基于注意力機制和殘差卷積網絡的語音增強?
2022-06-21 07:40:06李文志屈曉旭
艦船電子工程 2022年5期
李文志 屈曉旭
(海軍工程大學電子工程學院 武漢 430000)
1 引言
隨著通信技術的發展,語音增強技術是信號處理領域的一個重要的研究熱點,它可以從被噪聲污染的語音信號中提取有用的語音信號,改善語音質量和可懂度,廣泛應用于各種語音信號處理中[1]。
傳統的語音增強算法包括譜減法[2]、維納濾波法[3]、最小均方誤差法[4]和基于小波分解[5~6]的語音增強算法等。傳統的這些增強算法一般需要各種假設才能有較好的效果,但是對于非平穩信號,增強效果會明顯下降。近年來,深度學習技術不斷發展,基于深度學習的有監督的語音增強算法取得了重大進展,主要有基于深度神經網絡(Deep Neural Network,DNN)[7~9]、卷積神經(Convolutional Neural Network,CNN)[10~14]和循環神經網絡(Recurrent Neural Network,RNN)[15~16]。基于有監督的深度學習方法不需要假設,只需要從大量的含噪語音信號中學習語音與噪聲之間的非線性關系,得到一個訓練模型,從而通過這個模型增強語音信號,具有較好的去噪效果。
本文提出的基于注意力機制和殘差卷積網絡的語音增強算法,該方法將殘差學習和注意力機制融合到卷積神經網絡中,通過設計網絡結構,將含噪語音的語譜圖作為輸入特征,輸出為增強后語音的語譜圖,最后重構語音信號。
2 基本原理
2.1 卷積神經網絡
卷積神經網絡一般由卷積層、池化層,上采樣層和全連接層組成,通過這些網絡層就可以構建一個卷積神經網絡。卷積層是通過卷積核和前一網絡層輸出進行卷積運算來提取特征的,然后偏置項相加,得出當前層的特征。卷積核具有權值共享特性,相對于DNN和RNN可以大大減少參數。卷積層的更新公式如下[17]:

式(1)中:xmj代表當前層m的第j個特征圖輸入;f表示激活函數;M表示當前層的特征圖集合;k表示卷積核的權值;b表示偏置項。
2.2 殘差學習
