指標更好,證明K-means算法更適合余票查詢數據;從降維后的聚類效果來看,RDP K-means>PCA K-means>K-means,表明數據經過特征降維后,聚類的效果是最好的,所以在做熱門車次挖掘時采用該算法首先進行OD類別劃分。
2.5 聚類結果挖掘
選用RDP K-means聚類方法分別對普通日期和假期的高速鐵路余票查詢量進行聚類,并對聚類結果進行相關特征分析,特征參數包括:OD城市中間站占比、客流距離、出行日期查詢量分布、預售期內查詢量分布和總體查詢量等特征。以普通日期總體查詢量為例,分別統計各簇類中不同OD查詢量的出現頻次,其分布情況如圖6所示。

圖6 各簇類OD查詢流量分布圖
從圖6可以看出,各簇類查詢量差異顯著,其中第2類OD查詢量分布在20萬以內,該類別查詢量最少,為冷門OD類別;第3類OD查詢量分布在400萬~1 000萬,OD數量稀少,但查詢量最高,為熱門OD類別。
根據上述分析方式分別對普通日期和假期各個簇類OD的查詢量、中間站占比、乘車日期、預售期流量占比和客流距離等特征進行分析,可得出京滬高速鐵路OD客流特征,見表3和表4。

表3 普通日期各類別特征

表4 假期各類別特征
其中表3和表4各參數含義如下:
a:該類別的出發城市是中間站的OD數量占比。
b:該類別的到達城市是中間站的OD數量占比。
c:普通日期代表該類別乘車日期是星期五和星期日的OD數量占比;假期代表該類別乘車日期是假期第一天和假期最后一天的OD數量占比。
d:該類別預售期15天內查詢量高峰日。
e:該類別OD客流距離分布范圍,單位km。
根據上述獲得的OD客流特征可得出以下結論及相應的建議:
(1)非節假日熱門OD乘車日期主要集中于星期五和星期日,這類客流特點主要體現了跨城上班、周末往返的旅客需求,該結果可為推薦12306計次定期票業務提供數據依據。
(2)熱門OD中始發站需求高,符合鐵路旅客的出行規律。然而部分中間站的需求也相對較大,在節假日車次供不應求時,此類分析結果可為票額預分、增加車次等業務提供參考。
(3)熱門OD預售期內查詢量在乘車日期前1-2天占比較多。根據此結果,可以為節假日期間鐵路售票調系統調節負載能力提供參考依據。
(4)熱門OD的客流距離相對較短,可在節假日期間增加相應OD的出行車次,從而進一步滿足旅客的出行需求。
3 結束語
針對OD客流分析問題中歷史客運量與客運需求存在差距,聚類算法處理高維數據時魯棒性較差等問題,以余票查詢數據為基礎,提出了一種基于隨機距離預測的高層特征抽取模型RDP與K-means結合的OD客流聚類分析方法。以挖掘京滬高速鐵路熱門OD特征為目標,先使用RDP算法提取數據的重構特征,然后使用K-means算法對重構特征進行聚類,結果表明在三種聚類內部評價指標的評判下,RDP K-means算法均優于傳統的PCA K-means、K-means、層次聚類、DBSCAN算法,證明了RDP K-means算法對OD客流特征分析問題的有效性,最后挖掘出京滬高速鐵路OD客流特征,為相應的業務問題提供一定的參考依據。
基于余票查詢角度進行的客流分析研究,較大程度體現了旅客真實購票需求,可為鐵路票額預分、優化余票緩存、線路規劃等業務提供參考,有助于優化鐵路客運運力結構和資源配置。在后續的研究中,還可將余票查詢數據與實際訂單數據和候補訂單數據等結合起來,更加準確地分析旅客需求,進一步提高鐵路客運市場競爭力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
