基于損失函數的單元測試用例自動化生成算法研究與實現
2022-06-17 08:39:02傅瑞華王俊峰
四川大學學報(自然科學版) 2022年3期
傅瑞華, 李 凡, 王俊峰
(四川大學計算機學院, 成都 610065)
1 引 言
軟件測試是軟件質量保證的核心環節, 是軟件產品生命周期內質量保證不可缺少的有效措施.證據表明,目前完整的軟件測試過程最多可占項目開發總成本的40%[1],而早期及時通過軟件測試可大大降低修復軟件生命周期中的缺陷的成本[2].但目前,仍有相當多的軟件是依靠手工編寫測試用例來進行軟件測試.這種人工方式需保證測試人員有較多經驗和較高技術水平,且在有高質量測試人員情況下依舊會花費較高的成本(時間、人力),也并不能完全保證測試用例的高覆蓋率和軟件質量.因此研究測試用例自動化生成技術成為了軟件開發行業發展的必然趨勢.
測試用例的自動構建可視為一個優化問題,即如何在生成最小數量的測試用例集合的標準下,盡可能覆蓋更多的目標,并保證測試數據分布的平衡性,使得測試用例高有效.市面上目前已經有較多的成熟工具如Logiscope、Load Runner、Web Stress[3]等,可用于軟件測試中測試用例的自動生成,但大多數仍然無法解決如何自動生成高質量測試、如何使得測試用例全面覆蓋等自動化測試痛點問題,所以要實現真正意義上的自動生成測試用例,仍需投入大量研究及技術支持.
軟件測試方法可大類分為黑盒測試及白盒測試,前者注重在不清楚內部結構和細節的情況下驗證功能可用性;后者基于程序源碼內部邏輯知識,并通過特定的測試覆蓋率標準如語句覆蓋率、分支覆蓋率等,來檢測編碼過程中存在的潛在錯誤[4].
根據不同的軟件測試方法,自動生成測試用例的常見算法可分為隨機測試方法、符號執行方法、UML模型檢測法和基于元啟發式算法的測試用例自動生成方法等[5].李志博等[6]提出的優化的固定候選集算法(Fixed Sized Candidate Set,FSCS)在傳統的隨機測試算法[7]中添加了自適應方法,通過生成多個候選測試用例數據,計算每個候選數據與已執行用例數據集中最近測試用例數據之間的距離,并選擇出距離最大的候選數據作為下一個執行數據,從而使得測試用例數據盡可能均勻地在輸入空間內分布.Xiao等[8]提出一種以程序階段特征為指導的新型符號技術用于測試用例的自動生成,把程序基本塊執行次序劃分為不同的執行階段,但此種符號執行法易集中在局部代碼塊,導致其他部分的代碼無法被有效測試.Swain等[9]提出將UML行為模型轉換為圖形,通過測試場景和測試序列來自動生成測試用例的方法.Liu等[10]提出一種通過掃描帶有嵌套循環過程的源代碼來構造程序層模型,并將圖層模型轉換為擴展的正則表達式,進而獲得測試路徑的方法.但當程序復雜度上升(特指循環嵌套)時,該方法會導致測試序列爆炸問題.
元啟發式測試用例自動生成算法是根據測試充分性標準自動生成最優解測試用例集,包括粒子群優化算法[11]、遺傳算法、模擬退火算法[12]、蟻群算法等[13],其中遺傳算法應用最為廣泛.Bao等[14]提出的改進遺傳方法(Improved Adaptive Genetic Algorithm,IAGA)旨在每次迭代中根據個體相似度和適應度值的差異,動態調整一些參數來提高早熟收斂方面的搜索性能.相比于其他算法,元啟發式算法可適用于更大規模及更高復雜度的空間,并能更敏捷地找到最優解或近似最優解[15].但由于算法受限于適應度函數且依賴于初始種群,容易產生以下問題:算法時間復雜度過高、種群過早收斂、非全局最優解以及局部最優導致數據冗余.
為進一步解決以上所述的元啟發式算法缺陷,并使得生成的測試用例在數量較少的情況下能夠覆蓋盡可能多的路徑,本文提出一種基于損失函數的白盒測試用例生成方法:在GA算法過程中實時判斷種群數據的分布并進行動態調整,并根據分布情況自適應調整交叉變異算子,同時通過改進后的適應度及精英策略評估函數來對種群進行選擇,以保證每次迭代的初始輸入種群的有效性,最大程度構建出高覆蓋低數量高有效的最優解測試數據集.
