基于集成深度學習方法的跨被試EEG 特征情感識別*
2022-06-16 12:45:58唐杰豪
計算機與數字工程 2022年5期
唐杰豪 張 維 尹 鐘
(上海理工大學光電信息與計算機工程學院 上海 200093)
1 引言
情感計算是實現高級人機交互的關鍵技術之一,是人工智能領域中日益受到關注的研究方向。情感識別可利用人的面部表情、語音、姿勢、文本、和生理信號識別作為模型輸入[1]。基于生理信號的情感計算能反映人內在的心理生理過程。數據模態形式包括腦電、心電、肌電、皮膚電阻、皮膚電導、皮溫、光電脈搏、呼吸信號等。此外,近年來國內外有諸多工作利用機器學習方法作為建立生理數據驅動模型的基礎,結果表明這些技術對人腦電信號(Electroencephalogram,EEG)的分析是可行的。
集成學習是通過構建并結合多個弱學習器來完成學習任務的方法,即“博采眾長”,可以用于分類問題、回歸問題、特征選擇、異常點檢測等的集成。由于現在計算能力不斷增強,隨著訓練數據量的增加,大型神經網絡的算法性能與傳統的機器學習算法相比體現出越來越大的優越性,而且深度模型有很大的參數量,具有靈活、可調整性大的特點,使得研究者可以更快地驗證自己的想法,以便不斷試錯而得到更好的想法。
本研究的目的是將傳統的機器學習算法與集成深度學習的方法應用于跨被試的EEG 特征情感識別任務中,通過比較結果來證明集成深度學習方法的優勢。
2 相關工作
相關領域已有不少工作取得了好成績。文獻[2]中將同一時間段,不同通道的信號組合成一個向量,輸入至雙峰深度自編碼器(Bimodal Deep AutoEncoder,BDAE)中,生成EEG 特征。最終得到效價(Valence),喚醒度(Arousal),支配度(Dominance),喜愛度(Liking)維度的情感識別精度分別為85.2%、80.5%、84.9%、82.4%。文獻[3]將多元經驗模式分解產生的(Intrinsic Mode Function,IMF)歸一化,并在其中提取功率譜密度(Power Spectrum Density,PSD)、高階統計量(Higher Order Statistic,HOS)等特征,再經過獨立成分分析(Independent Component Analysis,ICA)進行處理,分別得到valence、arousal 維度的二分類精度為72.87±4.68%、75.00±7.48%。