面向多元時序數據的個性化聯邦異常檢測方法
2022-06-09 11:57:42王昊天鄭棟毅
計算機工程與應用 2022年11期
王昊天,鄭棟毅,劉 芳,肖 儂
1.國防科技大學,長沙 410073
2.湖南大學,長沙 410006
多元時間序列數據已經廣泛應用于現實世界中各個領域,例如天氣數據分析和預測[1]、醫療保健[2]、金融[3]等[4-5]。異常檢測是多元時間序列分析中的一類重要問題,目的是檢測出不符合期望行為的序列數據,是數據挖掘關鍵技術之一。隨著深度學習在學習復雜數據的特征表示方面表現出顯著的優勢[6],近年來使用深度學習方法進行異常檢測受到越來越多的關注。例如,深度自動編碼高斯混合模型(DAGMM)[7]綜合考慮了深度自動編碼器和高斯混合模型來對多維數據的密度分布進行建模;LSTM編解碼器[8]利用長短期記憶網絡(long short-term memory,LSTM)對時間序列中的時間相關性進行建模取得了較好的泛化能力。
但是,目前多元時序數據異常檢測仍面臨挑戰。以飛行數據異常檢測為例,飛行數據是典型的多元時序數據,有效的異常檢測將提高航空系統的安全性和可靠性,并改善著陸后的維修行動組織。然而飛行數據具有高度商業機密性,造成了通用航空公司之間的數據壁壘;同時,不同類型、不同任務的飛行器生成的飛行數據具有高度不同的概率分布,使用單一的統一的檢測模型不能適用于所有場景。因此,目前存在的挑戰概括為以下兩點:(1)由隱私安全帶來的數據孤島問題,使得一些領域內的數據難以融合,無法訓練出高性能的異常檢測模型。(2)由于來自不同機構的時序數據可能自發地呈現出非獨立同分布的特征,例如特征分布偏斜、標簽分布偏斜和概念偏移[9]等,這種統計異構性會導致嚴重的性能下降。
針對以上問題,本文提出了FedPAD,用于多元時序數據異常檢測的個性化聯邦學習框架。FedPAD可以同時解決數據孤島和個性化問題。通過聯邦學習[10]和同態加密[11],FedPAD聚合來自不同機構的數據,在云端構建高性能的深度異常檢測模型,同時很好地保護了隱私數據。云模型建立后,FedPAD利用fine-tuning(微調)進一步為每個機構訓練出個性化異常檢測模型。