2 相關概念
2.1 損失函數
在機器學習模型中,單個樣本的真實值與預測值的差值稱作損失,損失值越小表示模型越貼合真實場景.其中用于計算損失值的函數被稱作損失函數,其本質是一個用于找到場景最優解的目的函數,可被用于度量一個模型的好壞,所以損失函數是機器學習中檢驗模型結構風險的重要組成部分.
構建的模型能夠通過損失函數計算出的損失值,反向去傳播更新各參數,使得模型生成的預測值能夠更好地擬合真實值,從而判斷模型或者決策的好壞.當損失值小于既定的閾值后,則可停止學習得到最優模型.假設存在離散點(xi,yi)的集合,針對單一參數預測函數f(xi)=α1+α2xi,有平方誤差代價函數:
(1)
其中,N為總樣本數量;i表示第i個樣本.求解最優值即為求解參數α1,α2,使得函數J值極小從而獲取最佳預測函數與最小誤差.
2.2 GA算法
遺傳算法已在多學科中被用作解決全局搜索優化的方案,可形式化將該算法內容用一個多元組進行表示.
G=(C,F,O(α,β,γ),R(c,m,n),E)
(2)

表1 多元組符號含義
遺傳算法在每一次迭代中,通過適應度函數選擇更優的個體至下一代,再對種群進行交叉或變異操作,從而產生新的種群.
使用遺傳算法實現測試用例的自動生成可描述為:在每輪迭代過程,遺傳算法使用當前種群(即測試用例)來驅動被測程序的執行,并以最大化程序路徑覆蓋率作為適應性函數進行計算,通過交叉變異等操作優化有效性較低的測試用例數據,進而產生下一代種群至循環結束.
2.3 動態符號化執行
動態符號執行在傳統符號執行方法之上,讓具體值和符號執行同時進行[16].動態符號執行技術在生成測試用例時使用程序變量的具體值來替換復雜表達式或數據結構中的符號變量,通過簡化路徑條件自動生成更有效的測試用例,且具有較小的時間花銷[17].程序生成隨機數據進行第一次執行,并從當前執行路徑上的分支語句的謂詞中搜集所有符號約束,謂詞的定義如后式:P(x1,x2,…,xi),其中xi為獨立的個體(表示不同事物或某種抽象概念);P表示一種行為約束,刻畫出個體間的關系及性質.
之后對約束進行修改生成新路徑的約束序列,并利用約束求解器求解出另一個可行的新輸入.通過輸入迭代產生變種輸入,從而觸發程序新狀態,發現所有可行路徑下的測試用例數據.
3 算法概述
本文提出的單元測試用例自動化生成算法整體上需達成的目標為:保證測試用例數據高覆蓋高有效,平均覆蓋率盡可能達到α(α>=95%).在測試停止標準中基于測試用例的原則下,非功能性測試用例覆蓋率達到或超過95%允許正常結束測試[18].

圖1 種群個體惡性傾斜示意圖
保證分布平衡,分散重復路徑分支下的冗余個體,使得迭代完成后各路徑之間的種群數量差值β<=5.防止收斂速度過快導致的早熟以及單路徑數據爆炸(如圖1)等問題缺陷.圖1中Bi為分支Li為語句,虛線框中的部分代表聚集了較多的種群個體,因此在迭代中測試重點會偏向根節點B1的右子樹路徑上,從而導致失衡,造成最終種群迭代的惡性結果效應.
3.1 測試用例自動生成模型框架
本文提出的單元測試用例自動化生成算法(LFGA)模型如圖2所示.整體方法中含有程序分析、GA優化、最優種群集合評估等主要模塊,對初始測試程序進行插樁測試,并于中間過程引入損失函數驗證,通過及時判斷迭代各種群個體是否符合分支預期,動態根據路徑前序分支覆蓋情況調整種群在程序路徑樹的分布,執行時無需過度依賴于初始種群,最后以適當收斂速度及迭代次數來確定最優數據集,增強此種問題場景下通用模型的整體魯棒性及種群個體耦合依賴性,并以此可推斷至較為復雜軟件的用例生成.
