基于注意力和多級特征融合的鐵路場景小尺度行人檢測算法
2022-06-01 09:00:16石瑞姣陳后金李居朋李艷鳳萬成凱
鐵道學(xué)報 2022年5期
石瑞姣,陳后金,李居朋,李艷鳳,李 豐,萬成凱
(1.北京交通大學(xué) 電子信息工程學(xué)院, 北京 100044;2.北京世紀(jì)瑞爾技術(shù)股份有限公司, 北京 100085)
鐵路運輸兼顧貨運和客運,是關(guān)乎國計民生的運輸大動脈。現(xiàn)階段鐵路運輸無法做到全封閉運行,因鐵路基礎(chǔ)防護(hù)設(shè)施薄弱而導(dǎo)致的鐵路交通事故時有發(fā)生。其中,鐵路關(guān)鍵區(qū)域行人入侵是影響鐵路行車安全的重要因素,對鐵路區(qū)域進(jìn)行實時行人檢測對于保障行車安全具有重要意義。近年來,利用深度學(xué)習(xí)進(jìn)行行人檢測取得了飛速發(fā)展。相較于傳統(tǒng)算法,深度學(xué)習(xí)可以自動學(xué)習(xí)行人高級語義特征,具有更高的檢測精度和更強(qiáng)的泛化能力。
現(xiàn)有基于深度學(xué)習(xí)的行人檢測算法主要分為三類[1]:第一類是一階段檢測算法,將整個檢測環(huán)節(jié)作為一個回歸及分類問題處理,檢測速度快但準(zhǔn)確性低,代表性算法有SSD[2]、YOLO系列[3-6]、RetinaNet[7]等;第二類是二階段檢測算法,利用區(qū)域候選網(wǎng)絡(luò)產(chǎn)生候選區(qū)域,在候選區(qū)域分類和回歸輸出檢測結(jié)果,準(zhǔn)確度高但檢測速度慢,代表性算法有Faster R-CNN[8]、Mask R-CNN[9]等;第三類是多階段檢測算法,通過迭代二階段檢測器逐步提高網(wǎng)絡(luò)檢測的準(zhǔn)確度,檢測精度高于二階段檢測網(wǎng)絡(luò),但檢測速度明顯變慢,主要包括Cascade R-CNN[10]、級聯(lián)全卷積神經(jīng)網(wǎng)絡(luò)[11]等算法。目前基于深度學(xué)習(xí)的目標(biāo)檢測算法在大、中尺度行人目標(biāo)上取得了較高的檢測精度,但由于小尺度行人本身像素點少,攜帶特征信息不足,且經(jīng)卷積神經(jīng)網(wǎng)絡(luò)多次降采樣后部分行人信息丟失,因此針對小尺度行人的檢測仍面臨巨大挑戰(zhàn)。
現(xiàn)有小尺度行人檢測算法多是在通用行人檢測算法上進(jìn)行改進(jìn),以提升算法對于行人尺度變化的魯棒性,從而提高小尺度行人檢測精度。其中,針對小目標(biāo)檢測最通用且最有效的改進(jìn)方式為高、低層特征融合,充分利用低層特征圖的位置信息和高層特征圖的語義信息提高小目標(biāo)檢測精度。