基于密集連接與特征增強的遙感圖像檢測
2022-06-16 05:24:58王道累杜文斌劉易騰張天宇孫嘉珺李明山
計算機工程 2022年6期
王道累,杜文斌,劉易騰,張天宇,孫嘉珺,李明山
(上海電力大學能源與機械工程學院,上海 200090)
0 概述
隨著遙感技術的快速發展,高分辨率光學遙感圖像以其觀察面積大、范圍廣、不受國界和地理條件限制等特點而受到國內外學者的廣泛關注。在森林防護、交通監測、電力檢修、資源勘探、城建規劃等領域,遙感圖像檢測發揮著十分重要的作用,例如,通過檢測車輛目標來進行交通秩序管理,通過檢測建筑房屋等目標來為城市規劃提供依據,通過檢測受災房屋、道路、橋梁等目標來評估受災情況等[1]。傳統的遙感圖像檢測方法主要利用人工設計特征的方式提取特征信息然后訓練分類器,通過滑動窗口獲取圖像區域,由分類器輸出預測結果[2]。這種檢測方法不僅消耗較多資源,檢測速度與準確性往往也無法達到要求。
近年來,隨著計算機硬件與人工智能技術的不斷發展,基于深度學習的目標檢測算法因其適用性強、檢測效率高等優點而得到廣泛應用。基于深度學習的目標檢測算法主要分為兩類:第一類為雙階段目標檢測算法,以Faster R-CNN[3]、Mask R-CNN[4]等為代表;第二類為單階段目標檢測算法,以SSD[5]、YOLO[6]、YOLO9000[7]、YOLOv3[8]等為代表。目前,深度學習在遙感圖像檢測應用[9]中主要存在以下問題:遙感圖像分辨率較高,被檢目標信息少,背景噪聲影響較大,使得一般的目標檢測算法無法準確提取原始圖像的特征信息,造成分類和定位困難;遙感圖像中的目標普遍小而密集,尺寸較小的目標在網絡學習過程中極易被忽略,導致網絡對小目標的學習不足,降低了檢測的準確率。
為解決上述問題,本文對YOLOv3 算法進行改進,建立一種基于密集連接與特征增強的目標檢測模型。該模型使用改進的密集連接網絡作為主干網絡,同時基于Inception[10]與RFB(Receptive Field Block)[11]擴大卷積感受野,并引入特征增強模塊和新型特征金字塔結構,從而增強淺層特征圖語義并改善模型對小目標的檢測性能。
1 基于密集連接與特征增強的檢測算法
1.1 YOLOv3 算法
YOLOv3 是REDMON 等在2018 年提出的一種單階段目標檢測算法,是目前應用最廣泛的目標檢測算法之一[8]。YOLOv3 的檢測框架如圖1 所示,其主要包括2 個部分:第一部分為基礎網絡,采用DarkNet53,網絡包含5 個殘差塊(ResBlock),每個殘差塊由多個殘差結構(Residual Structure)組成;第二部分為借鑒FPN(Feature Pyramid Networks)[12]設置的特征金字塔網絡結構,其通過卷積和上采樣產生3 個具有豐富語義信息的特征圖,大小分別為13×13、26×26、52×52。在訓練階段,網絡將圖像劃分為N×N個網格單元,每個網格單元輸出預測框的信息以及分類置信度從而完成檢測。
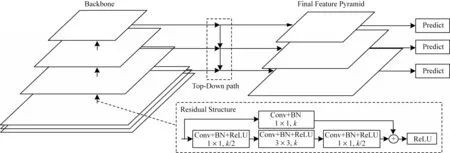
圖1 原始YOLOv3 框架Fig.1 Original YOLOv3 framework
