基于模糊關聯規則挖掘算法的企業財務風險分析模型
2022-06-02 05:03:12馬睿錚韓靜張宏雷
中國注冊會計師 2022年5期
| 馬睿錚 韓靜 張宏雷
作者單位 | 東南大學經濟管理學院 河北工程大學管理工程與商學院
企業財務狀況是企業所有利益相關者包括經營者、債權人和投資者關注的焦點。在激烈的市場競爭中,任何企業都無法規避風險。在市場管理決策、金融保險業信用評級和投資決策中,應考慮金融危機預警和風險規避。此外,隨著云計算、移動計算、大數據等技術不斷發展,企業財務風險預警也迎來了飛速發展。企業財務風險管理的研究熱點和難點是如何評估風險并及時預警。按照不同類別,風險管理方法可分為建模方法及智能計算方法。建模方法包括變量分析模型、Z-score模型等。建模方法計算過程復雜,且模型可移植性差。智能計算類方法包括神經網絡、支持向量機、粗糙集等。然而隨著企業財務數據不斷增多,海量數據給企業財務風險管理帶來了諸多挑戰,如存在假設多、無法處理海量數據、未考慮財務指標的時間波動及未來趨勢等問題。為此,在研究了模糊關聯規則基礎上,本文對企業財務風險進行了分析,提出了基于模糊關聯規則挖掘算法的企業財務風險分析模型,并對企業財務危機進行定性分析,從而預測企業財務風險,為企業規避風險提供借鑒。
一、相關理論分析
(一)Apriori算法
Apriori算法具有頻繁模式的反單調性,常用格結構枚舉所有可能的項集。Apriori算法流程如圖1所示。

圖1 Apriori算法流程


(二)基于時間序列的數據挖掘
時間序列數據挖掘是通過分析數據的時間特征來描述事件發展歷程。需注意,時間序列數據可提取潛在的、不可預測的規則,且這些規則與時間特性密切相關。這些規律可以用來預測時間數據的短期、中期或長期發展趨勢。
令表示一個時間序列,則有:

式中:表示長期趨勢,該預測值隨時間的推移按一定的規律穩定地增加、減少或保持在一定水平;為季節性變化因素;為周期性變化因素;為隨機項因素。
為了發現數據的規律性,需要對時間序列數據進行平滑和反季節處理。處理步驟如下:
步驟1:估計長期趨勢項,得到季節變化項和誤差項的乘積S=Y/T。對月度數據使用6月中心移動平均值來平滑數據,則有:
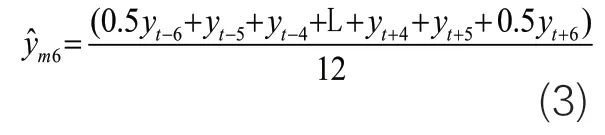
進一步,對季度數據采用2月中心移動平均值來平滑數據,則有:

需注意,移動數據中無季節性,其中是標準化的季節性因子。
步驟2:去除誤差項,估計季節項。首先,每月數據歸一化如下:

同理,季度數據歸一化如下:

步驟3:去除原始數據中的季節性項,得到季節性調整后的數據。
(三)模糊FCM聚類
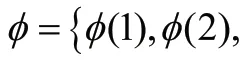


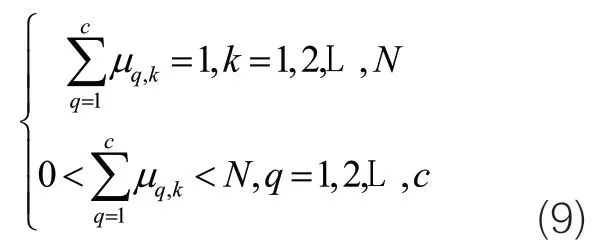
令式(8)最小化,則有:

式(10)無法得到解析解。FCM聚類算法提供了一種近似求目標函數最小值的迭代算法,具體描述如下:
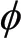