2016年,Liu等[2]提出的SSD算法第一次嘗試?yán)貌煌瑢蛹壧卣鲌D進(jìn)行不同尺度目標(biāo)的檢測,但由于低層特征圖感受野小、包含語義信息不足,導(dǎo)致SSD算法對小目標(biāo)檢測精度低。為解決SSD算法存在的缺點,2017年,特征金字塔網(wǎng)絡(luò)(Feature Pyramid Networks,F(xiàn)PN)[12]被提出,通過自頂向下的路徑和橫向連接實現(xiàn)高、低層特征圖融合,得到兼具高分辨率和高語義性的特征圖,對小目標(biāo)的檢測精度有了明顯提高,但該方法在網(wǎng)絡(luò)中引入額外的網(wǎng)絡(luò)層,增大了計算量,影響了檢測的實時性。為此,文獻(xiàn)[13]提出尺度變換模塊,在不增加額外參數(shù)的前提下獲得不同尺度的語義特征。2017年,DSSD[14]算法被提出,將SSD的基礎(chǔ)網(wǎng)絡(luò)由VGG替換為ResNet-101,同時在SSD的輔助卷積層之后添加反卷積層形成“寬-窄-寬”的沙漏結(jié)構(gòu),增強(qiáng)低層特征圖的語義信息,顯著提升了小目標(biāo)檢測精度。2018年,YOLOv3[5]算法被提出,借鑒FPN的思想,融合3個不同層的特征圖分別對不同尺度目標(biāo)進(jìn)行檢測。文獻(xiàn)[15]利用FPN提取多尺度融合特征,同時利用在線困難樣本挖掘篩選出困難樣本重新送入網(wǎng)絡(luò)訓(xùn)練,解決了正負(fù)樣本不均衡的問題。2019年,Golnaz等[16]提出基于自動架構(gòu)搜索的FPN結(jié)構(gòu),利用強(qiáng)化學(xué)習(xí)訓(xùn)練控制器在給定的搜索空間中選擇最優(yōu)的模型架構(gòu),具有良好的靈活性和較高的檢測性能。
上述基于FPN的多尺度目標(biāo)檢測器顯著提升了網(wǎng)絡(luò)對于小目標(biāo)的檢測性能,但直接將高、低層特征融合忽略了低層特征圖中背景噪聲的干擾。低層特征圖感受野小、語義信息弱,包含大量背景噪聲,直接與上采樣后的高層特征圖融合易將背景噪聲向后傳播,影響檢測精度。
為有效解決大視場中小尺度行人檢測精度低的問題,本文以YOLOv3為主干網(wǎng)絡(luò)提出一種注意力機(jī)制引導(dǎo)下的多級特征融合網(wǎng)絡(luò)模型(Attention Multi-Level Feature Fusion Network,AMFF-Net)。首先,通過將注意力機(jī)制引導(dǎo)下的特征融合與YOLOv3網(wǎng)絡(luò)相結(jié)合,抑制背景噪聲向后傳播;其次,針對多次降采樣后小尺度行人特征信息丟失的問題,設(shè)計四倍降采樣預(yù)測分支,利用高分辨率特征圖進(jìn)行小尺度行人檢測;最后,將CIoU損失函數(shù)作為目標(biāo)框回歸損失函數(shù),解決均方誤差用于目標(biāo)框回歸時存在的優(yōu)化不一致及尺度敏感問題。在私有數(shù)據(jù)集和Caltech公開數(shù)據(jù)集的測試結(jié)果表明,本文算法相較于原始YOLOv3具有更低的對數(shù)平均漏檢率。