殘差學習(Residual Learning)是一種優化網絡的方法,解決了由于隨著深層網絡結構的愈加復雜,梯度下降算法得到局部最優解的可能性就會越大,出現“退化”的問題[18]。
殘差學習網絡框架如圖1所示,從圖中可以看到,框架有兩部分組成,一部分是由兩層或多層神經網絡層組成的殘差映射,另一部分是由跳連層(Shortcut Connections)組成。
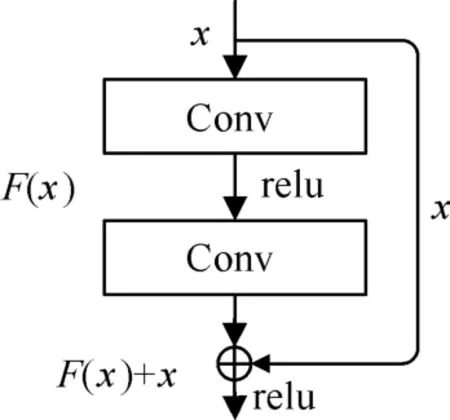
圖1 殘差學習網絡結構
假設輸入x經過兩層卷積層得到的殘差映射為F(x),目標輸出的映射為H(x),則殘差映射表示為

當F(x)為0時則:

由此可以看出,殘差學習只需要擬合殘差映射F(x),不需要對H(x)進行擬合,這樣網絡結構更容易擬合。
2.3 注意力機制
卷積神經網絡建立在卷積運算的基礎上,通過在局部信息和信道信息來提取信息特征。為讓網絡模型能學習到全局信息,在網絡中加入了注意力機制。
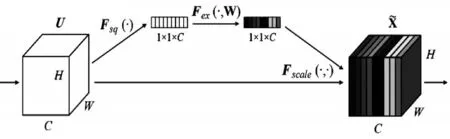
圖2 SE-Net結構
圖2表示的是主力注意力機制SE-Net(Squeeze-and-Excitation Networks),SE-Net是一個輕量級的模塊[19],首先是一個擠壓操作,把輸入的每個特征圖根據全局信息擠壓成一個固定值zc:

式中uc表示輸入的特征圖集合,H和W表示特征圖的高和款,c表示第幾個通道。
激勵部分是通過兩層卷積層融合各通道的特征信息,得到各個通道的權重s:
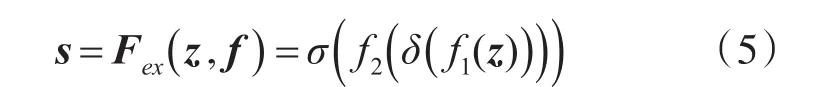
式中f1和f2表示兩層卷積造作,δ表示是relu激活函數,σ表示sigmoid激活函數
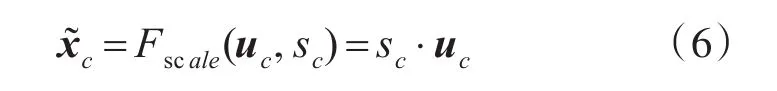
3 基于注意力機制和殘差卷積網絡的語音增強
3.1 模型結構
本文提出的基于注意力機制和殘差卷積網絡的語音增強模型結構由卷積網絡、殘差結構和注意力機制組成。殘差結構可以很好地防止“退化”現象,還可以防止梯度消失和梯度爆炸,從而提升網絡模型的精度。注意力機制可以有效地從復雜的特征圖集合中提取更重要的特征,抑制不重要的特征,使得訓練更有針對性。