文獻[4]采用巴特沃斯濾波器獲取θ、α、β三個頻段的時域信號,并在此基礎上分別計算雙頻譜功率,最終取得了61.17%、64.84%的valence、arousal 維度二類情感識別精度。文獻[5]中將數據集按照熟悉度分為低熟悉度(1 分~2分)和高熟悉度(3 分~5 分)兩部分,以分形維度(Fractal Dimension,FD)和PSD 作為特征,結果得到valence、arousal 維度二分類的結果為73.30%、72.50%。
文獻[6]中利用快速傅里葉變換(Fast Fourier Transform,FFT)計算功率作為特征,使用了概率神經網絡(Probabilistic Neural Network,PNN)模型,得到valence、arousal 維 度 二 分 類 結 果81.21% 、81.76%。文獻[7]對數據集里60s 的數據只用后40s 的數據進行實驗,將θ、α、低頻β(lower beta)、高頻β(upper beta)、γ頻段的數據每個頻段分為3個子頻段,在每個子頻段上用短時傅里葉變換(Short-Time Fourier Transform,STFT)計算PSD,使用了堆疊降噪自動編碼器(Stacked Denoising Auto Encoder,SDAE)和深度信念網絡(Deep Belief Network,DBN),其中基于DBN 的模型在arousal、valence、liking 維度上的F1 值分別達到86.67%,86.60%和86.69%。文獻[8]用長度為4s的窗將60s的數據分為15 段,計算512 點的FFT 來分離波段,對每個波段求能量,并且用ReliefF 算法進行特征選擇給出了排名前15 的通道高頻波段,最后valence和arousal維度二分類結果為60%左右。
3 方法
3.1 數據集介紹