1 YOLOv3網(wǎng)絡(luò)
YOLOv3網(wǎng)絡(luò)由特征提取和多尺度預(yù)測兩階段組成。特征提取階段,YOLOv3將Darknet-53作為特征提取網(wǎng)絡(luò),該網(wǎng)絡(luò)由53個卷積層組成,通過改變卷積核滑動步長完成張量尺寸的變化,避免了因池化造成的小尺度行人特征信息丟失,同時引入殘差塊結(jié)構(gòu),在增加網(wǎng)絡(luò)深度的同時降低產(chǎn)生過擬合的風(fēng)險。多尺度預(yù)測階段,YOLOv3網(wǎng)絡(luò)借鑒FPN的思想,融合3個不同層特征圖以提升目標(biāo)檢測性能。多尺度預(yù)測結(jié)構(gòu)示意見圖1。
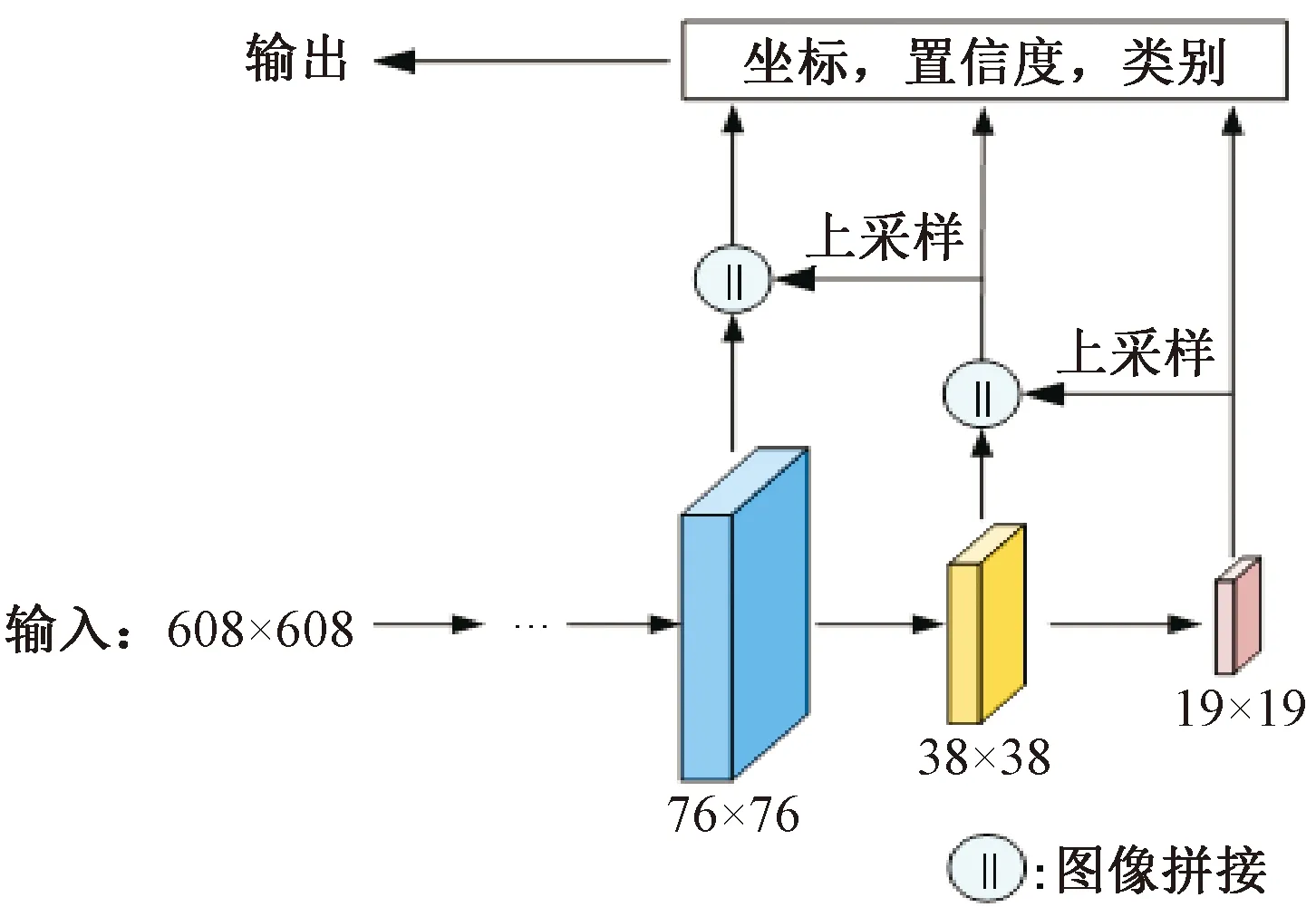
圖1 多尺度預(yù)測結(jié)構(gòu)示意
YOLOv3損失函數(shù)分三部分:目標(biāo)框預(yù)測損失、置信度預(yù)測損失和類別預(yù)測損失。其中,目標(biāo)框預(yù)測采用均方誤差(Mean Square Error,MSE)損失函數(shù),置信度預(yù)測和類別預(yù)測采用交叉熵?fù)p失函數(shù)。損失函數(shù)計算方式為
(1)

利用YOLOv3網(wǎng)絡(luò)進(jìn)行小尺度行人檢測存在以下問題:
(1)YOLOv3網(wǎng)絡(luò)利用八倍降采樣后的特征圖進(jìn)行小目標(biāo)檢測,小尺度行人特征信息嚴(yán)重丟失。
(2)低層特征圖語義信息弱,包含大量背景噪聲,直接與上采樣后的高層特征圖融合導(dǎo)致背景噪聲向后傳播,干擾后續(xù)行人目標(biāo)預(yù)測。圖2中融合前后特征圖對比證實了這一觀點。

圖2 YOLOv3網(wǎng)絡(luò)高低層特征融合前后對比
(3)目標(biāo)檢測任務(wù)通用距離測量標(biāo)準(zhǔn)為交并比(Intersection over Union,IoU),其計算方式為
(2)
式中:P、G分別為預(yù)測框和真實框;IPG為P與G的交并比。使用均方誤差作為目標(biāo)框回歸損失函數(shù)存在優(yōu)化不一致的問題,且均方誤差對目標(biāo)框尺度敏感,不具有尺度不變性。
2 小尺度行人檢測網(wǎng)絡(luò)模型
針對上述基于YOLOv3網(wǎng)絡(luò)的小尺度行人檢測所存在的問題,本文從多尺度目標(biāo)預(yù)測、注意力機(jī)制引導(dǎo)下的特征融合、損失函數(shù)優(yōu)化3個方面對YOLOv3作出改進(jìn),提出小尺度行人檢測模型AMFF-Net。