基于注意力機制和殘差卷積網絡的語音增強模型結構如圖3所示,該網絡的輸入為129×16的語譜圖,然后經過一層卷積網絡得到特征圖集合,經過兩層殘差學習網絡,其結構如圖1所示,中間一層設置為注意力層,然后經過兩層殘差學習結構,最后兩層卷積層把特征圖映射到129×16的目標語譜圖。其中注意力機制模塊的組成如圖3右圖所示,通過一個全局池化層將特征圖集合壓縮到一個一維向量,然后通過兩層卷積層作為激勵部分學習各個通道特征圖的重要程度,最后對各通道的特征進行加權。圖中卷積層括號內表示的是卷積核和卷積核個數。
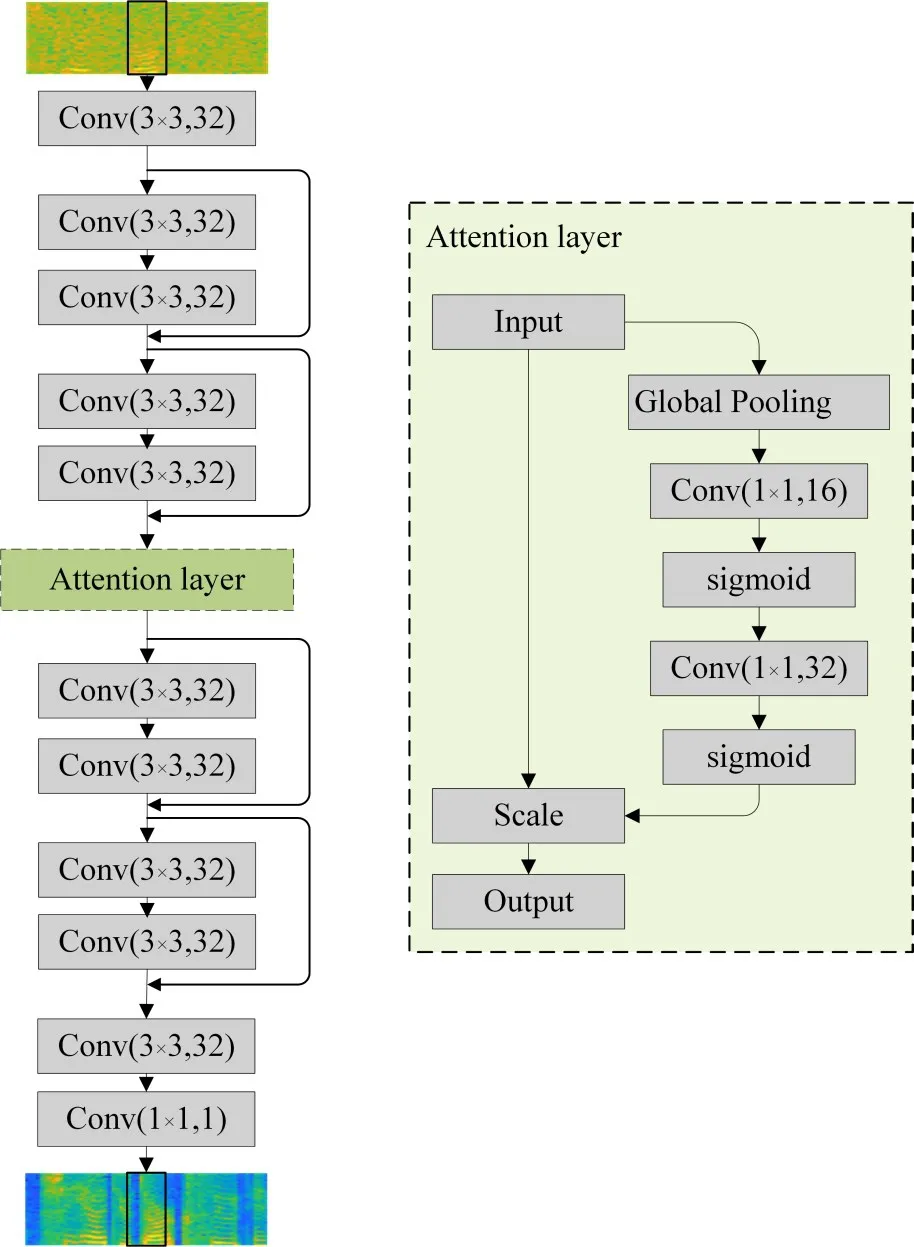
圖3 結構設計
3.2 算法流程
基于注意力機制和殘差卷積網絡的語音增強算法流程分為兩個階段:訓練階段和增強階段。
首先假設帶噪語音信號為
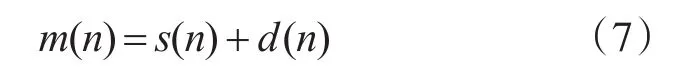
式(7)中s(n)表示原始語音信號,d(n)表示噪聲,m(n)表示含噪語音信號。
在訓練階段然后將含噪語音信號和純凈語音信號進行分幀,然后對每幀語音做STFT運算,通過取對數得到語譜圖。最后通過神經網絡訓練得到模型。
在增強階段,含噪語音信號通過分幀和STFT變換,提取相位信息,然后再提取語譜圖,輸入模型后得到增強后的語譜圖,最后通過語譜圖和相位信息重構信號,得到增強后的語音信號。過程如圖4所示。
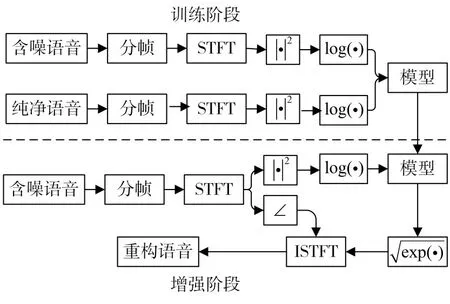
圖4 算法流程
4 仿真與結果分析
本次仿真實驗是在Python Tensorflow 2.3深度學習框架下進行,CPU為Intel Core i7-10750H,GPU為NVIDIA GTX 1065 Ti。網絡訓練時學習率設置為0.001,損失函數選擇均方誤差(Mean Squared Error,MSE),選用自適應矩估計(Adaptive Moment Estimation,Adam)優化器,迭代次數為50次。
4.1 數據處理
