基于字符區域感知的端到端車牌識別方法
2022-06-02 06:57:16范曉焓宿漢辰李斌陽
無線電工程 2022年6期
李 巖 ,舒 言 ,范曉焓 ,宿漢辰 ,李斌陽
(1.國際關系學院 網絡空間安全學院, 北京 100191;2.哈爾濱工業大學 計算機科學與技術學院, 黑龍江 哈爾濱 150006)
0 引言
車牌識別是智能交通系統的重要組成部分,在收費控制、數字安全監控等諸多應用中發揮著重要作用。傳統的車牌識別系統通常將任務分解為車牌區域檢測(車牌定位)、字符分割和字符識別3個階段[1-3],同時借助端到端訓練技術[4-8],深度學習方法進一步提升了車牌檢測與識別的整體性能。
盡管深度學習方法提升了車牌識別能力,但是大部分車牌識別系統在困難場景下依然無法兼顧識別精度與算法效率。這是因為大部分端到端車牌識別模型依然遵循車牌定位—識別這一框架[9-12]。基于此,本文提出了一種基于字符區域感知[13-14]的端到端車牌識別方法,有效平衡了復雜場景下車牌識別的精度與速度。該框架無需借助車牌區域檢測即可實現對字符的識別。與現有方法不同,本文提出的方法直接提取單字符特征并進行分類,同時在網絡結構設計階段采用由特征金字塔增強模塊和特征融合模塊組成的低計算量分割頭[15]彌補其在特征提取方面的精度缺陷,構建高效精準的車牌識別模型。
1 相關工作
1.1 車牌識別系統
傳統的車牌識別系統通常分為車牌區域檢測、字符分割和字符識別3個階段。隨著深度學習的發展,基于卷積神經網絡的目標檢測模型被廣泛用于車牌識別,典型的有YOLO[16],R-CNN[17]和SSD[18]。大量車牌識別工作基于以上目標檢測模型展開深入研究。Brillantes等[17]提出了一種基于Faster R-CNN[19]架構的車牌檢測網絡,使用特征金字塔網絡(FPN)作為Faster R-CNN的探測器,進一步提升了檢測速度。Wu等[18]在車牌檢測階段使用殘差網絡ResNet替代SSD中的VGG[20]網絡,通過引入殘差網絡結構加深網絡深度,提升模型學習能力。
在車牌識別階段,Zhang等[4]在字符識別階段將車牌視為二維信號,改善了傳統因將車牌視為一維序列所導致的復雜環境下車牌識別能力下降的問題。Chang等[1]設計了一種由字符分類、拓撲排序和自組織識別3個步驟組成的字符識別方法,顯著提升了識別的準確性。上述方法一定程度上提高了車牌自動識別能力,但卻局限于傳統三階段框架,當受到復雜環境影響時系統整體性能會受到較大影響。
1.2 端到端車牌識別模型
