基于改進Otsu算法的井下行人目標快速定位方法
2022-06-11 03:54:38余善好
黑龍江工業學院學報(綜合版) 2022年4期
余善好
(安徽三聯學院,安徽 合肥 230601)
中國是個以重工業發展為主的大國,為加大生產量,保證國家GDP,將工業推向自動化是必要手段,在大力發展工業的同時,井下作業往往具有事故風險,無法保障人員安全,為此井下人員和設備定位技術在保障煤礦安全生產方面起著至關重要的作用。煤礦行業越來越重視礦井人員的定位技術[1]。為了確保圖像的清晰度,井下行人目標的準確定位尤為重要。定位精度直接關系到煤礦的生產效果[2],且煤礦發展在要求精度的同時也需要加快生產效率,因此如何快速且準確的將井下行人目標進行定位是目前需要研究的問題[3]。
李清泉[4]提出單目視覺的室內多行人目標連續定位方法,構建像素坐標系到世界坐標系的坐標轉換模型,并結合卡爾曼濾波和匈牙利算法實現對多行人目標的連續定位與跟蹤,實現井下行人目標快速定位。韓江洪[5]等人提出基于深度學習的井下巷道行人視覺定位算法,基于深度學習網絡的系統整體結構;其次,搭建目標檢測多層卷積神經網絡(CNN),生成自主駕駛機車前方視野范圍內行人的二維坐標及邊界框的尺寸;再次,通過多項式擬合計算出圖像中行人到機車之間的第三維距離;最后,通過真實樣本集實施模型訓練,實現井下行人目標快速定位。田強[6]等人直接將非線性定位問題轉換成井下行人目標位置的加權最小二乘估計問題,并將最小二乘估計分成兩步進行求解,首先基于最小二乘準則將元件未發射的信號轉化為目標位置函數,同時將代價函數中未發射信號進行消除,其次在凸松弛技術的基礎上直接利用半正定規劃問題代替代價函數,最終計算出目標圖像的位置,實現井下行人目標快速定位。以上三種算法在進行井下行人目標定位過程中沒有對井下行人目標進行粗定位,同樣未對目標圖像進行邊緣分割處理,導致圖像邊緣不清晰,誤差過大,存在圖像匹配能力差、邊緣分割性能差以及定位偏差大的問題。
為了解決上述方法中存在的問題,提出基于改進Otsu算法的井下行人目標快速定位算法。
1 井下行人目標的粗定位以及邊緣檢測
在利用激光儀器獲取圖像時,為保證圖像清晰需將井下行人目標進行準確定位,因此需要提前對目標進行粗定位以及邊緣分割[7-8]。
1.1 井下行人目標的粗定位
