古漢語詞義標注語料庫的構建及應用研究
2022-06-21 08:30:28郭懿鸞王慧萍張學濤胡韌奮
中文信息學報 2022年5期
舒 蕾, 郭懿鸞, 王慧萍, 張學濤, 胡韌奮
(1.北京師范大學 中文信息處理研究所,北京 100875;2.北京師范大學 人文宗教高等研究院,北京 100875;3. 北京師范大學 漢語文化學院,北京 100875)
0 引言
詞義標注語料庫通常需要根據某個詞典對多義詞各個義項的定義,在真實的語料上標注多義詞的準確義項[1]。英語詞義標注語料庫的研究起步較早,由英國Sussex大學主辦的SENSEVAL英語詞義消歧評測推動了該領域的研究。英語詞義標注語料庫有基于詞典義項的SENSEVAL-1語料庫和以WordNet為詞義系統的SemCor語料庫、DSO語料庫、SENSEVAL-2語料庫,以及結合WordNet和Wordsmyth知識庫的SENSEVAL-3語料庫。在SENSEVAL評測中,研究者進一步加入外部知識庫,完善了競賽提供的詞義標注集,相關研究如Wu等[2]和Palmer等[3]。作為基礎語言資源,詞義標注語料庫可以服務于有監督的詞義消歧,進而為語言理解、機器翻譯和詞匯學研究提供支持。例如,Chan等[4]利用詞義標注語料庫建立消歧模型,并應用于機器翻譯系統,有效改善了翻譯效果。Hu等[5]利用牛津英語詞典的例句建立詞義標注語料庫,并借助BERT語言模型實現了細粒度的歷時詞義演變分析,從而揭示了義項競爭和合作的規律。
現有的漢語詞義標注語料庫以現代漢語為主,如北京大學漢語詞義標注語料庫(STC)、臺灣“中研院”中文詞義標注語料庫SSMS、新加坡國立大學華文教材詞義標注語料庫、漢語二語教學詞義標注語料庫等。北京大學的STC語料庫基于《現代漢語語義詞典》的詞義體系,對1998年1月和2000年1-3 月的《人民日報》(總計約642萬字)進行多義詞義項標注,共標注了966個多義名詞和動詞的義項[6]。截至2005年底,臺灣“中研院”詞義標注語料庫SSMS共包含約2 000個現代漢語中頻詞,共涉及約5 900個義項[7]。新加坡國立大學的中小學華文教材詞義標注語料庫依據《現代漢語詞典(第五版)》的詞義體系,對新加坡國立大學的中小學華文教材語料庫(約200萬字)進行詞義標記[8]。漢語二語教學詞義標注語料庫以《現代漢語詞典(第六版)》為詞義區分體系,對197冊漢語二語教材文本中的1 181個多義詞進行詞義標注,構建了約350萬字的詞義標注語料庫[9]。
現代漢語詞義標注語料庫以詞典為基礎,對新聞、教材語料開展加工,有了較為充分的積累。與之相比,古漢語語言資源的建設仍然較為薄弱。古漢語以單音節詞為主,其一詞多義現象十分突出,且在不同歷史時期的詞義分布狀況有較大差異。建設古漢語詞義標注語料庫不僅有助于研究古代詞匯的使用狀況,也可作為基礎資源服務于詞義消歧算法的研究,為古漢語信息處理技術、詞匯學本體研究、詞典編撰等提供參考。
