
測繪數據處理中的MPI并行技術應用研究
2022-06-07 09:21:36欒鑒
科學與信息化 2022年10期
欒鑒
安徽省地質測繪技術院 安徽 合肥 230022
引言
隨著科技進步,測繪工作中應用的工具和技術越來越先進,測繪數據呈現出爆發式發展,通過并行技術對測繪數據處理成為現階段研究重要方向。并行技術的應用可以實現大規模的計算工作,通過將計算任務分解為多個小任務,由不同處理器進行同時處理,快速提高測繪數據的處理速度,大幅縮短測繪數據計算時間,提高測繪工作的生產效率。
1 MPI并行技術
MPI作為常見并行編程環境,在石油開采、測繪學、生物醫學、核工業、空氣動力學等領域中廣泛使用。MPI是信息傳遞接口標準,包括多個信息傳遞函數組合而成的函數庫,提供JAVA、C++、Fortran等專用接口。MPI吸收了P4、PVM、Express等消息傳遞的優勢,具有較強的可移植性,可以在各類計算機中應用。同時具有良好的拓展性,可以大規模并行,提供異步通信功能,為MPI發展奠定了良好的基礎[1]。在測繪工作中使用地理測繪技術、遙感影像測量技術以及激光點云技術等獲取數據,并使用對應的算法進行計算解析,獲取目標數據。但由于算法耗時長,計算效率較低,通過MPI并行技術的使用有利于加快計算效率,縮短計算耗時,更有利于提高信息傳遞和數據共享的效率,為測繪工作的開展提供有力支持。
2 測繪數據處理中MPI并行技術的應用
2.1 并行ICP算法
在測繪工作中廣泛使用激光點云技術進行測繪,對點云配準主要采取ICP算法進行,但由于ICP算法實時性差、計算量大,需要使用ICP進行多幅點云配準,浪費較多時間。因此將MPI并行技術和ICP算法相結合,提高配準速度。ICP算法配準是對兩幅點云配準前搜索點云中最近的匹配點,通過搜索最近點對,計算參考點云中任一點到目標點云的距離,通過對比選擇最近一點作為對應點。最近點的算法計算量較大,電數多時耗時更長。使用MPI進行多幅點云并行配準,從而有效縮短耗時。點云配準耗時原因在于獲取相鄰變換矩陣,充分利用MPI計算相鄰變換矩陣,再行交換,最終獲取全局變換矩陣。如下圖所示為并行匹配七幅點云。其中P1/P2/P3表示并行進程1/2/3,Ii代表點云,每個進程先讀取點云數據,并行進程能獲得相鄰變換矩陣Ti-(i+1),Ii代表分局變換矩陣,即和第1幅點云變換矩陣。在進程分局變換矩陣后,進程要對最末各分局變換矩陣聚合廣播。每個進程通過共享獲得全局變換矩陣。每個進程獲得的全局變換矩陣將對應點云坐標變換至源點云坐標系之下,最終實現并行輸出。
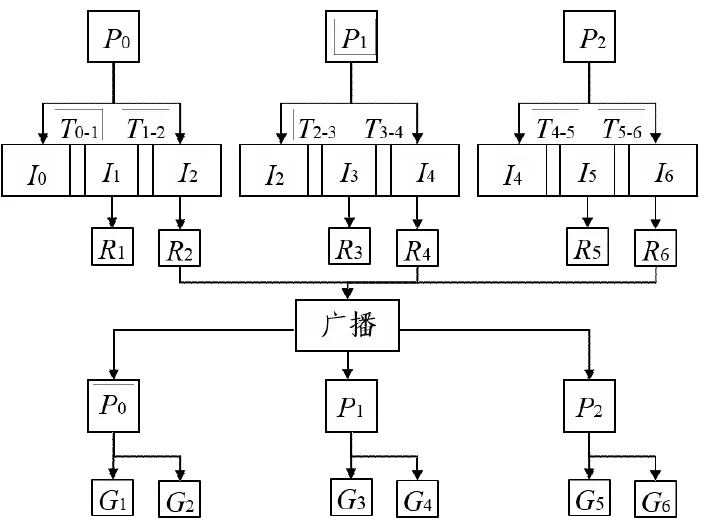
圖1 并行匹配多幅點云
由于點云PCD文件存儲包括二進制和文本兩種,文本類型點云數據耗時長,用MPI并行讀取可以縮短耗時。讀取80幅文本類型PCD文件,耗時200.35s,由于進程數增加,耗時會隨之減少,在進程數為16時,耗時達到最低值19.25s。當進程數逐漸增加,加速比降低。二進制點云數據進行讀取,速度更快,80幅點云數據讀取耗時只需要1s左右[2]。點云配準為了更準確控制配準過程,取消各項迭代終止閾值,迭代次數設定30次。不管迭代結果,次數達到30次即停止。如下表所示,在串行配準中進程數增加,耗時逐漸減少,直至達到進程數16,達到耗時最小值和加速比最大值。當進程數進一步增加時,耗時也會逐漸增加。由于服務器有16個核,借助于超線程技術對CPU進行拓展。當進程數達到16和32時,并行效率接近。隨著進程數的增加,由于進程之間出現競爭資源的關系,造成加速比降低。服務器計算資源十分有限,進程數的增加均分計算資源,造成相對效率的持續降低。因此要根據計算機核數選擇配準最優進程,避免進程數超過CPU數量。