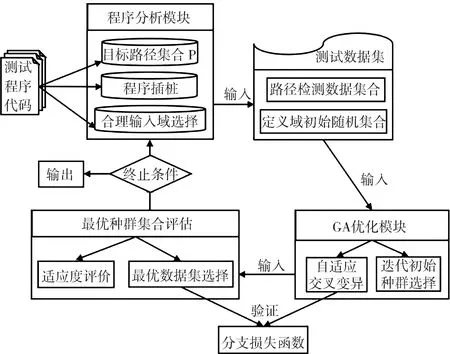
圖2 基于損失函數的測試用例生成模型Fig.2 Test case generation model based on loss function
3.2 程序分析
模型中程序分析采用靜態預分析方式,抽取程序片段中的關鍵信息包括分支節點、參數集合、輸入域范圍等,以Java語言為例,借助ASTParser類遍歷形成DOT類型文件數據,再利用正則從節點語句中獲取具體的輸入域范圍,具體DOT數據類型如表2所示.

表2 DOT文件數據結構字段
生成的dot文件同時包含了各個id之間的指向信息,能夠表示各分支之間的層級關系,訪問者根據dot文件數據中的節點語句信息可得到分支集合T={t1,t2,...,tn}.給定路徑集合P={p1,p2,...,pn},其中pi∈T,且pi代表的子集沒有重復,所有子集的并集涵蓋程序整個分支集合;若存在pm∈pn則僅保留最長路徑子集.
將所有路徑信息進行優化后,執行統一插樁,把測試數據集映射至路徑檢測及定義域初值數據集.路徑檢測數據集合在分支損失函數驗證階段將被用于控制種群在各路徑上的分布,定義域初始隨機集合將用于種群(測試用例)初始值的生成.
3.3 初值隨機生成優化
關于種群迭代演化的測試,前期輸入域有效性間接性確定了后期迭代時間長短及收斂速度的快慢.之前經過對代碼片段的靜態分析并確定了類的分支行為,在DOT數據集合上進行二次正則精簡來獲取每一個分支中可能存在的參考值以及其對應范圍符號,包括:>、<、=、&、!等,然后以預設數量的種群個體數在變量參考范圍內隨機生成初始種群,組成由范圍內隨機測試用例組成的測試套件,再用于之后迭代.
由于并非所有程度控制條件中含有明確變量信息(如:無數值僅有等式約束關系),因此考慮符號化執行思想,把輸入變為符號值來得到讓特定代碼片段區域執行的輸入組合值或關系,以圖3為例,獲取路徑分支truefalse序列的約束關系,,根據執行樹左右子樹進行初值的等式約束關系集取值,從而適應于無明確參考值下的種群初值生成.改分支集合序列T中每項為ti-0和ti-1,則ti-0代表true,ti-1代表false,作為路徑集合的存儲信息.
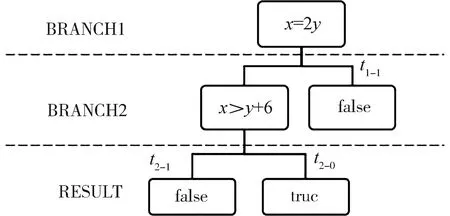
圖3 執行樹信息存儲示例Fig.3 Execution tree information store
獲取到各路徑下的參考值范圍或變量狀態關系后,將上述變量信息存儲至對應分支的數據結構中,根據取值范圍對各路徑設置相應概率閾值,便于在分支損失函數中進行分支碰撞檢測優化.
3.4 分支損失函數驗證
在最優種群集合評估模塊中,為確保數據集至少覆蓋一次決策點的每個條件的所有可能結果(即取真、取假分支),本文提出一種通過分支損失函數實時調整后序種群分布的驗證算法,其中分支損失函數在流程中作為用于找到最優解集合的目的函數,控制選擇及交叉變異方向,從而增強測試例數據之間的公平性、友好性,流程如圖4所示.
在進行整體種群評估后開啟分支損失函數的驗證,貫穿于每代個體的選擇丟棄和后續變異的突變方向等,盡可能地去掉某分支條件下的冗余測試數據,主要損失函數的實現由以下兩部分構成.