深度學習中的端到端訓練是提升車牌檢測與識別整體性能的重要技術手段。Li等[7]第一次將車牌檢測和識別集成到一個統一的端到端網絡中,通過共享卷積特征層對檢測和識別任務損失函數進行聯合優化,提升系統效能。Chen等[10]設計了一種基于車牌關系挖掘的端到端車牌檢測網絡,先根據車牌中心與車輛偏移量估計車牌位置,再對車牌四邊形框進行細化,最終聚合成車牌拼接區域,減少了車牌搜索面積,并提高了小尺寸車牌檢測性能。Wang等[12]提出了基于級聯網絡的實時端到端車牌識別框架,使用級聯卷積神經網絡以及多任務卷積神經網絡,將板塊分類、邊界框回歸、車牌地標檢測和板塊顏色識別4個任務同時進行,極大地提高了訓練速度。上述端到端車牌識別方法有效提升了車牌識別的精度,但受限于車牌定位—識別這一框架,計算開銷較大,無法在車牌識別的速度和精度間取得較好的平衡。
本文提出的車牌識別框架如圖1所示。
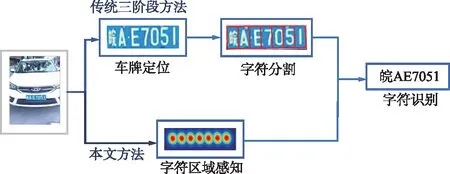
圖1 本文提出的車牌識別框架Fig.1 The proposed license plate recognition framework
2 字符區域感知方法
2.1 方法框架
本文車牌識別網絡體系結構如圖2所示。對于輸入的含有車牌的圖像,首先利用預訓練好的共享卷積層對車牌區域進行字符感知,從而生成正式訓練時所需要的標簽。在正式訓練中,車牌區域的字符區域高斯熱力圖和字符聯通高斯熱力圖將被預測,以檢測車牌框。與此同時,字符定位的結果被用于在共享卷積層輸出的特征圖中,以提取感興趣區域的特征向量。最后,2個并列的輕量卷積神經網絡用于預測不同位置的車牌字符輸出。值得注意的是,本文構建了一個統一模型,可以實現端到端訓練。作為主干網絡的共享卷積層架構的說明詳見2.2節。
為了有效解決因相機視角劇烈變化導致識別精度降低的問題,本文提出了一種通過構造人造數據集模擬多角度車牌字符進行預訓練的方法。同時針對車牌字符排列的特殊規律并參考車牌顏色的先驗信息,進一步提升字符定位精度。由于車牌具有自然場景文本中沒有的顏色以及字符規律等特性,在檢測過程中加入對車牌的顏色以及字符排列特性的處理,成功降低了車牌中字符定位的難度。
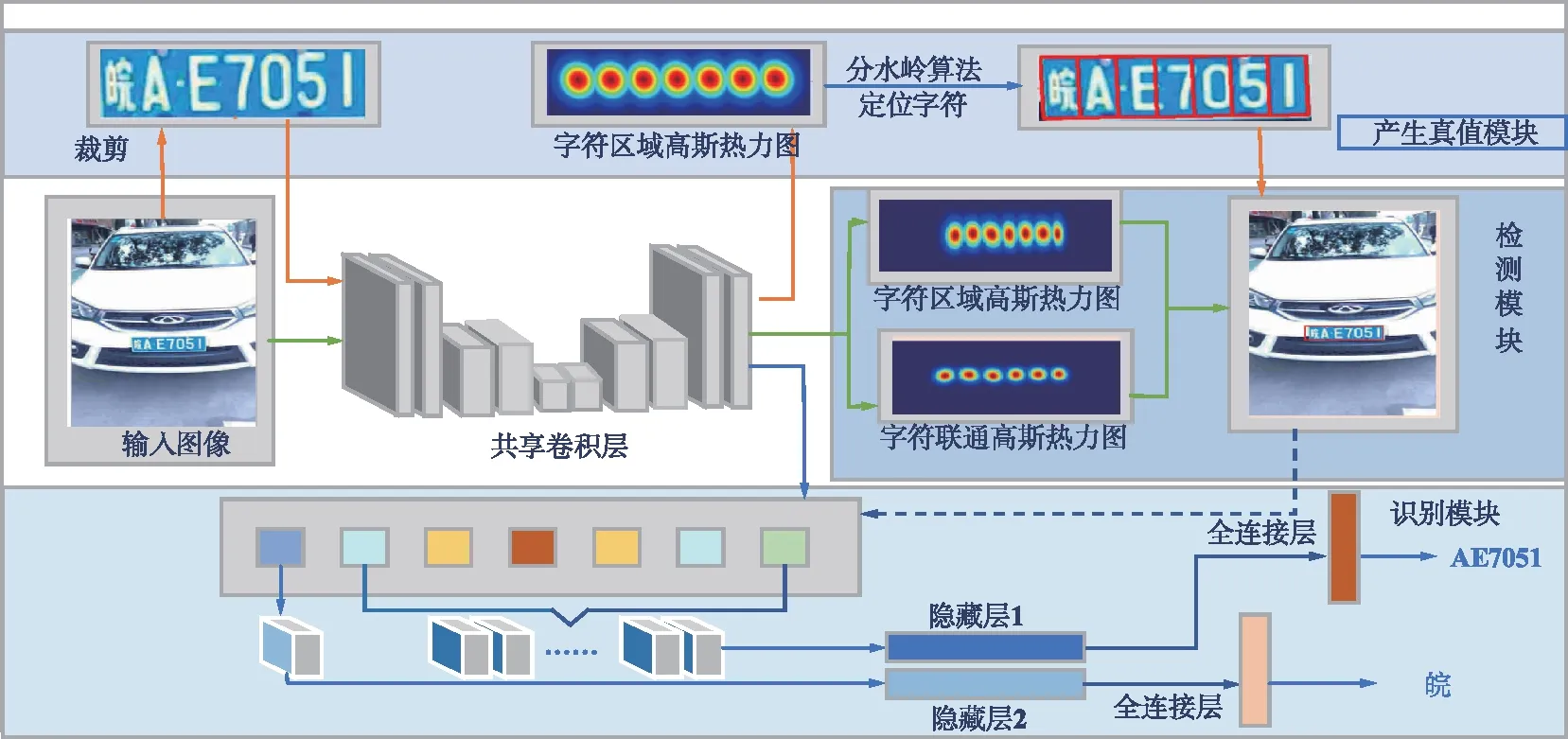
圖2 車牌識別網絡體系結構Fig.2 The architecture of license plate recognition network
2.2 主干網絡架構
分割頭對網絡的增強示意圖如圖3所示。主干網絡主要由特征金字塔增強模塊(FPEM)和特征融合模塊(FFM)組成。ResNet18[20]作為主干網絡雖然計算量較小,但由于網絡層數較低,模型學習能力有限。為了解決這一問題,使用FPEM和FFM彌補這一缺陷。FPEM呈級聯結構且計算量小,可以連接在主干網絡后面使不同尺寸的特征更深,從而更具表征能力。FPEM模塊可以看成是一個輕量級的FPN,可以不停級聯以達到不停增強特征的作用。而FFM模塊用于融合不同尺度的特征,最后通過上采樣將它們合并到一起。