基于改進XGBoost 的電商客戶流失預(yù)測*
2022-06-16 12:46:08廖開際鄒珂欣莊雅云
計算機與數(shù)字工程 2022年5期
廖開際 鄒珂欣 莊雅云
(華南理工大學(xué)工商管理學(xué)院 廣州 510641)
1 引言
目前我國電商行業(yè)發(fā)展迅速,電子商務(wù)數(shù)據(jù)作為國家大數(shù)據(jù)戰(zhàn)略的重要組成要素,不僅有很高的應(yīng)用價值,還有很高的經(jīng)濟價值[1]。目前,電子商務(wù)競爭愈發(fā)激烈,各大電子商務(wù)企業(yè)在推進業(yè)務(wù)增長的同時均在發(fā)展以客戶為中心的企業(yè)戰(zhàn)略,而如今企業(yè)發(fā)展新客戶的成本越來越高甚至大幅超過用以維系老客戶的成本,所以,如何有效精準(zhǔn)識別潛在的客戶流失對電商企業(yè)的長期戰(zhàn)略發(fā)展有著舉足輕重的意義。
目前國內(nèi)外通常采用的客戶流失預(yù)測研究主要有基于傳統(tǒng)統(tǒng)計學(xué)方法的客戶流失預(yù)測,如朱志勇等[2]利用貝葉斯分析客戶流失特征,創(chuàng)建貝葉斯網(wǎng)絡(luò)模型;張宇等[3]利用決策樹算法,創(chuàng)建了所需的流失預(yù)測模型,并用中國郵政的業(yè)務(wù)數(shù)據(jù)對模型進行了驗證;Arno De Caigny[4]將決策樹與邏輯回歸結(jié)合,為兩階段客戶創(chuàng)建了相應(yīng)的流失預(yù)測模型,但這兩種方法較為簡單,對于數(shù)據(jù)維度較高的問題不太適用。
近幾年由于人工智能等技術(shù)的發(fā)展,利用機器學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)構(gòu)建的客戶流失預(yù)測模型,也取得了很大的進展。如Ruiyun 等[5]提出了一種優(yōu)化的BP神經(jīng)網(wǎng)絡(luò)來預(yù)測電信公司流失客戶。Yaya Xie[6]提出改進平衡隨機森林算法的預(yù)測模型并將其應(yīng)用于銀行客戶流失數(shù)據(jù)集,結(jié)果表示該方法效果更優(yōu)。朱幫助等[7]提出了基于最小二乘SVM 的三階段客戶流失預(yù)測模型并驗證了模型的有效性。王重仁[8]等通過把社交網(wǎng)絡(luò)分析、XGBoost 兩者結(jié)合起來,最終發(fā)現(xiàn)具有更好的效果。
