利用隨機森林基于文本形式的經緯度預測
2022-06-03 12:48:35羅寅張俊坤陳堯楊曦
電腦知識與技術 2022年8期
關鍵詞:文本
羅寅 張俊坤 陳堯 楊曦

摘要:目前的地理信息系統已經趨于完善,但仍受到許多因素的制約。比如,希望通過大量的地理信息數據建立模型,輸入一些未知的地理信息,就可以在一定程度上預測目標位置時,現有的技術會遇到許多挑戰。本文針對這一問題,提出通過將機器學習中的隨機森林算法應用于地址文本,實現一定程度上的地理位置(經緯度)的預測。
關鍵詞:機器學習;隨機森林;經緯度預測;地址文本
中圖分類號:G424? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)08-0069-02
21世紀以來,由于互聯科技的發展,以前只存在于科研機構和政府機關的數據已經在互聯網隨處可見,地理信息也開始對群眾開放,而且它已經進入了人們的生活,成了必備的生活服務工具[1]。在解析地名后,將地理信息與自然語言結合在一起[3],如今通過發展,這些信息醫療保健、公共衛生、科學研究、社會建設等領域展現出了十分顯著的作用[4-6]。
基于文本的地名解析,是對中文地名進行識別和語義判斷并映射到文本中地名地理坐標的過程[7]。一般的地名解析需要進行5個步驟,構建地名識別模型、構建地名詞典、地名識別、局部模糊匹配、文本地理編碼[3]。一般流程為:篇章化需要地名解析的文本、基于篇章識別地名和局部模糊匹配地名、編碼文本地理。上述三個步驟都需要依賴機構化的地名詞典[3]。
從上面的信息可以看出,目前地理信息系統非常依賴地理詞典。但是因為需要對國家的基礎地理資料以及 GIS 服務商所提供的資料進行結構化的處理后才能夠得到一個地理字典。所以,在某些時候,當地理數據服務器無法及時地更新數據,甚至無法獲取目標所在的地理數據時,就需要對目標的地理位置進行一定范圍內的預測。針對這一問題,本文試圖將輸入文本形式的地址分詞,提取出其中的關鍵信息與經緯度信息結構化,通過隨機森林算法訓練模型,使之可以在一定程度上進行預測。通過實驗,得到關于經緯度的0.002014969960158303的均方誤差,證明了本文的方案具有一定的有效性。同時,由于本文的數據少且零散,也未對模型進行更深的優化,如果能夠獲得更好的數據,相信本文所提出的方案所得到的偏差值更小。
1 數據來源
首先需要說明的是,由于筆者無法得到較健全的數據,本文的數據來源為利用Python爬取拉勾網中所有登記的上海公司的首個地址文本(地址列表中的第一個),并利用百度地圖API將地址文本全部轉化為經緯度。筆者選擇拉勾網,是因為拉勾網中公司的地址描述較為完整,雖然根據理論來講,這樣得到的有效數據量較少、集聚程度較差,不利于對本文數據結構的預測,但是本文主要目的是證明本文所建立的數據結構的重要性,而不是為了進行高精度的實驗,所以只要預測的結果在接受的范圍內即可。另外,由于爬取全國地址所需的計算量太大,這里只針對上海市的地址進行爬取,之所以選用上海,是因為這些地址在上海市的分布較為集中,而且上海市市轄區的劃分較為明確,非常符合本文建立的結構化數據文本分詞對文本地址的要求。
2 數據預處理
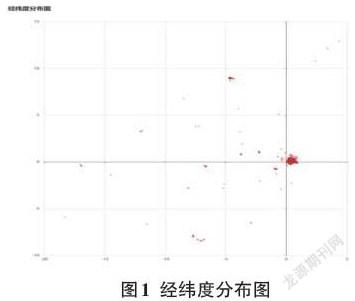
通過可視化繪圖,數據的經緯度分布情況如圖1(x軸為經度,y軸為緯度):
通過圖1可以發現,有大部分數據集中在一小塊區域,而這些數據正是所需要的(數據越集中,預測結果精度越高),其他過于離散的數據需要排除掉。
2 所用工具和算法簡介
2.1 THULAC
THULAC(THU Lexical Analyzer for Chinese)是由清華大學自然語言處理與社會人文計算實驗室開發并正式公布的一系列基于中文單詞法進行分析的工具包,目前普遍地認為,THULAC分詞工具包優于大多數中文分詞工具包。
2.2 隨機森林
作為包含多個決策樹的隨機森林,可以有效地處理并解決決策樹泛化能力弱的問題。對于決策樹來說,它的構成結構為節點和有向邊,決策樹由根節點、葉節點和內部節點構成。決策樹算法將會從根節點開始運算,在輸入的數據與決策樹中的特征節點進行比對后,根據數據與特征節點的比對結果,選擇下一個合適的分支進行再比較,直到比較到葉子節點結束,該葉子節點即為最后的決策結果。但在對于更加復雜、巨大的數據時,決策樹的泛化能力弱的問題將影響決策結果,所以,由多個決策樹組成的隨機森林可以有效地解決該問題。