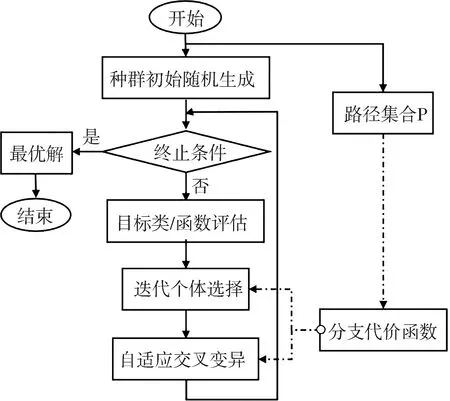
圖4 分支損失函數驗證流程Fig.4 Branch loss function verification process
第一項:用于迭代選擇過程中判斷個體累計是否符合分支覆蓋預期.由于前序步驟中進行了正則切割及插樁等過程,程序能夠獲取存儲的分支數據結構信息,包括分支id、分支所含變量范圍及關系、分支概率閾值等.當進入某分支的個體數占比超過設定的該分支概率閾值則選擇舍棄,重新隨機選取其他分支進行參考值范圍內的數據隨機生成以補位,再結合精英個體選擇策略下的剩余種群形成新一代種群數據的有效輸入;第二項:提供個體交叉變異的趨勢判斷.由于適應度函數的設計易使測試數據后續匯集在已生成數據的路徑上(即概率閾值更大),考慮在經過選擇階段后,通過累計各路徑個體,選取數目相對較多和較少的分支種群集合進行交叉變異.算法中的變量含義對應關系如表3所示.

表3 算法變量含義對照表
整體算法思路過程偽代碼如算法1所示.
算法1分支損失函數驗證
1) procedure Branch Cost(,)
2) Pretreatment:T&P←dot類型數據
3) Initializa:PopList←Referencevaluerange
4) Evaluate: the primary population
5) whilei< maxGeneration do
6) Select:NewPopList←f(xi)評估
7) while in Function(CostBranch) life
circle do
8)PXover& PMutation: 自適應改變
9) if reachedPopListend
10) end while
11) 使用JUnit計算數據覆蓋率
12) if test data optimal←cov(%) max
13) end while
14) 輸出最優解集合
15) end procedure
3.5 自適應算子設計
采取常規遺傳算法中的策略,交叉函數對選定的兩個父級中的基因進行交換,變異函數實現采用的單點交叉.通常在覆蓋率高的測試用例數據上修改某一個參數值或用高覆蓋率測試用例中的某幾位參考數據替換前一階段新生成的測試用數據,往往能夠在適當速度范圍內加快收斂改善結果,有效加強進化性能[19].
當連續碰撞某分支次數累計達到設定閾值,認為在此分支參考值范圍內已經設定了足夠的測試用例,為避免出現過度收斂導致分支不平衡現象,動態地調整交叉變異算子.根據測試數據累計分支碰撞閾值,動態改變交叉變異算子的取值.式(3)和式(4)分別表示變異和交叉算子的調整方式.
(3)
(4)
式中,fmax代表相對適應度最大的個體;fi代表待變異個體(適應度較小的測試用例)的相對適應度;favg代表種群個體平均相對適應度.在遺傳算法中Pc,Pm取值范圍一般為[0.25,0.99)及[0.001,0.1)[20],此處公式中k1及k2、k3及k4,通過隨機函數分別取[0.25,0.99)及[0.001,0.1)區間內的值.
相對適應度越小的個體表示進入其對應分支的概率越大越容易進入,相對較大的變異算子在此種情況下更能促進進入冗余分支測試數據的變異.
對于分支概率最大的情況下,fi必定大于favg,使得整體Pm增加,從而對應個體變異的概率增加;對于進入分支難的個體,應使Pm變小,從而使這個個體更不容易變異順利進入下一代.
3.6 GA優化模塊
(1) 適應度函數設計.根據個體分支覆蓋情況和所有種群分支覆蓋情況進行個體的適應度計算,每次進行更改時需重新編譯代碼.越易覆蓋的路徑會有越多的測試數據集,適應度函數見式(5).
(5)
其中,N代表種群待選擇個體總數;ui為路徑集合個體pi所含有的測試數據數目;umax為測試用例在pi路徑下達到理想平衡狀態下的個數,越易被覆蓋的路徑會有更多的測試數據集,對應個體適應度值越低,在擇優選擇中表現為更劣勢個體.
(2) 精英策略設計.結合分支驗證機制之前,本文先采用輪盤賭個體選擇策略,將中間步驟得到的最優解個體進行保留.結合分支損失函數驗證后能在確保當代種群中最佳成員組作為二代種群的初始有效輸入的條件下動態調整其余測試數據的平衡性,從而防止由遺傳算法過度收斂導致的數據極端不平衡.輪盤賭策略對優劣個體的相對適應度計算式如式(6).
rf(i)=f(i)/∑f(i),i≤N
(6)
式中, ∑f(i)表示當前適應度的總和.個體相對適應度rf(i)越高表示個體更優良,將保留至分支損失函數執行階段.