以上基于人工智能和機器學(xué)習(xí)的算法雖然都能有效地提高客戶流失的預(yù)測精準(zhǔn)度,但是其研究所涉及領(lǐng)域與電商大數(shù)據(jù)領(lǐng)域的特點仍有一定差異。如今,在研究客戶流失預(yù)測狀況時,主要把契約型客戶當(dāng)作研究對象,其流失有著較為明確的標(biāo)志。然而以電子商務(wù)客戶為典型代表的非契約型客戶與企業(yè)之間并不存在契約關(guān)系,企業(yè)無法準(zhǔn)確觀察到客戶的流失時間點,因此該類客戶的流失預(yù)測是現(xiàn)階段研究的難點和重點。
本文基于多種模型和算法,開發(fā)了相應(yīng)的客戶流失預(yù)測方法,在最終的預(yù)測模型中還對預(yù)測過程中對電商領(lǐng)域?qū)φ骊栃藻e誤更敏感的情況進行了針對性的算法改進,使得方法和模型更加符合電商領(lǐng)域的使勁應(yīng)用情境。
2 客戶流失預(yù)測模型
圖1 展示了模型的基本流程,該方法含有三個不同的模塊,包括流失預(yù)測模型模塊,客戶細(xì)分模塊、客戶特征篩選模塊。
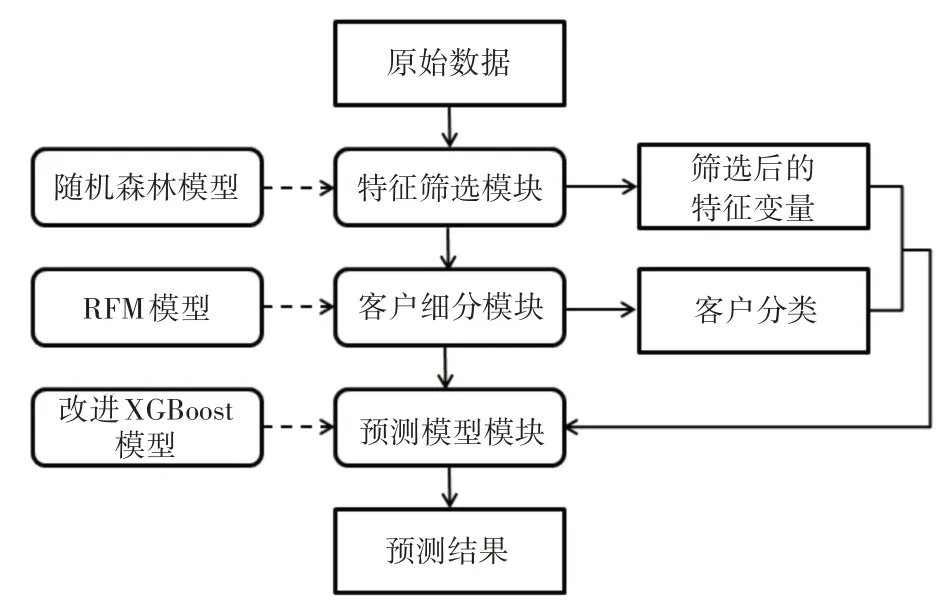
圖1 預(yù)測方法流程圖示
2.1 客戶特征篩選模塊
由于電子商務(wù)客戶的特征數(shù)量較多且維度較高,在進行客戶流失預(yù)測之前首先采用隨機森林算法進行降維和特征篩選操作。隨機森林算法通過計算數(shù)據(jù)誤差來衡量特征的好壞程度,其中的數(shù)據(jù)誤差來源自訓(xùn)練決策樹時隨機抽取的樣本數(shù)據(jù)所帶來的隨機誤差[9]。特征X 的重要性由式(1)計算得出。
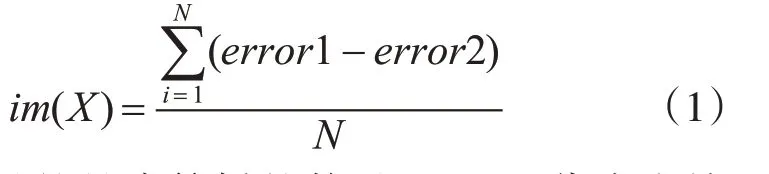
其中,N 表示的是決策樹的數(shù)量。error1 代表去掉被抽取樣本數(shù)據(jù)外的數(shù)據(jù)誤差,error2 代表加入隨機干擾后去掉被抽取樣本數(shù)據(jù)外的數(shù)據(jù)誤差。
對于原始數(shù)據(jù)集合首先使用Boot-Strapping隨機采樣方法來獲取n 個數(shù)據(jù)樣本集合。再對數(shù)據(jù)子集進行單獨訓(xùn)練,變?yōu)闃浞诸惼鳎瑢τ诿恳粋€樹分類器,在實施分裂操作時,會需要按照信息增益情況,選擇最佳的分裂特征[10]。隨后每棵樹繼續(xù)分裂,直到所有的訓(xùn)練樣本分為同一類結(jié)束,然后組合不同的決策樹,形成隨機森林,此時每個特征的影響程度也會被計算出來。最終選取影響程度高且其累計營銷程度超過90%的特征進行流失客戶預(yù)測。
2.2 客戶細(xì)分模塊
客戶細(xì)分是指根據(jù)客戶的某些特征來識別客戶群體的方法,其中基于客戶價值的細(xì)分是近年來較為常見且應(yīng)用廣泛的方法,其中,對于RFM 模型而言,是從眾多交易數(shù)據(jù)中篩選出來的,可以有效地判斷用戶的價值,常被用于研究顧客忠誠度和活躍度[11]。
