基于GA-KELM的ZPW-2000A型軌道電路故障預測研究
2022-06-11 07:29:16李曉艷
大連交通大學學報 2022年2期
李曉艷
(陜西鐵路工程職業技術學院 鐵道動力學院,陜西 渭南 714000)
伴隨著設計時速350 km,正線全長174 km的京張高鐵“精品工程、智能高鐵”的建設,鐵路線路針對軌道電路所采用的“天窗修(TBM)”和“故障修”的維修維護模式[1-2]已不能滿足行車安全和運輸效率的提高.
當前已有不少文獻對軌道電路進行了深入研究:文獻[3]就軌道電路銹蝕、集污造成軌面電阻超高導致分路不良進行研究;文獻[4]就軌道電路檢測精度低、耗時長等方面進行算法改進;文獻[5]針對軌道電路中紅光帶故障的多樣性及復雜性問題進行故障診斷;文獻[6-10]中對道砟信號、多故障診斷方法等方面進行了研究.
隨著智能技術及PHM(Prognosticsand Health Management,故障預測與健康管理)理論的發展,基于狀態修(CBM)的故障預測方法成為當前的研究熱點[11-12].典型故障預測的方法主要有:統計法、數學法、智能法和傳統基于梯度的學習迭代策略,選擇正則化最小二乘法調整輸出矩陣,在網絡訓練速度及泛化速度方面都有很大的改善[14].本文選擇ELM及其優化算法對我國鐵路線路上廣泛采用的ZPW-2000A型軌道電路進行故障預測研究,最后通過兩個實例驗證了模型的可行性與有效性.
1 ZPW-2000A結構分析
圖1為ZPW-2000A型軌道電路的結構圖.室外由調諧區、機械絕緣節、匹配變壓器、補償電容、電纜和調諧區引線構成.室內主要有發送設備和接收設備組成.

圖1 ZPW-2000A型頻軌道電路原理圖
本文數據來自微機檢測室,具體參數指標如表1所示.
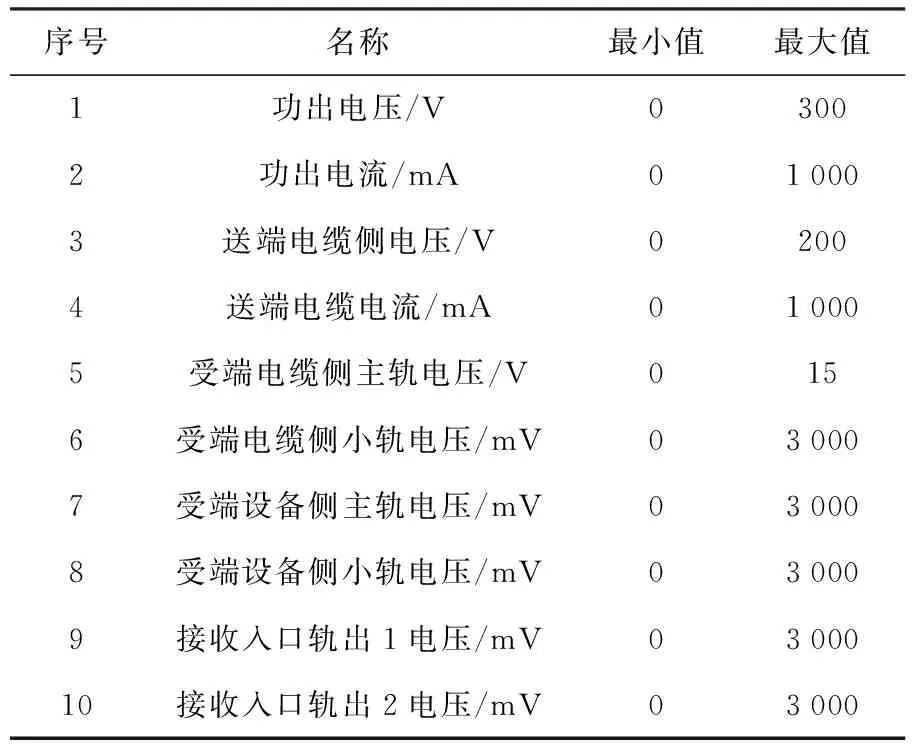
表1 軌道電路集中監測基本數據
2 ELM及其改進算法
ELM是一種單隱層前饋神經網絡,包括輸入、隱層和輸出3層.若有N組訓練樣本數據集(xj,tj),(xj,tj)∈Rn×Rm,隱含層節點數L,激勵函數v,則:
(1)
其中,j=1,…,N,βi為第i個隱層節點和輸出層節點間的權重向量.
