銀行客戶分類的數據特征選擇方法與實證研究
2022-06-09 12:00:18段剛龍楊澤陽
計算機工程與應用 2022年11期
段剛龍,王 妍,馬 鑫,楊澤陽
西安理工大學 經濟與管理學院,西安 710054
隨著信息化水平的提升和物聯網(Internet of things,IoT)技術的快速發展,教育、通信、金融和醫學等領域數據呈指數式增長,海量數據的累積標志著大數據時代的到來。金融大數據是大數據的重要板塊,全國各大金融機構每年都會產生大量數據,一般金融機構每年產生結構化數據已超5 PB,非結構化數據超過15 PB,每次網上支付業務僅記錄用戶行為的數據量就達1 GB。數據內容涵蓋金融產品數據、個人刷卡消費數據、客戶基本信息數據、開戶數據、客戶各自信用數據等。其中的銀行客戶數據是金融大數據的重要組成部分,不僅包括受教育程度、婚姻狀況、受教育年限等客戶個人靜態數據,還包含客戶日均消費次數、日均消費金額、預期還款天數等消費行為的動態行為數據,包含了大量的有價值知識。研究者可通過統計分析或機器學習等方法挖掘數據集中潛在的規律、模式、經驗或知識[1-3],輔助銀行實現“以客戶為中心”的精準營銷、風險管控和核心競爭力提升。
但由于銀行客戶數據維度高、量級大和冗余特征多[4]的特點,為知識挖掘與發現帶來了諸多挑戰,降低了數據價值密度,影響客戶分類模型效率,易產生維數災難[5-6],而現有針對高維數據特征選擇方法的相關研究主要集中于單一視角,并未將人類先驗認知考慮在內,且很少有針對銀行客戶數據特征選擇的系統性研究,因此,本研究以高維銀行客戶數據為研究對象,綜合統計、機器學習、先驗認知、多模態融合思想,對銀行客戶數據特征選擇方法進行研究。
本研究的主要貢獻如下:
(1)綜合考慮現有與銀行客戶分類有關的研究成果以及真實銀行客戶數據特點,本文給出了一種可用于銀行客戶分類特征篩選研究的數據預處理方案,該方案共包括類型轉換及離散化、缺失值填充和標準化三部分,能有效提升真實銀行客戶數據質量。
(2)鑒于單一特征篩選方法在不同場景下存在性能受限的問題,本文在多模態視角下,綜合考慮主觀特征選擇方法和客觀特征選擇方法,提出了一種綜合性的特征篩選方法。
(3)本文給出了一種較為系統且全面的銀行客戶分類特征選擇效果評價方法,該方法包括定性評價與定量評價兩部分。其中,定性評價主要對各特征選擇方法的原理、適用條件和特征選擇占比等指標進行比較分析;定量評價則是在不同特征選擇方法的特征篩選結果之上比較不同銀行客戶分類模型的精確度(ac)、測試集精確度(tc)、查全率(tl)、查準率(pd)、召回率(rl)、F1-score(f1)以及模型訓練成本(ct)共計7個指標。
(4)針對不同特征選擇方法,本文設計并實行了一種包含4種特征選擇方法、4種定性評價指標和7種定量評價指標的實驗方案。實驗結果表明,相較于單一特征選擇方法,本文提出的特征選擇方法更具多元性與全面性,能夠為銀行客戶數據知識挖掘與發現提供參考。
1 研究現狀
銀行客戶數據的核心價值在于構建用戶畫像,深度挖掘用戶統計學信息、消費行為、社會關系和情景信息,為揭示用戶行為特征并進行精準營銷和風險管控等提供理論支持和現實依據[7-8]。目前,國內外學者已將其應用于加強渠道服務體系的建設[9]、客戶信用風險評估[10]、重要基金客戶識別[11]、小微金融客戶續貸預測[12]和個人客戶價值評價[13-14]等多項研究。隨著信息技術發展,銀行客戶數據傳輸和存儲成本大大降低,不僅數據體量逐年增大、數據類型增多,且數據維度提高,價值密度有所降低,這些變化在為銀行客戶數據應用提供充足“養分”的同時,也為知識挖掘與發現帶來了巨大挑戰。
