基于多尺度注意力引導的遮擋行人檢測方法*
2022-06-16 12:45:26謝東軍劉志剛劉苗苗
計算機與數字工程 2022年5期
謝東軍 劉志剛,2 黃 朝 田 楓 劉苗苗
(1.東北石油大學計算機與信息技術學院 大慶 163318)(2.東北石油大學應用技術研究院博士后工作站 大慶 163318)
1 引言
隨著深度學習應用研究的深入,行人檢測的性能有了較為明顯的改善,在很多實驗場景下開始嘗試應用到安防監控、輔助駕駛、應急救援等領域。但真實場景中,受遮擋、視角、光照等多種因素影響,行人檢測距離工業化的應用還存在很大距離。
與其他因素不同,遮擋會在行人的表征特征中引入噪聲干擾,是直接造成精度下降的重要原因,該問題近年來引起了國內外學者的廣泛關注。文獻[1]提出一種多標簽學習方法聯合訓練身體不同部分檢測器以捕獲多種遮擋模式。文獻[2]利用遮擋行人目標可見部分估計分支和全身估計分支進行聯合學習,產生的互補輸出可以進一步融合以提高檢測器性能。文獻[3]提出一種遮擋感知池化單元,將人體先驗信息與可見區域信息集成到檢測網絡。文獻[4]提出一種全新的排斥力回歸損失函數,使預測框盡可能接近真實目標框,遠離干擾目標框。文獻[5]提出利用通道注意力機制來處理不同的遮擋模式,這是注意力機制首次用于遮擋行人檢測領域中。文獻[6]提出逐級定位擬合策略,以單階段檢測器SSD[7](Single Shot Multibox Detector)為基礎,將默認錨框(anchor)逐步演化為精確的檢測結果。
但是,上述均為基于錨框(anchor-base)的行人檢測方法,在檢測過程中需要生成大量anchor,導致參數量過大,影響檢測速度。近年來,基于關鍵點的無錨框(anchor-free)檢測方法為行人檢測領域提供了新思路,文獻[8]提出的CornerNet以及文獻[9]提出的CenterNet 都是利用關鍵點回歸直接預測邊界框,解決了生成大量anchor所帶來的參數冗余問題,使模型更加輕量化。2019 年,Liu Wei[10]等提出一種基于anchor-free 的中心點和尺度預測(Center and Scale Prediction,CSP)行人檢測方法,直接通過生成行人目標中心位置和尺度對目標邊界框進行預測。CSP 對常規場景下的行人目標有著很好的檢測效果,但是它并沒有重點解決行人檢測中的遮擋問題。
綜上,本文以CSP 作為基礎網絡架構,提出一種專注于遮擋問題的注意力引導模塊,引導網絡模型關注遮擋行人目標的可見區域,削弱遮擋部分對網絡模型特征提取過程帶來的影響,增強行人特征的抽取與表征,提高對遮擋行人目標檢測的準確度。通過多次迭代,所提出模塊可以具備兩個優點:一是增強行人目標可見部分區域的特征判別力;二是學習全局特征,提升模型泛化能力。