ELM隨機選擇隱層節點的輸入權重w和偏置b,再計算出權重β的最小二乘解,保證訓練錯誤率最小.式(1)可被重新寫為:
Hβ=T
(2)
則有:
其中,H為隱層節點輸出,其特征映射為:
h(xj)=[v(w1xj+b1), …,v(wLxj+bL)]
其中,β為輸出權重矩陣,T為目標矩陣.
在訓練數據集中ELM訓練過程包含3步,即:
Step1:隨機產生輸入權重wi與偏置bi,1≤i≤L; Step2:求取隱層的輸出矩陣H;
Step3:計算輸出權重矩陣β=H+T.
其中,H+為隱層輸出矩陣H的Moore-Penrose廣義逆.當HHT為非奇異時,H+=HT(HHT)-1.為消除“病態矩陣”造成的誤差引入正則化系數η,網絡的輸出權重最小二乘解可表述為:
β=HT(HHT+ηI)-1T
(3)
則ELM相應輸出矩陣為:
y(x)=h(x)β
(4)
將核函數引入到ELM中,形成新的核函數KELM.
KELM重新定義核函數QELM=HHT,其元素為:
QELM(i,j)=h(xi)h(xj)=K(xi,xj)
(5)
網絡輸出表示為:
(6)
核函數K(xi,xj)的類型確定為徑向基核函數,即:
(7)
其中,γ為徑向基核函數的核參數.
2.1 O-KELM方法及其算法
核極限學習機的優化過程主要在于確定正則化系數η與徑向基核參數γ.在O-KELM過程中適應度評價函數越小,網絡性能越好,則均方誤差值ERMSE(y*,y)可表述為:
(8)
其中,y*(i)為方法的預測輸出,y(i)為實際輸出.
待優化的決策變量由γ與η共同組成,形成種群個體,即ah=[γ,η],h=1,2,…,m,其中m表示種群個體數目.變量歸一化過程可表述為:
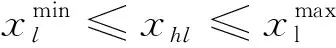
(9)
Step2:為方便計算個體評價函數,將個體的決策量轉化到真實范圍.
2.2 GA-KELM算法
選擇遺傳(GA)、微分(DE)與模擬退火(SA)3種算法對ELM的核參數γ、正則化系數η進行優化.再分別與典型算法:SVM、ELM、KELM在應用對象預測中進行等條件比對.
GA主要累積的信息在可行域中進行,具體GA-KELM的實現如下.
Step1:初始化種群A:
A=[a1,…,am]
(10)
Ah=[ah1,…,ahl]T
(11)
其中,0≤ahl≤1,h=1,2,…,m,m代表種群容量,l為待優化決策的數目.
Step2:根據式(8)計算個體的適應度.
Step3:由算法結合個體適應度值選擇雙親,再以概率pc進行均勻交叉操作產生新一代種群.
Step4:以概率pm進行均勻變異操作.
3 預測結果驗證方式
O-KELM模型中的時間序列表述如式(12),式中D為預測步長,Δ為嵌入維數;xt包括歷史數據(yt-1,yt-2,…,yt-Δ)因素.
y(t+D)=f(xt),?t=Δ,…,l
(12)
選擇平均絕對誤差(MAE)、平均絕對百分比誤差(MAPE)、均方誤差(NMSE)和相對誤差百分比(REP)作為預測結果的評價指標,具體如式(13)~式(16)所示.
(13)
(14)
(15)
(16)
其中:y(i)為時間序列對應的實際輸出;y*(i)為相應模型預測輸出;N為預測樣本點數;δ2為待預測時間序列方差.
4 模型高效性驗證
選擇某區段2016年1月-2018年1月ZPW-2000A數據臺賬中軌出1和軌出2的電壓值進行改進算法樣本值的訓練.通過預測2018年2月(28天)的輸出結果,對各算法的預測性能進行評判,具體數據如下:區段名稱:1 128 G;載頻2 300 Hz;發送電源24.7 V;接收電源25.8 V;功出電壓154 V;主軌入電壓997 mV;小軌入電壓115 mV;軌出1電壓656 mV;軌出2電壓147 mV.
在算法優化中,ELM模型的隱層節點設置為L=200,選擇Sigimoid激活函數,設定核參數初始值γ∈(0.1,300],正則化系數η∈[0,100].KELM核參數γ為6,η=0.01.GA-KELM初始種群選擇為150,最大進化代數為300.GA的交叉概率Pc=0.4,變異概率Pm=0.1.訓練后的不同算法性能如表2.