本小節采用TIMIT語音庫的訓練語音信號和測試語音信號,采用8000Hz采樣率進行上采樣,對于訓練的語音,是把語音庫中測試集中的3696個句子做分幀處理,幀的長度設置為1000,即每幀語音時長為125ms,從中隨機的選取100000幀。噪聲選用 NOISEX-92中的 buccaneer1、factory1、hfchan?nel、pink和white五種噪聲,每幀純凈語音信號添加噪聲的強度在-5dB~15dB之間隨機取值。然后對含有噪聲的語音和純凈語音做STFT變換,提取語譜圖特征。
4.2 評價指標
本文主要使用SNR、語音質量感知評估(Per?ceptual Evaluation of Speech Quality,PESQ)和對數譜距離(Log Spectral Distance,LSD)對仿真結果進行客觀的評估。PESQ是國際電信聯盟推出的P.862標準,用來評估語音質量的客觀評價,評價得分取值范圍為-0.5~4.5,數值越大表示語音質量越好。
SNR和LSD[13]可以分別在時域和頻域上評估語音的失真程度。其公式分別為
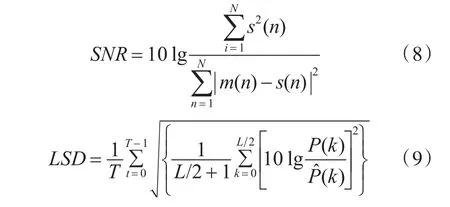
4.3 結果分析
為了驗證本文提出的基于注意力機制和殘差卷積方法(記為ResAtt)的性能,分別與文獻[12]中的基于深度卷積網絡方法(記為DCNN)和文獻[14]中的冗余卷積編碼器譯碼器方法(記為R-CED)進行對比。DCNN中神經網絡包含3個卷積層和3個全連接層;R-CED方法神經網絡由15層做成。
表1、表2、表3和表4分別表示在測試集中添加-5dB、0dB、5dB和10dB與訓練噪聲匹配的white噪聲之后,本文算法與兩外兩種方法的對比。表中黑體數字表示在該項指標中最好的得分。
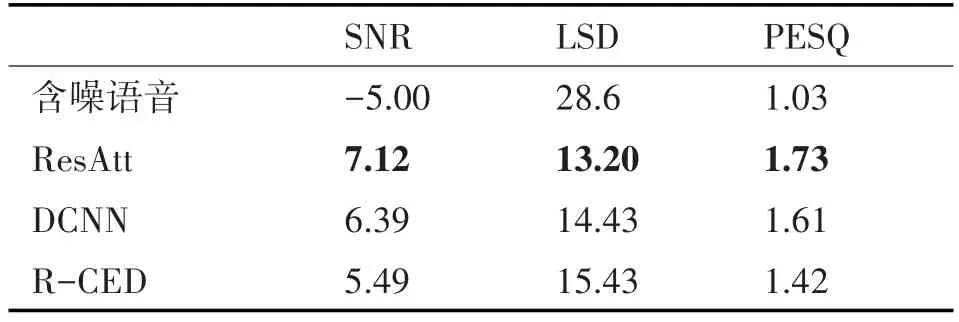
表1 匹配white噪聲下的性能(-5dB)
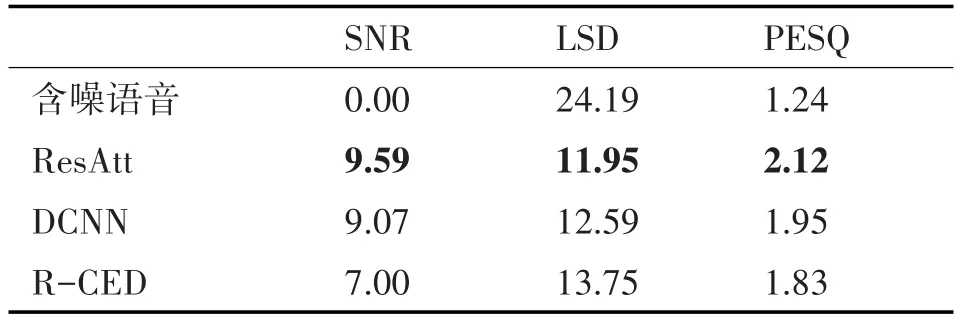
表2 匹配white噪聲下的性能(0dB)
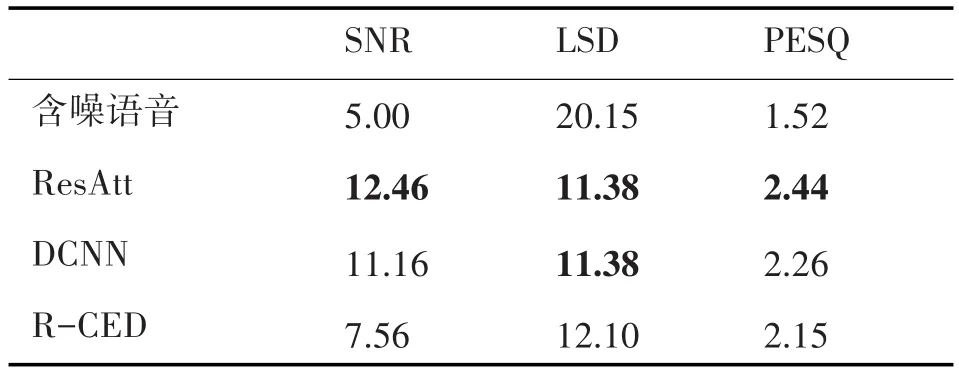
表3 匹配white噪聲下的性能(5dB)