本文的主要貢獻:(1)提出了一個面向多元時序數據的個性化聯邦異常檢測框架FedPAD,它在保護隱私安全的前提下聚合了來自不同機構的數據,并將LSTM時序預測模型與深度學習的fine-tuning技術結合,得到了相對個性化的檢測模型。(2)展示了FedPAD在NASA航天探器數據集上的異常檢測性能。實驗表明,與基準方法相比,該方法有效提高了精確率與召回率。
1 相關工作
1.1 基于預測的多元時序異常檢測模型
LSTM-NDT[12]使用長短期記憶網絡來實現高性能的時序數據預測,同時保證了整個系統的可解釋性。模型生成預測數據后,使用一種非參數、動態的閾值方法來評估殘差。具體來說,設yi為輸入序列第i時間步的信號值,為模型預測輸出的序列第i時間步的信號值,那么預測誤差為e i=y i-,用多個時間步的誤差來計算閾值序列ε:

其中,e s是多個時間步的誤差序列,μ(·)是均值,σ(·)是標準差,z是權重系數。每一個時間步的閾值εi是動態變化的,取決于之前整個閾值序列ε的最大值,計算公式如下:
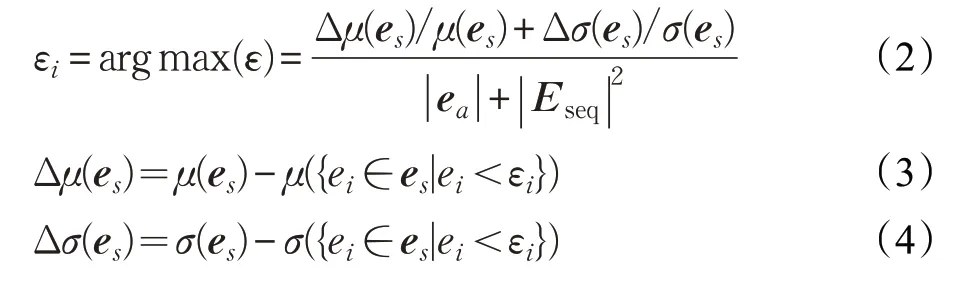
其中,e a是異常序列的誤差值,Eseq是異常序列中的連續異常的誤差值,表達式如下:

除此之外,還使用了剪枝方法來減少誤報,將所有誤差序列中的最大值emax按照降序排列得到e s,然后遍歷序列計算下降百分比d i:

如果d i超過了最小百分比p,那么相關的異常序列仍為異常;如果d i和所有后續下降百分比都沒有超過p,那么這些誤差序列重新分類為正常序列。
1.2 聯邦學習及個性化
聯邦學習最早是在2016年由Google提出的[13]。其設計目標是在保證數據交換過程中的信息安全、保護個人數據隱私、確保法律合規的前提下,在多個參與者或計算節點之間進行高效學習。聯邦學習能夠有效地解決數據孤島問題,在很多領域已經有了實際應用,例如,它對于移動設備上的下一個單詞預測問題表現出了良好的性能和魯棒性[14]。Bonawitz等人[15]提出一個可擴展的系統,在移動設備上實現大規模的聯邦學習。Guo等人[16]在興趣點推薦任務中使用邊緣加速聯邦學習框架,在保護隱私的同時,實現了高效的推薦性能。