具體地,特征提取部分全部使用3×3大小的卷積核進行圖像特征提取,并以一個平均池化層和含有1 000路Softmax的全連接層結束。使用1×1卷積將特征圖通道數減少到128后得到縮小的特征金字塔,并用FPEM進行增強,每個FPEM產生一個增強的特征金字塔,最后由FFM將增強后的特征金字塔融合,通道數為512。實驗結果表明,本文使用輕量級網絡ResNet18配合由特征FPEM和FFM組合成的低計算分割頭作為主干網絡[15],在保證模型準確性的同時極大地提升了模型的推理速度。
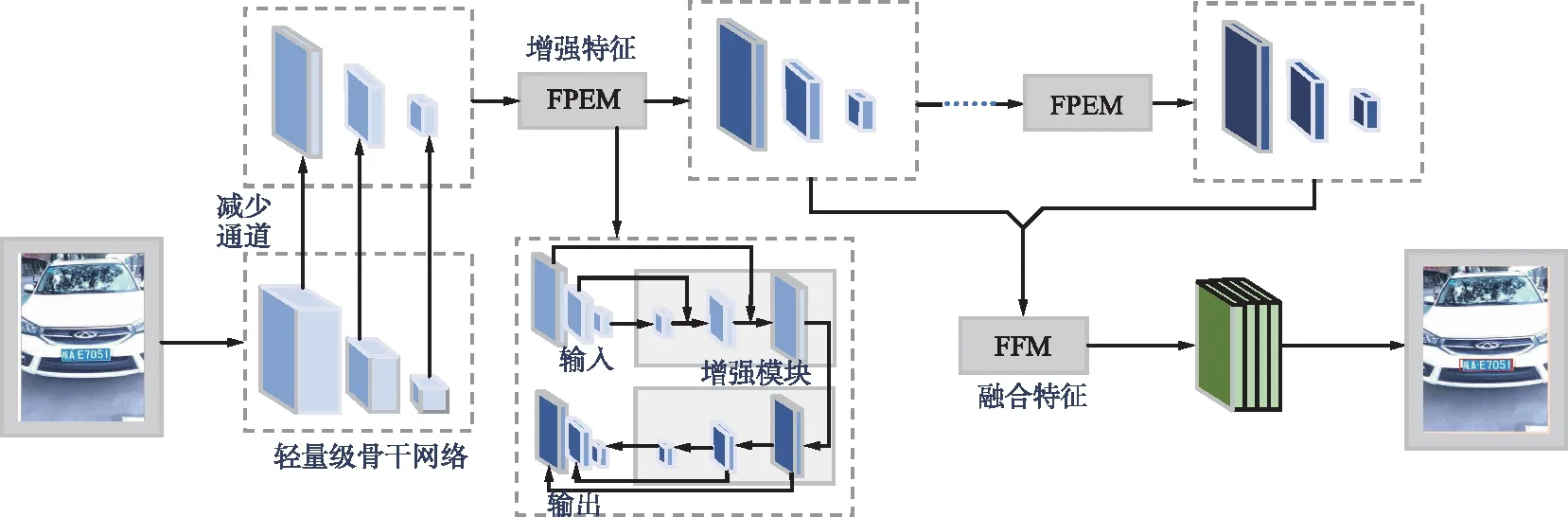
圖3 分割頭對網絡的增強示意Fig.3 The diagram of the segmentation head’s enhancement to the network
2.3 預訓練&訓練
為了進一步提高模型對車牌字符區域的感知能力,本文使用帶有字符級標注的人造數據集進行預訓練。與構造自然場景光學字符識別(OCR)人造數據集不同[13],本文根據真實車牌特性構造的人造數據集僅包含大寫字母與數字的字符形式。由于車牌首位一般為代表地區的漢字,訓練時只需將最前的字母前一位確定為該漢字位置即可。構造人造數據集時不僅需要模擬產生多種視角的車牌字符,同時應模擬與真實車牌相似的各類復雜場景,從而提升模型在各類復雜情況下的車牌字符區域感知能力。
模型預訓練與訓練流程如圖2所示,綠線和藍線流程分別揭示了檢測模塊和識別模塊的訓練流程。由卷積網絡輸出2個通道的字符區域高斯熱力圖和字符聯通高斯熱力圖用于定位字符的邊界框,包含16個通道的特征圖用于識別模塊。識別模塊利用模型自動定位的每個車牌字符區域,輸出車牌的內容信息,并根據車牌的字符數量和位置信息輸出車牌的具體類型。值得注意的是,預訓練階段標簽已由人造數據集提供;正式訓練時由于缺少字符級別的標注,需要利用弱監督學習生成偽造標簽,即紅線所展示的流程。具體地,紅線流程首先使用人造車牌數據集中的每張圖片,裁剪出車牌區域,針對圖像中每個文本實例經過共享卷積網絡生成單個字符區域的高斯熱力圖,使用分水嶺算法將高斯熱力圖與背景分開,并使用最小外接矩形框出每個車牌字符的位置,最后通過尺度變化的方式即可在原始圖像中得到每個字符的邊界框。
本文采取端到端訓練方式,預訓練階段誤差函數由檢測端和識別端共同組成,其中檢測端的誤差函數可表示為:
(1)
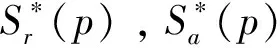
識別端的誤差函數表示為:
(2)
式中,xi為預測出該字符類別的概率;ci為該字符類別在真實標簽中的概率。對于第2個分類器,i為該字符類別;yi為預測出該字符類別的概率;di為該字符類別在真實標簽中的概率。
總的誤差函數表示為:
L=w1Ldet+w2Lrec,
(3)
式中,超參數取值w1=w2=1。
預訓練結束后將輸入真實車牌數據以弱監督學習方式進行正式訓練。在此過程中, 通過預訓練事先得到的模型已經具備預測字符級標注的能力。同時,為保證訓練過程可靠性,在正式訓練時建立真值評估機制,通過設置置信度對生成的真值進行評估、篩選和糾正。假設對于某車牌w,由模型分割出的字符框數量為l*(w),車牌字符真值數量為l(w),可得分割置信度為:
(4)
訓練過程中設定該置信度最小閾值為0.7,如果置信度大于等于最小閾值,則使用模型產生的真值;相反,則啟用矯正機制重新對字符進行分割。正式訓練的誤差函數在引入真值置信度后可修改為:
(5)
本文提出的模型可以通過不斷學習原始圖像中的字符提升識別能力。隨著訓練時間的增加,模型可以獲得越來越多的正確車牌數據標簽,從而提高車牌識別性能。
3 實驗結果與分析
本文使用PyTorch 1.8版本,在Intel酷睿i5 CPU,單塊GTX3090 GPU的平臺上進行車牌識別模型的訓練和評估。實驗比較了幾種優秀的車牌識別方法,同時進行了消融實驗比較分析。
3.1 數據集與評價指標
本文在公開大型車牌數據集CCPD 2019[21]上與之前的工作[18-19]進行了對比實驗。CCPD數據集是目前中國最大的公開可得的車牌數據集,收錄近30萬張彩色圖片,每張圖片分辨率為720 pixel×1 160 pixel,包含多種類型的車牌。其中“DB”為光線較暗或較亮車牌、“Challenge”為具有挑戰性的車牌、“Blur”為模糊的車牌、“FN”為距離攝像頭較遠或較近的車牌、“Rotate”為小傾斜角度車牌(水平傾斜20°~50°,垂直傾斜-10°~10°)、“Tilt”為大傾斜角度車牌(水平傾斜15°~45°,垂直傾斜15°~45°)、“FPS”為幀率、“AP”為平均準確率,具體如表1所示。這些圖片包含不同背景、不同拍攝角度、不同拍攝時間和不同光照等級的獨立車牌圖像,是現有公開車牌識別數據集中種類最為豐富、度最高的數據集,可以很好地驗證本文提出方法的有效性。

表1 CCDP數據集檢測結果
評價指標選取上,在車牌檢測任務中本文使用目標檢測中廣泛使用的VOC評價標準[20]進行評估。具體地,對比每張圖片檢測出的結果和真實標簽的交并比(IOU),如果IOU值超過了某個閾值,則將它劃歸到真陽(True Positive,TP)中,IOU值低于某個閾值,則將它劃歸到假陽(False Positive,FP)中。最終根據TP,FP計算準確率和召回率,然后據此計算平均準確率(Mean Average Precision,MAP)。車牌識別任務的評價指標與ICDAR2013場景文字識別的評價指標相同,即當某個文本識別的結果和真實標簽一致時才算正樣本,最終計算每個類別的平均準確率即為最終的MAP結果。