2 相關理論
CSP 是anchor-free 在行人檢測領域的首次應用,并取得了良好的檢測效果。該方法的網絡結構主要分為兩個部分:特征提取部分和邊界框預測部分。
特征提取部分使用ResNet50[13]進行特征提取,卷積層分為五個階段,下采樣比例分別為2、4、8、16 和32。其中,為了保證深層特征圖的高分辨率,通用做法[14]是利用空洞卷積,保持第五階段的下采樣比例為16。此外,為了兼顧淺層特征圖的位置信息和深層特征圖的語義信息,需要對不同尺度特征圖進行融合。該方法經過實驗驗證,選取第3、4、5 層特征圖進行通道維度的特征拼接生成用于邊界框預測的多尺度特征圖,并且下采樣比例為4時,模型檢測性能最優。邊界框預測部分首先利用3×3 卷積核降低輸入特征圖的通道數至256,之后利用三個1×1 的卷積核分別生成目標中心位置特征熱圖、尺度預測圖以及中心位置偏移量預測圖,最終,利用中心位置和尺度,通過簡單幾何運算得到目標檢測框的大小。
CSP 的總損失表示為L,由中心預測損失、尺度預測損失和中心偏移回歸損失加權相加得到,損失函數如式(1)所示:
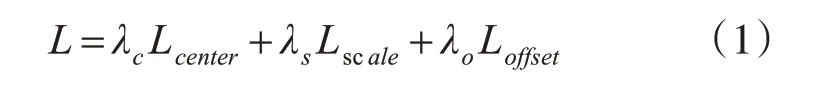
其中,λc、λs和λo為對應損失平衡權重因子,分別設置為0.01、1和0.1。
3 所提方法
3.1 模型設計
為了進一步處理行人檢測領域中的區域遮擋問題,設計一種針對遮擋問題的多尺度注意力引導模塊(Multi-scale Attention Guided Block,MAGB)。所提方法以CSP作為基礎架構,在經過特征提取過程后,引入多尺度注意力引導模塊進行注意力特征調制,增強特征圖目標可見區域特征表現力,為后續邊界框預測部分生成行人目標中心位置,高度以及中心位置偏移量提供更為準確的分類引導。關于多尺度注意力引導模塊,將在3.2 節中詳細闡述。所提方法總體網絡結構如圖1所示。
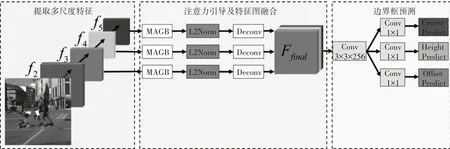
圖1 模型總體網絡結構圖
3.2 注意力引導模塊
注意力機制在特征提取階段可以引導網絡模型更好地關注特征中有用的信息,抑制無用的信息,讓網絡模型自動調節關注位置,提升特征提取能力。近年來,注意力機制對計算機視覺領域產生了重要影響,被廣泛應用于目標檢測[15]、圖像分類[16]、語義分割[17]等任務中。
受到注意力機制的啟發,為了提高網絡模型對遮擋行人目標的檢測效果,本文提出一種基于多尺度的注意力引導模塊。該模塊主要是對不同尺度特征圖的注意力特征進行空間域的調制,利用預處理的行人目標可見區域標注作為外部監督信息,使網絡模型將注意力主要聚焦于遮擋行人目標可見區域,充分提取有限的行人特征,抑制無用的遮擋部分特征,提高邊界框預測的精確性。多尺度注意力引導模塊整體結構如圖2所示。