機構參與聯邦學習的主要動機是獲得更好的模型,然而,對于那些擁有足夠的本地數據來訓練高效模型的機構來說,參與聯邦學習得到的全局模型可能并不適用于其本身的檢測任務。Yu等人[17]表明,對于許多任務,由于全局共享模型不如局部模型精確,所以一些參與者可能無法通過聯邦學習來提高模型性能。Hanzely等人[18]對全局模型的性能提出了質疑,由于跨客戶端的數據是非獨立同分布的,這種統計異構性導致很難訓練出一個對所有客戶都適用的單一模型。為了解決這種異構性的挑戰,規范的聯邦學習方法——聯邦平均法(FedAvg)被證明能夠處理某些非獨立同分布數據。然而,當面對高度偏斜的數據分布時,FedAvg可能會導致嚴重的性能下降。具體來說,一方面,非獨立同分布數據會導致聯邦學習過程和傳統集中式訓練過程之間的權重差異,FedAvg最終將得到比集中式方法性能更差的模型[19]。另一方面,FedAvg只從數據中學習粗略的特征,而無法學習特定任務數據上的細粒度特征。
為了應對統計異質性和數據的非獨立同分布帶來的挑戰,個性化的全局模型變得十分必要。大多數個性化技術[20]通常包括兩個步驟。第一步,以協作的方式訓練一個全局模型。在第二步中,使用客戶端的私有數據為每個客戶端個性化全局模型。Arivazhagan等人[21]提出了FedPer,主張將深度學習模型視為基礎+個性化層,基礎層作為共享層,使用現有的聯邦學習方法以協作方式進行訓練,而個性化層是在本地培訓的。Chen等人[22]首先通過傳統的聯邦學習訓練一個全局模型,然后將訓練好的全局模型傳遞回各個設備,相應地,每個設備都能夠通過用其本地數據精煉全局模型來構建個性化模型。Hanzely等人[18]在傳統的全局模型和本地模型之間作權衡,每個設備可以從自己的本地數據中學習本地模型,而無需任何通信。Zhang等人[23]為了實現個性化,沒有像FedAvg那樣計算模型參數的平均值,而是通過計算出一個客戶端可以從另一個客戶端的模型聚合中受益多少,得出每個客戶端的最優加權模型組合。
2 本文方法
2.1 問題定義
{S1,S2,…,S N}代表來自N個不同的機構{Q1,Q2,…,Q N}的時序數據,不同機構的數據都有不同的分布。傳統集中式的方法使用全局數據S=S1∪S2∪…∪S N訓練一個統一的模型MALL。在本文的問題背景中,希望使用所有的數據來訓練一個聯邦異常檢測模型MFED,在模型訓練過程中,任何機構都不會相互公開自己的數據,模型訓練目標是提高聯邦異常檢測模型MFED的性能,使得異常檢測率接近或優于MALL。