3.2 車牌識別結果比較
本文提出的模型同時在檢測器和識別器中進行端到端聯合訓練。檢測器采用了一種基于弱監督框架的學習方法進行訓練,因此識別器只反向傳播由正確分割的車牌在訓練每個階段產生的損失。此外,在訓練過程中還應用了水平翻轉、隨機裁剪、仿射變換和顏色變化等數據增強技術。本文訓練過程可以分為2個階段:基于人造數據集的預訓練階段和基于真實數據的參數微調階段。首先,利用人造數據對主干網絡進行預訓練初始化網絡參數,直到損失值收斂;然后,在CCPD數據集上進行正式訓練,正式訓練階段的損失函數引入真值置信度。
為了驗證模型的有效性,本文選取了最具代表性的Faster R-CNN和SSD作為基線模型進行實驗對比,定量結果如表1所示。實驗結果表明,本文提出的車牌識別模型在車牌檢測任務上遠超基線模型,尤其在旋轉和傾斜數據上顯著地超過了基于目標檢測的模型。而在車牌識別任務上,本文選取“ SSD+HC ”的模型[21]作為基線模型,定量結果如表2所示。

表2 CCPD數據識別結果
實驗結果表明,本文提出的網絡模型在車牌識別任務上具有明顯優勢。部分檢測識別可視化結果如圖4所示,可以看出,本文提出的模型可以成功檢測并識別常規、傾斜角度及低分辨率圖像中的車牌。

圖4 車牌識別可視化結果Fig.4 The visualization results of license plate recognition
為了進一步驗證本文輕量級主干網絡中FPEM和FFM模塊的必要性,采用消融實驗進行驗證。實驗使用ResNet18作為基本骨架網絡,具體結果如表3所示。實驗結果表明,相比于傳統的FPN,FPE和FFM結構,本文方法在保證模型準確率的前提下極大地降低了模型復雜度和推理時間;同時相較于不使用該模塊又提升了模型準確率。因此相較于傳統的CNN特征提取架構,本文采取的FPEM和FFM的結構能夠更好地與主干網絡架構相結合,在具有輕量級網絡快速提取特征的基礎上,增強了圖像中不同尺度車牌區域特征表示能力,從而使其適合于各類富有挑戰的車牌識別任務。

表3 本模型關于分割頭的消融實驗
4 結束語
本文的主要貢獻包括兩方面:① 提出了一種基于字符區域感知的車牌識別框架,將車牌識別問題轉換為直接對車牌中每個字符進行定位并識別的問題,有效兼顧了復雜場景下車牌識別的精度與實時性需求;② 構造了人造車牌相關字符數據集并將其應用于車牌字符區域感知模型預訓練過程,有效提升了模型對車牌字符區域的感知能力與識別精度。
未來的工作將會繼續優化改進端到端車牌識別模型,如利用模型壓縮剪枝等方法加快模型推理速度,使之可以更好地適應實際應用。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