因此,本文選取了古漢語常用詞匯,綜合經典辭書和語料庫實際使用狀況對多義詞進行義項區分和屬性整理,并據此開展詞義標注,建成了超過117萬字規模的古漢語詞義標注語料庫(1)本文所構建的古漢語詞義標注語料庫參見: https://github.com/iris2hu/ancient_chinese_sense_annotation。以該庫為基礎,本文基于BERT語言模型研究了小樣本情境下的詞義消歧技術,準確率達到80%左右。進一步地,本文以詞義歷時演變分析和義族歸納為案例,初步探索了語料庫與詞義消歧技術在語言本體研究和詞典編撰領域的應用,以期為自然語言處理技術在古漢語領域的應用,如文白機器翻譯、文言文信息抽取、古漢語詞匯語法現象研究等提供參考和借鑒。
1 基礎詞義知識庫構建
1.1 選詞的原則
本研究的目標詞為古漢語常用單音節多義詞。綜合考慮詞頻和學術研究需要,篩選出了200個古漢語單音節實詞,在后續研究中還將根據研究需要和用戶反饋持續補充,進行版本迭代。根據國家語委古代漢語語料庫字頻表(2)古漢語字頻表: http://corpus.zhonghuayuwen.org/resources.aspx,第一階段選詞有較高的使用頻度,如表1所示。在頻率排序上,51.5%的所選詞在古漢語字頻表中排名前500,80.5%的所選詞在古漢語字頻表中排名前1 000。
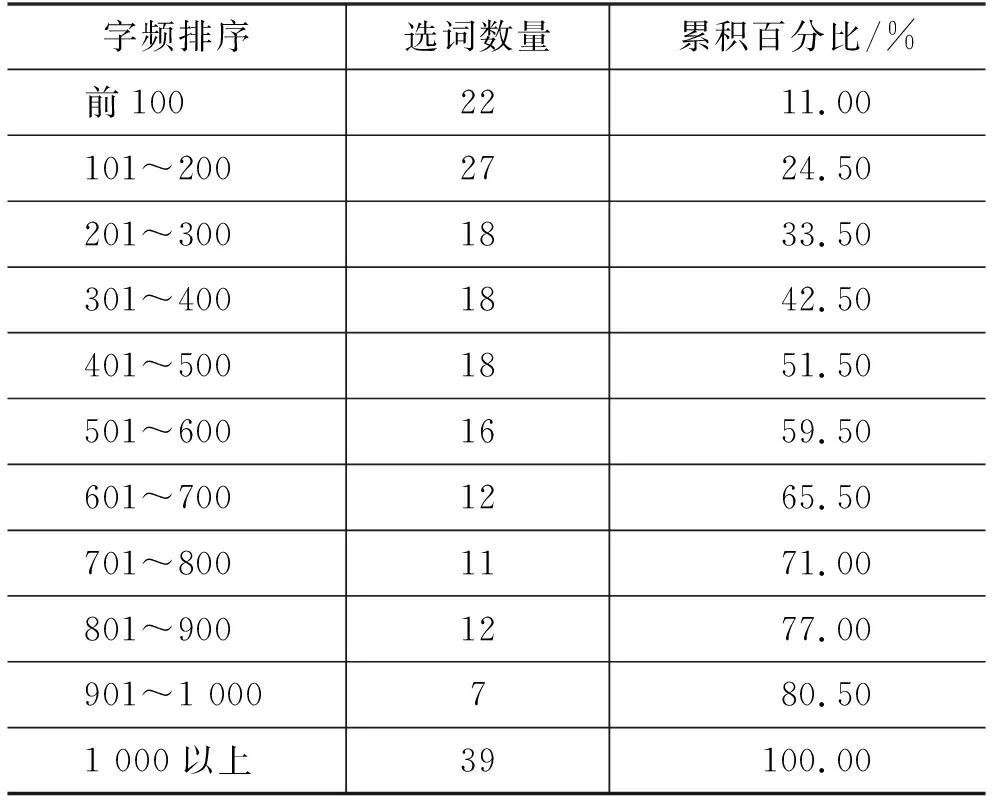
表1 選詞的字頻分布
1.2 義項的設立
詞義知識庫構建的關鍵任務是多義詞義項的設立與區分。吳云芳和俞士汶[6]討論了面向人的辭書義項和面向漢語信息處理的詞語義項的區別,認為后者需要充分比較面向人和面向機器的詞語義項,抽取、概括而成一系列義項區分的原則。肖航和楊麗姣[8]提出,詞義標注語料庫建設主要有兩個難點: 一是詞典詞義區分不清晰,可能導致標注時出現兩可的情況;二是詞典義項不全面,無法包括真實語料中目標詞所有可能的含義。從前人研究可以看出,詞義標注語料庫中的義項設立,既需要尊重辭書描寫,也需要考慮語言事實和后續信息處理加工的需要。同時,值得注意的是,古漢語詞匯在數千年的使用中,產生了極為豐富的引申、活用、借用等現象。與現代漢語的詞義歸納側重共時用法有所不同,古漢語的詞義描寫具有時間跨度大、復雜性高等特點,這也就導致了不同的辭書對同一多義詞的義項設立存在較大差異。
以“興(xīng)”為例,《王力古漢語字典》《漢語大字典》《辭源》及商務印書館《古代漢語詞典(第2版)》對其義項劃分差異較大。其中,《王力古漢語字典》分列4個義項,《辭源》6個,《古代漢語詞典》8個,而《漢語大字典》則有14個義項。各辭書的義項區分如表2所示。