2.2 框架概述
FedPAD旨在通過個性化聯邦學習實現高性能的異常檢測,同時保護隱私安全。圖1給出了框架的概述,以飛行數據異常檢測為例(可以擴展到其他場景),假設有三個通航公司,各有不同類型的飛行器。該框架主要包括四個流程,首先,基于公共數據集訓練服務器上的云模型。然后,云模型被分發給所有機構,每個機構在云模型的基礎上使用本地數據訓練自己的模型。隨后,將機構模型回傳到云端,通過FedAvg來更新云模型。重復以上流程,直到模型收斂或達到指定訓練輪數。最后,每個機構可以利用云模型和本地數據來進一步訓練個性化模型。在這一步中,由于全局數據和機構的本地數據之間存在很大的分布差異,所以通過微調方法使模型更適合本地數據。在整個流程中,通過同態加密,所有參數共享過程都不會泄露用戶數據。
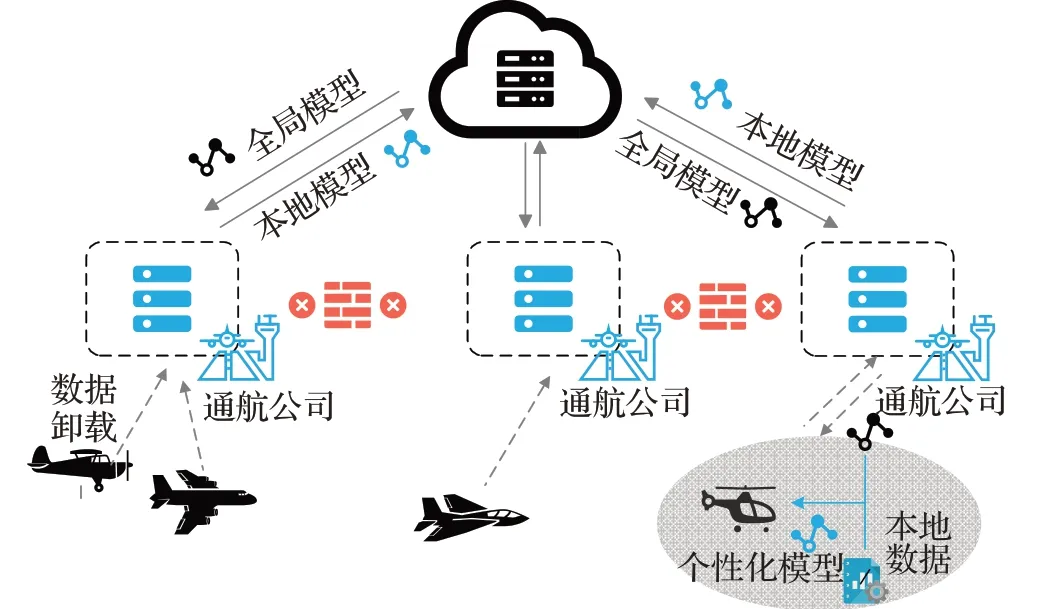
圖1 FedPAD框架概述Fig.1 FedPAD framework overview
2.3 聯邦學習
FedPAD采用聯邦學習范式實現分布式加密模型訓練和共享,解決數據隔離的問題。這一步主要由兩個關鍵部分組成:云模型聚合和機構模型訓練。在FedPAD中,采用基于LSTM時序預測的神經網絡作為云端和機構模型。LSTM通過輸入機構數據來進行端到端的特征學習。云端模型和機構端模型的學習目標分別如式(7)、式(8)所示:
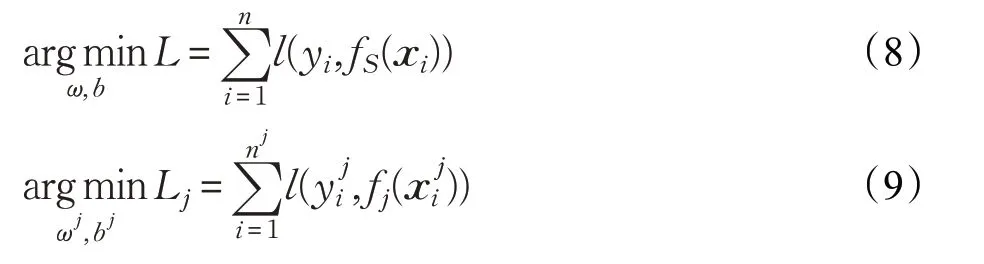
其中,ω和b表示要學習的所有參數,即權重和偏差,l(·,·)表示損失函數,j表示機構編號表示來自全局數據和第j個機構的時序數據實例,n和n j表示數據集的大小。
對所有用戶模型f j進行訓練后,將其上傳到云端進行聚合。使用聯邦平均算法[12]對齊用戶模型,在每輪培訓中對M個用戶模型進行平均,得到平均模型:
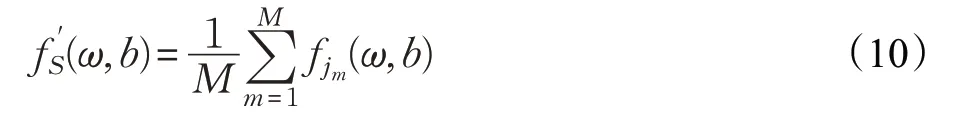
其中,(ω,b)表示神經網絡參數,M表示機構數量,經過足夠多輪的迭代,云端模型具有更好的泛化能力。
2.4 個性化學習