4 實驗與結果
本文實驗選擇了5種不同復雜度的被測程序來進行所提出方法的評估,并與其他方法和工具進行橫向對比實驗,算法實現采用Intellij IDEA軟件環境,開源測試框架JUnit輔助進行測試結果優劣分析.實驗評估標準以回答以下兩個問題:Q1: 本文提出方法是否能夠優化數據收斂結果,并提高總體覆蓋率?Q2: 與其他方法相比,本文提出方法是否能夠在相同規模的測試數據集合下,實現更高的覆蓋率結果?
4.1 實驗過程
實驗測試采用軟件測試中的經典模型Triangle, Next Date, GCD, premium, decision[21]等作為被測程序來驗證所提出方法的可行性(如表4).
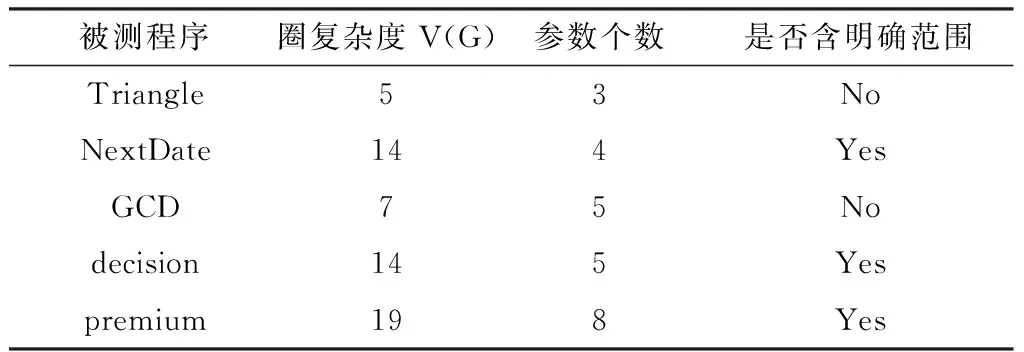
表4 測試模型信息
本文提出的方法記為LFGA,隨機算法記為RA,蟻群算法記為ACA,標準遺傳算法記為SGA,開源工具Evosuite中的改進遺傳算法記為IGA.Evosuite[22]基于傳統GA算法,然后迭代地使用變異和交叉等遺傳算子來進化.
通過使用不同的算法對上述5種待測程序模型進行單元測試用例的自動生成,并通過Junit進行測試用例數據的覆蓋率計算輸出及后續結果對比.實驗種群規模保持為50,最大迭代次數設上限500,自適應遺傳操作中設置單點交叉概率上限0.9;變異概率上限0.1.實驗中使用的評估指標是在預先確定的獨立運行次數上實現的平均覆蓋率.通常迭代停止機制的判斷方式為兩種:人為設定及數據收斂趨勢穩定或陷入局部最優解.
4.2 實驗結果
通過使用不同算法對同種程序測試模型進行測試,生成數據的路徑覆蓋率結果數據如圖5所示,其中cov表示多次實驗累計下的覆蓋率結果均值.
表5為在每種模型經過40輪次實驗后,程序輸出分布結果趨勢穩定情況下的平均迭代次數(去除最優及最壞結果以盡量降低偶然事件誤差).注:程序輸出的最優結果不代表數據一定可用,僅可通過此數據判斷種群收斂情況.