第一個數據集是DEAP[9]數據集。32個參與者(被試)參與數據采集實驗,每個被試在觀看經過選擇的40 個不同類型的長度為1min(在這之前有3秒預采樣的準備時間)的視頻的同時,以512Hz 采集32 通道的EEG 腦電信號,經過預處理后再下采樣至128Hz。數據集每個被試的數據分為兩個數組,一個是data 數組,格式為40×40×8064(視頻/試驗×通道×數據),另一個是labels數組,格式為40×4(視頻/試驗×標簽)。標簽在Valence,Arousal,Dominance,Liking 四個維度上表示為1~9 的連續值。
第二個數據集是HCI[10]數據集。27 個被試參與數據采集實驗,采集的信息包括面部視頻,音頻信號,眼動數據,周圍/中樞神經系統的生理信號。在數據采集實驗中,被試觀看了20 個情緒視頻,并使用Valence,Arousal,Dominance,可預測性(Predictability)以及情緒關鍵詞來自我報告他們的情緒感受。
3.2 數據預處理
在DEAP 中,根據國際10-20 標準,取前32 個電極作為進一步分析。DEAP 數據集有公共參考電極,所以每個電極的電壓可確定;在HCI中,同樣取32 個通道分析,但HCI無公共參考電極,故取32個導聯電極的平均作為公共參考點,每個電極的電勢減去此公共參考點即為電壓。用巴特沃斯帶寬濾波器對數據進行濾波,只保留4Hz~45Hz的數據,參考文獻[11]并作修改,分為四個頻段,分別為θ(4Hz~8Hz)、α(8Hz~14Hz)、β(15Hz~30Hz)、γ(30Hz~45Hz)。
一個頻段內每個被試的一個試驗的數據8064個點的數據表示為63s×128Hz,在此去除前3s 的信號,保留后60s 的數據,數組變為(32,60×128)即(32,7680),經過改變形狀后為(60,32×128)。選用valence 和arousal 維度作為分類任務的標簽,兩個數據集處理方法相同,數值小于5.0 標記為0,大于等于5.0 則標記為1,即可把標簽轉換為二分類標簽。
3.3 特征提取
取每秒內每個頻道的128 個數據點,參考文獻[12],采用微分熵(Differential Entropy,DE)作為工具做特征提取,由:
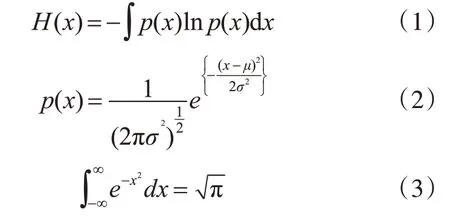
可得:

式(4)為計算微分熵的公式,其中σ2為每秒128 個點的數據的方差。經過特征提取后數組形狀變為(40×60,32),同理其他三個頻段重復此提取過程,再將32 個被試的數據拼接起來,數據集最終處理為(32×2400,32×4)即(76800,128)。HCI只取24 個被試做研究,預處理與特征提取過程類似,經過處理后數據集的形狀為(24×2400,128),即(28800,128)。DEAP 數據集提取了微分熵特征后未進行歸一化處理,HCI 數據集經過了歸一化處理。
3.4 機器學習模型
本研究選取線性分類器(Logistic)、支持向量機(Support Vector Machine,SVM)、K 近鄰(K-nearest Neighbor,KNN)、樸素貝葉斯、決策樹(Decision Tree)對數據集進行評估。模型使用的最佳參數通過網格搜索、hyperopt工具調參而得到。
3.5 集成模型
本研究采用兩種集成學習的方法對EEG 的兩個數據集進行分析:Boosting,Bagging。
梯度提升樹(Gradient Boosting Decision Tree,GBDT)是一種迭代的決策樹算法,是Boosting 家族的成員,GBDT 的核心在于每一個弱學習器學習的是上一輪迭代結論和的殘差,即殘差與預測值之和等于真實值。XGBoost(eXtreme Gradient Boosting)[13]是Gradient Boosting 算法的高效實現,而且做了許多優化,故將其應用在本研究中。Adaboost(Adaptive Boosting)[14]是一種自適應的boosting 算法,它的自適應在于:前一個基本分類器分錯的樣本會得到加強,加權后的全體樣本再次被用來訓練下一個基本分類器。同時,在每一輪中加入一個新的弱分類器,直到達到某個預定的足夠小的錯誤率或達到預先指定的最大迭代次數。隨機森林(Random Forest,RF)是對Bagging算法的改進,基本學習器限定為決策樹,一個樣本的分類結果由多棵決策樹綜合決定。
同樣,四個集成模型使用的最佳參數通過網格搜索和hyperopt工具進行調參而得到。
3.6 深度學習模型
3.6.1 深度神經網絡