現有一些研究人員將YOLOv3 應用于遙感圖像檢測領域。李昕等[13]將空間變換網絡(SpatialTransformer Networks,STN)融入YOLOv3 算法中,以提升遙感圖像中油罐的檢測精度。鄭海生等[14]通過替換主干結構和激活函數將YOLOv3 的參數量縮小為原始的1/15,實現了輕量級的遙感圖像檢測。沈豐毅[15]在原始YOLOv3 算法中引入壓縮激勵結構,通過權重差異提升模型對遙感圖像特征的敏感度。上述研究通過不同方法改進YOLOv3 模型,使其具有更好的表現,但是都未能很好地解決遙感圖像中特征提取困難以及目標尺度小的問題,這是由于YOLOv3 對小尺度目標的檢測主要依賴位于淺層的特征圖,淺層特征圖的分辨率較高,空間位置信息豐富,但由于其處于網絡的淺層位置,沒有經過足夠的處理,因此語義信息較少,特征表達能力不足。此外,YOLOv3 的主干網絡DarkNet53 在遙感圖像中無法取得較好的表現,特征提取能力不足,導致檢測效果較差。
1.2 改進的YOLOv3 算法
1.2.1 主干網絡改進
本文依據DenseNet121[16]提出一種新型的密集連接主干網絡,網絡由閥桿模塊(Stem Block)和4 個密集連接塊(Dense Block)組成。閥桿模塊借鑒Inception v4 和DSOD(Deeply Supervised Object Detectors)[17]的思想,結構如圖2 所示,該模塊可以有效提升特征表達能力,同時不會增加過多的計算成本,與DenseNet121 中的原始設計(首先是大小為7、步長為2 的卷積層,然后是大小為3、步長為2 的最大池化層)相比,多分支的處理可以大幅減少輸入圖像在下采樣過程中的信息損失。
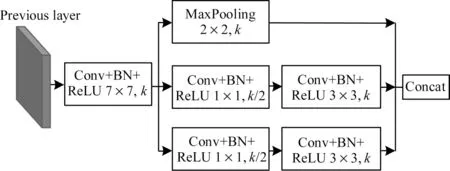
圖2 閥桿模塊結構Fig.2 Stem block structure
密集連接塊的基本組成為密集連接結構(Dense Structure),其最顯著的特點是跨通道的特征連接方式,通過每一層與前面所有層建立連接,使誤差信號快速傳播到較淺層,加強整個網絡對特征信息的傳播,在提升特征提取能力的同時大幅降低網絡參數量。密集連接塊的計算可表示為:其中:xl表示第l層的輸出;Hl(·)表示非線性操作組合,包括BN 層、ReLU 和卷積層;δ[·]表示Concatenation 特征融合操作。

網絡的輸入大小為448×448 像素,在訓練階段,輸入圖像首先經過閥桿模塊處理,通過大尺度卷積與多分支處理以緩解圖像下采樣時尺度變化所帶來的損失,之后經過密集連接塊得到4 個不同尺度的特征圖,其下采樣倍數分別為4、8、16、32。圖3所示為DarkNet、原始DenseNet 與本文改進主干網絡的結構對比,其中,原始DarkNet53 輸入大小為416×416 像素,使用下采樣倍數為8、16、32 的特征圖預測,原始DenseNet121 作為主干網絡,輸入大小為224×224 像素,使用下采樣倍數為8、16、32 的特征圖預測,改進的密集連接網絡輸入大小為448×448 像素,使用下采樣倍數為4、8、16、32 的特征圖預測。從圖3 可以看出,相較原始的DenseNet121,本文改進的主干網絡的輸入分辨率與預測特征圖分辨率更高,并通過閥桿模塊緩解了原始網絡輸入時信息損失過大的問題。同時,本文采用4 種預測尺度,最大尺度為112×112,最小尺度為14×14,在保證小目標檢測精度的同時提升了對大尺度目標的檢測效果。