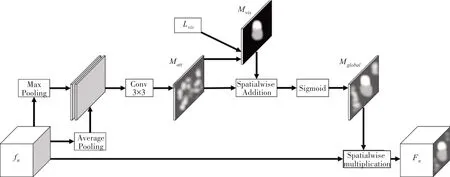
圖2 多尺度注意力引導模塊結構圖
多尺度注意力引導模塊的輸入是不同尺度的特征圖fn,在通道維度上對其分別進行最大池化(Max Pooling)與平均池化(Average Pooling),之后利用一個3×3 的卷積核進行特征平滑操作,并通過sigmoid 激活函數輸出得到空間自注意力圖Matt,其中Matt中每個像素強度與特征判別力成正比。然后,設置目標可見區域注意力增強分支,該分支利用行人目標邊界框標注作為外部監督信息,生成目標可見區域注意力增強圖Mvis,具體如下。
1)對數據集進行預處理,將行人目標邊界框可見區域像素值置為1,全身區域像素值置為γ,其中γ的值為0~0.5 間的隨機值,背景區域像素值置為0。對γ這樣設置的原因是為了在邊界框預測階段能夠得到更為準確的中心位置真值,即抑制遮擋區域特征影響的同時,也要對其進行像素值弱化保留;
2)引入可見區域像素值損失Lvis指導模型重點關注行人目標可見區域。Lvis為二分類交叉熵損失函數,表示預測像素值與標簽像素值之間的損失,可以通過式(2)得到:
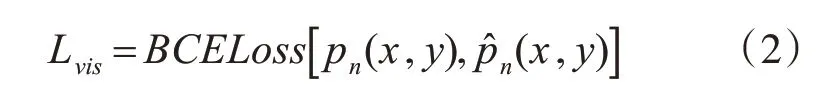
其中,pn(x,y)表示行人目標標注對應位置像素,表示目標可見區域注意力增強分支產生的對應位置預測像素。通過可見區域像素值損失Lvis,遮擋行人目標可見區域與全身區域的像素值將會分別趨近于1 和γ,引導網絡模型重點關注行人目標可見區域。
然而,在模型的每次迭代訓練過程中都應用目標可見區域注意力增強分支,將會造成網絡模型對外部監督信息的過度依賴,導致模型泛化能力變弱。為解決此問題,將該分支得到的目標可見區域注意力增強圖Mvis以空間相加的方式作用于自注意力圖Matt,所得到的全局注意力圖Mglobal不僅增強了行人目標可見區域特征,同時并未完全摒棄背景特征,這種處理方法會更好地抑制模型對外部監督信息的依賴,從而提升模型泛化能力。最終,將全局注意力圖Mglobal以空間點乘的方式作用于輸入的特征圖fn得到最終特征圖Fn。
引入多尺度注意力引導模塊后,網絡模型的總損失表示為Lfinal,將可見區域像素損失Lvis與式(1)提到的中心預測損失、尺度預測損失和中心偏移回歸損失進行聯合優化訓練,損失函數如式(3)所示:
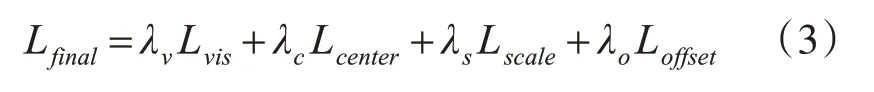
其中λv為可見區域像素損失平衡權重因子,為了突出多尺度注意力引導模塊在整體網絡模型訓練中的作用,本文將其設置為1。
4 實驗分析
4.1 實驗設置