本文提出的客戶細(xì)分模塊是以RFM 客戶價值模型為重要依據(jù)與分類基礎(chǔ),確定RFM 模型的三大指標(biāo),組成相應(yīng)的數(shù)據(jù)集,然后通過K-means 方法,實施聚類操作,詳細(xì)地劃分電子商務(wù)客戶的類型。主要指標(biāo)如下所示,分別為Recency、Frequency、Monetary[12]。其中,R 代表的是最近購買與現(xiàn)在相距的時間,反映了用戶活躍程度;F 代表的是某一階段的購買頻次,反映的是用戶的忠誠度;M 代表的是某一階段購買的總金額,反映了用戶消費能力[13]。
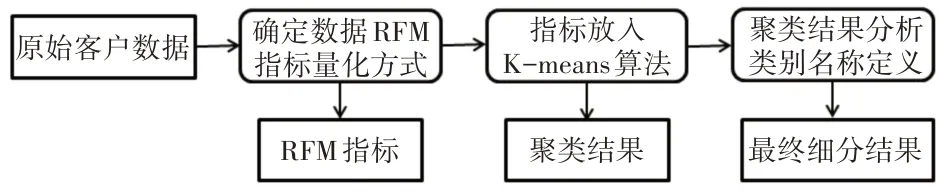
圖2 客戶細(xì)分模塊流程圖
將通過RFM 模型確定的指標(biāo)數(shù)據(jù)放入K-means聚類算法中得到一個收斂的聚類結(jié)果,對于K-means 算法,它是最常用的聚類算法,是一種劃分為主的聚類算法[14]。最后對聚類結(jié)果進行分析并根據(jù)每一個客戶類別顯示出來的特點對聚類結(jié)果中的客戶類別進行命名,最終對客戶進行細(xì)分。
2.3 流失預(yù)測模型模塊
根據(jù)電子商務(wù)領(lǐng)域的情境,將客戶流失錯分為非客戶流失視為第一類錯誤。在此種情況下,企業(yè)不會挽留這部分客戶,企業(yè)將會錯失此類客戶。而對于非客戶流失,錯誤的看作是客戶流失,這屬于第二類錯誤,此時企業(yè)會對被錯分為客戶流失的客戶采取相挽留措施,從而增加了企業(yè)的運營成本。然而,通過研究發(fā)現(xiàn),與維持老客戶相比,發(fā)展新客戶所需的成本更高,所以在預(yù)測電子商務(wù)客戶流失時,第一類錯誤能夠?qū)е赂蟮膿p失,遠(yuǎn)遠(yuǎn)超過了第二類錯誤。因此,通過分析電子商務(wù)客戶流失預(yù)測發(fā)現(xiàn),對真陽性錯誤更敏感。
XGBoost 算法在處理大數(shù)據(jù)集時能夠保持較高的精度,其原理通過不斷對誤差進行進一步分類,來改善系統(tǒng)的訓(xùn)練準(zhǔn)確率[15]。因此本文選擇XGBoost 來構(gòu)建流失客戶預(yù)測模型。在處理分類問題時,XGBoost 一般把對數(shù)函數(shù)當(dāng)作損失函數(shù),見式(2)。本文基于電子商務(wù)的特殊情境,在XGBoost 算法的損失函數(shù)中,需要添加上懲罰系數(shù)α(0.5<α≤1),對上述兩類錯誤的損失比例進行了調(diào)整,見式(3)。

當(dāng)樣本yi=1 時,相應(yīng)的損失函數(shù)為ln(1+e-αy^t) ,如果樣本yi=0 時,那么損失函數(shù)為ln(1+e(1-α)y^t)。可見經(jīng)過對損失函數(shù)的改進,發(fā)生一類錯誤的損失會高于二類錯誤損失,更加符合電子商務(wù)領(lǐng)域場景特征。經(jīng)過多次實驗,當(dāng)懲罰系數(shù)α取0.6 時,AUC 值達(dá)到最優(yōu),因此預(yù)測模型中懲罰系數(shù)α取值為0.6。