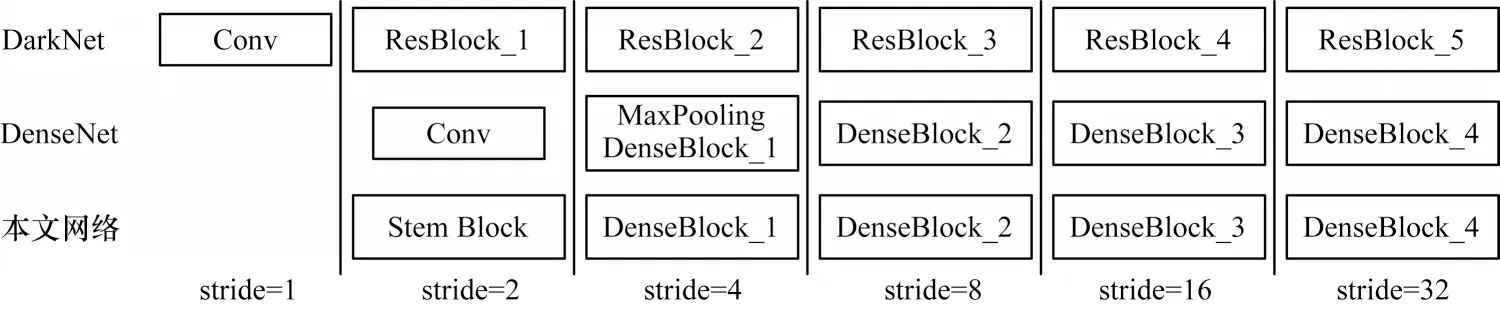
圖3 3 種網絡的結構對比Fig.3 Structure comparison of three networks
1.2.2 特征增強模塊
在本文主干網絡中,由于預測所用的特征圖分辨率較大,淺層特征圖沒有經過充分處理可能會導致特征中的語義信息不足,因此,本文提出一種特征增強模塊,針對淺層特征圖語義信息少、感受野不足的問題,使用多分支處理和空洞卷積來提高淺層特征圖的語義信息,從而改善網絡對小尺度目標的適應能力。本文模型結構如圖4 所示,提取出下采樣倍數分別為4、8、16、32 的特征圖用于預測,對淺層特征圖(下采樣倍數為4 和8)進行特征增強處理,對深層特征圖(下采樣倍數為16 和32)使用SPP(Spatial Pyramid Pooling)[18]進行處理,SPP 結構如圖5 所示。

圖4 改進的YOLOv3 框架Fig.4 Improved YOLOv3 framework

圖5 SPP 結構Fig.5 SPP structure
特征增強模塊借鑒RFB 感受野原理,通過增加網絡的寬度與感受野來提高模型的特征提取能力,增加特征圖的語義信息,其結構如圖6 所示,共有4 條支路,其中1 條支路為殘差網絡結構中的殘差支路(Shortcut Connection),只進行1×1 的卷積操作,另外3 條支路由1×1 與3×3 的卷積級聯而成,并在3×3的卷積后加入不同膨脹率的空洞卷積層。多個3×3的卷積級聯在擴大感受野的同時也減少了參數量,使網絡的訓練與推理速度更快,網絡中的每個卷積層后都加入了BN 層,旨在通過數據的歸一化處理來加快模型收斂。

圖6 特征增強模塊結構Fig.6 Structure of feature enhancement module
特征增強模塊的計算可表示為:

其中:Xj表示輸入特征圖;P表示由1×1 卷積層、BN 層和ReLU 層組成的非線性操作組合;Hi表示進行i次由3×3 卷積層、BN 層和ReLU 層組成的非線性操作組合;Qi表示i次卷積操作后的特征圖;Ri表示空洞卷積,i=1,2,3 時空洞卷積的膨脹率分別為1,3,5;Zj表示融合后的新特征圖。
經過特征增強模塊的處理,網絡對小目標的敏感度更高,在復雜背景下依然可以準確提取小目標的特征信息,從而提升網絡的檢測精度。
1.2.3 特征金字塔結構
本文使用重復的自淺而深(Double Bottom-up path)的特征金字塔結構,如圖4 所示,使用經特征增強模塊和SPP 處理的特征圖作為特征金字塔結構的輸入,輸入的特征圖被分為2 個分支:一支在進行下采樣與卷積操作后與下一層特征圖相累加;另一支同樣進行下采樣操作并與累加后的特征相結合,使網絡中的信息由淺層向深層傳輸。通常在網絡訓練過程中,目標的像素不斷減小,若小目標的信息在主干網絡的最后一層已經消失,則在上采樣操作后無法恢復小目標的信息,在淺層特征與深層特征相結合時便會出現混淆,降低了網絡的檢測精度。通過本文的特征金字塔結構處理,網絡不會因上采樣操作而丟失小目標信息,避免了網絡因小目標信息丟失所造成的精度損失。