國內外相關學者針對數據特征選擇的相關研究,主要有兩大類:統計學方法[15-16]和機器學習方法[17-23]。部分常見的具有代表性的特征選擇方法及原理如表1所示。

表1 特征選擇方法與原理Table 1 Method and principle of feature selection
基于統計的特征選擇方法通過計算不同特征與目標屬性之間的相似度或空間距離,按照排序結果從大到小對特征進行篩選,該種特征選擇方式雖能對特征進行篩選且效率較高,但篩選效果較差,對數據預處理質量依賴較大,篩選后特征包含過多的冗余特征,從而影響最終的模型性能。相比之下,基于機器學習的特征選擇方法的特征篩選能力更強,性能更優,因此被廣泛應用于特征選擇當中,依據特征中子集評價標準同后續算法的結合方式可分為:嵌入式(embedded)、過濾式(filter)和封裝式(wrapper),算法通用性強,可快速去除大量不相關特征,但所選擇特征的通用性較低且忽略了低貢獻度特征,當改變算法,則需進行針對性的訓練和測試,模型訓練成本較高。
從國內外現有針對銀行客戶數據的應用以及高維度數據集特征選擇方法的研究成果可見,研究大多集中于單一特征選擇方法的應用與優化,篩選出的特征準確性還有提升空間,多角度綜合性的銀行客戶數據降維方式特別是融合人先驗認知的研究相對較少。因此,本研究旨在提出一種有效的銀行客戶數據挖掘方法,來降低數據特征冗余,提高銀行客戶分類的模型精度,降低訓練成本和構建系統的主題模型。
2 高冗余銀行客戶數據特征選擇方法
黨的十八大以來,銀行遵循“創新、協調、綠色、開放、共享”的發展理念,貫徹實施網絡強國、大數據戰略等一系列重點戰略部署,積極推動銀行信息化建設,穩步推進重要信息系統建設[24]。銀行客戶電子數據正是銀行信息化進程中的典型產物。
銀行客戶數據不僅集成了每個客戶的靜態數據,還記錄了客戶的動態行為數據,形成了具有多個特征的高維數據集,銀行則可通過以上客戶數據對客戶進行精準畫像,及早發現待流失客戶、高風險客戶或高價值客戶等,及時規避金融風險提升銀行效益。然而,數據集中并非所有特征都與客戶分類的目標密切有關,而是存在大量冗余特征,如:卡類型、幣種代碼和戶籍所在地等,此類冗余特征會對模型結果產生較大影響,降低模型性能。因此,對高冗余銀行數據進行挖掘前必須對數據特征進行篩選,降低數據維度。為提高銀行客戶分類模型性能,本文所制定的高冗余銀行數據特征選擇具體流程如圖1所示。
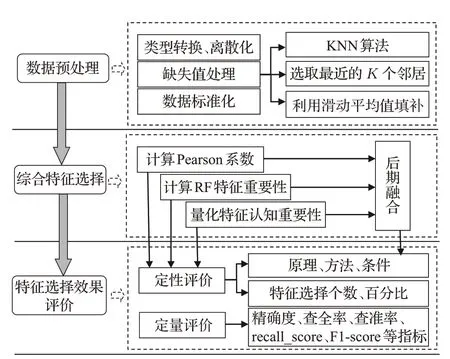
圖1 高冗余銀行客戶數據特征選擇流程圖Fig.1 Flow chart for feature selection of high redundancy bank customer data
2.1 數據預處理
在實際情景中,特征值缺失的情況經常發生甚至是不可避免的。采集自銀行信息系統的已整合有序原始數據同樣也不例外,因人為因素或機械因素導致原始數據中存在較多缺失值,數據價值密度較低,對銀行客戶數據的挖掘與分析產生不利影響,因此,需要對原始數據缺失值進行填補,缺失值填充方式有三大類:刪除、補齊和忽視。常用缺失值處理方法如表2所示。
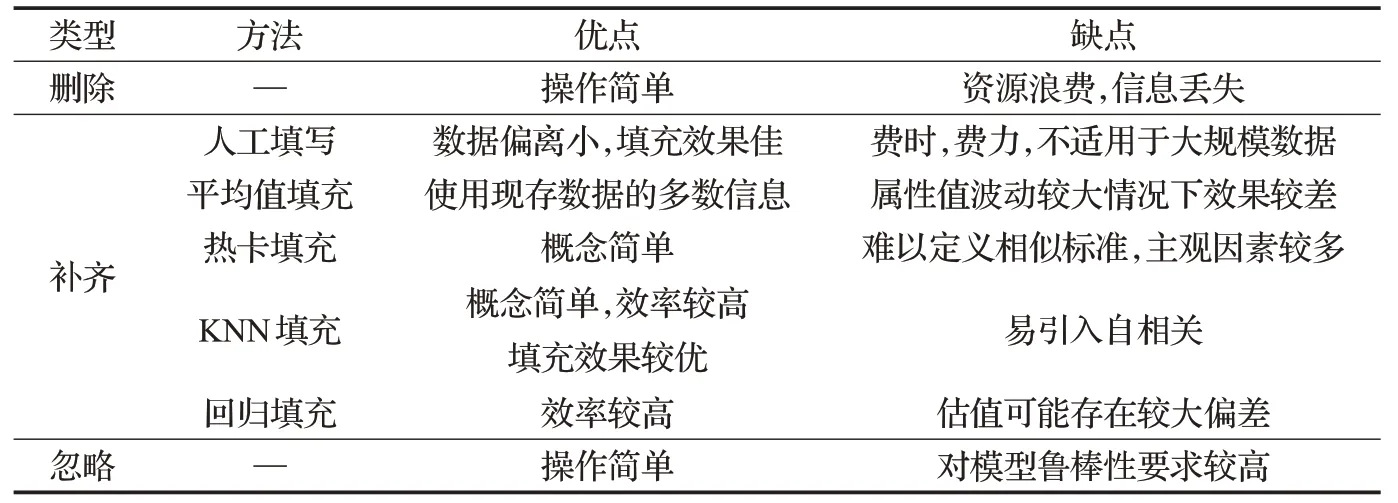
表2 缺失值處理方法及優缺點Table 2 Missing value processing methods and advantages and disadvantages
無論采用何種方式對缺失值進行填充,均無法避免主觀因素對原始數據的影響,因此,本文綜合考慮表2中各填充方法優缺點及銀行客戶數據缺失值分布較為集中特點,采用KNN算法對缺失值進行填充,但KNN計算的填充值為均值計算結果,對特征值的波動較為敏感,故采用滑動平均值替換算數平均值對缺失值進行填充,填充過程如圖2所示。具體操作過程如下:
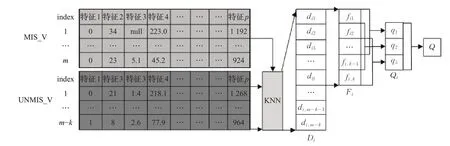
圖2 缺失值填充過程Fig.2 Missing value filling process
(1)將含n個對象p個特征的原始數據劃分為兩部分:包含m個對象的缺失值數據集MIS_V和m-k個對象組成的非缺失值數據集UNMIS_V。
(2)分別計算MIS_V中的對象obj i到UNMIS_V中的各對象obj j的歐式距離d ij,并組成向量D i={d i1,di2,…,d ij,…,d i,m-k}。
(3)向量D i中各元素按從小到大排序,并選擇前k個最小距離對應對象MINS-Vi的對應缺失值特征的特征值F i={f i1,f i2,…,f ik}。
(4)以步長s=3計算F中所有距離的滑動平均值Q作為填充值進行填充。
此外,由于現有的銀行客戶分類模型如決策樹和CART&Tree等均為基于離散型數據的算法模型,有效的離散化能夠降低模型的時間和空間開銷,提高分類模型的性能與抗噪能力,鑒于離散化特征值相對連續型特征值更易理解,更趨向于知識層面的表達,還可有效屏蔽數據中的隱含缺陷,提升模型的普適性等原因,本文針對待離散化數據以距離d i進行等距離散化:
式中,f i為待離散化特征值,Li為當前離散化特征分段數,d i為分段距離。
2.2 綜合特征選擇
綜合特征選擇是銀行客戶分類數據特征選擇方法的核心步驟,其綜合不同視角的特征選擇方法,將看似雜亂無章的數據映射為不同貢獻度的若干特征,并從各視角互補角度出發融合特征貢獻度,依據最終貢獻度大小篩選原始數據中冗余特征,保留少數能精確反映數據全貌的特征,從低維數據中挖掘知識。綜合特征選擇共包含三部分:客觀特征貢獻度計算、主觀量化特征認知和特征貢獻度融合。前者包含基于統計的特征選擇方法Pearson相關系數和基于機器學習的特征選擇方法RF,后者則為考慮人為先驗認知的特征篩選方法。
(1)基于Pearson相關系數的特征選擇方法
Pearson相關系數(Pearson correlation coefficient,PCC)是用來衡量兩個不同特征之間線性相關程度的統計量,在特征篩選領域是一種經典的基于統計的特征選擇方式,計算的是待篩選特征與目標屬性之間的線性相關關系。
皮爾森相關系數計算公式如下:
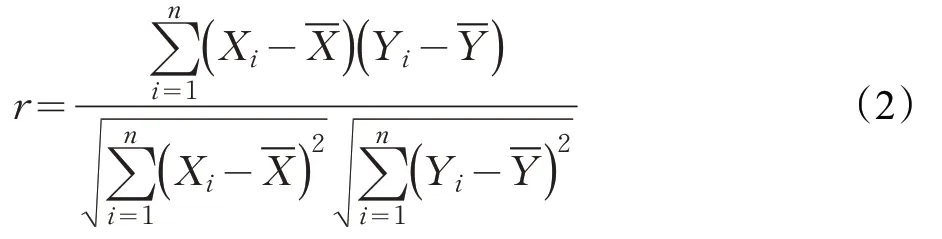
式中,Xi和Y i分別為特征X和Y具體取值,Xˉ和Yˉ分別為特征列X和Y的均值,r為相關系數值,n為樣本量。當r的取值位于[-1,1]之間,若r>0,表明自變量特征X對目標屬性Y存在正相關關系,即X與Y的值同向變化;若r<0,表明自變量特征X對目標屬性Y存在負相關關系,即X與Y的值反向變化;若r=0,則表明兩個特征之間并不存在線性相關關系,但并不能排除其他類型的相關關系。
同時,為使得主觀特征貢獻度和客觀特征貢獻度處于同一量綱,算法需要對相關系數進行歸一化處理,其最終特征貢獻度計算公式如下:

(2)基于隨機森林的特征選擇方法
隨機森林(random forest,RF)作為新興的、高度靈活的機器學習算法,擁有廣泛的應用場景,既可以用來做市場營銷模擬建模,統計客戶來源、保留和流失,也可用來預測疾病風險和患病者的易感性。而RF模型具有一個十分重要的特征,即可計算單個特征的貢獻度,因此常被用來進行特征的選擇。
基于隨機森林的特征選擇計算過程如下:
①對原始數據集X進行隨機有放回抽樣形成袋內數據,未抽中數據形成袋外數據(OOB),即測試集數據。
②利用袋內數據構建RF模型。
③對于RF中每一棵決策樹,使用相應的OOB數據計算袋外數據誤差,記為errOOB1。