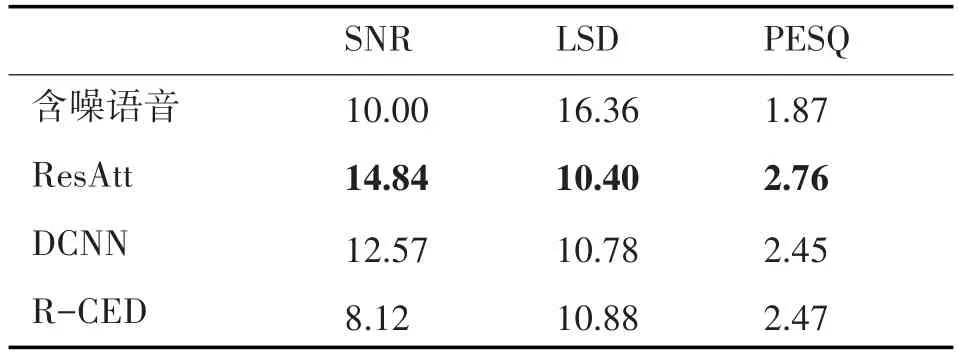
表4 匹配white噪聲下的性能(10dB)
從以上表中可以看出,本文方法在SNR、LSD和PESQ指標中都比其他兩種方法獲得更好的得分,說明經過本文方法增強后的語音的質量和可懂度都優于另兩種方法。
為了驗證本文方法的泛化能力,表5表示了本文ResAtt方法、DCNN和R-CED在5dB的不匹配f16噪聲情況下的三種方法的性能。
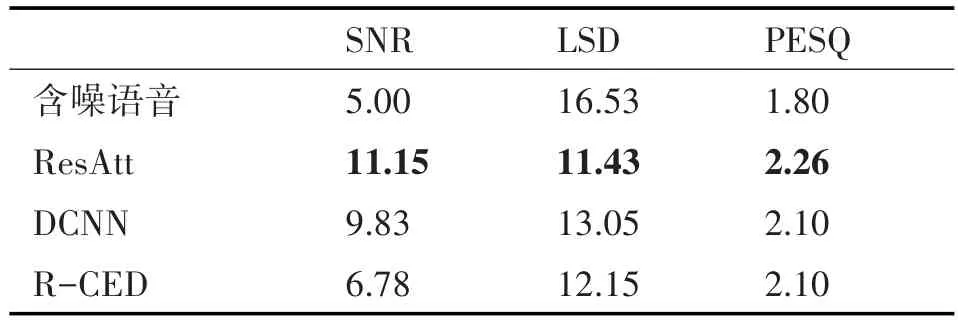
表5 不匹配f16噪聲下的性能(5dB)
從仿真結果可以看到,本文提出的方法在不匹配噪聲環境下,也表現出較好的效果,在評價指標SNR、LSD和PESQ中效果是最好的,表明本文方法在未知噪聲環境下也有較好的增強效果,有較強的泛化能力。
為了更直觀地比較三種方法的性能,選用含有信噪比為5dB white噪聲的一段語音,用三種方法分別進行增強,圖5和圖6中(a)~(e)分別表示純凈語音、含噪語音、DCNN增強語音、RCED增強語音和本文ResAtt增強語音的時域圖和語譜圖。從圖中可以看出,經過本文ResAtt方法增強后的語音,噪聲殘留更少。
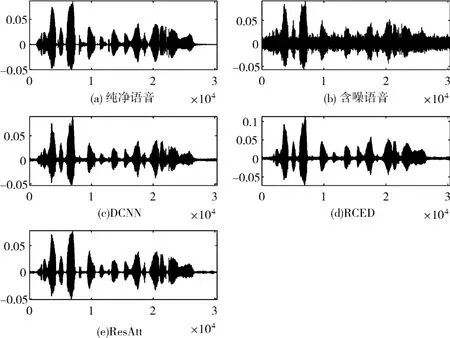
圖5 5dB white噪聲下的語音增強時域圖

圖6 5dB white噪聲下的語音增強語譜圖
綜合比較可以看出本文提出的基于注意力機制和殘差卷積網絡的語音增強方法在低信噪比下可以有效地去除噪聲,提高語音信號的質量,并具有良好的泛化能力。
5 結語
為了進一步提高語音增強算法的性能,本文提出了一種基于注意力機制和殘差卷積網絡的語音增強算法。該方法在卷積神經網絡中添加殘差學習和注意力機制,使得網絡更好地學習特征圖集中的全局信息,增強了網絡的學習能力。通過與DCNN和R-CED方法進行對比,驗證了本文提出的基于注意力機制和殘差卷積網絡的語音增強方法可以顯著提高語音信號的質量,與另外兩種方法相比有更好的語音增強性能,并且有良好的泛化能力。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