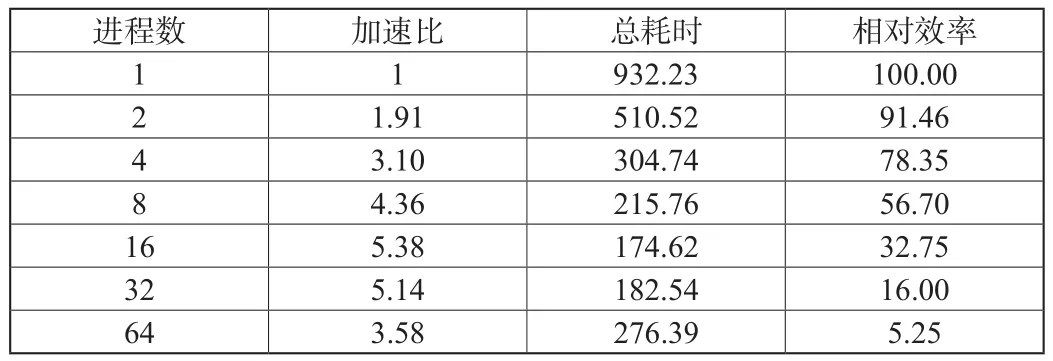
表1 點云并行配準分析
2.2 并行球諧綜合法計算
根據地球重力模型對大地水準面、重力異常、擾動位以及垂線偏差等進行計算均使用球諧綜合法。由于計算量大使用地球重力場模型對格網重力場元進行計算,計算過程耗時長。任何一個質點都受到重力作用,重力位W計算公式為:
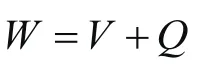
式中,W為重力位,V為引力位,Q為離心力位。
但由于地球內部密度不均勻,表面不規則,重力位只是理想狀態下,正常重力位()和真實重力位存在擾動位(T)差距,計算公式為:
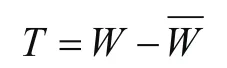
正常重力位是按照橢球重力位參考計算,按照球諧函數,引力位可以通過下式計算:

式中,r, , 表示地心向徑、余緯、經度;GM表示地心引力常數;n和m表示階和次;Snm和Cnm表示規格化引力位系數;Cn0x表示正常引力位系數;R表示橢球長半徑;Pnm(cos)表示締合勒讓德函數。
為了讓計算效率得到提高,先對地球重力場元計算公式進行求解,引入數組避免傳統算法重復計算的問題。MPI并行技術可以并行計算大規模重力場元的計算。進行格網重力場元計算時采取逐緯度計算,重力場元的緯度帶保持獨立關系,數據并行模式將緯度帶作為基本單元。MPI并行技術可以對格網進行分解,形成多個緯度帶,緯度帶分配給多個進程計算[3]。由于緯度帶獨立運行,計算過程中不需要通信。計算結束后可以將進程結果收集至根進程,通信開銷相對較小,可選擇主從模式并行,方便于管理。分解格網可以選擇維度循環分解以及維度分塊分解,維度分塊分解由每個進程負責對緯度帶的處理,維度循環分解,由進程連續負責多個緯度帶。MPI數據收集按照進程號進行收集,先將進程存放至數組中,逐個存在進程數據。使用維度分塊的分解模式直接輸出收集結果。根據維度循環分解模式對結果的收集需要變換順序才能輸出,運算量更大,因此建議選擇維度分塊分解模式。
2.3 并行SIFT算法
SIFT作為一種精度高的算法,在圖像配準中廣泛使用,由于SIFT算法較為復雜,耗時較多,實時性差,要想讓SIFT配準速度加快,使用MPI并行技術予以處理。SIFT算法包括圖像采樣、高斯平滑濾波、高斯差分金字塔等步驟,各個步驟之間并行難度較大。SIFT算法處理數據是將圖像分塊處理,每塊作為獨立塊搜索特征點,最終集合匹配所有特征點。在數據并行中,除了收集分塊特征點外,每個步驟可以單獨完成進程,不需要通信,大幅減少通信開銷。同時還要考慮圖像大小和硬件條件,選擇最合適的進程數量,快速完成圖像配準。SIFT算法并行數據方便于編程,通信需求少,并行程度更高。將圖像分為九塊,每塊對應著進程1~9處理,最后收集特征向量,完成特征向量提取。為了減少圖像邊緣對于特征提取產生的影響,每個進程都可以經過平均分塊,高和寬均可以增加適當寬度,作為重疊分割。