實驗環境:所用服務器配置為Intel Xeon(R)E5-2640 CPU、8G 內 存 和NVIDIA RTX2070Super GPU。算法主要基于Pytorch深度學習框架實現。
數據集選擇:為了驗證本文所提方法的可行性,分 別 使 用Citypersons[11]行 人 檢 測 數 據 集 和Caltech[12]行人檢測數據集進行相關實驗。
評估標準:為了驗證網絡模型的性能,使用每張圖片的誤檢率(False Positives Per Image,FPPI)介于[10-2,100]之間的對數平均漏檢率(Log-average Miss Rate,MR-2)作為模型評估標準。MR-2的值越低,說明網絡模型的檢測性能越好。
參數設置:利用隨機水平翻轉,隨機裁剪等技術對數據進行增強擴充,提高數據集多樣性。利用Adam方法進行參數優化,使用平均權重移動策略[18]控制梯度下降過程,初始學習率設置為2×10-4,Batch Size設置為2,共訓練120個Epoch。
4.2 MAGB消融實驗分析
為了驗證MAGB 對遮擋行人目標檢測的有效性,消融實驗以CSP 作為測試基準(Baseline),將通用注意力模塊SENet[15],CBAM[16]分別添加至測試基準特征提取部分第3、4、5 層特征圖之后,與添加MAGB 的本文方法進行對比。消融實驗在Citypersons 數據集所提供的合理子集(Reasonable,R),重度遮擋子集(Heavy Occlusion,HO),部分遮擋子集(Partial)和輕微遮擋子集(Bare)上進行驗證評估。結果如表1所示。
由表1 可以清晰地看出,與測試基準對比,添加MAGB 后的檢測器在合理子集和三種不同遮擋子集上的MR-2均有顯著下降,特別是在重度遮擋子集(HO)上,MR-2下降了2.2%。此外,與通用注意力模塊SENet 和CBAM 相比,測試基準添加MAGB 后,在合理子集和三種不同遮擋子集上的檢測指標均表現出一定的優勢。
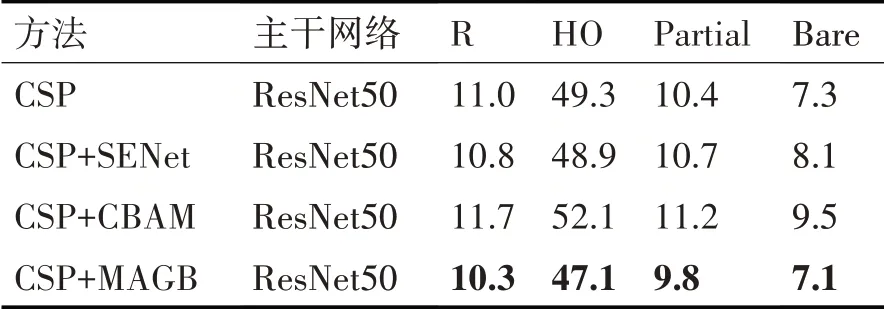
表1 在Citypersons數據集上的消融實驗結果MR-2/%
通過以上結果分析得出,在CSP 的基礎上,MAGB 在特征提取階段引入了外部數據標簽監督信息,通過像素級別的可見區域損失,指導模型對行人目標可見區域及全身區域進行不同級別的像素增強,同時,對背景區域像素進行像素置0 的遮罩抑制,經過對模型的迭代訓練,這種操作能夠有效地引導檢測器將背景噪聲與行人目標特征分離,關注遮擋行人目標可見區域,有效地提取行人特征,增強網絡模型的特征判別力,并且,該遮罩機制可以在一定程度上抑制前置遮擋物體的特征,削弱遮擋噪聲對檢測器性能的影響。而作為對比方法,測試基準引入SENet 與CBAM 模塊后,檢測器的性能提升并不明顯,甚至還會對測試基準的檢測效果產生消極影響,產生這種現象的原因在于,以上兩種通用注意力模塊只是通過對通道特征或通道空間混合特征的隨機調制去提升網絡模型的性能,但是對于行人檢測中的遮擋問題,可能會在注意力特征調制過程中受到遮擋噪聲與背景噪聲的影響,將行人目標特征的所對應的特征權重降低,這種操作的結果會影響模型對目標特征的學習能力,進一步降低檢測器的檢測效果。