2 實驗結果與分析
2.1 實驗平臺與數據集
本文實驗平臺設置:使用Ubuntu16.04 操作系統,NVIDIA Tesla T4(16 GB 顯存),Python 編程語言,深度學習框架為Tensorflow。
本文實驗所用數據來自RSOD 和NWPU NHR-10[19]數據集,針對原始圖像進行篩選,剔除質量較差的圖片,并核驗標注信息,對錯標、漏標的樣本進行重新標注,最終得到包括不同場景的圖片共計1 620 張,檢測目標包括飛機、船舶、儲油罐、棒球場、網球場、籃球場、田徑場、海港、橋梁和車輛,圖片分辨率為(600~1 000)×(600~1 000)像素。
圖7 所示為本文數據集中目標真實框的尺寸分布情況,目標真實框總共11 296 個,主要集中于小尺度范圍,絕大多數目標分布在100×100 像素點以內,其中,16×16 像素大小的目標占比為41.79%,低于32×32 像素的目標占比達到約92%。

圖7 目標尺度分布Fig.7 Target scale distribution
2.2 模型訓練及評價指標
數據增強采用隨機裁剪、隨機旋轉、縮放等操作,初始學習率設置為0.01,采用隨機梯度下降法對總損失函數進行優化訓練,訓練批次設置為4。
本文使用的評價指標為平均準確率(mAP)。通過衡量預測標簽框與真實標簽框的交并比(IOU)得到每個類別的精確度(Precision,P)和召回率(Recall,R),由精確度和召回率所繪制的曲線面積即為準確率均值(AP),多個類別的AP 平均值即為平均準確率,其計算可表示為:

2.3 對比實驗結果分析
利用所整理的數據集對本文算法性能進行驗證,將其與原始YOLOv3 算法、SSD 算法、EfficientDet 算法[20]、CenterNet 算法[21]、YOLOv4 算法[22]、Faster R-CNN 算法得到的結果進行客觀比較,結果如表1 所示,其中,mAPlarge、mAPmedium、mAPsmall分別代表大目標、中目標、小目標的平均準確率。從表1 可以看出,本文改進YOLOv3 算法的平均準確率高于其他算法,達到74.56%,相比原始YOLOv3 算法提高了9.45 個百分點,尤其在小尺度目標檢測上,比原始算法提高了11.03 個百分點,并且參數量也低于原始YOLOv3 算法。與YOLOv4 算法相比,本文算法的大目標檢測精度與其相差0.69 個百分點,但在中、小目標的檢測精度上均高于YOLOv4 算法,與雙階段目標檢測算法Faster R-CNN 相比,本文算法也取得了更優的檢測效果。
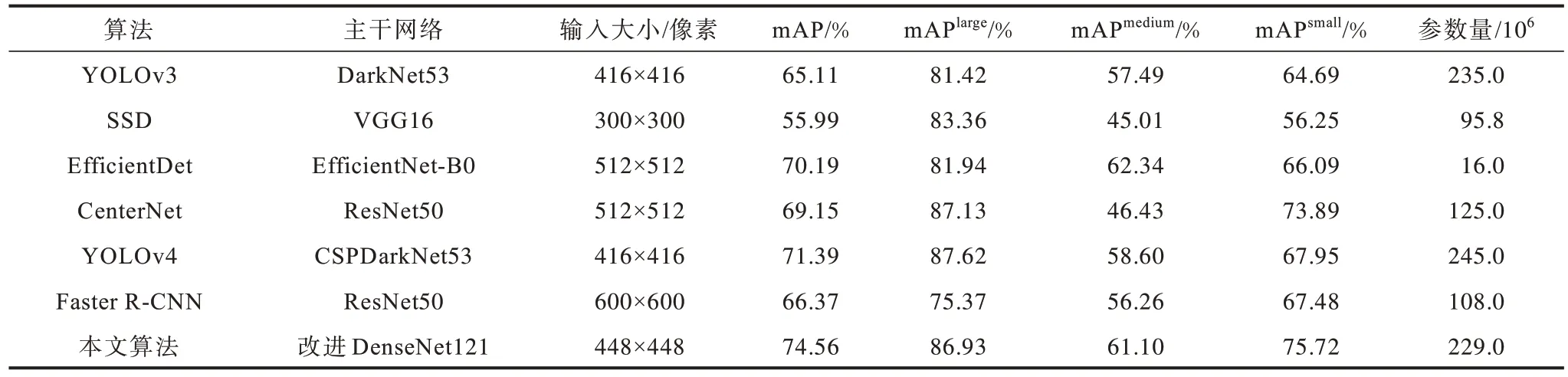
表1 對比實驗結果Table 1 Results of comparative experiment