④隨機于OOB所有樣本特征x中加入噪聲干擾,再次計算袋外數據誤差,記為errOOB2。
⑤假設RF中共ω棵決策樹,則數據集X中各特征的貢獻度計算公式如下:
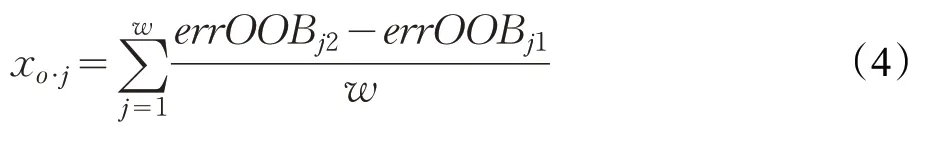
⑥特征貢獻度經公式(3)進行歸一化處理,可得特征貢獻度向量X o=(xo·j)T。
(3)基于量化認知的特征選擇方法
認知(cognition),或稱為心理活動,描述的是知識的獲取、存儲、轉換和使用。人的每一次獲取信息、存儲信息和使用信息的時候認知都會起作用[25-26]。人的認知活動通常包含自上而下和自下而上兩個過程,是高效、準確且存在諸多局限的。以管理決策為例,當需調用某些信息來支持管理者做出正確決策時,其可在極短時間內從海量先驗經驗中抽取相關知識并進行加工,當然,這個認知過程或信息加工過程同樣存在局限,即人的記憶力或信息處理能力是有限的,會依據先驗認知或情感舍棄掉某些重要性程度較低的信息或知識,而這恰好與數據中冗余特征的篩選有著異曲同工之妙。
因此,將人類對銀行客戶細分數據特征貢獻度的認知進行可視化,作為特征選擇過程中的一個補充具有十分重要的意義。鑒于問卷調查作為一種數據采集方式,具有省時、省力、省錢及便于定量處理與分析等優點,本文采用問卷調查的方式對銀行客戶數據特征貢獻度認知進行量化,問卷類型為“網絡調查問卷”與“紙質問卷”相結合,每個特征即一個問題,問題備選項類型為二值封閉式選項,形式為選擇式,問卷具體形式如圖3。

圖3 調查問卷Fig.3 Questionnaire
針對不同的數據集,問卷題目個數及問題均有所區別。記問卷數據集S i下共包含f1,f2,…,f p共p個特征和A1,A2,…,An共n個對象,其中對象A i對特征f j的認同度記為f ij(f ij∈[0 ,n] ),構造決策矩陣F=(f ij)n×p,然后對決策矩陣中各列進行標準化處理,變換方法如下:

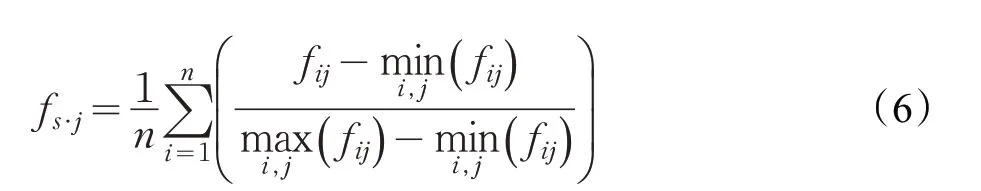
公式(5)、(6)中f s·j表示標準化處理之后的特征貢獻度,公式(5)能夠有效保持原有數值間的絕對差別,公式(6)將數據量綱處理后表示某個對象在整個特征向量中的相對排位和相對差別,但不能代表數據間的絕對差別。經標準化處理后,得到各特征的主觀貢獻度:
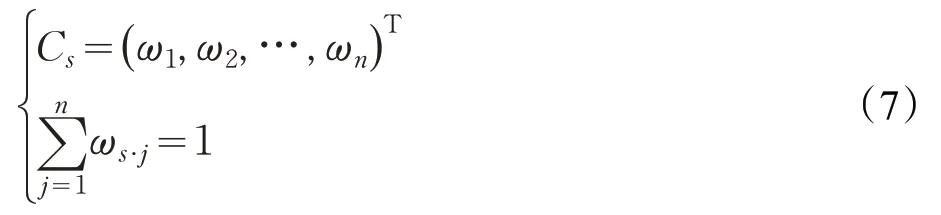
(4)基于多模態后期融合的特征選擇方法
多模態數據融合是指通過利用多模態之間的互補性,剔除模態間的冗余性,從而學習到更好的特征表示。目前,多模態數據融合主要有三種融合方式:前期融合、后期融合和中間融合。鑒于后期融合相較于前期融合與中間融合具有簡單、高效和易于理解等優勢,因此本文借鑒后期融合思想對上述三種特征選擇方法結果進行融合。
鑒于本文中客觀特征貢獻度計算與主觀量化特征認知計算之間相互獨立,因此,本文采用情感預測多模態后期融合中線性加權方式計算綜合特征貢獻度,該方式操作簡單且應用廣泛。主觀量化特征認知特征貢獻度向量為C s,客觀特征貢獻度為Pearson貢獻度向量X o和RF貢獻度向量C o,其綜合特征貢獻度如下:

式中,C w為綜合特征貢獻度向量,α和β分別為主觀量化特征認知貢獻度和客觀特征貢獻度系數,滿足α+β=1且α,β∈[ ]0,1。當α=β,表示主客觀同等重要;當α>β,表示主觀量化特征認知貢獻度重要性程度更高;當α<β,表明客觀特征貢獻度重要性程度更高。并將綜合特征貢獻度向量中每個元素C w·j與最小特征貢獻度θ進行比較,大于θ的特征構成篩選特征向量R=(r1,r2,…,r z)T,其中z為篩選后特征個數。
2.3 特征選擇效果評價