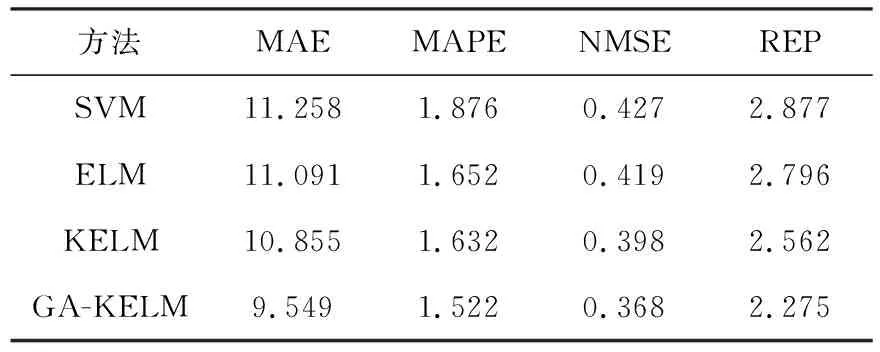
表2 不同方法性能比較
通過給出的SVM、ELM、KELM和GA-KELM算法在2018年2月份的軌出1的數據預測圖(圖2),得出GA-KELM預測效果最優.

圖2 不同預測算法結果對比
5 實例分析
5.1 斷軌故障預測
理論上ZPW-200A主軌道的軌出1電壓應不小于落下門限(大于等于170 mV);小軌道軌出2電壓不低于10 mV,實驗數據見表3.針對某局2018年10月某段發生的ZPW-2000A斷軌故障,采用GA-KELM算法對其電壓趨勢進行預測驗證.
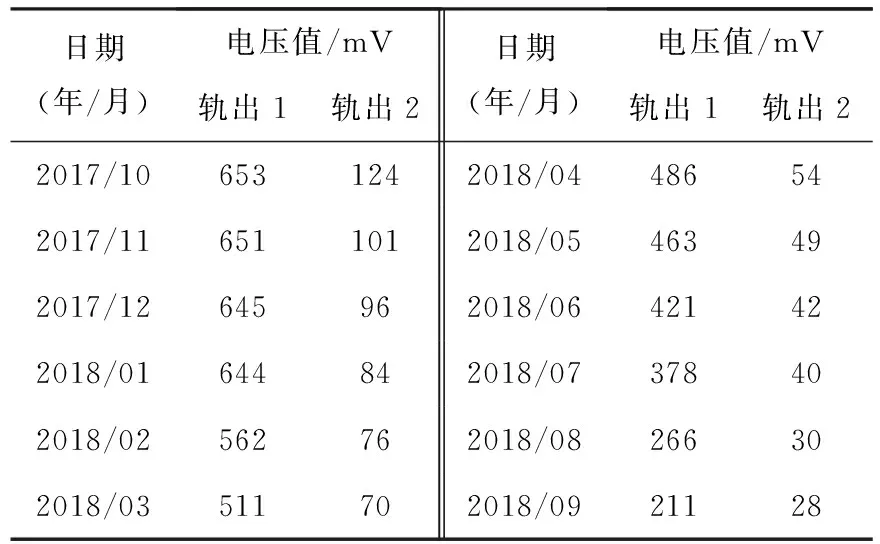
表3 實驗驗證數據
圖3說明在2018年10月份軌出1和軌出2電壓值均低于門限值,驗證該優化模型具有一定有效性,便于現場工作人員及時維護保養.
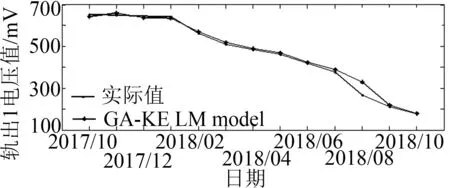
(a)軌出1
5.2 紅光帶故障預測
本例選自2016年2月15日10∶13∶11-10∶13∶42,京九下行線21793G在空閑狀態時出現紅光帶.21793G屬京九線復線自動閉塞區段的一個中繼站,該站區間全部采用ZPW-2000A無絕緣軌道電路.如圖1中電氣絕緣節由調諧單元、匹配變壓器、空芯線圈和29 m鋼軌組成,實現鄰軌道電路間的電氣隔離.21793G軌道電路區段全長1 335 m,載頻為1 700 Hz.圖4列出了某站21793G設備布置圖.