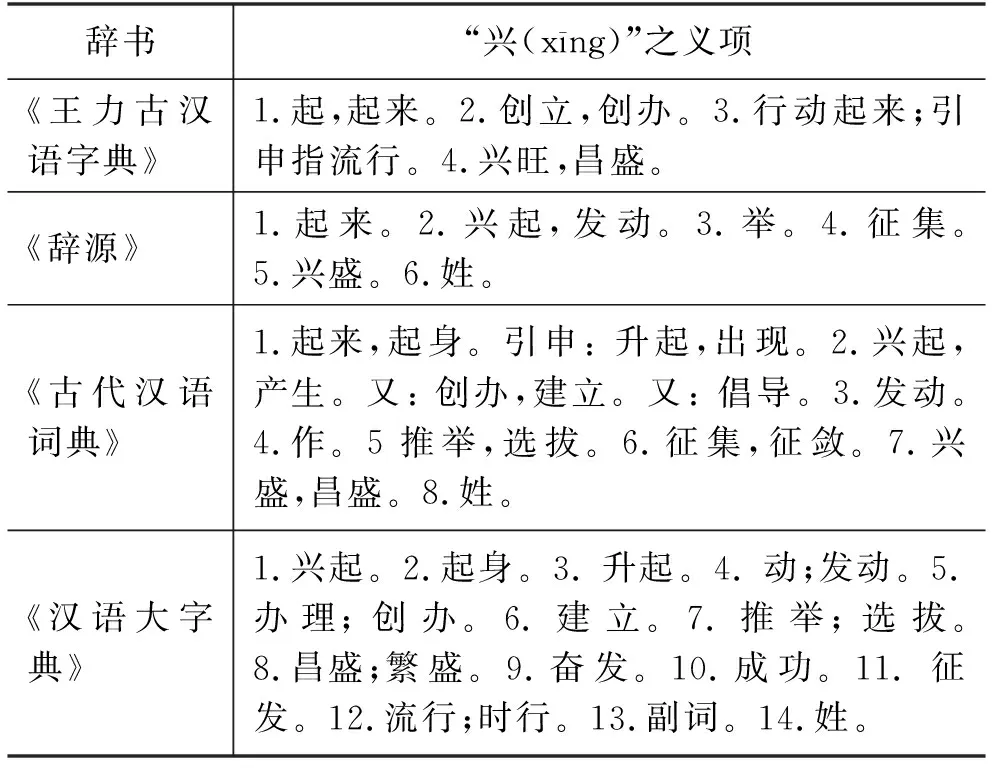
表2 各辭書對“興(xīng)”的義項區分
詞典對標注質量有著極為重大的影響。詞典的選擇必須具有專業性、被認可度高、對詞語義項描述清晰等特點。《王力古漢語字典》兼具“概括性”和“時代性”,可以直觀地解釋義項的類聚與引申。《王力古漢語字典·序》中提出字典具有“擴大詞義的概括性”和“注意詞義的時代性”的特點。就“概括性”而言,王力認為: “一般字典辭書總嫌義項太多,使讀者不知所從,其實許多義項都可以合并為一個義項,一個是本義,其余是引申義。本書以近引申義合并,遠引申義另列,假借義也另列。這樣,義項就大大減少,反而容易懂了。”就“時代性”而言,《王力古漢語字典》在《凡例》指出: 本字典的義項按照“本義在前,引申義在后;通用義在前,非通用義在后;實詞義在前,虛詞義在后;古義在前,后起義在后”的原則排列,體現出較強的時代性和系聯性,體現出了義項之間的關系。
而《漢語大字典》具有“粒度細”“涵蓋廣”的特點,恰好與《王力古漢語字典》在義項設立的寬嚴方面形成互補。《漢語大字典·第二版修訂說明》稱該字典力求“古今兼收、源流并重”,“不僅注重收列常用字的常用義,而且注意考釋常用字的生僻義和生僻字的義項……是新中國成立以來形音義收錄最完備、規模最大的一部漢語字典”。
結合《王力古漢語字典》和《漢語大字典》構建基礎詞義知識庫,兼顧了“概括性”、“時代性”和“涵蓋性”,能有效應對古漢語的詞義描寫時間跨度大、復雜性高等特點,滿足詞義標注語料庫的需要。
因此,本文擬以《王力古漢語字典》為基礎、《漢語大字典》為補充,對多義詞的義項設立進行初步劃分。除了基于辭書信息進行義項的設置之外,詞義標注語料庫還需要從語言事實和信息處理的需求出發,根據語料標注情況對詞典義項進行一定程度的增補、刪減與合并。
確立上述原則后,本研究首先設計了詞義知識庫的框架,其各屬性字段如表3所示。除了詞語和義項的基礎屬性外,還引入了義族、義項屬性等信息,以呈現古漢語詞義的類聚、引申和假借等特殊現象。同時,根據標注語料庫中的義項出現情況設置了“義項頻次”字段,為進一步的義項修訂提供參考。
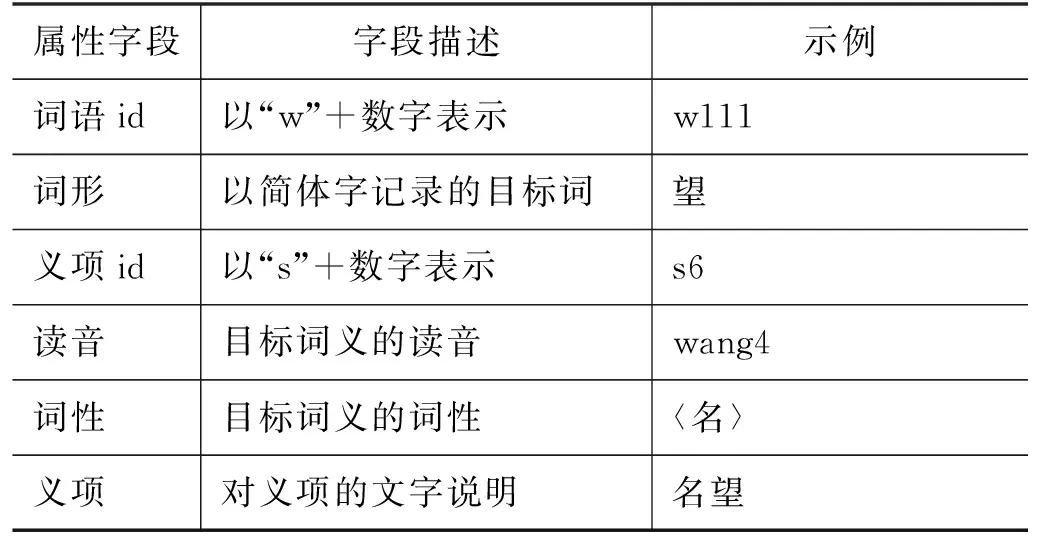
表3 詞義知識庫各屬性字段
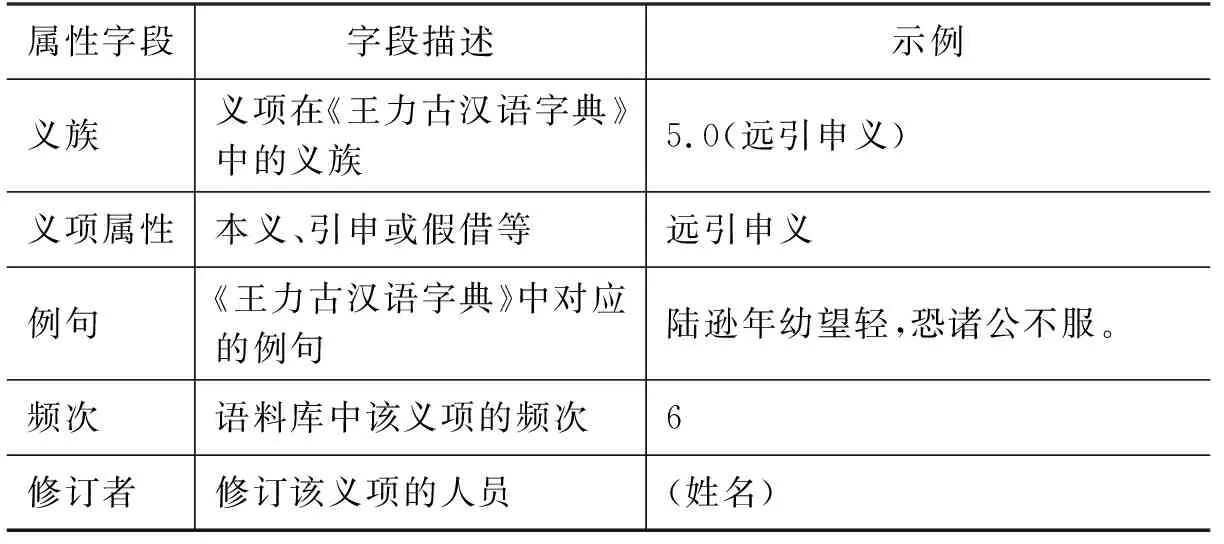
續表
在義項整理的過程中,按照如下步驟進行詞義知識庫屬性填充。第一步,根據《王力古漢語字典》確立基礎義項,將詞語和義項的屬性填入表中。然后,根據詞典中的義族信息確立義族編號和義項屬性: 義族以a.b的形式編號,a對應王力劃分的義項,b對應同一義項內的小類。義項屬性包括“本義”“近引申義”“遠引申義”“假借義”“后起義”“晚起義”“偏僻義”,具體定義如下:
(1) 本義: 《王力古漢語字典》中的第一個義項;
(2) 近引申義: 與本義合并在同一義項內的為近引申義;
(3) 遠引申義: 由本義引申,但列為另一個義項的引申義;
(4) 假借義: 《王力古漢語字典》另列的假借義;
(5) 后起義: 魏晉至唐宋產生的詞義;
(6) 晚起義: 元明以后產生的詞義;
(7) 偏僻義: 《王力古漢語字典》收錄在“備考”欄中的少見的詞義。
以“假(jiǎ)”為例,《王力古漢語字典》中義項為:
① 借。引申為憑借。②暫攝職務為假。引申為非真的,偽的(后起義)。【備考】大。
詞義知識庫與《王力古漢語字典》義項的對應如表4所示。
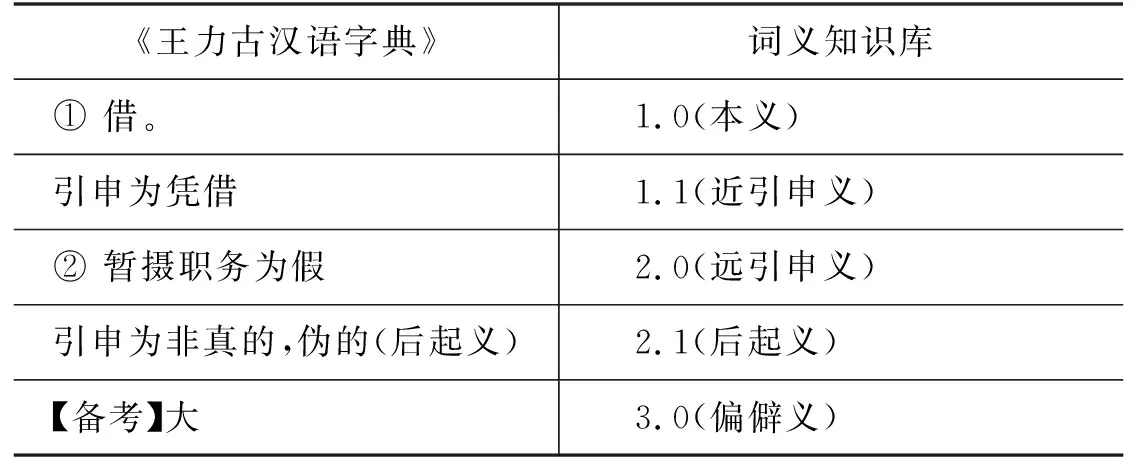
表4 詞義知識庫與《王力古漢語字典》義項的對應
最后,詞義知識庫還需要根據語料的實際標注情況填充義項頻次,并據此進行增、刪、合并等操作,該步驟的操作方式可參見本文第2節。
1.3 義項整理中特殊語言現象的處理
1.3.1 同形詞問題
區分義項時該如何處理同形詞?吳云芳和俞士汶[6]認為,在面向中文信息處理的現代漢語詞義區分體系中,可將同一個詞的不同義項與同形異義詞放在同一個平面上,而無須嚴格區分同形和多義。在中文信息處理實踐中,區分同形詞與區分多義詞的實際義項遵循相同的過程,即根據語境選擇該詞形下的某個含義。然而,在古代漢語中,同形詞事實上由不同的古代詞形表示,只是受到漢字簡化的影響而變成了今天在簡化字書寫范疇下的古漢語同形詞,如“后”(皇后)和“後”(先后),這些同形詞不僅在傳統辭典中有分立的詞條,而且在各詞內部也有相對獨立的詞義引申鏈條。因此,本文認為,吳云芳和俞士汶所提出的應用驅動的觀點是切實合理的,而本研究針對古漢語語言現象進行處理,也應兼顧同形詞不同詞形的獨立性,在標注形式上有所體現。
具體來說,本文通過如下方式進行同形詞的義項梳理。以“后”為例,根據辭書記載,“后”這個字形共對應了兩個同形詞,在字形欄分別用“后1”“后2”標注,“詞語id”欄則用詞語序號+字形序號標注。每個不同的“后”各自有本義、引申義,被看作是兩個起點不同的引申鏈,互相之間沒有聯系,義項編號也各自從s1開始。特別地,在同形詞各自的義項編號前,由一位數字來區分同形詞。這樣的標識方法在基于大規模語料庫的信息處理實踐中也具有一定的靈活度。表5顯示了同形詞“后”的義項區分標注方法。
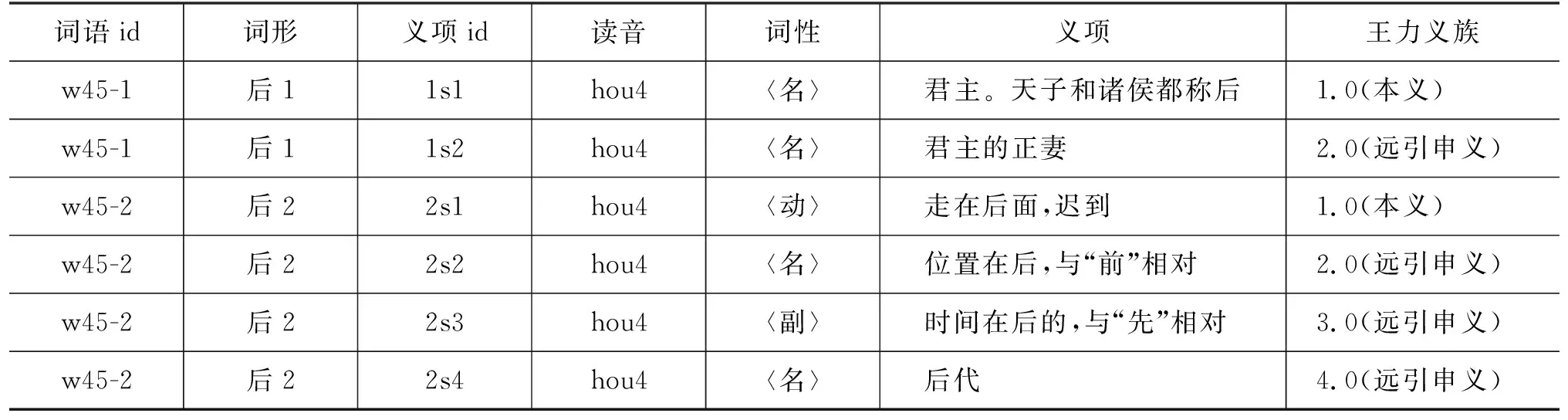
表5 同形詞“后”的義項區分標注方法
1.3.2 臨時用法或通假