本文分別從定性與定量兩個角度對銀行客戶數據特征選擇效果進行評價。首先從定性角度對特征選擇方法進行評價,主要針對特征選擇方法的原理、特征選擇個數、選擇特征個數占原始數據總特征個數比重以及特征選擇重合度對各方法進行橫向對比評價。之后從定量評價角度對特征選擇方法進行評價,通過特征選擇后的數據集構建不同算法的銀行客戶分類模型,依據模型查準率(Precision)、召回率(Recall)、F1系數(F1-score)和模型訓練成本(Cost)定量評價指標對不同算法模型下特征選擇方法效果進行評價。定性與定量相結合的特征選擇效果評價方法能夠有效判斷所選特征集合是否能夠代表原始數據集特征,及是否能夠選擇出對目標貢獻度較小的特征,綜合評價不同特征選擇方法對銀行客戶分類所產生的影響。
3 特征選擇實證研究
基于經典數據挖掘框架、多屬性決策理論、主觀先驗認知理論及多模態融合理論,結合現有銀行客戶分類研究主要采用單一特征選擇方法現狀以及客戶有效分類對銀行規避金融風險及提升效益等方面的顯著作用,選取銀行客戶數據為研究對象,通過建立客戶分類模型,從定性與定量角度綜合評價特征選擇方法的性能,探索銀行客戶數據價值為銀行精準營銷與風險規避提供決策支持,同時為銀行客戶提供個性化進行產品與服務。
3.1 研究準備
(1)數據來源
數據來源于網易數據分析項目,該項目承擔單位為上海數局科技有限公司,該公司為國內合資企業,經營范圍涉及電子商務、計算機科技、計算機軟件開發、環保科技、生物科技等多個領域。項目涉及到的數據集以保護數據提供單位知識產權及個人的隱私為出發點,為相關數據使用工作者提供高保真數據集。本研究選擇銀行客戶信用卡相關數據,數據內容共存儲于客戶信用記錄表、申請客戶信息表、拖欠歷史記錄表和消費歷史記錄表,整合后銀行客戶信用卡真實數據共計5 954條數據,每條數據包含28個特征,原始數據內容如表3所示,整合后數據特征構成如圖4所示。
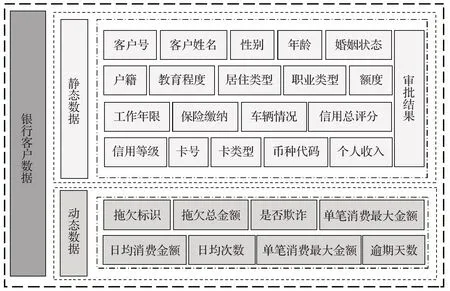
圖4 銀行客戶數據屬性構成Fig.4 Composition of bank customer data attributes

表3 原始數據內容及特征簡介Table 3 Contents and characteristics of raw data
(2)實驗條件
本實驗模型訓練單機硬件配置為Inter?Core?i3-3220 CPU@3.30 GHz 3.30 GHz核心處理器,4.00 GB RAM,500 GB常規硬盤,Inter?HD Graphics單顯卡,軟件平臺為PyCharm集成開發環境,Windows 10企業版2016企業長期服務版,anaconda6 64 bit包管理工具。
3.2 研究方法
基于高維銀行客戶數據的特征選擇方法實證流程,如圖5所示。首先,將分散在不同業務系統中的銀行客戶數據進行整合并以信用等級為目標變量篩選出審核通過客戶數據,并依據與銀行客戶分類相關的現有研究對于客戶分類目標無明顯貢獻的特征,如:客戶號、客戶姓名、審批結果、卡號等,進行初步篩選形成較低緯度數據集。其次,由于機械因素或人為因素導致整合后數據集中存在較多缺失值、分類模型無法處理的非數值型數據和連續型數值數據,因此需要對初步特征篩選后的數據進行預處理,通過改進KNN方法對缺失值進行填充,Map映射對數值類型進行轉換、公式(1)對連續型數據進行等距離散化及特征數值標準化。再次,對預處理后高質量數據集分別通過量化特征認知、Pearson相關系數、RF特征貢獻度及多角度融合方法對特征進行選擇,并分別生成篩選數據集。最后,基于篩選數據集分別構建不同算法分類模型,并就特征篩選效果進行定性與定量評價。
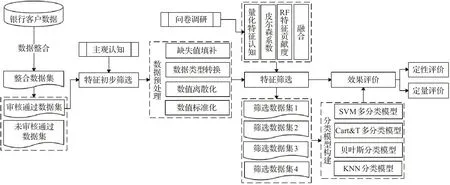