參考文獻[15]的DNN 網絡結構,本研究使用的深層神經網絡(Deep Neural Network,DNN)有4個全連接層。第一層輸入層有128 個神經元,層后連接 參數keep_prob=0.25 的Dropout 層。隱藏層1和隱藏層2 的神經元個數分別是2000 和200,其后連接的是keep_prob=0.5 的Dropout 層。這三個隱藏層都以線性整流函數(Rectified Linear Unit,Re-LU)作為激活函數。輸出層有兩個神經元,使用Softmax 函數作為激活函數,輸出one-hot 編碼形式的標簽。DNN的結構如圖1所示。

圖1 DNN網絡結構
3.6.2 卷積神經網絡
本研究將卷積神經網絡(Convolutional Neural Network,CNN)應用于情感識別的分類任務中,模型結構如圖2所示。把DEAP數據集的形狀重塑為(76800,16,8,1),即把每個樣本看作一個長16寬8通道數為1 的圖片矩陣,相對應的HCI 數據集的形狀重塑為(28800,16,8,1)。模型第2、3 層都為卷積層,第2 層有64 個神經元,第3 層有128 個神經元,都使用3×3的卷積核以及雙曲正切函數(hyperbolic tangent function,tanh)作為激活函數,函數表達式如下:
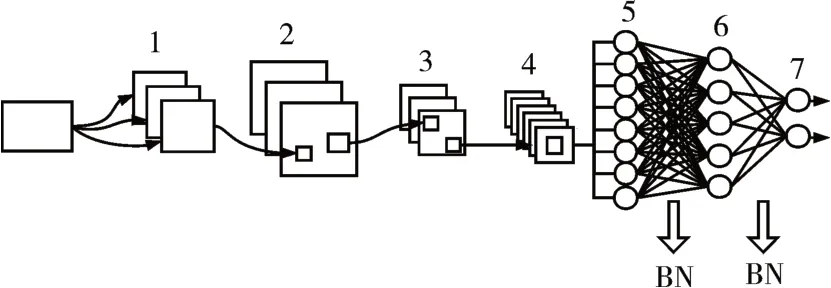
圖2 CNN深度模型結構
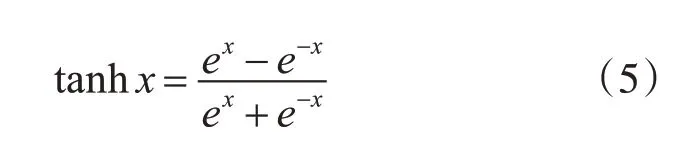
4 是一個最大池化層(max pooling),池化窗口大小為2×2。模型在經過第5 層的flatten 操作后連接的是間隔著批量歸一化(BatchNormalization,BN)層[16]的全連接層,BN 層的作用是把數據歸一化,防止訓練發生偏移,加快訓練速度。全連接層6 有128 個神經元,其中加入了L2 正則化以減小過擬合。輸出層7的激活函數為Softmax。
3.6.3 GoogLeNet
受集成模型中模型融合策略的啟發,多模型結合進行分類任務一般會提高結果的準確率,因此本研究嘗試使用一個用于計算機視覺的經典的卷積神經網絡架構——GoogLeNet[17]來對EEG數據集進行分析。本研究參考GoogLeNet 而使用的深度模型的結構如表1,Inception module 如圖3 所示,其中加入了L2正則化以減小過擬合,第40層Dropout層的參數keep_prob=0.6。

表1 GoogLeNet 網絡結構
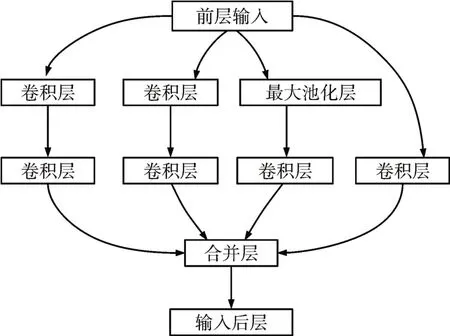