聯邦學習能夠解決數據孤島問題,因此,FedPAD可以使用所有的機構數據來構建異常檢測模型。此外,另一個影響性能的重要因素是數據的統計異構性。在特定機構上直接使用云模型的性能仍然很差,這是由于單一機構數據和全局數據之間的分布差異。云端的通用模型只從所有機構那里學習粗略的特征,而無法學習特定機構數據的細粒度特征。Yosinski等人[24]證明在深度神經網絡中,較低層的特征是高度可遷移的,因為它們集中于學習共同的和較低層次的特征,網絡中的較高層將學習任務中更具體的特征。因此,在獲得云模型之后,機構使用fine-tuning方法來實現個性化的機構模型,過程如圖2所示。神經網絡由兩個LSTM層、兩個Dropout層、一個Dense層和一個Linear層組成。輸入是多元時序數據,輸出是預測時序數據。FedPAD保持較低層(LSTM和Dropout)凍結,并調整較高層(Dense和Linear)的參數。
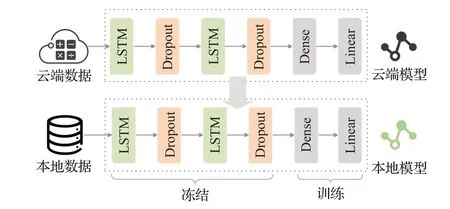
圖2 FedPAD微調過程Fig.2 FedPAD fine-tuning process
2.5 算法流程
在算法1中介紹了FedPAD的模型訓練流程。當機構生成新的數據時,FedPAD可以同時更新機構模型和云模型。因此,使用FedPAD的時間越長,模型性能就越好。
算法1FedPAD模型訓練流程

3 實驗與結果分析
3.1 數據集
NASA開源的專家標注的真實世界航天器故障數據集[11]包括火星科學實驗室好奇號(mars science laboratory rover,MSL)和土壤水分主動被動探測衛星(soil moisture active passive,SMAP),共計82個通道、105個故障,數據集描述如表1所示。

表1 FedPAD模型訓練流程Table 1 FedPAD model training process
3.2 評估指標
為了與LSTM-NDT[12]提出的基準進行直接比較,采用序列數據異常檢測任務中常用的Point-based檢測指標,即當預測異常與真實值有交集時記為true positive,預測異常與任何真實值均無交集時記為false positive,真實值與任何預測值均無交集時記為false negative,其中,精確率(Precision)、召回率(Recall)與F1值的計算均與一般的檢測任務相同:

其中,TP為真陽性,FP為假陽性,TN為真陰性,FN為假陰性。