圖5 高維銀行客戶數據特征選擇方法研究流程Fig.5 Research process of customer data feature selection method in high dimension bank
3.3 特征選擇結果
(1)基于Pearson相關系數的特征選擇結果
通過公式(2)計算不同特征與目標變量之間的線性相關關系,依據相關系數絕對值是否非負對特征進行選擇,選擇特征包含:性別、年齡、教育程度、居住類型、工作年限、個人收入、保險繳納、車輛情況、信用總評分、額度、拖欠標識、拖欠總金額、逾期天數和單筆消費最小金額共計14個特征,如表4所示,對應特征及數據生成篩選數據集2。
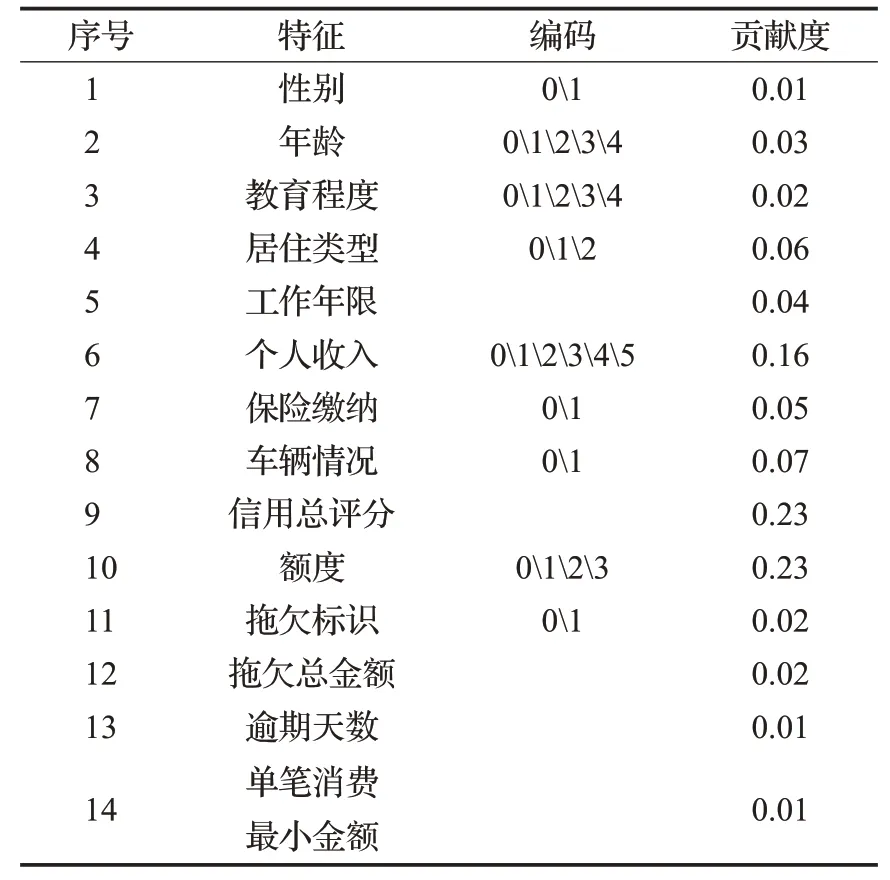
表4 Pearson系數特征選擇結果Table 4 Pearson coefficient feature selection results
(2)基于RF特征貢獻度的特征選擇結果
基于預處理后高質量數據集,借助Pycharm集成開發環境,通過python中numpy、pandas等數據處理第三方庫與sklearn機器學習庫調用RandomForestRegressor函數接口構建RF模型,計算特征貢獻度,并按特征貢獻度大小,對特征進行篩選,具體函數如下所示:
RandomForestRegressor(n_estimators,criterion,max_leaf_nodes,random_state,n_job)
其中,參數n_estimators設定為整數值101,表示RF中建樹的個數,同時為了防止“投票”過程中出現特征得票相同的情況,故設置為奇數;參數criterion表示RF內部決策樹在進行分叉時依據哪個特征進行分裂的衡量標準,本文設定為Gini系數;參數max_leaf_nodes設定為整型參數16,表示種樹的最大葉子節點數;參數random_state設置為整數1,表示隨機種子,通過隨機種子的設定能保證程序運行結果的可復現性;參數n_job表示模型訓練函數fit與模型預測函數predict并行運行的作業數,無特殊要求,默認設定為1。最終選擇的8個特征如表5中所示。
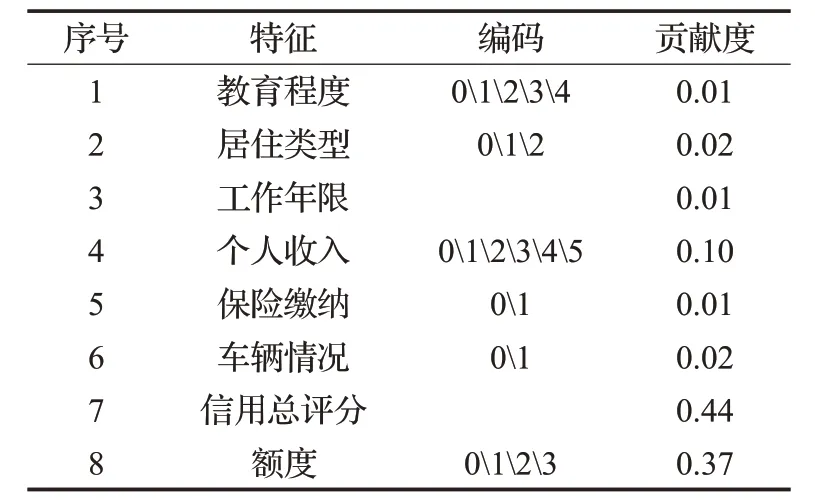
表5 RF特征選擇結果Table 5 RF feature selection results
(3)基于量化特征認知的特征選擇結果
基于量化特征認知的特征篩選方法通過問卷調查方式對無法定量測量的人類先驗認知進量化,問卷形式如圖3所示。問卷形式為“網絡調查問卷(問卷星)”和“紙質問卷”相結合,共28個問題,問題均為二值單選題,共發放問卷160份,有效問卷98份,網絡問卷52份,紙質問卷46份,其中超過50%問卷填寫人為在校研究生、博士生、講師或教授,問卷填寫質量較高。
(4)基于多角度融合的特征選擇結果
在多模態情感預測當中,綜合考慮多個模態以及其他信息理論上來說可提高情感識別系統的性能,非恰當的融合方式不僅無法提升模型性能,而且有極大可能降低模型的性能[27-29]。現有的模型融合方式主要有前期融合、中期融合和后期融合,其中后期融合以其簡單高效的特點被廣泛應用于多模態情感預測領域。鑒于本文不同視角下對特征貢獻度的計算是獨立進行的,符合后期融合前提假設,因此本文通過線性加權方式對不同視角下的特征貢獻度進行計算,計算過程如公式(8),其中α=0.28且β=0.72,最終篩選特征為:年齡、教育程度、居住類型、職業類別、工作年限、個人收入、保險繳納、車輛情況、信用總評分、額度、拖欠總金額共計11個特征,如表6所示。