張永言在《詞匯學簡論》中提出,詞的臨時用法是詞在個別的特殊的應用場合臨時帶上的含義,比如“行將就木”中的“木”臨時具有了“棺材”的意義[10]。詞的意義和詞的用法存在一定差別,意義是穩定和普遍的,而用法是不穩定的、特殊的。所以我們在面對詞義活用、通假和其他臨時用法時,應根據它的出現頻次判斷是否需要設置義項,以確保詞義的代表性和典型性。若詞的某種臨時用法較為常見,則需要為它設立新的義項,來保證詞義知識庫能涵蓋盡可能多的用例。
例如,詞語“殆”在《王力古漢語字典》中的義項“通‘怠’,懶惰,疲憊”屬于假借義,例句如“學而不思則罔,思而不學則殆”。首先根據《王力古漢語字典》設立該義項,在隨后的語料庫標注過程中,有12句語料中的目標詞“殆”屬于該義項,因而確定設立該義項。又如“奇”的活用義“以……為奇,驚異”在《王力古漢語字典》中收錄,且在語料庫中有可觀的頻次,如例句“大將軍鄧騭奇其才,累召不應”,因此設立為義項。另外,我們亦設立了一些辭書未收錄的臨時用法義項,其考量標準是在語料中的頻次。如“城”的活用意義“守城”并未在辭書中列出,但在語料庫中的例句“(李)應庚發兩路兵城南城”“丞相嘗使籍福請魏其城南田”等均應屬于“守城”意義,共約10句語料,因此也設立該義項。
一些特殊的、不常見的臨時用法則不收入知識庫,例如,“及其為天子三公,而立為諸侯賢相,乃始信于異眾也”,高誘注“信,知也”,可知“信”在語境中是“知曉”的含義,屬隨文釋義,意義具有臨時性,因而不設立義項。又例如,“尚得推賢不失序”中的“得”應為“德”的借字,屬名詞用法,含義為“德,道德,有德之人”。考慮到“得”“德”的借用在語料庫中較為罕見,所以不設為新義項。同理,“右”的“通‘侑’,勸食”義,“方”的“通‘謗’,指責別人的過失”義出現在極少量語料中,皆屬此類,均不為臨時用法新增義項。
1.3.3 專有名詞
在實際語料標注中,發現不少詞例為專有名詞,例如,“誦”在句子“冬十一月,遣使冊高麗國王誦”中應當被解釋為人名;“視”在句子“以真時南北差加減之,為食甚視緯”中屬于天文術語;“孰”在句子“上詔王僧辯鎮姑孰以御之”中屬于地名“姑孰”。絕大部分作專名的用法并未被傳統辭書收錄,而使用頻次卻相當可觀。為了服務于后續的語言學及信息處理研究,本研究對專有名詞單獨設立義項編號: s0,并按照表6所示規則標注具體的專有名詞類別。
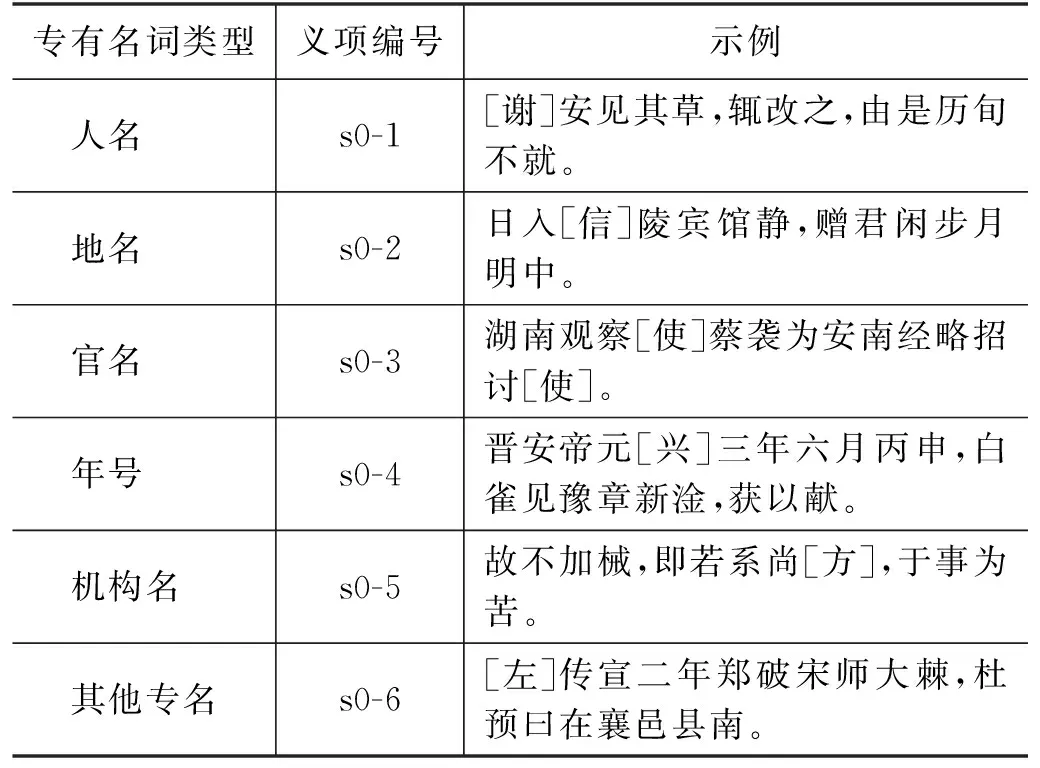
表6 專名標注示例
在實際的語料標注過程中,共有約1 800個例句的目標詞被標注為專有名詞,接近語料庫規模的4.7%。
2 詞義標注
完成了基礎詞義知識庫的構建后,本研究依據詞義知識,在語料庫中標注目標詞的義項,并根據標注結果對詞義知識庫中的義項進行增補、刪除、合并等操作。
2.1 語料采樣及預處理