3 預(yù)測模型驗證與結(jié)果對比
本文采用國內(nèi)某電子商務(wù)平臺中4439 名客戶在2018 年1 月至8 月產(chǎn)生的數(shù)據(jù)作為原始數(shù)據(jù)對提出的方法進行驗證。通過準(zhǔn)確率、召回率、ROC曲線、AUC值等指標(biāo),對其進行評價。
3.1 特征篩選結(jié)果
采用隨進森林算法對上述數(shù)中21 個特征進行篩選,得到表1 中重要性程度較高的7 個特征,且這7 個變量對結(jié)果的解釋貢獻(xiàn)率達(dá)到了90%,因此選取這7 個特征變量作為最終輸入預(yù)測模型的特征。

表1 特征變量重要性結(jié)果
3.2 客戶細(xì)分結(jié)果
通過標(biāo)準(zhǔn)化等預(yù)處理操作之后,再通過K-means聚類算法,實施相應(yīng)的聚類操作。經(jīng)過反復(fù)試驗,發(fā)現(xiàn)當(dāng)類數(shù)K=3 時結(jié)果達(dá)到收斂,故最終結(jié)果將客戶分為三類,最終聚類結(jié)果見表2。
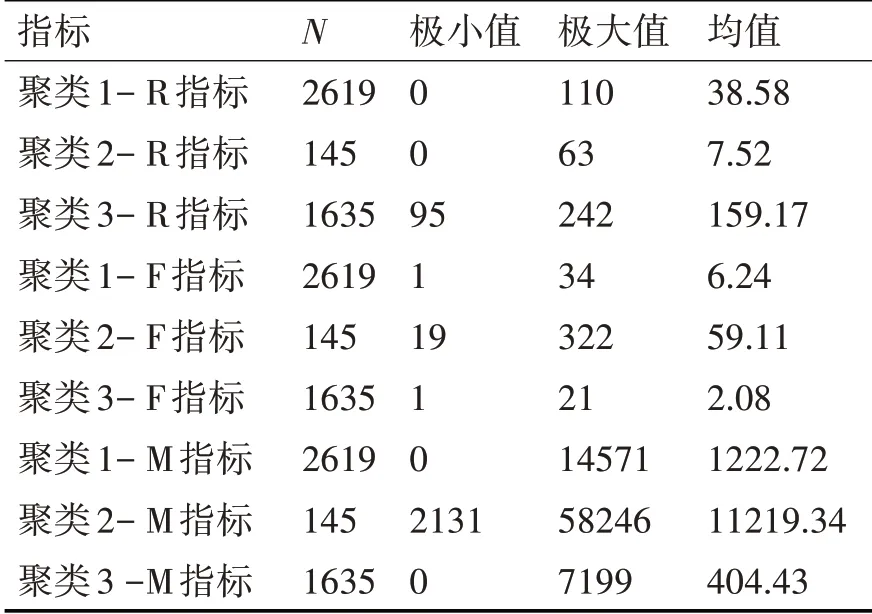
表2 客戶細(xì)分結(jié)果
對結(jié)果中的三類客戶的三項指標(biāo)分別進行描述統(tǒng)計后發(fā)現(xiàn),第二類客戶的R 指標(biāo)均值最小為7.52,同時這類客戶的F 指標(biāo)與M 指標(biāo)均值在三類客戶中均為最大且遠(yuǎn)大于其他兩類客戶,即這類客戶最后一次在該電子商務(wù)平臺的購買時間距現(xiàn)在普遍較近而且他們的累計訂單數(shù)與累計銷售額遠(yuǎn)高于其他兩類客戶。可以認(rèn)為這類客戶經(jīng)常在該平臺消費且消費金額較大,可見此類客戶對電子商務(wù)企業(yè)具有重要的價值,因此將聚類結(jié)果中的第二類客戶定義為重要價值客戶。
聚類結(jié)果中的第三類客戶的R 指標(biāo)均值最大為159.17,并且該類客戶的F 指標(biāo)與M 指標(biāo)的均值遠(yuǎn)小于其他兩類指標(biāo),即第三類客戶最后一次在該電子商務(wù)平臺的購買時間較現(xiàn)在較遠(yuǎn)且這類客戶的累計訂單數(shù)與累計消費金額較小,這就表示該類客戶在該平臺購買的頻率較低且消費力度較小,該類用戶更容易變成潛在的客戶流失,因此需要企業(yè)針對他們開展相應(yīng)的挽留措施,所以,在得出聚類結(jié)果之后,往往把第三類客戶當(dāng)作價值最低的客戶。