3.3 實驗設置
NASA航天器數據集中,通道之間的時序數據具有相同的特征維度,但在特征分布上具有較大差異性,即統計異構性,這符合本文的問題背景。因此,將每一個通道的數據作為一個機構的數據,即在SMAP上的實驗中有55個機構節點,在MSL上的實驗中有27個機構節點,進行FedPAD模型訓練。LSTM-NDT方法使用每一個通道數據單獨訓練一個模型,為了更直觀的比較,使用與LSTM-NDT相同的模型架構和參數,如表2所示。
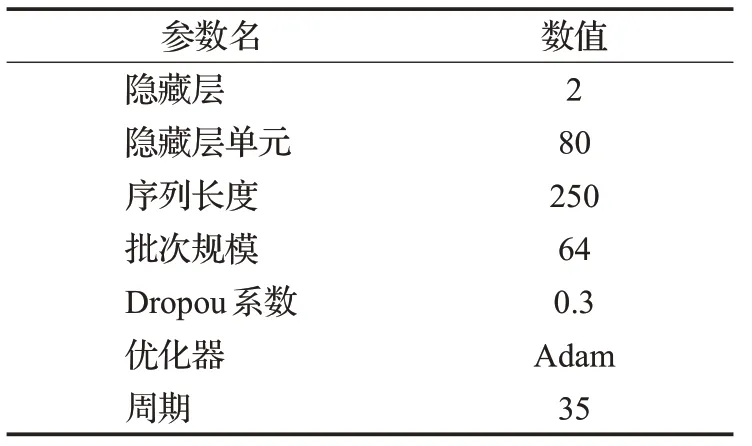
表2 模型架構及參數Table 2 Model architecture and parameters
3.4 結果分析
將FedPAD與LSTM-NDT作比較,同時記錄了僅使用聯邦學習(FED)的性能。
如表3所示,與LSTM-NDT相比,僅使用聯邦學習進行模型訓練雖然能解決數據孤島問題,但由于數據的統計異構性,FED模型的預測性能在兩個數據集上都出現了下降,整體預測誤差增加了1.2個百分點。同時,FedPAD整體預測誤差下降了1.6個百分點,比LSTMNDT方法表現得更好,這是因為聯邦學習可以間接學習到來自多個機構的數據特征,進而訓練更好的模型,并且通過微調,模型變得更加個性化,更能適應每個機構的數據特征。
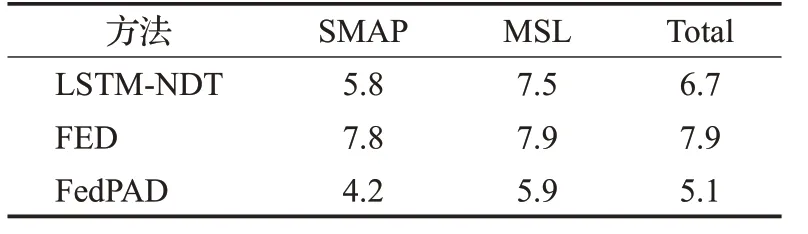
表3 遙測預測誤差Table 3 Telemetry prediction error %
在LSTM-NDT方法中,剪枝參數p是控制精確率和召回率的重要參數,通過調整參數p實現精確率和召回率的權衡。在本文的實驗中,將p作為控制變量,比較三種方法在兩個數據集中異常檢測的性能表現。如圖3、4所示,在不同的參數p下,FED方法性能最不穩定,精確率和召回率無法同時達到較高水平。而Fed-PAD方法,僅在SMAP數據集中的p取較低值時性能略低于LSTM-NDT,其他情況下精確率和召回率均高于LSTM-NDT,這得益于fine-tuning提高了LSTM模型的預測性能。
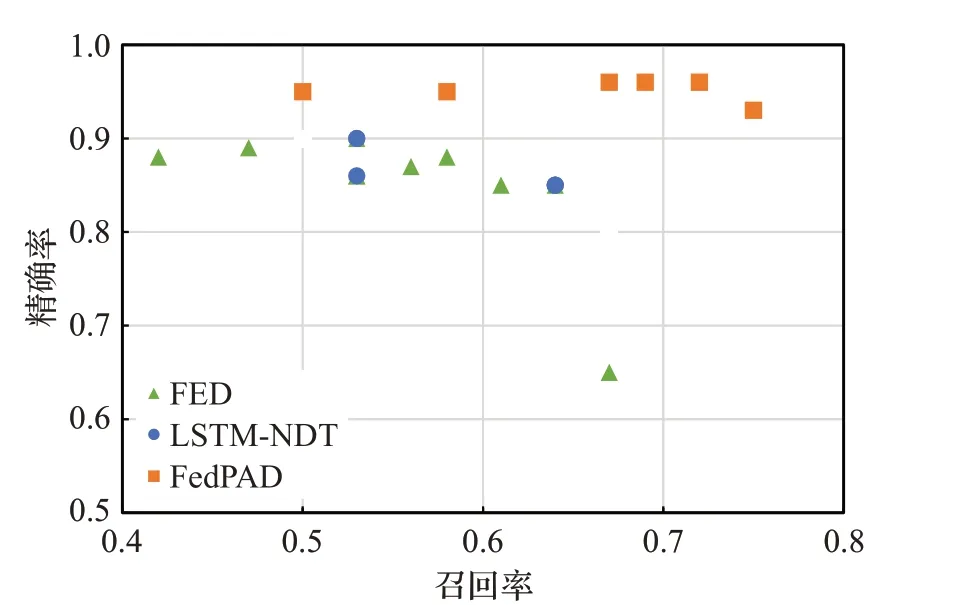
圖3 三種方法在MSL數據集中的性能比較Fig.3 Performance comparison of three methods in MSL dataset