2.1 四分支目標(biāo)檢測網(wǎng)絡(luò)
為避免多次降采樣后小尺度行人特征信息丟失,設(shè)計了四分支目標(biāo)檢測網(wǎng)絡(luò)。四分支YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)見圖3。將YOLOv3中用于小目標(biāo)預(yù)測的八倍降采樣特征圖進(jìn)行二倍上采樣后與Darknet-53特征提取網(wǎng)絡(luò)第2個殘差模塊輸出的特征圖進(jìn)行融合,構(gòu)建四倍降采樣分支進(jìn)行小目標(biāo)檢測。
2.2 通道-空間注意力機(jī)制
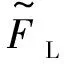

圖3 四分支YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)

圖4 引入注意力機(jī)制抑制低層特征圖中背景噪聲實現(xiàn)流程
CSAM用于注意力模塊中權(quán)重系數(shù)生成的網(wǎng)絡(luò)結(jié)構(gòu)見圖5。圖5中:上分支為通道注意力模塊(Channel Attention Module,CAM),采用SENet網(wǎng)絡(luò)[17]的權(quán)重生成方式,維度為w×h×c的輸入特征圖首先通過全局平均池化(Global Average Pooling,GAP)將維度壓縮為1×1×c,然后經(jīng)過兩次全連接層(fully connected layers,F(xiàn)C)生成通道注意力權(quán)重;下分支為空間注意力模塊(Spatial Attention Module,SAM),采用CBAM網(wǎng)絡(luò)[18]的空間注意力權(quán)重生成方式,維度為w×h×c的輸入特征圖分別進(jìn)行全局平均池化和全局最大池化(Global Max Pooling,GMP)輸出兩幅維度為w×h×1的特征圖,將兩幅特征圖橫向連接后經(jīng)過7×7卷積得到空間注意力權(quán)重;通道注意力權(quán)重與空間注意力權(quán)重經(jīng)過Sigmoid歸一化后點乘生成CSAM注意力權(quán)重。

圖5 CSAM注意力網(wǎng)絡(luò)結(jié)構(gòu)
2.3 CIoU損失函數(shù)
針對均方誤差用于目標(biāo)框回歸所存在的優(yōu)化不一致及尺度敏感問題,本文基于比值的概念重新設(shè)計具有尺度不變性的目標(biāo)框回歸損失函數(shù)——CIoU損失函數(shù),其具體計算方式為
LCIoU=1-IPG+RCIoU
(3)
(4)
(5)
(6)