4.3 MAGB對比實驗分析
為了進一步驗證MAGB 對遮擋行人目標的檢測性能,選取OR-CNN[3],RepLoss[4],ATT-part[5],ALFNet[6],CSP[10]等五種主流遮擋行人檢測方法與本文所提方法進行對比實驗。對比實驗在Citypersons 數據集所提供的合理子集(Reasonable,R),重度遮擋子集(Heavy Occlusion,HO),部分遮擋子集(Partial)和輕微遮擋子集(Bare)上進行驗證評估。結果如表2所示。
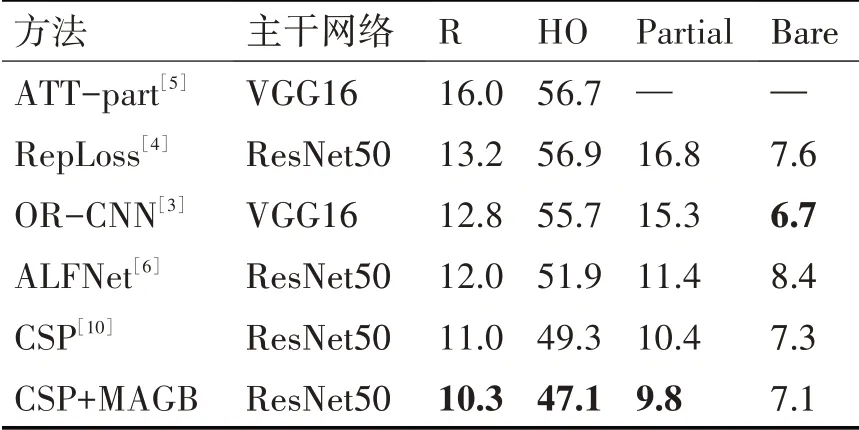
表2 在Citypersons數據集上的對比實驗結果MR-2/%
由表2 可以清晰地看出,本文方法在重度遮擋子集(HO)上取得了47.1%的MR-2,領先CSP 2.2%,這是因為通過MAGB的調制,網絡模型的注意力通過像素級的損失調制產生了空間維度的轉移,即重點關注行人目標可見區域特征,對前置遮擋及背景特征進行擦除,這個過程可以讓網絡更好地提取遮擋行人目標的特征,增強對行人特征的表征能力,抑制前置遮擋物體特征及背景噪聲對檢測過程的影響,為邊界框預測部分提供了更具魯棒性的行人特征。此外,本文方法在合理子集(R)及部分遮擋子集(Partial)上均領先于其他對比方法,在輕微遮擋子集(Bare)上本文所提方法取得了7.1%的MR-2,仍然具有不錯的檢測效果。
4.4 MAGB的跨數據集實驗分析
由于本文所提方法的網絡訓練過程在Citypersons 數據集上進行,因此,為了證明所提方法的適用性,需要在不同數據集上進行驗證實驗。
驗證實驗在Caltech 數據集所提供的合理子集(Reasonable,R),重度遮擋子集(Heavy Occlusion,HO)和整體數據集(ALL)上對測試結果進行驗證評估,將測試結果與RepLoss[4],ATT-part[5],ALFNet[6],CSP[10],DeepParts[19],F-DNN[20]等六種主流遮擋行人檢測方法進行對比,通過對比結果對所提方法的泛化性能進行驗證。泛化性能驗證實驗通過繪制FPPI-MR 曲線比較不同行人檢測方法的性能,曲線下方面積越小,檢測器性能越出色。合理子集(R)驗證結果如圖3(a)所示,重度遮擋子集(HO)驗證結果圖3(b)所示,整體數據集(ALL)驗證結果圖3(c)所示。