聚類結(jié)果中的第一類客戶的三項指標(biāo)的均值均處于中等水平,這表示該類客戶在活躍度、忠誠度以及消費能力上均處于三類客戶的中間水平,因此,把這部分客戶當(dāng)作一般價值的客戶。
3.3 XGBoost算法改進前后對比
算法改進前后預(yù)測結(jié)果的各項評價指標(biāo)見表3,可知改進后的算法在各個指標(biāo)上的表現(xiàn)均優(yōu)于改進前的算法。
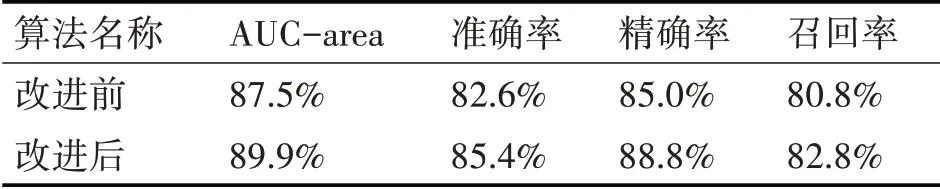
表3 XGBoost改進前后預(yù)測結(jié)果對比表
3.4 不同算法對比
這里選取了邏輯回歸、支持向量機、BP 神經(jīng)網(wǎng)絡(luò)這三種常用的算法模型來與改進后的XGBoost算法進行對比分析,結(jié)果見表4。可以看出,除了召回率與其他算法存在較小差距之外,改進后的XGBoost 算法的預(yù)測結(jié)果在其余各項指標(biāo)的表現(xiàn)均明顯優(yōu)于其他算法,即說明改進后的XGBoost 算法較其他算法來說在預(yù)測客戶流失的效果上表現(xiàn)更好。
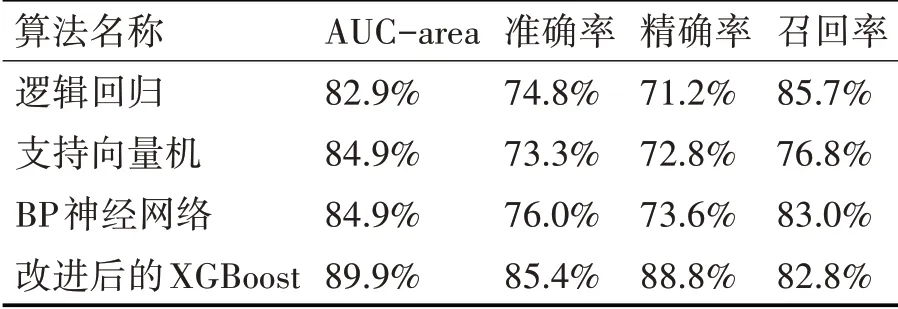
表4 各類算法預(yù)測結(jié)果對比表
3.5 客戶細(xì)分前后對比
經(jīng)過客戶細(xì)分后再進行預(yù)測與用總體客戶即不進行客戶細(xì)分進行預(yù)測的結(jié)果對比見表5(均采用改進后的XGBoost 算法進行預(yù)測),可以看出經(jīng)過客戶細(xì)分后再進行預(yù)測時各個評價指標(biāo)的結(jié)果均有明顯上升,說明在預(yù)測前對客戶進行細(xì)分能夠有效提升價值客戶的流失預(yù)測精度。

表5 客戶細(xì)分前后預(yù)測結(jié)果對比
4 結(jié)語
研究結(jié)果表明經(jīng)過預(yù)先進行客戶細(xì)分能更有效地進行客戶流失的預(yù)測,預(yù)測結(jié)果的各評級指標(biāo)均有明顯提升。同時,結(jié)合電子商務(wù)客戶流失的特征,對損失函數(shù)作出一定的修正,改進后的XGBoost 算法的預(yù)測效果相比改進前也有更好的表現(xiàn),預(yù)測結(jié)果AUC 值提高了2.4%,準(zhǔn)確率提升了2.8%,精確率提升了3.8%,召回率提升了2%。由此可以說明,所提出的預(yù)測方法是行之有效的。
根據(jù)客戶價值對電子商務(wù)客戶進行了細(xì)分并預(yù)測了不同群體中的客戶流失情況,但是現(xiàn)有研究主要基于結(jié)構(gòu)化的客戶數(shù)據(jù),圖片、音視頻等其他類型的復(fù)雜數(shù)據(jù)并沒有涉及,后續(xù)有待進一步深入研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