圖8 所示為2 種算法的檢測效果對比,第1 行為原始YOLOv3 算法的檢測結果,第2 行為本文算法的檢測結果。第1 列、第2 列背景為機場與港口,是典型的遙感圖像場景,從中可以看出,原始YOLOv3 算法在這種具有復雜背景的圖片下存在漏檢現象,部分目標如飛機、油罐等無法檢出,而本文算法漏檢現象則大幅減少;第3 列、第4 列為道路背景圖片,待檢目標的尺寸較小,原始YOLOv3 算法無法有效檢出目標車輛,而本文算法在高分辨率下對小目標仍有較好的檢測效果;第5 列~第7 列為森林、海域背景圖片,可以明顯看出,當待檢目標距離較近時,原始YOLOv3 算法會出現漏檢現象,而本文算法的檢測效果得到有效提升。

圖8 2 種算法的檢測效果對比Fig.8 Comparison of detection effects of two algorithms
2.4 消融實驗結果分析
本節通過消融實驗以探究各部分改進對模型的性能影響。
第1 組對比實驗分析替換主干網絡對模型精度的影響,本次實驗設置3 組模型進行對比,分別為原始 YOLOv3 模型,對比模型 1(使用原始DenseNet121 的YOLOv3 模型)以及對比模型2(使用本文主干網絡的YOLOv3 模型),3 組實驗分別使用不同的主干網絡,其他參數相同,實驗結果如表2所示。從表2 可以看出,使用原始DenseNet121 作為主干網絡時mAP 的提升并不明顯,這是由于較低的分辨率輸入以及原始DenseNet121 在下采樣時損失過多特征信息所導致,而使用本文改進的主干網絡時,mAP 提高了6.76 個百分點,在大、中目標上的檢測精度均高于原始模型,且在小目標上的檢測精度提升最為顯著。由于遙感圖像中的目標尺度集中分布在小尺寸范圍內,因此本文所提主干網絡更適用于遙感圖像檢測。
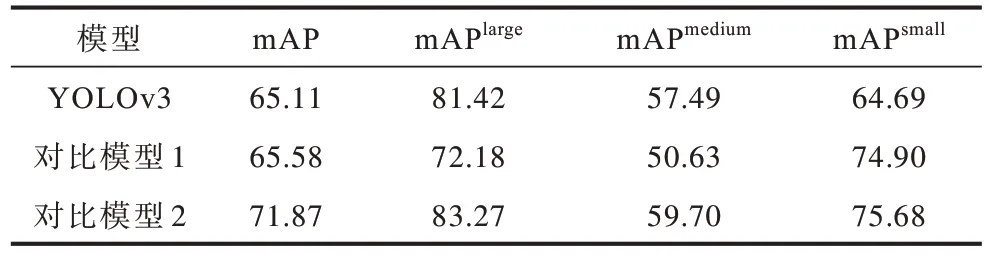
表2 主干網絡消融實驗結果Table 2 Experimental results of backbone network ablation %
第2 組對比實驗分析特征增強模塊與特征金字塔結構對模型的影響,設置4 組模型進行對比,實驗結果如表3 所示。從表3 可以看出,使用特征增強模塊的模型mAP 提升顯著,而單獨使用改進特征金字塔結構時則效果不明顯,這是由于原始YOLOv3 模型中特征未經強化處理,語義信息過少,使改進后的特征金字塔效果較差,而當2 項改進共同使用時,檢測精度達到最高。
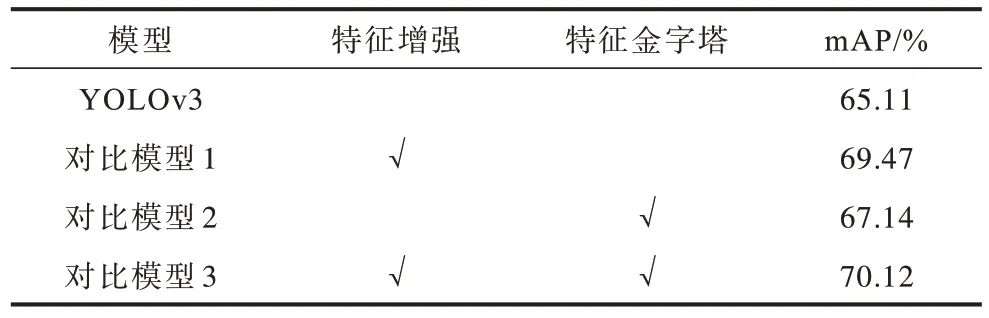
表3 特征增強模塊與特征金字塔消融實驗結果Table 3 Experimental results of feature enhancement module and feature pyramid ablation
3 結束語
本文針對遙感圖像背景干擾大、目標尺度小等問題,提出一種基于改進YOLOv3 的遙感圖像目標檢測算法。將密集連接網絡與YOLOv3 相結合,通過由多分支結構與空洞卷積所組成的特征增強模塊來加強特征的語義信息,使用新型的特征金字塔結構減少對小目標的檢測精度損失。在遙感圖像數據集上的實驗結果驗證了該算法在目標檢測任務中的有效性,尤其在小目標檢測上優勢明顯。后續將結合本文算法進一步探究密集連接網絡與感受野原理對遙感圖像檢測的影響,以實現更高的檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