表6 多角度融合特征選擇結果Table 6 Feature selection results of multi-angle fusion
3.4 特征選擇效果評價
(1)定性評價
四種特征篩選方法的類型并不相同,Pearson相關系數(方法1)為基于統計的特征選擇類型,RF(方法2)特征貢獻度為基于機器學習的特征選擇類型,量化特征認知(方法3)則為依據人類先驗知識的一種特征選擇類型,而本文提出的多視角融合的特征選擇方法(方法4)則為考慮不同方法間互補性的一種特征選擇類型。其中方法1是通過衡量待篩選特征與目標變量之間相似度大小的一種特征選擇方式,該方法受數據預處理效果影響較大,共篩選出14個特征;方法2則通過公式(4)計算各特征貢獻度,依據貢獻度大小對特征進行選擇,共篩選出8個特征,篩選效果較好,但模型針對性較低且訓練成本較高;方法3則依據人類先驗知識通過問卷調查方式對特征貢獻度進行度量并選擇特征,篩選效果對問卷填寫人的知識背景和問卷填寫質量要求較高,共篩選15個特征,特征篩選效果較差,本文分析該種現象產生的原因主要有兩點:第一,直接采用屬性名稱作為問卷問題可能導致某些問卷填寫人對問題無法把握,此時,人們更加傾向于認為該特征對目標屬性具有貢獻作用;第二,問卷填寫人本身缺乏該領域的相關認知,導致問卷填寫質量不高;本文提出的方法4從多角度出發,綜合多種特征選擇方法,優勢互補,共選擇11個特征,特征選擇效果較好,預處理階段對數據的缺失值填充考慮充分,訓練成本較低,且有效降低了數據特征冗余,提升了篩選準確性。四種特征選擇方法共選擇特征包括教育程度、居住類型、工作年限、個人收入、保險繳納、車輛情況、信用總評分、額度。綜上可知,上述8個特征對目標屬性的貢獻程度較大。四種不同特征選擇方法的比較結果如表7所示。

表7 特征選擇結果對比Table 7 Comparison of feature selection results
(2)定量評價
分別基于未特征選擇數據集與四種特征選擇方法降維后的數據集構建SVM(S)、Cart&T(C)、貝葉斯(B)和KNN(K)銀行客戶分類模型。首先基于先驗認知剔除較為明顯的對目標屬性無貢獻的特征,并通過PyCharm編程對集合后數據進行預處理,生成utf-8格式數據文件raw_data.csv,并依據不同特征選擇方法分別生成數據文件pearson.csv、rf.csv、people.csv和total.csv;其次,將數據集劃分為訓練集(70%)和測試集(30%),并在此基礎之上分別構建上述4種算法的銀行客戶分類模型,分別計算依據不同特征選擇方法所選擇數據集構建分類模型的訓練集精確度(ac)、測試集精確度(tc)、查全率(tl)、查準率(pd)、召回率(rl)、F1-score(f1)以及模型訓練成本(ct),最終計算結果如表8所示。
由表8中的實驗結果數據可知,未進行特征選擇的高維數據集的各項評價指標均低于依據特征選擇后數據構建的分類模型評價指標,表明特征選擇能有效提升模型性能;從SVM分類模型可見,基于方法4數據集構建的客戶分類模型各項指標均優于方法1和方法3模型性能指標,同時,在各項指標基本不變情況下,方法4的模型訓練成本要較方法2低0.14 s;從Cart&T、貝葉斯分類器和KNN分類模型結果可見,基于不同篩選后數據集構建的分類模型性能基本一致但基于本文特征選擇方法篩選后數據集構建的分類模型的訓練成本相對更低。綜合以上分析可知:首先,經過特征選擇后的數據各項指標更為精確,可提升分類模型性能;其次,從分類模型角度考量時,本文提出的多視角綜合方法所構建出的模型指標優于其他單一方法,且較其他方法而言訓練成本較低,實際操作中易于實現。
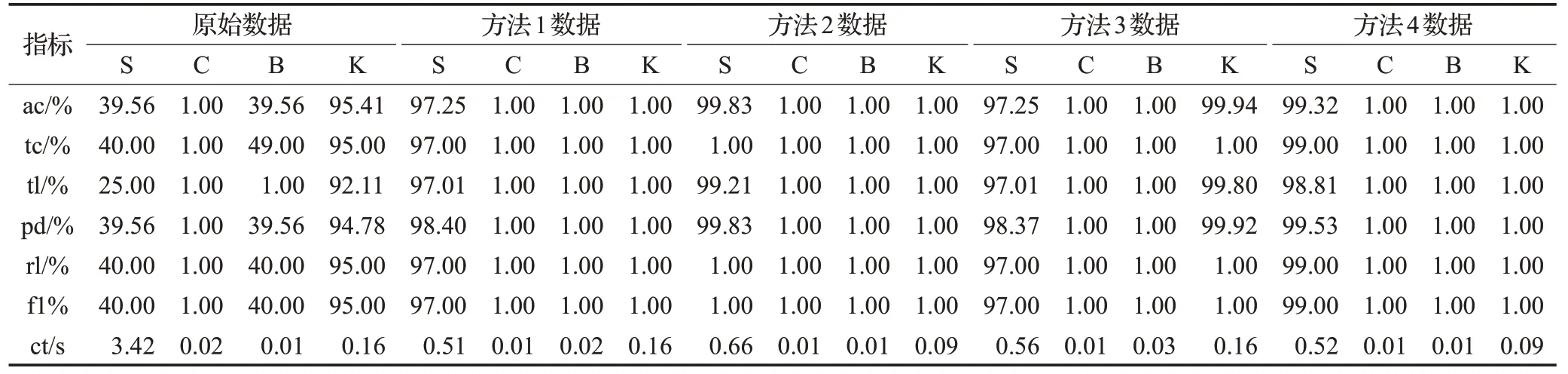