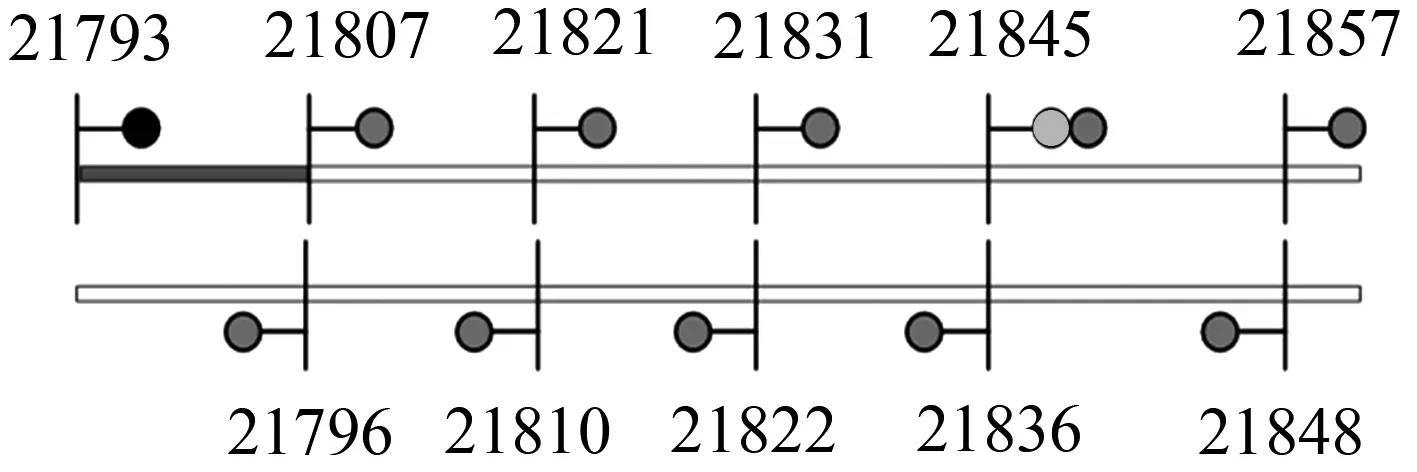
圖4 某站21793G設備布置圖
通過調閱數據發現:故障處理人員通過CTC設備回放確認21793G在10∶13∶11-10∶13∶42出紅光帶31 s,微機監測數據顯示:
(1)10∶13∶11主軌電壓由540 mv突變為0 mv(正常為540 mV),一直持續31 s;
(2)21793G運行前方相鄰區段軌道電路電壓為0 mV;
(3) 21793G區段移頻電纜側電壓突然為134.6 V(正常為61.6 V);
(4) 21793G移頻電纜側接收電壓0 mV;
(5) 21793G區段的發送端匹配變壓器電纜側短路146.5 V、電纜側開路134.7 V、鋼軌側開路32.7 V.
如圖5為系統CSM實時輸出的監測曲線,本文引入GA-KELM模型與CSM數據結合,通過監測當前時刻主軌道和小軌道兩個最敏感特征量參數變化來對設備運行狀態進行分析.
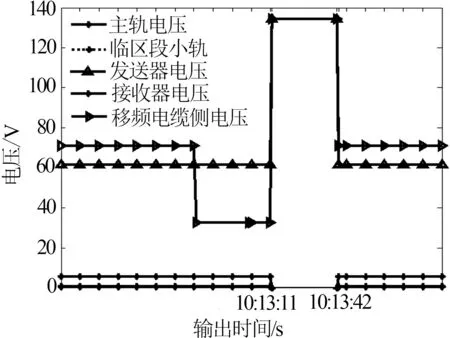
圖5 CSM系統輸出
如圖6,GA-KELM算法的輸出結果顯示在10∶13左右,主軌出現軌點,主軌軌出電壓迅速降為0,預測模型與實際運行情況一致.
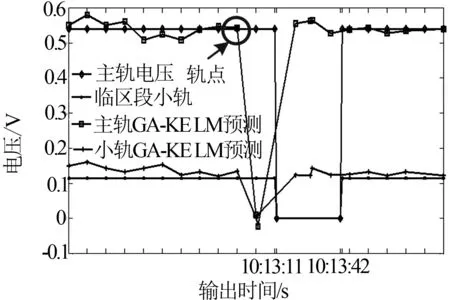
圖6 實際輸出與優化算法輸出比對
通過指導現場人工檢修,最終發現是由于送電端匹配變壓器鋼軌側開路所致.經測試發現:匹配變壓器內部電解電容C1、C2性能不達標,導致匹配變壓器鋼軌側開路所致.更換發送端匹配變壓器后,793G設備電壓恢復正常,通過預測算法快速找到故障點位置并驗證了模型的有效性.
6 結論
(1)本文主要針對傳統鐵路線路中軌道電路維修維護中存在維修不足和維修過剩的問題,建立了一種基于GA-KELM算法的ZPW-2000A型軌道電路的故障預測模型;
(2)通過實例將改進模型性能與傳統的SVM、ELM、KELM算法作比對,驗證了改進的GA-KELM性能最優;
(3)選擇GA-KELM算法對兩個實例進行預測分析,驗證了模型的高效性.
本文方法對鐵路信號設備從定時修、故障修和轉向狀態修的發展過程具有積極意義.
致謝:本文受陜西鐵路工程職業技術學院科技計劃基金項目(2014-17)資助,特此致謝!
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