從古漢語詞義標注語料庫的建設需求出發,本研究認為語料選取應符合如下原則: ①句子完整、句長適中,以提供較為明確的語境信息; ②語料均衡,覆蓋了不同時代和文獻類型,盡可能體現詞義使用和分布狀況; ③無文本內容之外的特殊符號和標記。
根據上述原則,本文將語料采樣的范圍設定于“語料庫在線”古代漢語語料庫(國家語委語料庫)和CCL古代漢語語料庫,二者均為研究者廣泛使用的古代漢語語料庫,采用簡體字加工,具有體量大、收錄全、覆蓋不同朝代等特點。從上述語料庫中抽取含有目標詞的句子,每個目標詞隨機抽取200條語料,并保證其朝代分布的均衡性。隨后,去除語料中的特殊標記。
2.2 詞義標注實踐
根據基礎詞義知識庫,由漢語言文字學、古典文獻學專業研究生開展語料標注工作,具體遵循如下步驟。
(1) 標注義項。根據目標詞在語境中的含義,從義項表中選擇義項編號。對于無法找到對應義項的情況做如下標記: 若目標詞屬于專有名詞,則按上文所述專名編號標記;若目標詞義屬于知識庫未收錄的義項,則標為“其他”;若根據上下文難以判定義項歸屬則標為“待定”;若存在句子不完整情形或目標詞在該語境中有歧義,則標記為“語料不宜”。
(2) 搜集標注反饋,統計義項頻次信息,并結合詞典描寫調整知識庫中的義項列表,對詞義知識庫中的義項做出新增、刪除、合并等操作建議。具體來說,包括如下幾種情形: ①若語料庫中該義項出現至少2次,則在詞義知識庫中保留該義項。②若義項在語料庫中未出現或僅出現1次,參考《漢語大字典》的義項設立和例句情況,如果其為《漢語大字典》獨立收錄且有例句佐證用法,則保留,否則建議歸并或刪除: 如該罕見義項與其他義項存在較高相似性,則建議歸并,否則建議取消該義項的設立。③針對標注中發現的“其他”義項,如果為《漢語大字典》收錄且具有可觀頻次,則建議為其新增義項;如果兩部辭書均未收錄,且僅在少量語料中出現該意義,則不設立新義項,例如,包含目標詞“絕”的一條語料: “鄉中少年聞其美,神魂傾動,媼悉絕之。(《聊齋志異》)”,根據文義應當屬 “拒絕”義,但兩部辭書中“絕”字均無“拒絕”義。考慮到此義項出現情況較少,且不宜和其余義項合并,因而不新立義項。
(3) 針對上述操作中給出的新增、刪除、歸并等建議,由漢語言文字學、中文信息處理專業教師再次審訂后,確認詞義知識庫的修訂。
(4) 根據修訂后的詞義知識庫對語料標注結果進行修訂,以確保修訂后的詞義知識庫和語料標注中義項的一致性。同時,將詞典中的例句也作為補充加入語料庫。
(5) 開展知識庫和語料庫校對工作,首先由高年級漢語言文字學研究生對語料庫中的“待定”“其他”等條目進行校對,給出合理的標注建議;然后由項目組師生對詞義知識庫和語料標注結果做再次校對。
3 語料庫整體規模和義項分布概覽
3.1 整體規模