圖3 Inception module 結構
3.7 訓練方法
本研究中機器學習模型、集成模型與深度模型對數據集樣本的訓練統一采用K-折交叉驗證(K-fold cross validation)的方法(K=32)來達到跨被試研究的目的,即每一次驗證取31個被試的74400個樣本作為訓練集,另外1個被試的2400個樣本作驗證集進行訓練。機器學習模型與集成模型使用準確率(accuracy)、roc 分數(roc-score)作為指標記錄下驗證集的結果,深度模型使用準確率作為指標記錄下每個被試驗證的結果。深度模型的參數設置如表2。
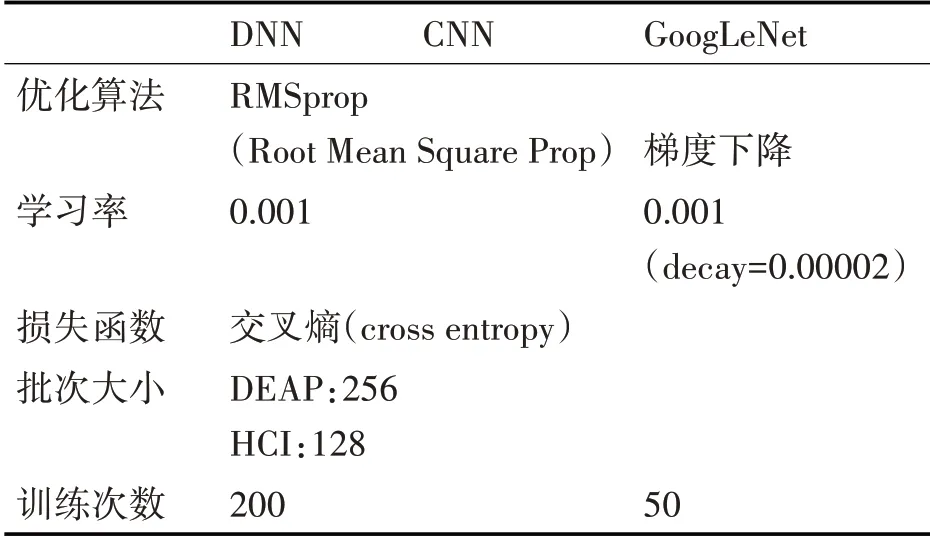
表2 深度模型參數
4 結果與分析
4.1 機器學習模型實驗結果
logistic、SVM、KNN、樸素貝葉斯、決策樹對DEAP、HCI 兩個數據集得到的跨被試交叉驗證的準確率(accuracy)與roc 的結果取平均如表3(兩個數據集每一列的最大值用粗體表示,最小值用斜體表示),其中SVM 在兩個數據集上的跨被試分類準確率箱型圖如圖4。
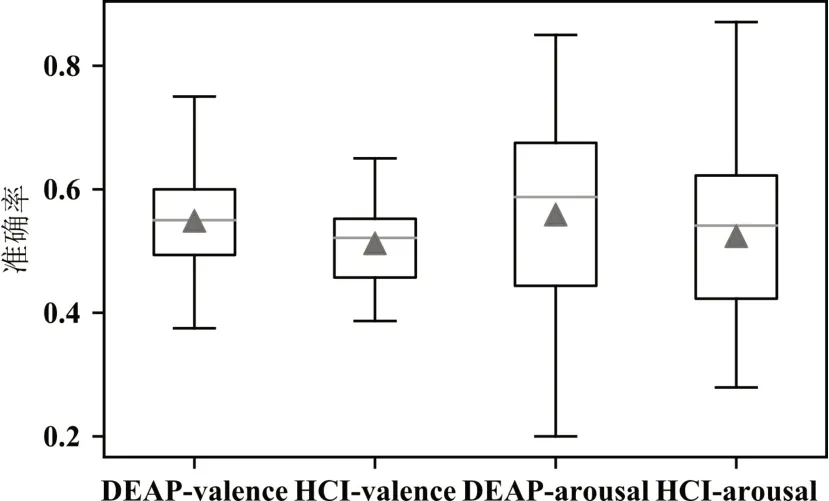
圖4 SVM模型的準確率跨被試曲線
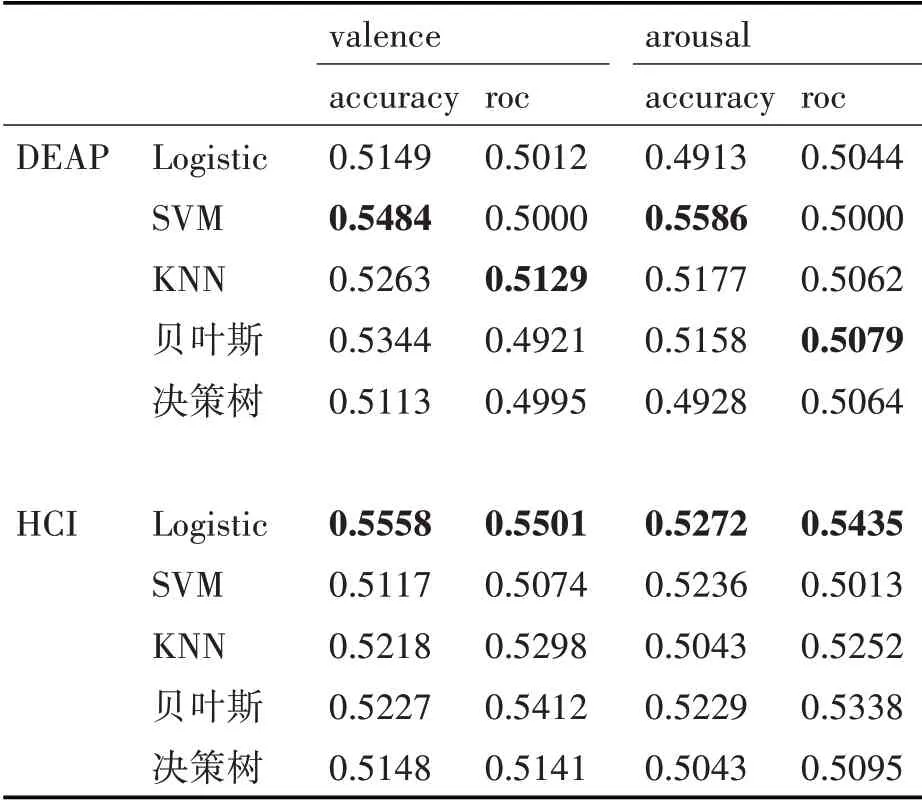
表3 機器學習模型跨被試分類平均結果
4.2 集成模型實驗結果
集成學習中的GBDT、Xgboost、Adaboost、隨機森林(RF)四個模型對兩個數據集進行跨被試交叉驗證的準確率、roc 結果取平均如表4(兩個數據集每一列的最大值用粗體表示,最小值用斜體表示)所示。其中Adaboost 在兩個數據集上的跨被試分類準確率箱型圖如圖5。
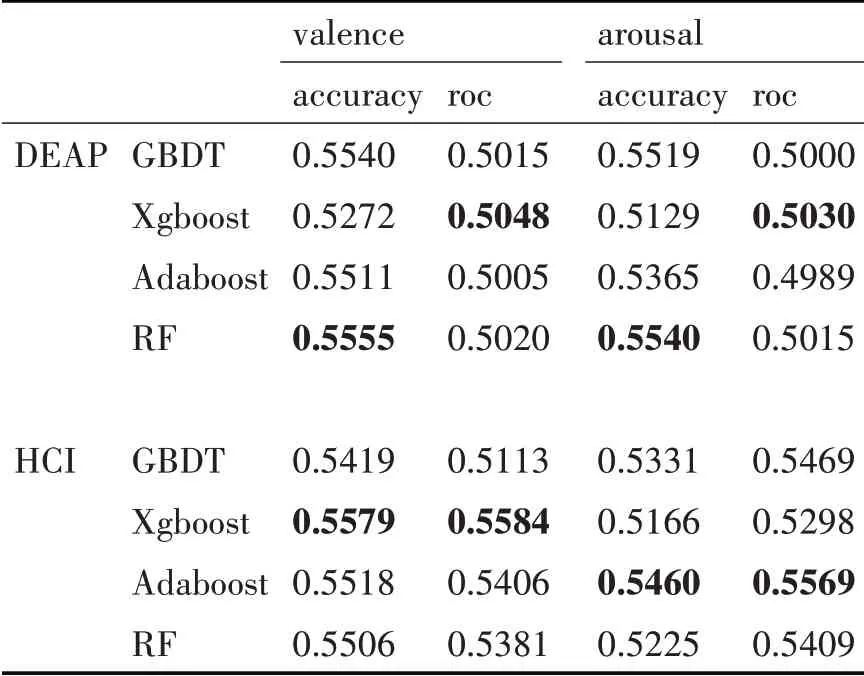
表4 集成模型跨被試分類平均結果

圖5 Adaboost模型的準確率跨被試曲線
4.3 深度模型實驗結果
深度學習的三個模型對兩個數據集進行交叉驗證得到的準確率的結果的平均如表5(每一列的最大值用粗體表示,最小值用斜體表示)所示,每個模型在DEAP 的valence、arousal 上的準確率曲線如圖6,在HCI 的valence、arousal 上的準確率曲線如圖7。