隨機森林屬于Bagging類型,Bagging策略來自Bootstrap Aggregation:從數據集中重采樣特征數據,并在全部的數據中,對這些特征數據生成分類器(如ID3、CART等),重復重采樣和建立分類器這兩步,得到多個分類器,再根據這些分類器的決策結果,對數據進行分類。
隨機森林在bagging的基礎上進行了優化:
1)數據的隨機:從數據集中用Bootstrap選取部分數據;
2)特征的隨機:從數據集中隨機地選出一些特征,并選擇最佳的特征作為節點建立決策樹;
3)重復以上兩個過程多次;
4)這些決策樹形成隨機森林,通過投票得出結果,決定數據屬于什么類。
3 結構化數據的原理流程
3.1原理介紹
首先,將地址文本進行分詞,并篩選得到有效的地理描述特征詞(如地名、名詞、方位詞等),這里用到的不是日常生活中用到的口語化的位置描述語句,而是特指含有完整的絕對地理位置信息的描述語句,如何把口語化的描述語轉化為完整的信息屬于NLP問題,不在本文所討論范圍內,所以本文使用“地址文本”指代這種語句。其次,將得到的地理描述特征詞轉化為易于計算機處理的特征值向量,最后,將特征值向量與地理位置信息結合(如經緯度),得到完整的數據結構。
3.2 實現流程
本文結構化數據的實現較為簡單,可參見圖2所示,通過把地址描述分詞,并抽取出地名、名詞和方位詞,將其轉換位特征值。如果地址描述分詞后存在對應的特征值,將特征值置為1,否則為0,再結合其經緯度,形成完整數據結構。最后通過上述的預處理,得到可用的結構化數據,部分數據見圖3所示。
4 預測結果以及評估模型
實驗得到的預測結果如圖4所示(部分):
評估模型的方法有很多,這里筆者只用最簡單有效的一種方法——求均方誤差。
其公式如下:
實驗評估得到的結果為:0.002014969960158303
4 結論
總體來說,在只有拉勾網數據的情況下,這樣的誤差已經比較理想。由于沒有上海市更多和更加完整的地址描述文本的信息,并受限于設備,無法進行更多關于本文所提出的數據結構對地理位置預測有效性的實驗。但是,如果有更多有效數據,預測值的偏差會更小。
參考文獻:
[1] 李德仁.論21世紀遙感與GIS的發展[J].武漢大學學報·信息科學版,2003,28(2):127-131.
[2] 李欣海.隨機森林模型在分類與回歸分析中的應用[J].應用昆蟲學報,2013,50(4):1190-1197.
[3] 唐旭日,陳小荷,張雪英.中文文本的地名解析方法研究[J].武漢大學學報·信息科學版,2010,35(8):930-935,982.
[4]HillLL.Georeferencing:theGeographicAssociationsofInformation[M].Cambridge:MITPress,2009.
[5] 江洲,李琦.地理編碼(Geocoding)的應用研究[J].地理與地理信息科學,2003,19(3):22-25.
[6] Goldberg D W,Wilson J P,Knoblock C A.FromTextto Geographic Coordinates:The Current State of Geocoding[J].URISA Journal,2007,19(1): 33-46
[7] Leidner J L. Toponym Resolution in Text: Annotation, Evaluation and Applications of Spatial Grounding of Place Names[D].Edinburgh: University of Edinburgh, 2007
[8] Aurélien Géron. Hands-On Machine Learning with Scikit-Learn and TensorFlow [M].南京:東南大學出版社,2017:173.
[9] [美] Jake VanderPlas.Python數據科學手冊[M].陶俊杰,陳小莉譯.北京:人民郵電出版社,2018:374.
[10] Stephen Lucci,DannyKopec. Artificial Intelligence in the 21st Century [M]. 北京:人民郵電出版社,2018:277-288.
【通聯編輯:唐一東】
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