第一階段的古漢語詞義標注語料庫共收錄200個單音節多義詞,詞義知識庫中收錄的詞語義項數量為2 007個,加上專名義項編號6種,共有2013個義項,平均每詞義項數量10個。其中,有5個義項未出現在語料庫標注中,這些義項被《王力古漢語字典》或《漢語大字典》認為屬于本義,但未列出例句用法,如“盡”的本義“器物中空”。考慮到這些屬于本義的義項在引申鏈的構建中具有較大的意義,因此保留這些低頻義項備考。
目前,詞義標注語料庫收錄38 720條標注數據,總計117.6萬字。除專名外,標注語料庫中的總義項數量為2 002個,每條語料僅對唯一的目標詞進行標注。
3.2 義項分布概覽
語料庫中義項頻度信息如圖1所示,其中,大量的義項僅出現1次,出現次數在5次及以下的義項占比51.85%,主要原因推測有兩方面: ①古漢語歷時跨度長,不少義項僅在個別或少數朝代使用,整體的頻次較低; ②在同一個詞形下,存在使用優勢的義項占據主導地位,使得其他義項比例較低。
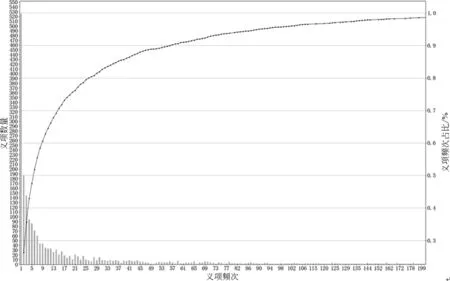
圖1 語料庫中的義項頻次分布情況
為了解詞義分布的真實情況,僅依靠統計詞義標注語料庫中對應目標詞的標注結果(約200條/詞)是不夠的,因而我們可通過有監督的詞義消歧技術,對大規模語料進行義項標注,從而獲得義項真實的分布情況。
4 詞義標注語料庫的應用
4.1 古漢語詞義消歧
依托詞義標注語料資源,可以實現有監督的多義詞消歧。Hu等[5]以牛津英語詞典的例句作為訓練語料,將每個義項不多于10條例句作為訓練集,通過BERT語言模型獲得各個義項的語境向量表示。針對新語料中的目標詞,計算該詞的語境向量與該詞形各個義項向量的相似度,將相似度最高的義項確定為該句中目標詞所屬義項。類似地,本研究嘗試將義項標注語料庫資源劃分為訓練集和測試集,開展詞義消歧實驗。
本研究采用的語言模型來自胡韌奮等[11]構建的古漢語BERT模型,該模型由總計33億字的殆知閣古代文獻藏書2.0版語料庫訓練而成。由于訓練語料庫中繁簡體混雜,考慮到繁體轉簡體的準確率更高,模型研發者將訓練語料統一轉換為簡體。本研究選擇該模型進行詞義消歧,是因為其訓練語料和本研究所使用的語料較為接近,均來自存世古代漢語典籍,且都有朝代跨度廣、涵蓋文體多的特點。
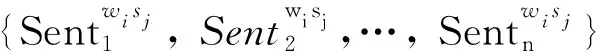
考慮到古漢語詞義標注語料庫中,每個義項下的例句樣本較小,實驗設定了2~10共9種閾值,在不同閾值下進行詞義消歧實驗。閾值表示對于某一個義項,若例句數量超過該閾值,則將其納入消歧實驗。設立不同閾值可以較好地檢驗和對比小樣本情境下消歧方法的效果。當某個義項的例句數量為2、3、4時,實驗劃分出1條例句作為測試,其余例句歸入訓練集。當閾值大于或等于5時,按照8: 2的比例劃分訓練、測試集。考慮到語料庫中約52%的義項只有1~5條例句,這樣的劃分方法能夠較為真實地反映詞義消歧模型的效果。