式中:b、bgt分別為兩框的中心點;ρ為兩中心點間歐式距離;c為同時覆蓋預(yù)測框和目標(biāo)框的最小矩形的對角線距離;w、h為預(yù)測框的寬、高;wgt、hgt為真實框的寬、高;v為用來衡量預(yù)測框和目標(biāo)框之間寬高比例的一致性;α為用于平衡比例的參數(shù)。從α參數(shù)的定義可以看出,CIoU損失函數(shù)更傾向于向重疊區(qū)域增多的方向優(yōu)化。
CIoU損失函數(shù)以IoU損失函數(shù)為主體,有效解決了均方誤差作為目標(biāo)框回歸損失函數(shù)時的優(yōu)化不一致及尺度敏感問題。在此基礎(chǔ)上加入懲罰項RCIoU,用于對預(yù)測框形狀以及距真實框中心點的距離進(jìn)行約束。
CIoU損失函數(shù)中充分考慮到影響目標(biāo)框回歸效果的3個重要幾何因素:重疊面積、中心點距離和寬高比。通過在IoU損失函數(shù)基礎(chǔ)上引入中心點歸一化距離以及寬高比例因子,有效改善IoU損失函數(shù)無法優(yōu)化真實框和預(yù)測框不相交的情況,以及在兩框相交時無法區(qū)分其相對位置的缺陷,使得回歸過程更穩(wěn)定。
3 數(shù)據(jù)與實驗
3.1 數(shù)據(jù)集
為滿足實際應(yīng)用需求,使算法更好地契合鐵路場景,構(gòu)建了Railway私有數(shù)據(jù)集(以下簡稱“Railway數(shù)據(jù)集”),并與Microsoft COCO Dataset數(shù)據(jù)集(以下簡稱“COCO數(shù)據(jù)集”)共同構(gòu)成聯(lián)合數(shù)據(jù)集進(jìn)行網(wǎng)絡(luò)模型訓(xùn)練。Railway數(shù)據(jù)集中圖像采集區(qū)域主要包括火車站臺、鐵路道口及鐵路沿線等,為保證數(shù)據(jù)集中圖像多樣性,對采集到的視頻每秒抽取一幀構(gòu)成最終數(shù)據(jù)集。Railway數(shù)據(jù)集相關(guān)屬性信息見表1,不同場景下行人圖像示例見圖6。
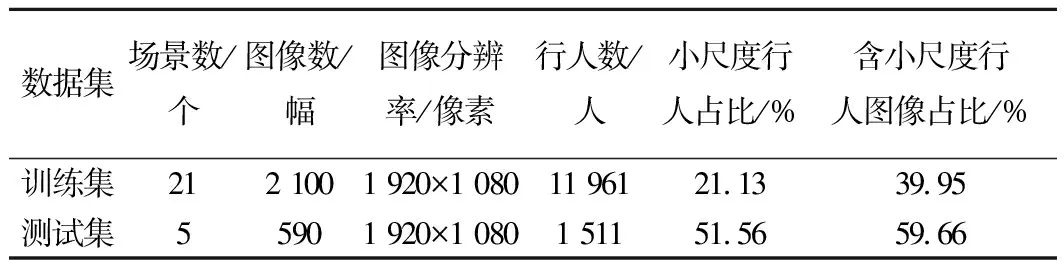
表1 Railway數(shù)據(jù)集屬性信息

圖6 Railway數(shù)據(jù)集不同場景下行人圖像示例
從圖6中可以看出,由于鐵路沿線監(jiān)控位點距離行人較遠(yuǎn),采集到的圖像多為大場景下的小尺度行人(本文將小尺度行人具體定義為寬度小于20像素的行人)。
將COCO、Railway數(shù)據(jù)集的訓(xùn)練集合并作為聯(lián)合數(shù)據(jù)集的訓(xùn)練集,Railway數(shù)據(jù)集的測試集作為聯(lián)合數(shù)據(jù)集的測試集。
3.2 評價指標(biāo)