表8 特征選擇結果對比Table 8 Comparison of feature selection results
3.5 研究結論
本研究提出的銀行客戶細分數據特征選擇方法共包含三大部分:數據預處理、綜合特征選擇和特征選擇效果評價。數據預處理是以相關預處理技術為基礎,通過缺失值填補、異常值處理、數據類型轉換和連續型數據離散化等操作,提高數據質量。其次分別基于統計、機器學習、先驗認知和綜合視角對預處理后數據集特征進行選擇,其中,統計類型方法選擇:Pearson相關系數,通過衡量特征與目標屬性之間的相關性大小,對特征進行篩選;機器學習類型方法選擇:RF特征貢獻度,依據模型計算出的特征貢獻度大小從小到大對特征進行篩選;先驗認知類型方法選擇:通過問卷調查方法量化不可直接測量的人類先驗認知,通過最終問卷結果統計各特征對目標屬性的貢獻度,進而篩選特征;綜合視角類型方法選擇:考慮到不同方法之間存在的互補性,借鑒多模態情感預測后期融合思想,通過線性加權方式對上述方法計算結果進行線性加權計算。最后,基于不同篩選后數據集構建不同的客戶分類模型,從定性與定量兩個角度對特征選擇效果進行評價。實驗結果發現,未篩選特征的原始數據集構建模型性能較差,方法4特征篩選效果和模型個性評價指標較優。
4 結語
銀行客戶數據作為金融大數據的重要組成部分,包含了大量的有價值知識,對其進行有效挖掘可助力銀行提升風險管控能力和客戶滿意度,但銀行客戶數據量之大、特征之多和價值密度之低等問題,限制了人們對銀行客戶數據蘊藏知識的有效挖掘。同時,現有的針對高維數據集的特征選擇方法主要采用單一方式進行,并未考慮不同特征選擇方法之間的互補性,另外,對人類先驗認知的重視程度也遠遠不足。
本文提出的銀行客戶細分的數據特征選擇方法綜合考慮統計相關理論、機器學習相關理論、先驗認知相關理論和多模態融合相關理論,按數據預處理、綜合特征選擇和特征選擇效果評價策略對銀行客戶數據集特征進行選擇。研究結果表明,本文所提特征選擇方法能夠有效對高維銀行客戶數據特征進行篩選,且篩選后特征維度較低,所構成的數據集能夠有效表示原始數據集全貌,同時,基于本文所提特征選擇方法特征選擇后構成的數據集構建的分類模型性能,基本優于單一方法下構建的分類模型性能,不同類型下的特征選擇方法可以實現有效互補,篩選出的對應特征數據集能有效提升模型性能。
本文創新點主要有:(1)結合銀行客戶數據自身特點,給出了一種包括類型轉換及離散化,缺失值填充和標準化三部分的針對銀行客戶分類特征篩選的數據預處理方案,經過預處理后的數據質量得到顯著提升;(2)結合認知心理學相關理論,通過問卷方式量化先驗認知,并將其引入特征選擇;(3)借鑒多模態情感預測思想,考慮到不同特征選擇方法之間的互補性,綜合主觀特征選擇方法和客觀特征選擇方法,通過后期融合線性加權方式對不同類型特征選擇方法進行融合,實現方法互補;(4)提出的銀行客戶細分特征選擇方法較前人研究更加系統全面,實證研究模型從單一數據、單一模型和多指標評價優化為單一數據、多模型和多評價指標,更具多元性,能為銀行客戶數據知識挖掘與價值發現提供參考。不足之處在于:不同角度特征選擇方法所計算的特征貢獻度系數需要人為調整,且系數設置合理與否將對模型性能產生較大影響;同時,考慮到數據采集成本等因素,未采集不同銀行客戶數據,對特征選擇方法的適用性進行驗證。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
High Technology Letters(2017年3期)2017-09-25 12:53:30
中國老區建設(2016年3期)2017-01-15 13:53:21
創新作文(小學版)(2016年20期)2016-08-22 09:11:22