表5 程序穩定解下的遺傳代數
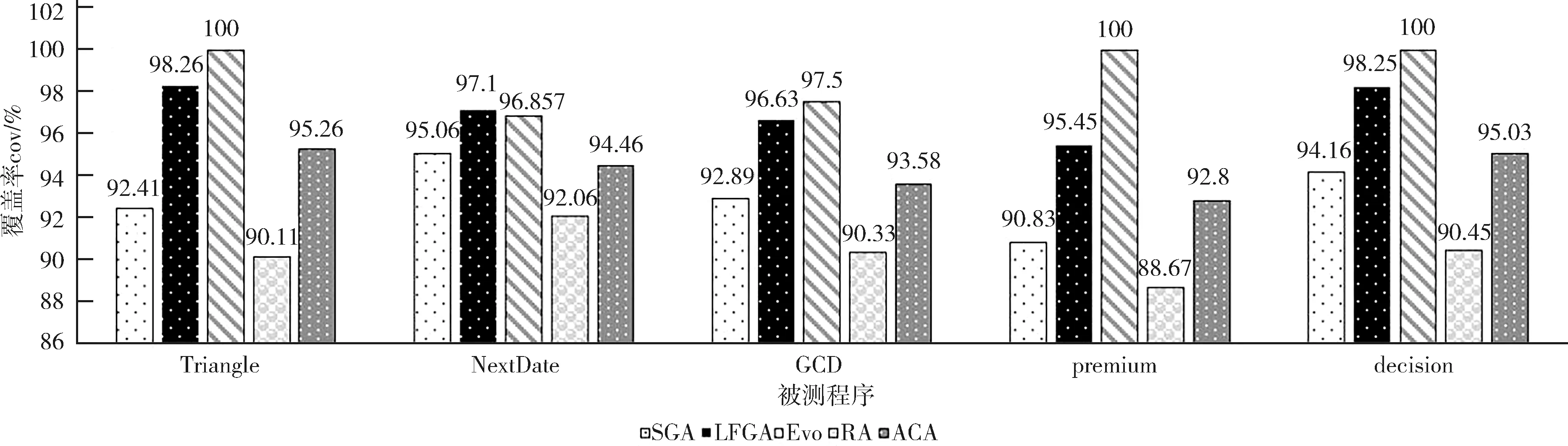
圖5 不同方法下的覆蓋率結果Fig.5 Coverage results under different methods
為了驗證被測程序的測試數據生成在改進方法下的有效性,繪制了在本文所提出的思路下,種群數據的收斂趨勢(以Triangle為例),如圖6所示,并以標準遺傳算法SGA下的過程中種群數據分布趨勢作為對照.圖中橫坐標表示種群的迭代次數,縱坐標表示為種群個數,其中每一條折線表示:一條路徑分支上的種群個數在迭代過程中的變化.
以含有4條分支路徑的Triangle程序為例,兩幅圖中從上到下的折線依次代表4條路徑上種群數量的變化.經過20余次迭代后,在圖7的SGA算法中,每條路徑上的種群數量變化波動較大且無明顯收斂趨勢;而在圖6的LFGA算法中,每條路徑上的種群數量變化趨于平緩,且各路徑之間的分布的種群數量差值也呈現越來越小的趨勢.
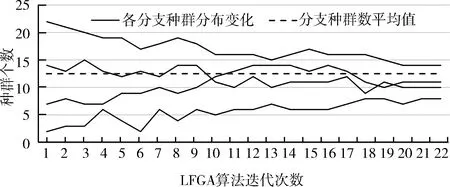
圖6 LFGA種群收斂趨勢(以Triangle為例)Fig.6 Convergence trend of LFGA population (take Triangle as an example)

圖7 SGA種群分布圖(以Triangle為例)Fig.7 SGA population distribution trend (take Triangle as an example)
4.3 數據分析
根據實驗結果,結合第4節開篇,Q1和Q2數據分析情況如下.Q1:從表5展現的數據中可看出傳統方式生成數據雖然經過較少的迭代總數,但測試數據可用性遠遠低于本文提出的方法,說明傳統算法使得種群數據過快收斂或陷入局部最優中,從而通過本文中的分支損失函數驗證方式,能夠較好地讓種群數據分布得到有效的篩選,并通過圖5生成測試數據的路徑分布圖可看出,整體數據以適當速度進行較穩定的收斂,最終達成最優解較均勻覆蓋目標路徑目標.Q2: 橫向對比方式下如表4數據,本文方法生成數據對于幾個測試程序來講生成了較好的覆蓋率且高于SGA算法,數據可用性更高,同時Evosuite開源工具數據覆蓋率比較穩定可作為本文方法參考目標覆蓋率,LFGA算法中的覆蓋率與Evosuite數據覆蓋率也更為接近,說明文本所提出損失函數方法適用于測試數據的自動生成.
5 結 論
本文提出了一種基于損失函數的方法,目的是通過判斷算法過程中平衡性變化,改進種群適應度及精英策略評估方式,并利用分支信息優化自適應交叉變異算子,自動完成數據收斂過程,生成最小高覆蓋有效測試用例集.經過大量實驗及數據表明,本文方法能夠有效收斂種群,增強算法全局尋優能力,并較好解決初值依賴、收斂早熟、局部尋優能力滯后等傳統缺陷,盡可能地提升搜索效率及數據有效率,將測試覆蓋度達到一個滿意的值,對快速生成滿足測試要求的數據有著重要意義.由于本文所提算法能夠通過判斷用例數據分布情況來自動完成數據收斂的過程,后續引入神經網絡進行訓練是值得嘗試和研究的.