為了更加客觀地對算法檢測性能進(jìn)行評價,本文將通用的行人檢測評價指標(biāo)——對數(shù)平均漏檢率LAMR作為算法性能定量評價標(biāo)準(zhǔn)。LAMR根據(jù)MissRate-FPPI曲線計算得出,MissRate-FPPI曲線橫坐標(biāo)為每張圖像的誤檢率FPPI,縱坐標(biāo)為漏檢率MissRate。在MissRate-FPPI曲線橫坐標(biāo)的(10-2,100)區(qū)間上以0.25為間隔取9個點,9個點對應(yīng)漏檢率對數(shù)的平均值作為e的指數(shù)獲得LAMR,具體計算方式為
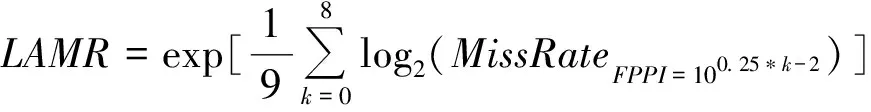
(7)
(8)
(9)
式中:FN為假陰性,表示漏檢行人數(shù)量;NP為測試集中行人總數(shù);FP為假陽性,代表誤檢行人數(shù)量;NI為測試集中包含的圖像數(shù)量。
3.3 訓(xùn)練與測試
Railway數(shù)據(jù)集中圖像分辨率為1 920×1 080,YOLOv3網(wǎng)絡(luò)輸入尺寸為608×608,為避免圖像輸入網(wǎng)絡(luò)時因過度縮放而造成小尺度行人信息丟失,將1 920×1 080分辨率的圖像左右重疊拆分為兩張分辨率為1 080×1 080的圖像,兩張圖像之間有重疊,可有效應(yīng)對行人剛好位于圖像正中間的情況。將拆分后的1 080×1 080分辨率的圖像等比例縮放至608×608送入網(wǎng)絡(luò)訓(xùn)練。
3.3 鋼纖維再生混凝土的軸心抗拉強(qiáng)度與鋼纖維含量特征值呈線性增長的關(guān)系,劈裂抗拉強(qiáng)度基本呈三段式線性增長的關(guān)系。鋼纖維的含量特征值在0.2~0.4之間時,劈裂抗拉強(qiáng)度增長較快,含量特征值在0.5時達(dá)到頂峰。但是,鋼纖維對再生混凝土軸心抗拉強(qiáng)度的影響系數(shù)遠(yuǎn)小于鋼纖維對再生混凝土劈裂抗拉強(qiáng)度的影響系數(shù)。
網(wǎng)絡(luò)基于Tensorflow框架實現(xiàn),操作系統(tǒng)為Ubuntu 16.04,服務(wù)器顯卡配置為GeForce GTX 1080 Ti。訓(xùn)練所需超參數(shù)設(shè)置為:batchsize設(shè)置為32,subdivisions為16,動量為0.9,權(quán)重衰減為0.000 5,初始學(xué)習(xí)率為0.001,迭代30 000次,訓(xùn)練至20 000和25 000次時分別對當(dāng)前學(xué)習(xí)率進(jìn)行0.1倍的衰減。
3.3.1 Railway數(shù)據(jù)集測試結(jié)果
(1)加入注意力機(jī)制前后檢測結(jié)果對比
在特征融合階段加入CSAM注意力模塊對低層特征圖中背景噪聲進(jìn)行抑制,定性說明注意力機(jī)制對于背景噪聲的抑制作用。加入注意力機(jī)制前后特征圖可視化結(jié)果對比見圖7。

圖7 加入注意力機(jī)制前后特征圖可視化結(jié)果對比