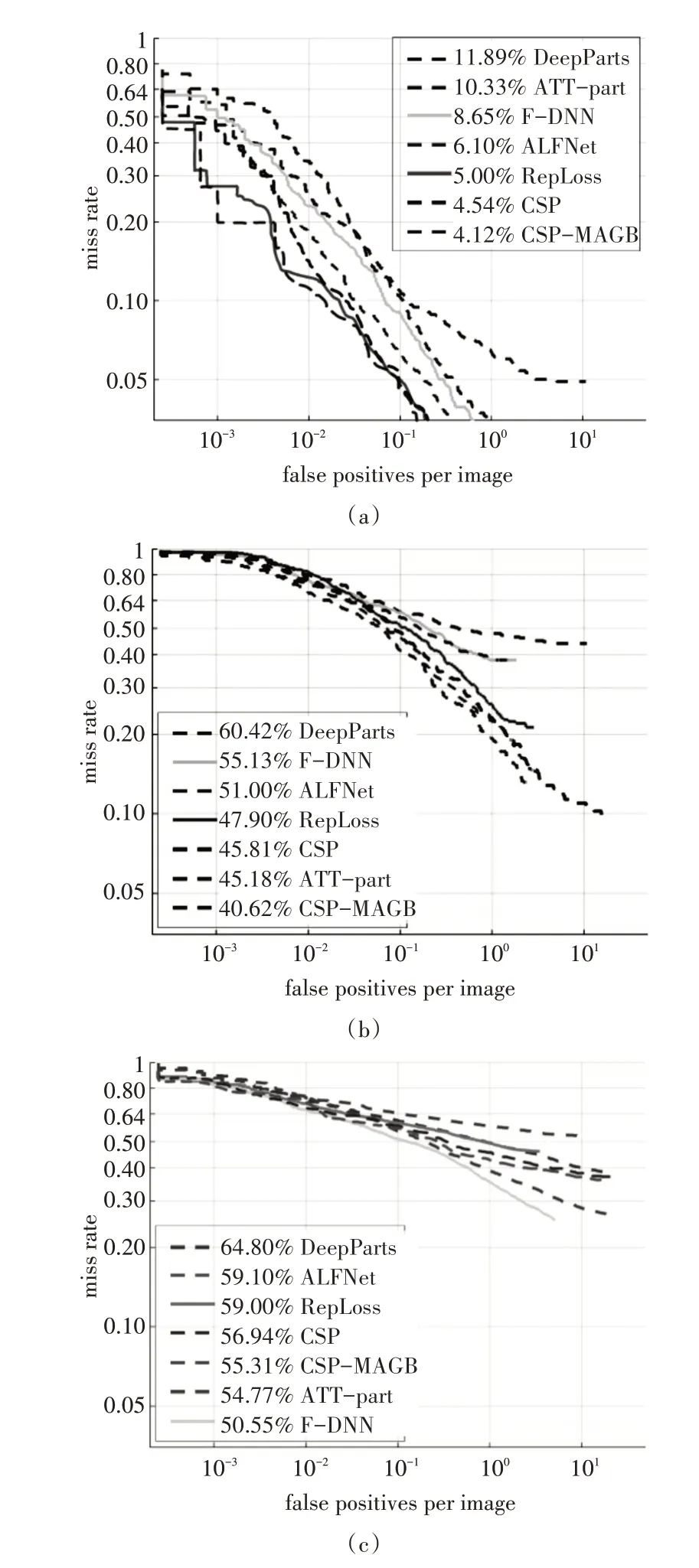
圖3 FPPI-MR曲線
通過以上結果,可以清晰地看出,在Caltech 行人檢測數據集的合理子集(R)上,本文所提方法達到了4.12%的MR-2,對比CSP 下降了0.42%,在Caltech 行人檢測數據集的重度遮擋子集(HO)上,本文所提方法達到40.62%的MR-2,對比ATT-part下降了4.56%。在Caltech 行人檢測數據集的整體數據集(ALL)上,雖然相比于CSP下降了1.63%,但是,并未達到目前最優水平,仍然有提升空間。
實驗結果表明,本文所提方法在不同數據集上仍然可以有效地應對行人檢測中的區域遮擋問題。經過分析,所提出的多尺度注意力引導模塊在進行局部特征增強的同時,通過多尺度注意力模塊的雙分支融合結構保留了全局特征,這減少了該模塊對外部監督信息的依賴性,提升了模型的泛化能力,得以使模型在不同數據集上均有較強的適用性。
4.5 真實場景檢測仿真實驗分析
為了驗證本文所提方法在真實場景的檢測效果,對測試基準CSP與本文所提方法進行真實場景檢測仿真實驗,實驗分別在Citypersons 數據集和Caltech 數據集上各選取一張具有遮擋場景的樣本圖片上進行。不同數據集檢測結果分別如圖4(a)和(b)所示,其中左側和右側分別代表測試基準和本文所提方法。

圖4 不同數據集檢測效果
上述結果中,淺色檢測框代表行人目標真實標注框,深色檢測框代表測試基準CSP 的檢測結果,白色檢測框代表本文方法的檢測結果。可以看出,在面對真實場景中的不同遮擋模式時,測試基準均不能有效地檢測出遮擋行人目標,其檢測過程會受到遮擋噪聲,重疊行人特征的影響,最終導致漏檢現象的發生。而上述示例可以看出,本文所提方法分別將每個行人目標準確檢測出來,這證明了專注于遮擋問題的多尺度注意力引導模塊的有效性,以及對不同遮擋模式均具有良好的魯棒性。
5 結語
針對行人檢測領域所面臨的遮擋問題,本文在基于anchor-free的行人檢測方法CSP 的基礎上,提出了一種多尺度注意力引導模塊,用于引導網絡模型更多地關注遮擋目標可見部分區域,抑制遮擋物的特征表現力,消除外部噪聲影響,進一步增強行人特征判別力。在Citypersons 行人檢測數據集上的實驗結果表明,所提方法有效地增強了網絡模型對行人特征的提取能力,提升了對遮擋行人目標的檢測精度,與其他主流行人檢測方法相比,本文所提方法對遮擋目標的檢測能力更為出色。在Caltech 行人檢測數據集上的泛化實驗結果表明,本文方法不過度依賴外部監督信息,在不同數據集上均實現了高質量的檢測效果,具有良好的泛化能力。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