對于圖像來說,都需要利用最有效的方法大致定位出該區域位置,并將其視為目標區域,粗定位的意義就是獲取該目標區域,現今粗定位的最優辦法就是模板匹配算法,該算法的原理就是將兩組在不同環境下的圖像進行比較,留下兩組圖像中最相似的部分。
模型匹配的效率高低最主要的影響因素就是兩組圖像的平移個數,因此為提高運算效率,可利用隔點取樣方法將準備進行對比的圖像尺寸減小,其原理如圖1所示。
圖1 隔點取樣
隔點取樣雖可提高運算效率,但同時因為圖像梯度值的增大導致圖像重要信息丟失,因此需要通過平滑濾波處理獲取更多尺度圖像,選取高斯濾波方法保證處理后的圖像不會出現局部極值點,高斯函數表達式如式(1)所示。
G(xi,yj)=(1/2πσ2)e
(1)
式(1)中,G(xi,yj)代表卷積模板內(xi,yj)相對應的權重值大小,σ代表高斯濾波器的方差。
通過隔點采樣處理后的圖像可將其中的鋸齒現象完全消除,將圖像進行高斯平滑以及采樣處理后即可利用NCC算法進行圖像匹配[9-10]。
NCC算法是通過兩圖像之間的相關性得出圖像相似度從而進行匹配的一種方法,令該算法中相關性為R(i,j),其波動范圍為[0,1],則相關性R(i,j)的計算方程式如式(2)所示。
(2)
式(2)中,E(T)代表模板圖像的均值,T代表模板圖像,Si,j代表準備匹配的圖像,E(Si,j)代表Si,j的平均數值,s代表原始圖像的灰度分割閾值,t代表相鄰圖像的灰度分割閾值。
利用式(2)計算出兩圖像中相似度最大的匹配點進而完成匹配,即提取出在范圍[0,1]中相關性最大的點完成匹配。
1.2 基于改進Otsu算法的圖像邊緣分割
圖像的邊緣分割也叫邊緣檢測,這是一種處理圖像清晰度的手段,其目的是將圖像邊緣清晰化,提取圖像邊緣點,為保證處理圖像過程中無其他噪聲進入圖像,選用Otsu算法進行圖像分割,它是通過原始圖像以及相鄰圖像生成二維直方圖[11]。
假設原始圖像為f(x,y),相鄰平滑圖像為g(x,y),令原始圖像的大小為M×N,原始圖像以及相鄰圖像的灰度值大小均為L,進而生成二維直方圖,則二維連接概率密度表達式如式(3)所示。
(3)
式(3)中,fij代表原始圖像f(x,y)內像素點灰度值i和相鄰圖像像素點平均灰度j可匹配到相同位置的像素點數量,L代表兩圖像的灰度值,其中i≥0,j≤L-1。
