基于圖小波網絡模型的文本分類研究
2022-06-15 09:06:12馬誠賈凱莉李云紅高子明候嘉樂
電子設計工程 2022年11期
馬誠,賈凱莉,李云紅,高子明,候嘉樂
(西安工程大學電子信息學院,陜西西安 710048)
隨著互聯網技術的發展,文本信息呈指數增長。面對海量的文本信息,如何對各種文檔進行恰當的表達和分類,從中快速、準確地找到所需的信息,已成為眾多研究者關注的焦點。文本分類過程主要涉及文本表示、特征選擇、分類器設計3 個步驟。其中最重要的步驟為文本表示。詞袋(Bag of Words,BoW)模型[1]是最常用的文本表示方法,由于其將文本表示為One-hot 向量,忽略了語法和語序信息,因此丟失了大量的文本信息。為了解決文本表示中存在的問題,神經網絡模型被應用于文本表示,如卷積神經網絡(Convolutional Neural Networks,CNN)[2-5]、遞歸神經網絡(Recurrent Neural Networks,RNN)[6-9]、膠囊神經網絡(Capsule Neural Networks)[10]等。與傳統的文本表示方法相比,RNN 在獲取短文本的語義方面表現優越,但在學習長文檔的語義特征方面效果較差;CNN 進行文本表示時,與n-gram[11]有些類似,只能提取連續單詞的語義成分,可能會失去單詞之間的長距離語義依賴性[12]。
近年來,由于圖卷積網絡(GCN)[13-14]能更好地捕獲非連續詞和長距離詞的語義和語法信息,引起了眾多研究者的關注。Kipf 和Welling[15]提出GCN 模型,該模型通過譜圖卷積的局部化一階近似對圖卷積進行逼近與簡化,使得計算復雜度降低,并可以對局部圖結構和節點特征進行編碼,學習隱藏層表示,改善了文本分類性能。Chiang 等人[16]為了降低圖卷積網絡的時間復雜度與內存復雜度,提出了聚類GCN方法,該方法使用圖聚類算法對子圖進行采樣,并對采樣子圖中的節點進行圖卷積。由于鄰域搜索也被限制在采樣子圖范圍內,因此聚類GCN 能同時處理較大的圖和使用較深的體系結構,所用時間短、內存少。Xu 等人[17]為了降低計算復雜度并提高分類準確率,提出了GWNN(Graph Wavelet Neural Networks)方法,該方法用圖小波代替圖拉普拉斯的特征向量作為基集,并且利用小波變換和卷積定理定義卷積算子。Yao等人[18]提出TextGCN模型,該模型是將整個文本語料庫建模為文檔字圖,并應用GCN 進行分類。
文中在Text-GCN[18]模型研究基礎上建立基于圖小波網絡文本分類模型(Text-GWNN)。Text-GWNN模型使用改進的TF-IDF 算法計算詞與文檔間的權重,能突出特征詞對類別的重要程度;同時,該模型在節點域是稀疏及局部化的,具有較高的計算效率。此外,通過超參數s更加靈活地調整節點的鄰域,能更有效地根據鄰域節點獲取中心節點表示,從而改善文本分類效果。通過R8、R52 及Ohsumed 英文語料庫的驗證,提出方法提高了文本分類性能,具有較高的文本分類準確率。
1 Text-GWNN文本分類模型
圖1 為使用Text-GWNN 模型進行分類的原理框圖。對文本進行分類,首先需要對文本進行預處理,包括去除停止詞、分詞并清洗不需要的數據和去除標點符號;其次利用清洗后的文本通過詞共現及詞與文檔的關系構建文本圖;最后訓練分類模型,在測試集上對分類模型進行測試,并對分類結果進行評價。
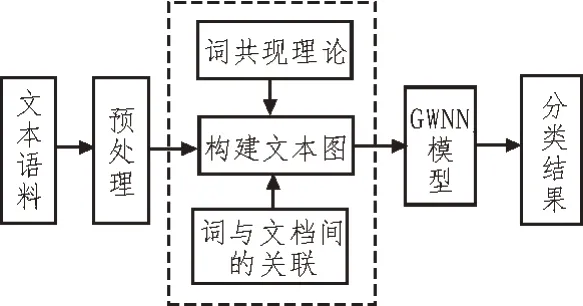
圖1 Text-GWNN模型分類框圖
1.1 構建文本圖
根據語料庫的特點,使用詞共現原理及詞與文檔的關聯構建無向文本圖。在語料庫中,節點的數目為文檔數加上文檔中不重復出現的詞的數目。根據詞與文檔的關系,如果詞在該文檔中,則使用改進TF-IDF 算法建立詞與文檔之間的權重關系;否則,詞與文檔之間的權重為0。改進TF-IDF 算法的計算方式如式(1)所示:
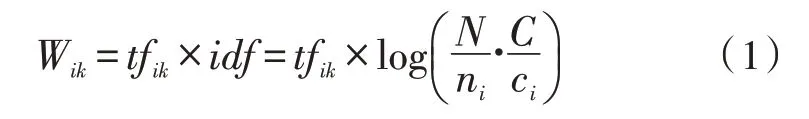
其中,tfik指的是詞i在文檔k中出現的次數,N為總文檔數,ni為出現詞i的文檔數,C為總類別數,ci為出現詞i的類別數。
根據詞共現理論,采用PMI 算法建立詞與詞之間的權重關系:

其中,Nij為詞i和詞j出現在同一滑動窗口的數目,Ni為語料中包含詞i的滑動窗口數目,N為語料中滑動窗口的總數目。
1.2 圖小波文本分類模型
假設無向圖G=(V,E),其中V代表所有節點的集合,E代表邊的集合。通常用拉普拉斯矩陣L=D-A表示圖,其中A為鄰接矩陣,代表兩個節點之間的連接關系,D為度矩陣,代表每個節點與其他節點連接的個數。
文中采用GWNN 模型[17](兩層網絡)進行文本分類,該模型是基于圖數據操作的。正則化后的拉普拉斯矩陣為:
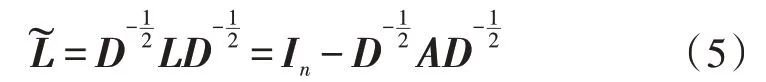

其中,?代表哈達瑪積,y為卷積核,可以用對角矩陣g(θ)代替UTy,哈達瑪積可以被視作矩陣乘法。上式可以被簡化為:

圖小波變換是將信號從頂點域變換為譜域進行操作,其是以一組小波基Ψs=(Ψs1,Ψs2,…,Ψsn) 為基礎,每個Ψsi都代表以節點i為中心,鄰域范圍為s的信號。因此,圖信號x的圖小波變換為圖小波逆變換為圖小波卷積被定義為:

其中,Gs=diag((g(sλ1),…g(sλn))),g(sλi)=eλis,U為拉普拉斯的特征向量。
圖小波神經網絡(GWNN)為一個多層的神經網絡,其傳播規則為:

其中,Ψs為小波基,為圖小波變換矩陣,是對角濾波矩陣,h為非線性函數。
2 仿真實驗
實驗采用R8、R52 及Ohsumed 英文語料庫進行文本分類任務,對提出的文本分類方法進行評估。
2.1 實驗數據
使用R8、R52 和Ohsumed 3 個標準數據集。其中,R8為8種類別的數據集,而R52為52種類 別的數據集,Ohsumed 為23 種心血管疾病病例的數據集。各數據集的統計信息見表1。

表1 數據集統計信息
2.2 實驗設置
實驗基于Python 語言實現,采用Tensorflow 框架對Text-GWNN 模型進行數據集測試驗證。
1)實驗參數設置
根據Text-GCN 及GWNN 模型進行參數設置,并通過反復多次實驗驗證,最終設置Text-GWNN 模型各參數的取值,具體見表2。

表2 實驗參數設置
2)評價指標
采用文本分類中常用的準確率(Accuracy)、召回率(Recall)、F1 值對文本分類結果進行評價,其中TP、FP、TN和FN分別代表正陽性、假陽性、正陰性和假陰性的分類數量。各評價指標的計算如式(11)所示:

2.3 實驗結果與分析
將文中模型與TF-IDF+LR、PV-DM+LR、LSTM、Bi-LSTM 和Text-GCN 文本分類模型對比,并在R8、R52 和Ohsumed 數據集進行實驗驗證。為驗證Text-GWNN 模型的有效性,通過分類準確率、召回率、F1值3 個評價指標進行實驗結果評估,結果如表3~表5所示。
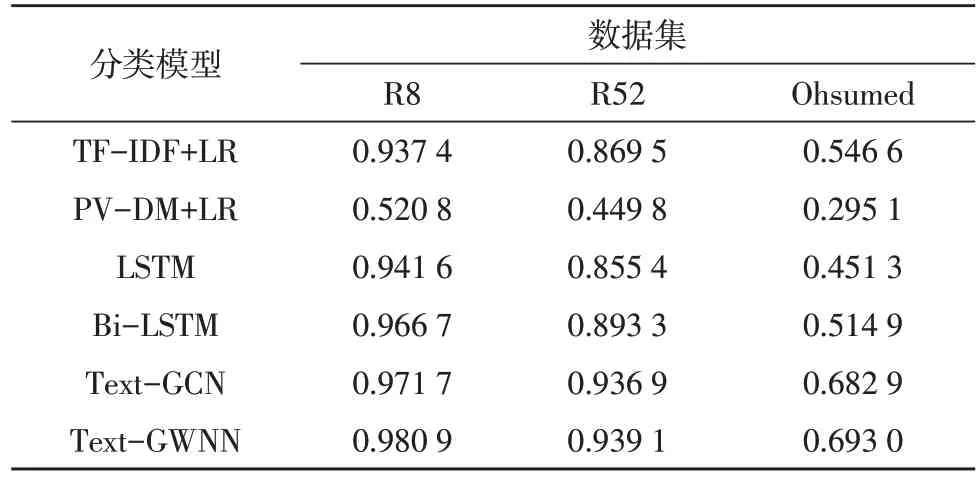
表3 分類準確率比較

表4 分類召回率比較
從表3~表5 列出各方法的實驗結果可以得出,Text-GWNN 與TF-IDF+LR、PV-DM+LR以及LSTM、Bi-LSTM文本分類方法相比,對于R8、R52及Ohsumed3個數據集,Text-GWNN 分類評價指標均高于對比的分類方法,該結果說明文中方法可以改善文本分類效果。

表5 分類F1值比較
Text-GWNN 模型與TextGCN 模型相比,R8、R52及Ohsumed 3 個數據集的分類評價指標有所提高,Text-GWNN 模型測試準確率分別達到了98.09%、93.91%、69.30%,分別提升了0.92%、0.22%、1.01%,結果證明Text-GWNN 分類模型可以有效提高文本分類結果。
圖2 給出了參數s對Text-GWNN 模型分類準確率的影響,參數s代表鄰域范圍,其取值范圍一般為s∈[0.5,1]。當s較小時,無法將與該節點有關的節點信息全部包含在其中;當s的取值太大時,又會將無關的信息包括進來,因此,要合理選擇s值。對于不同的數據集,參數s的取值往往不同。從圖中可以看出,對于R8、R52 和Ohsumed 3 個數據集,分別取s=0.9、0.7、0.5 時,Text-GWNN 模型分類準確率最高。
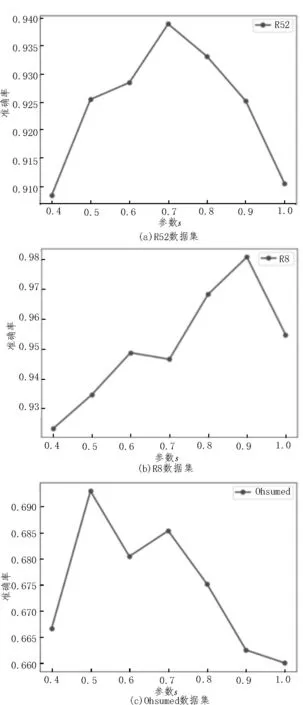
圖2 參數s 對分類準確率的影響
3 結論
文中提出基于圖小波網絡模型(Text-GWNN)的文本分類方法,該方法利用圖小波卷積的局部化特性,能更好地捕獲局部詞共現信息,改善文本分類效果。通過R8、R52 及Ohsumed 3 個英文語料庫測試,驗證了模型的有效性。未來工作中,將會研究加入池化層的圖小波網絡模型對文本分類性能的影響,并嘗試將其應用于中文文本分類;另一方面,還會研究Text-GWNN 網絡深度對于文本分類性能的影響,并在情感分類任務中應用該模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