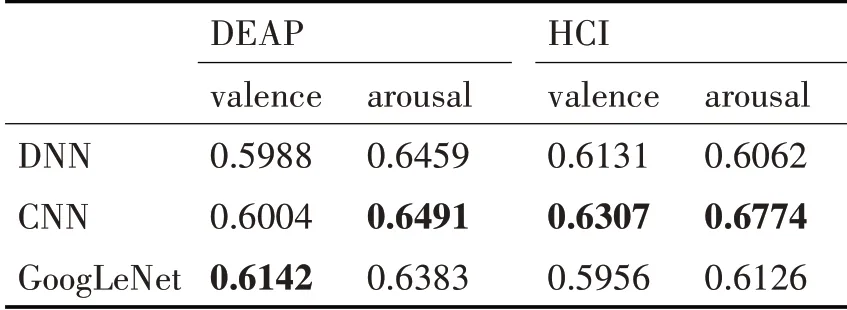
表5 深度模型跨被試分類準確率平均結果
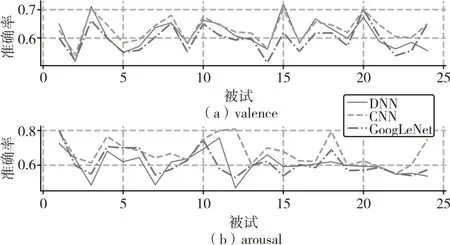
圖7 深度模型在HCI數據集上的準確率跨被試曲線
4.4 分析
從表3中可以看出DEAP數據集中取得較高準確率的機器學習算法為SVM算法,HCI數據集中取得較高準確率的為Logistic;表4 顯示DEAP 數據集中準確率結果較高的集成模型為隨機森林模型,而HCI 數據集中Xgboost 與Adaboost 則取得了較好的結果。集成模型取得的平均準確率與機器學習模型相差不大但略優于機器學習模型的結果。對比圖4、5,SVM 與Adaboost 模型的識別準確率比較接近,在valence 上的跨被試準確率數據相比arousal更集中。由表5 可得深度模型在DEAP、HCI 上的valence 和arousal 上的平均準確率分別為0.5988~0.6142、0.6383~0.6491、0.5956~0.6307、0.6062~0.6774。 將三個方法對兩個數據集的valence 和arousal 維度取得最好結果的模型進行總結如表6,總體而言在三個方法中,深度學習的方法取得的成績是最好的,且明顯優于機器學習算法與集成模型。
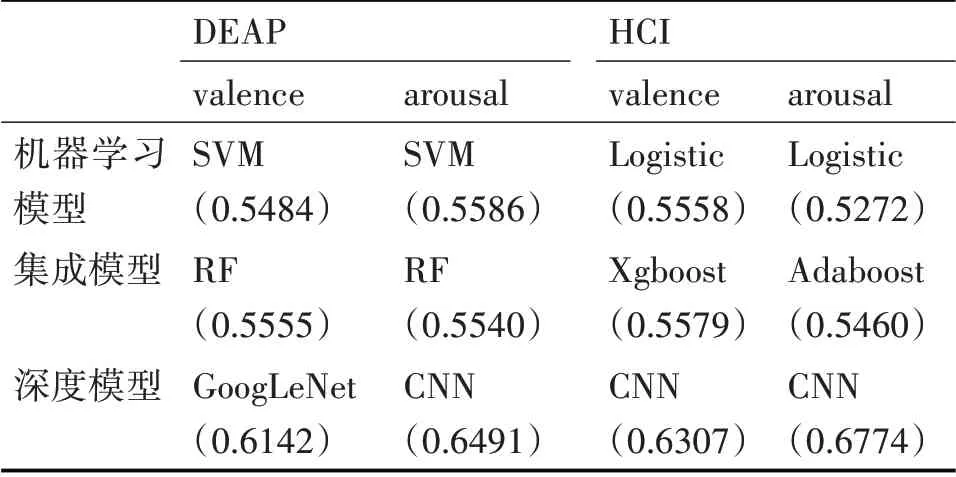
表6 各方法準確率的比較
5 結語
在腦電信號EEG 的特征情感識別中,集成學習具有高效的算法以及模型融合的優點,深度學習方法的神經網絡模型參數量大、復雜度高,在樣本數量足夠多的情況下,深度神經網絡能利用樣本數據訓練出更好的模型。本研究嘗試將應用于計算機視覺領域的卷積神經網絡模型和復雜度更高的GoogLeNet 架構應用于EEG 的情感識別上,結果沒有明顯優于使用其他深度模型得到的結果,說明了采取更合適的策略和模型是很重要的。總體而言,本研究利用微分熵作為特征提取工具的基于集成深度學習方法對EEG 的跨被試特征情感識別取得了較好的識別結果。后續可采取效果更好的特征提取方式和模型對研究方法進行優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