相鄰平滑圖像g的灰度等級的計算公式如式(4)所示。
(4)
式(4)中,g(m,n)代表灰度等級,k代表相鄰圖像像素點中為正方形區域的寬度值。
若利用閾值s和t對圖像進行分割,劃分成背景和目標圖像兩部分,則在整幅圖像中目標圖像和背景各占圖像大小的表達式如式(5)所示。
(5)
式(5)中,ωb代表背景所占整幅圖像比例,ωo代表目標圖像所占整幅圖像比例,且ωo+ωb=1。
因此得出背景與目標圖像相對應的均值矢量表達式如式(6)所示。
(6)
式(6)中,μ0代表背景相對應的均值矢量,μb代表目標圖像相對應的均值矢量,Pij代表二維連接概率密度值。則整幅圖像的均值公式如式(7)所示。
(7)
此時可根據離散度矩陣對圖像進行處理,在背景與目標圖像的均值和所占圖像比例得出離散度矩陣的公式如式(8)所示。
σB={ωo[(μo-μ)(μo-μ)]+
ωb[(μb-μ)(μb-μ)]}
(8)
式(8)中,σB代表圖像的離散度。
利用σB的跡計算目標圖像以及背景與目標之間距離,其表達式如式(9)所示。
tr(σB)=[ωb[(μb2-μ1)2+(μb1-μ1)2]+
ωo[(μo2-μ2)2+(μo1-μ2)2]]
(9)
式(9)中,tr(σB)代表圖像與目標之間的距離。
為保證井下行人目標的精確定位,需保證閾值(s,t)為最優,則需要取tr(σB)的最大值即可,并通過最優閾值將圖像進行分割,保證最終獲取高精度的邊緣圖像。
2 井下行人目標的快速定位
進行邊緣分割后所獲取的圖像就是二值圖像,為進一步縮小目標圖像,可對目標圖像進行識別,通過連通區域標記法將同一區域的像素點進行連接[12],連接后求解出該區域的相應參數,最終根據目標圖像屬性提取目標圖像。將識別出的目標圖像進行精確定位,首先將圖像的大致輪廓進行擬合,最后提取出其圓心坐標即可實現井下行人目標的定位[13]。
目前最優的圖像擬合方法就是最小二乘法圓擬合,假設目標圖像為(xi,yi),擬合的圓心為(xc,yc),由于最小二乘法圓擬合的原理就是計算出擬合圓心到圖像點之間距離平方差[14],并使得距離平方差f為最小,其表達式如式(10)所示。
(10)
式(10)中,N代表目標圖像中點的個數,r代表擬合圓的半徑。
對半徑進行偏導數計算[15],得出其表達式如式(11)所示。