由于SIFT算法特殊,圖像分割后,提取特征因素較多,包括特征點剔除、分塊大小等因素,因此重疊分割寬度并不具備明確標準。剔除邊緣特征點即設定閾值,剔除圖像邊緣特征。提取特征向量后需要匹配圖像特征向量,將圖像分為四塊,分別將各圖像進程提取的特征向量收集到進程內。由進程獨立對特征向量匹配,最后得到匹配特征向量。提取特征向量采取并行方式,匹配特征向量采取串行方式。在特征向量不多的情況下,特征樹串行匹配可以滿足用戶需要[4]。但特征向量較多時,特征樹串行匹配將耗費較多時間。各個進程完成特征提取后,將特征收集并發送至進程,每個進程需要建立圖像特征點,將圖像特征樹的點和進程提到圖像特征匹配,將進程獲得的分塊特征點收集至進程中,匹配和提取并行。
SIFT算法和MPI并行配準主要經過圖像分塊、封裝特征、發送特征以及拆封特征幾個部分。對圖像分塊后提取圖像的特征量,形成特征描述子。進程可以獲得特征點的坐標,將其轉換至原圖坐標系。由于MPI采取通信,各進程提取特征量按照順序封裝數組,再通信。各進程對應特征向量封裝數組后,發送給其他進程。由于提取特征量不同,發送特征量前需要先發送個數,根據特征個數預留儲存空間。特征向量發送至指定進程中,函數將特征向量發送至給所有進程,收集完畢后進行拆封,按照順序保存至對應結構中。其中圖像分塊會對匹配特征點產生影響,將特征匹配點通過圖形方式表示數據,特征匹配點隨著分塊數量增多而減少。由于不同進程對應圖像特征數量不同,進程特征匹配耗時也明顯不同,總耗時是由匹配最大值決定。將匹配最大值衡量匹配效率。在進程數為16時,耗時最低,加速比達到最大值。當進程數為4時,特征匹配和耗時減少最明顯。隨著進程數增加,耗時逐漸增加。進程數越多分攤了特征樹搜索任務,充分建構特征樹。隨著進程數增加,各進程占用資源減少,耗時增加。耗時增加也影響到特征樹匹配的效率。因此按照PCU個數進行并行進程數量的確定,可達到最低耗時,雖然特征樹并行匹配耗費更多通信資源,但匹配速度得到明顯提升。
4 結束語
綜上所述,測繪工作處理測繪工具時應用MPI并行技術,能夠充分利用計算機資源并行處理多進程,大幅提高數據處理效率。主要體現在格網重力場元測繪數據、攝影遙感影像數據、激光點云數據的處理上,通過和SIFT算法、ICP算法以及球諧綜合法的并行計算,有效縮短計算耗時,提高數據處理效率,為測繪工作提供支持。

猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國外匯(2019年20期)2019-11-25 09:54:58
浙江國土資源(2019年10期)2019-10-31 03:17:00
建材發展導向(2019年10期)2019-08-24 06:25:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國公共安全(2017年7期)2017-10-13 08:18:11
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電子制作(2017年9期)2017-04-17 03:01:00
民主與科學(2014年3期)2014-02-28 11:23:03
河南科技(2014年23期)2014-02-27 14:19:15