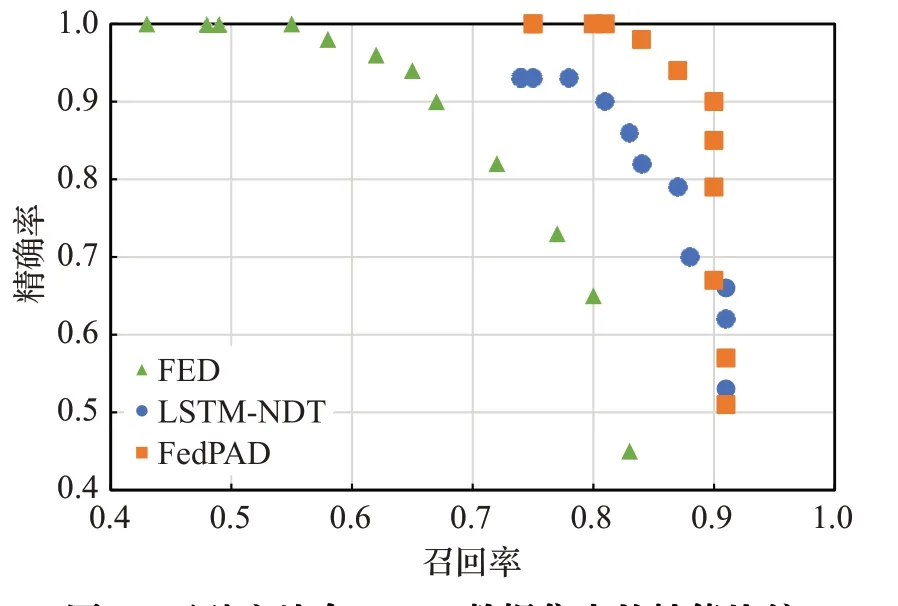
圖4 三種方法在SMAP數據集中的性能比較Fig.4 Performance comparison of three methods in SMAP dataset
如表4、5所示,記錄了三種方法在不同參數p下的平均性能表現。與LSTM-NDT相比,FED在兩個數據集上的F1分數分別下降了4.3%、10.9%,FedPAD在MSL數據集上的異常檢測F1分數提高了10.1%,在SMAP數據集上提高了3.6%,平均F1分數提高了6.9%。這再次證明了FedPAD在提高異常檢測性能上的有效性。其中的原因是,在聯邦學習和微調過程中,FedPAD中每個數據機構上的異常檢測模型都可以學習到其他機構的數據特征,提高了模型的推理性能。由于數據集的異構性,使用統一的聯邦學習模型更容易出現誤報率增加或模型魯棒性降低的問題。FedPAD能夠解決這些問題,因為它通過微調為每個數據機構構建了更加個性化的異常檢測模型。
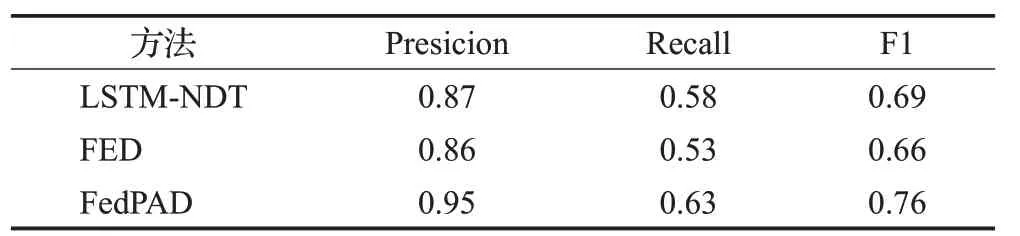
表4 MSL數據集上的平均性能對比Table 4 Average performance comparison on MSL Datasets
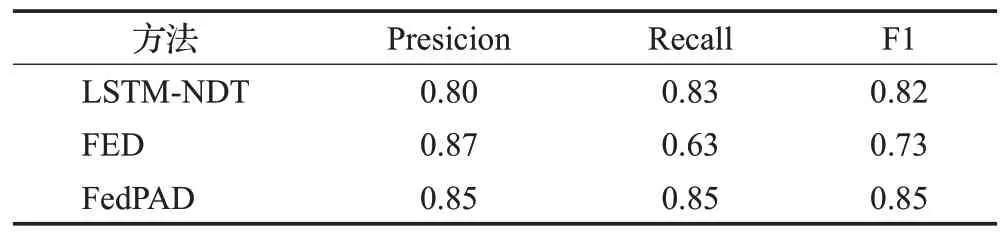
表5 SMAP數據集上的平均性能對比Table 5 Average performance comparison on SMAP datasets
4 結束語
針對多元時序數據異常檢測,提出了一種基于個性化聯邦學習的異常檢測框架FedPAD。FedPAD基于聯邦學習框架,能夠在不泄露數據和隱私的情況下,學習不同機構的時序數據特征,在各自機構端使用本地數據對模型fine-tuning獲得個性化檢測模型。實驗表明,通過檢測NASA航天器數據異常,FedPAD的異常檢測F1分數比基準方法平提高了6.9%。未來,計劃使用更多的深度異常檢測模型來驗證模型的可擴展性,以及通過增量學習以實現更加靈活和個性化的異常檢測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