r2=(y-y0)2+(x-xc)2
=y2-2ycy+yc2+x2-2xcx+xc2
(11)
假設擬合圓中參數a、b和c的表達式如式(12)所示。
(12)
進而得出擬合圓的曲線方程式[16]如式(13)所示。
x2+y2+ax+by+c=0
(13)
則目標圖像中點(xi,yi)到圓心的平方表達式如式(14)所示。
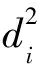
(14)
式(14)中,di代表點(xi,yi)和擬合圓心的距離。
=xi2+yi2+axi+byi+c
(15)
令Q(a,b,c)是δi的平方和,其表達式如式(16)所示。
(16)
根據上述求解出的偏導數得出其極值條件如式(17)所示。
(17)
式(17)中,C、D、E、G和H代表偏導數的極限點,?代表坐標以及半徑的約束條件。根據極值條件得出圓的坐標以及半徑,其表達式如式(18)所示。
(18)
式(18)就是需要定位的井下行人目標的坐標以及半徑。
3 實驗與結果
為了驗證基于改進Otsu算法的井下行人目標快速定位算法的整體有效性,分別采用本文所提算法、李清泉[4]提出的單目視覺的室內多行人目標連續定位方法(以下統稱為算法一)和韓江洪等人[5]提出的基于深度學習的井下巷道行人視覺定位算法(以下統稱為算法二)進行圖像匹配能力、邊緣分割性能以及定位偏差的測試,測試結果如下。
3.1 井下行人目標定位
隨機選取3幅需要匹配的圖像與模板進行匹配,其中模板圖像的像素是120*120,準備進行匹配的像素分別為380*302,360*260,280*210,利用三種算法對圖像進行定位,其實驗結果如圖2所示。

圖2 三種算法的定位對比
所提算法在三種不同像素下均精準定位圖像中的井下行人目標,且基本沒有誤差。算法一只能定位出像素較高的兩張圖,且誤差較大,算法二的定位能力極差,三張實驗圖沒有定位出任何一張圖中的井下行人目標。本文所提方法定位能力強的原因是在進行定位過程中先對于井下行人目標進行粗定位,利用隔點取樣方法將待匹配圖像尺寸減小,進而提高運算效率,減少圖像點的平移個數,降低運算誤差,從而提高了定位準確性。
3.2 邊緣分割性能
邊緣分割性能包含邊緣分割精度以及邊緣檢測所需時間。首先對三種算法的邊緣分割精度進行測試,隨機選取一幅圖,為保證算法準確性對三種算法均測試兩遍后觀察其結果,如圖3所示。