根據以上步驟即可得到隸屬度矩陣和簇中心。也就是說,對于給定的聚類數目,需要確定待識別的參數v,并且v可以通過最近鄰啟發式算法來確定。因此,最鄰近啟發式算法下v的計算過程更新如下:

式中:是第個簇的最近鄰居個數,c()是c的每個最近鄰居的聚類中心。

二、企業財務風險預警模型
(一)財務指標選取及相關性分析
為了考察財務指標對企業財務風險的影響,本文從企業盈利能力指標、企業經營能力指標、企業成長能力指標、企業償債能力指標和企業現金流量指標中選取。在此基礎上,對這些財務指標進行相關性分析后,剔除一些相關性很強的財務指標,簡化模型。各財務指標的相關系數可由下式確定:

式中:和為兩個變量,r為變量的相關系數,滿足-1≤r≤1。當|r|=1時,完全線性相關于;當r=1時,完全正相關于;當r=-1時,完全負相關于;當r=0時,和不相關;當-1<r<1時,和呈線性關系。
進一步,排除高正相關或負相關的指標,以減少財務指標之間的共線性影響。
于2017年9月舉行的第四屆“跨越太平洋——中國藝術節”,11項展示中華文化藝術成就的活動在舊金山、圣何西、西雅圖、波特蘭、拉斯維加斯等4個州的多個城市舉行,為持續推動中美文化交流與合作搭建舞臺。本屆藝術節首次設立中國地方文化周,集中推介底蘊深厚、地域特色鮮明的山東文化。孔子第75代孫孔祥林在舊金山圖書館講述孔子思想及其對世界
(二)財務數據處理與重構
為了減少企業財務風險分析的偏差,有必要對收集到的樣本數據進行清理,剔除所有財務指標的異常值。同時,根據下一步挖掘關聯規則,需要根據財務風險等級對連續的財務指標數據進行離散化處理。
考慮到財務數據集由多個不同企業的財務數據組成,各財務指標變量基本處于正態分布。因此,正態分布中的等面積劃分被用來離散連續變量。根據各變量分布函數的1/5、2/5、3/5和4/5分位數,將各財務指標變量離散為5個等級,分別描述為盲目階段(等級1)、遲緩階段(等級2)、錯誤行為階段(等級3)、危機階段(等級4)和消亡階段(等級5)。
(三)模糊關聯規則數據挖掘算法
采用基于候選模式生成和測試的Apriori算法確定頻繁模式集,首先對候選模式集進行并行化處理,從而得到時間序列數據。其次,將數據的連續屬性進行離散化處理,從而確定相關模糊屬性數據集。算法具體過程描述如下。輸入:最小模糊支持度sup,最小模糊信任度conf;輸出:關聯規則集為S。
步驟1:令并行處理器為p,p,L,;
步驟2:將數據庫劃分為多個分區,并分配給不同處理器;
步驟3:使用模糊FCM聚類算法對不同處理器進行聚類,并生成新數據集,同時,離散化屬性得到時間序列,并依據 sup和 conf構造文檔樹;
步驟4:對每個本地處理器執行計數操作;
步驟5:根據本地計數計算全局計數,并生成輸出規則集。
根據規則的前后屬性所滿足的時序約束對規則進行過濾,得到時序規則。運用規則的發展趨勢來確定企業的危機程度,并對企業財務危機進行定性分析。通過計算危機系數,最終確定企業的危機階段,實現對企業財務危機的定量分析。規則的低前因和高后因加劇了企業危機;否則,危機就會減少。如果規則總是處于第一階段,企業危機相對較輕;如果在第三階段,危機較溫和;如果處于第五階段,企業就瀕臨破產。
進一步,引入危機系數來計算企業財務危機的具體程度:
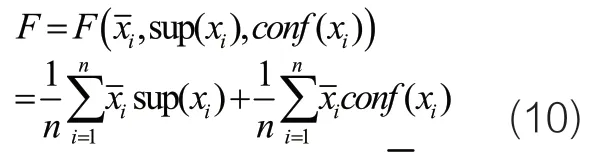