由圖7(b)可以看出:低層特征圖中包含大量背景噪聲;如不對背景噪聲進(jìn)行抑制而直接與高層特征圖融合,會導(dǎo)致融合后特征圖存在背景噪聲干擾,見圖7(c);引入CSAM注意力后背景噪聲得到有效抑制,見圖7(d),從而說明了改進(jìn)的有效性。
(2)綜合改進(jìn)檢測結(jié)果對比
依次將CIoU損失函數(shù)、四倍降采樣預(yù)測分支、通道-空間注意力機(jī)制加入YOLOv3網(wǎng)絡(luò),在Railway數(shù)據(jù)集測試改進(jìn)前后算法檢測性能。網(wǎng)絡(luò)綜合改進(jìn)前后測試結(jié)果對比見表2。
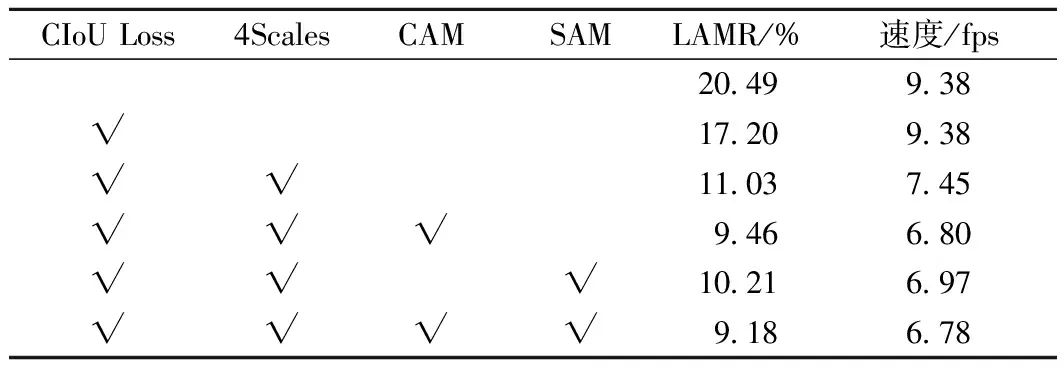
表2 網(wǎng)絡(luò)綜合改進(jìn)前后測試結(jié)果對比
由表2可以看出:將CIoU損失函數(shù)用于訓(xùn)練過程中目標(biāo)框回歸時,使YOLOv3在不改變參數(shù)量和計算量的前提下對數(shù)平均漏檢率降低了3.2%;在此基礎(chǔ)上增加四倍降采樣分支,運行速度降低了1.93 fps,對數(shù)平均漏檢率進(jìn)一步降低了6%;在特征融合階段引入通道注意力和空間注意力均可以提高網(wǎng)絡(luò)檢測精度,兩種注意力疊加使用時檢測精度進(jìn)一步提高,對數(shù)平均漏檢率降低了1.85%,檢測速度略有降低。

圖8 改進(jìn)前后算法測試結(jié)果對比
改進(jìn)前后算法在Railway數(shù)據(jù)集的檢測結(jié)果示例見圖9。圖9(a)中紅色框為人工標(biāo)記的真實框,圖9(b)和圖9(c)中藍(lán)色框為改進(jìn)前后網(wǎng)絡(luò)預(yù)測框。由圖9中可見,使用YOLOv3檢測時漏檢的行人通過本文算法成功被檢出。

圖9 改進(jìn)前后算法在Railway數(shù)據(jù)集檢測結(jié)果示例
為進(jìn)一步驗證本文算法的優(yōu)越性,將本文算法與現(xiàn)階段其他小目標(biāo)檢測算法進(jìn)行對比。不同算法訓(xùn)練所用數(shù)據(jù)集及實驗環(huán)境配置相同,其在Railway數(shù)據(jù)集測試結(jié)果對比見表3。

表3 不同算法在Railway數(shù)據(jù)集測試結(jié)果對比
從表3中可以看出,本文算法在檢測精度上具有明顯優(yōu)勢,相較于原始YOLOv3網(wǎng)絡(luò)對數(shù)平均漏檢率降低了11.31%,相較于其他改進(jìn)YOLOv3算法仍具有更高的檢測精度。但由于本文算法在原始YOLOv3網(wǎng)絡(luò)基礎(chǔ)上增加了四倍降采樣分支以及CSAM注意力機(jī)制,網(wǎng)絡(luò)層數(shù)增加增大了網(wǎng)絡(luò)的參數(shù)量及運算量,致使檢測速度有所降低。