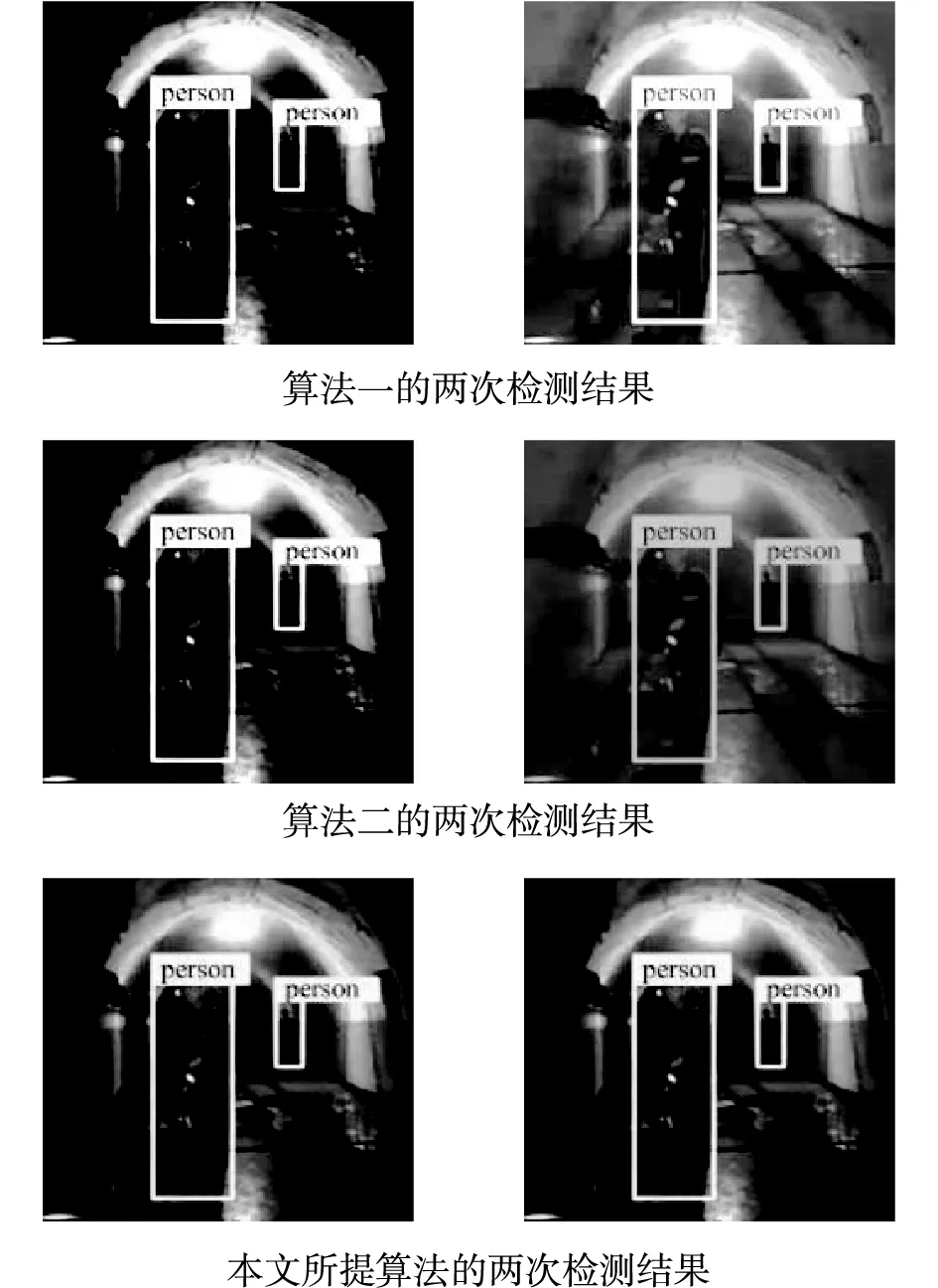
圖3 三種方法邊緣分割結果
由圖3可知,算法二對邊緣進行分割后目標圖像邊緣十分不清晰,同時伴有虛化現象,算法一雖強于算法二,但該算法的邊緣分割結果仍不理想,且第二遍分割結果過于失真,這種現象極可能導致最終結果出現較大偏差,而本文所提算法分割后的目標圖像邊緣十分清晰,因為本文所提算法提前對圖像進行高斯平滑處理,降低圖像中噪聲的影響,保證圖像的質量,進而提高邊緣分割精度。
邊緣分割時間也是驗證邊緣分割性能的重要指標,隨機選取6組樣本圖像進行,在保證其分割精度的情況下,對比三種算法所需時間,其結果如圖4所示。
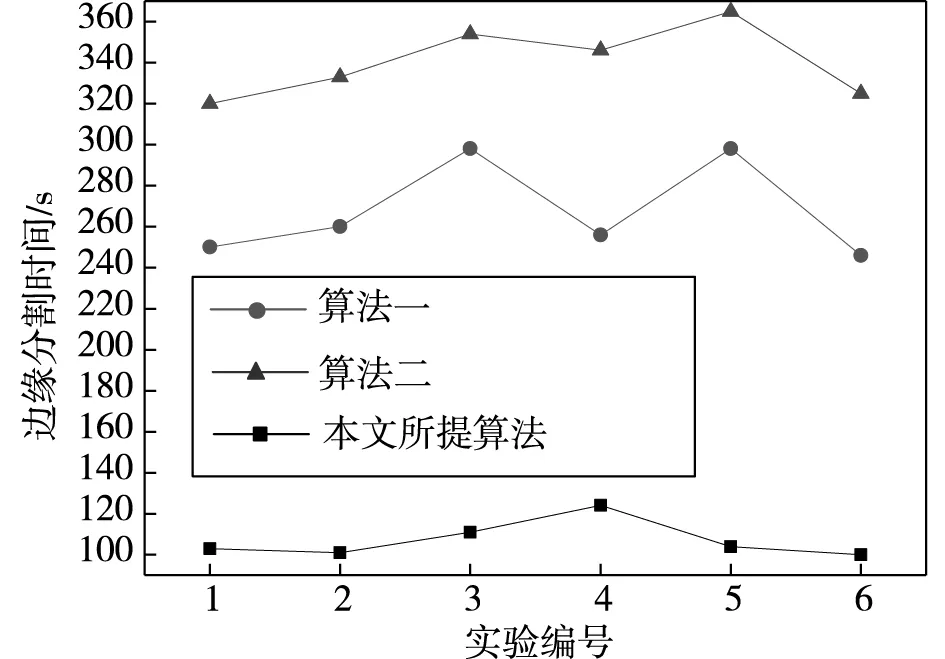
圖4 三種算法邊緣分割時間
由圖4可知,經比較后發現,在相同精度下所提算法是三種算法中用時最短,效率最高的算法,算法一雖強于算法二,但其用時也遠遠高于所提算法。綜上所述,證明本文所提算法的邊緣分割性能是三種算法中最優的。
3.3 定位偏差
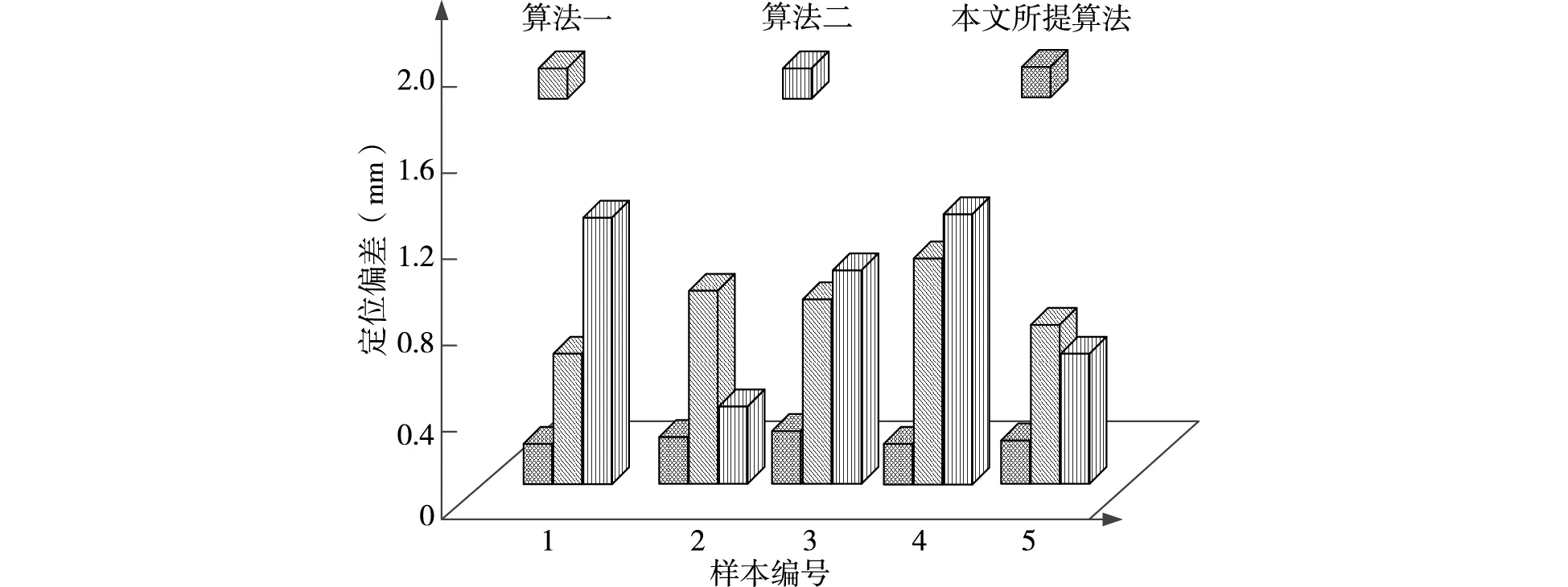
圖5 三種算法的定位偏差
比較井下行人目標定位優劣最直觀的指標就是對比算法偏差的大小,隨機選取五組完全不相同的樣本圖像,通過三種算法對井下行人目標進行定位,并與目標實際位置對比,得出三種算法的定位偏差,根據圖5可知,所提算法的定位誤差最高僅為0.4mm,算法一和算法二的最高定位誤差分別為1.25mm和1.4mm,這兩種算法的定位誤差遠遠高于本文所提算法,其中最低誤差也高于所提算法的最高誤差,本文所提算法的偏差之所以可以控制這么小是因為該算法對目標圖像邊緣進行分割,保證目前圖像的完整,進而提高定位準確性,從而降低定位偏差。
結語
井下行人目標的定位對于煤礦行業尤其重要,且必須保證定位的準確程度,因此提出基于改進Otsu算法的井下行人目標快速定位算法,該算法首先對井下行人目標進行粗定位,在此基礎上利用Otsu算法將目標圖像進行邊緣分割,其次對目標進行識別以及精準定位,實現井下行人目標快速定位,解決圖像匹配能力差、邊緣分割性能差以及定位偏差大的問題,保證工業效率的同時加強工作人員的安全。