三、仿真及分析
(一)數據集
本節選取某上市公司為研究對象,以2003年至2020年的年度和季度報表為數據來源,數據集相關信息如表1所示。共收集了32個財務指標。

表1 財務數據集相關信息
(二)數據處理
對選定財務指標的數據樣本進行分類,剔除異常值。同時利用前文理論計算財務指標之間的相關系數,選取同一組財務指標中絕對相關系數較高的財務指標,其余指標根據財務風險水平進行離散化,得到重構后的財務指標數據庫。最終選取的財務指標如表2所示。

表2 相關性分析后選取的財務指標
進一步,將每家企業12個季度的財務指標匯總為時間序列,同時將離散化后的數據集作為關聯規則挖掘算法的輸入。此外,利用關聯規則對財務指標進行預測和危機預警。
(三)實驗對比及分析
圖2所示為本文提出的算法和傳統的Apriori算法的運行時間。可以看出,在不同的閾值下,本文所提算法具有更短的運行時間和更高的運行效率。

圖2 不同算法運行時間對比結果
圖3所示為不同閾值和置信閾值下的規則數對比結果。X軸表示支持度閾值,Y軸表示置信度閾值,Z軸表示規則數量。當選擇不同的支持度閾值和置信度閾值時,可以根據財務指標庫得到不同的關聯規則。

圖3 不同閾值下規則數對比結果
表3所示為企業存在財務風險時頻繁出現的關鍵財務指標。主要關鍵指標是判斷企業是否存在財務風險的關鍵因素,其波動性決定了企業的風險水平。
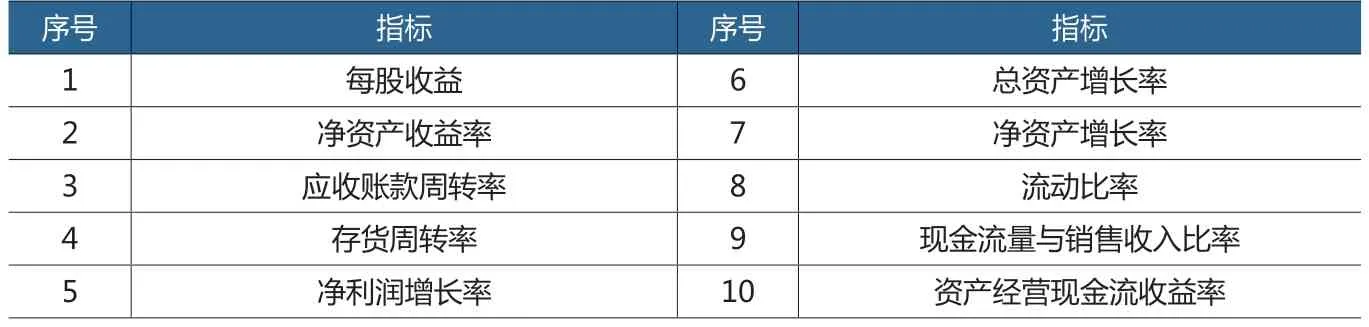
表3 關鍵財務指標
本文對企業財務風險預測問題進行了研究與分析。提出了一種基于模糊關聯規則的企業財務風險預警模型。在確定風險指標及對財務數據進行處理后,采用基于候選模式生成和測試的Apriori算法確定頻繁模式集,并對連續屬性進行離散化,得到新的模糊屬性數據集。最后,根據規則的前后屬性所滿足的時序約束對規則進行過濾,得到時序規則。運用規則的發展趨勢來確定企業的危機程度,并對企業財務危機進行定性分析,從而預測企業財務風險,為企業規避風險提供一定幫助。
猜你喜歡
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
云南畫報(2020年9期)2020-10-27 02:03:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