3.3.2 Caltech公開數(shù)據(jù)集測試結(jié)果
為驗證本文算法泛化性能以及與現(xiàn)階段主流算法進(jìn)行對比,在Caltech公開數(shù)據(jù)集上對算法檢測性能進(jìn)行評估。Caltech數(shù)據(jù)集采集自10 h的車載視頻,分辨率為640×480。按照常規(guī)劃分,set00~set05子集中每3幀取一幀構(gòu)成訓(xùn)練集,set06~set10子集中每30幀取一幀構(gòu)成測試集,網(wǎng)絡(luò)輸入為608×608。
由于本文將小尺度行人定義為寬度小于20像素的行人,因此在Caltech數(shù)據(jù)集的“Scale=Far”(行人寬度為0~12像素)和“Scale=Medium”(行人寬度為12~32像素)子集上測試本文算法對小尺度行人的檢測性能。同時,為進(jìn)一步驗證本文算法對所有尺度行人的普適性,在“Reasonable”和“All”子集上對算法進(jìn)行測試。不同算法在Caltech數(shù)據(jù)集測試結(jié)果對比見表4。
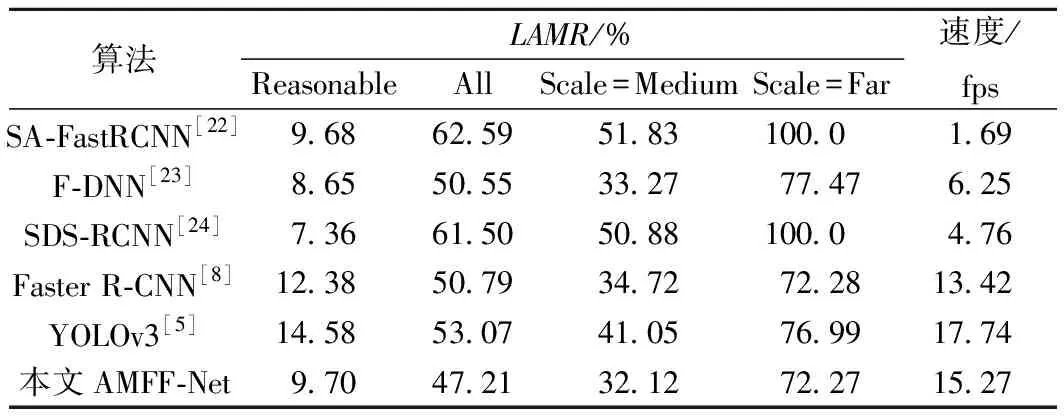
表4 不同算法在Caltech數(shù)據(jù)集測試結(jié)果對比
從表4可以看出,本文算法在“Reasonable”子集的對數(shù)平均漏檢率與SDS-RCNN算法存在2.34%的差距,但在“All”“Scale=Medium”“Scale=Far”子集相較于其他算法均具有更高的檢測精度,對數(shù)平均漏檢率明顯降低。在檢測速度方面,本文算法相較于SA-FastRCNN等網(wǎng)絡(luò)檢測速度較快,但由于網(wǎng)絡(luò)層數(shù)增加致使本文算法相較于原始YOLOv3檢測速度有所降低。
4 結(jié)論
(1)本文針對使用YOLOv3網(wǎng)絡(luò)進(jìn)行小尺度行人檢測時存在的不足,從多尺度預(yù)測、特征融合、損失函數(shù)優(yōu)化三方面對網(wǎng)絡(luò)作出改進(jìn),提出了一種基于注意力和多級特征融合的鐵路場景小尺度行人檢測網(wǎng)絡(luò)AMFF-Net。
(2)通過在Railway私有數(shù)據(jù)集和Caltech公開數(shù)據(jù)集上測試,本文算法相較于原始YOLOv3網(wǎng)絡(luò)雖然運行速度有所降低,但檢測精度明顯提升,在Railway數(shù)據(jù)集上對數(shù)平均漏檢率降低了11.3%,在Caltech數(shù)據(jù)集的不同子集中對數(shù)平均漏檢率均有明顯降低。在后續(xù)研究中可通過將網(wǎng)絡(luò)輕量化進(jìn)一步加快算法檢測速度。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