不同閾值下詞義消歧的數據劃分結果及準確率如表7所示。
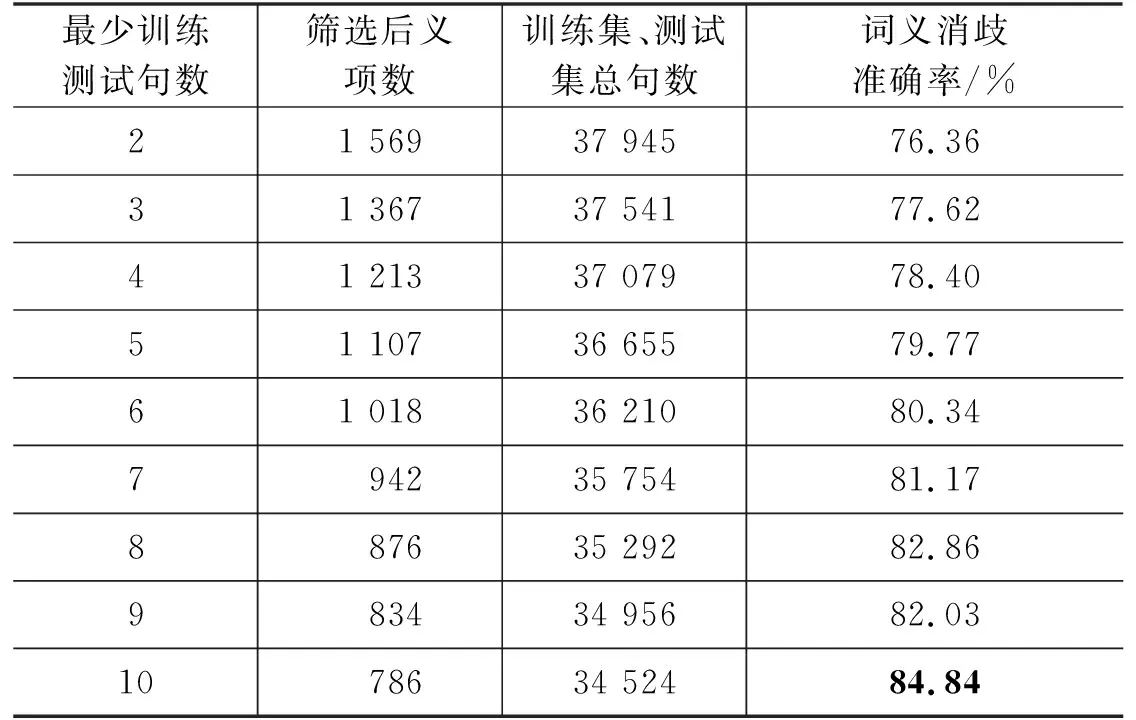
表7 詞義消歧實驗數據
句子數量閾值為2時,模型達到了高于75%的準確率,而隨著閾值的增高,消歧準確率也進一步提高,當訓練樣本數量達到5(即閾值取6)時,詞義消歧準確率達到80%以上。實驗結果顯示,本研究構建的古漢語詞義標注語料庫可以作為詞義消歧技術的基礎語言資源,基于BERT語言模型的小樣本詞義標注方法達到了一定的準確率。如能進一步有針對性地人工增補例句,確保每條義項的例句數量達到一定閾值以上,該方法將可能取得更好的效果。
接下來,我們對低閾值和高閾值下模型判斷錯誤的數據進行人工分析,歸納總結出兩種典型的情況:
典型情況一: 閾值的提升糾正了原本判斷錯誤的義項。例句“束書辭東山,改服臨北風。”中的目標詞“書”正確的義項應為“s4-書籍,裝訂成冊的著作”。在閾值為2時,目標詞被模型自動標注為“s2-文字”,屬于標注錯誤的案例。而當閾值為10時,義項被正確標注了。對此本文認為可能的原因是: 閾值較高時,低頻義項不參與訓練,這減少了目標詞在義項消歧時的候選義項數量,增加了消歧準確率。另外,相較于高頻義項,低頻義項由于參考例句較少,其義項向量難以得到充分的表示。
典型情況二: 高閾值時仍然判斷錯誤的義項。目標詞“慕”在例句“湯、禹久遠兮,邈而不可慕。”中的正確義項為“s2-羨慕”,而模型標注為“s1-思念,依戀”。原因可能是這兩個義項本身較為接近,且上下文未提供足夠信息。類似的誤判有: “九者彼來加我,志在不報。”的“報”本應標為“s1-報答,報酬”,卻被模型標為“s7-報復”;例句“子思,字眾念,性剛暴,恒以忠烈自許。元天穆當朝權,以親從薦為御史中尉。”中的目標詞“朝”本應標為“s3-朝廷”,而被模型標為“s8-政事”。
4.2 古漢語歷時詞義演變
歷時詞義演變研究依托大規模的歷時語料庫,旨在還原多義詞義項在一段歷史時期內頻率的變化,發現詞語義項產生、消亡和義項之間的競爭等關系[12]。在本研究中的詞義消歧模型獲得一定準確率的基礎上,可以使該模型自動標注大量歷時語料中的目標詞詞義,從而獲得義項的歷時分布。
本文以多義詞“使”為例,從國家語委古漢語語料庫中隨機抽取20 000條帶有時代信息、且包含目標詞“使”的語料,以詞義標注語料庫中所有目標詞為“使”的例句作為訓練集,建立目標詞“使”的詞義標注模型。用該模型對20 000條帶有時代標簽的語料進行義項自動標注,梳理各個主要義項的歷時分布情況,對曲線進行四次多項式擬合,其結果如圖2所示。
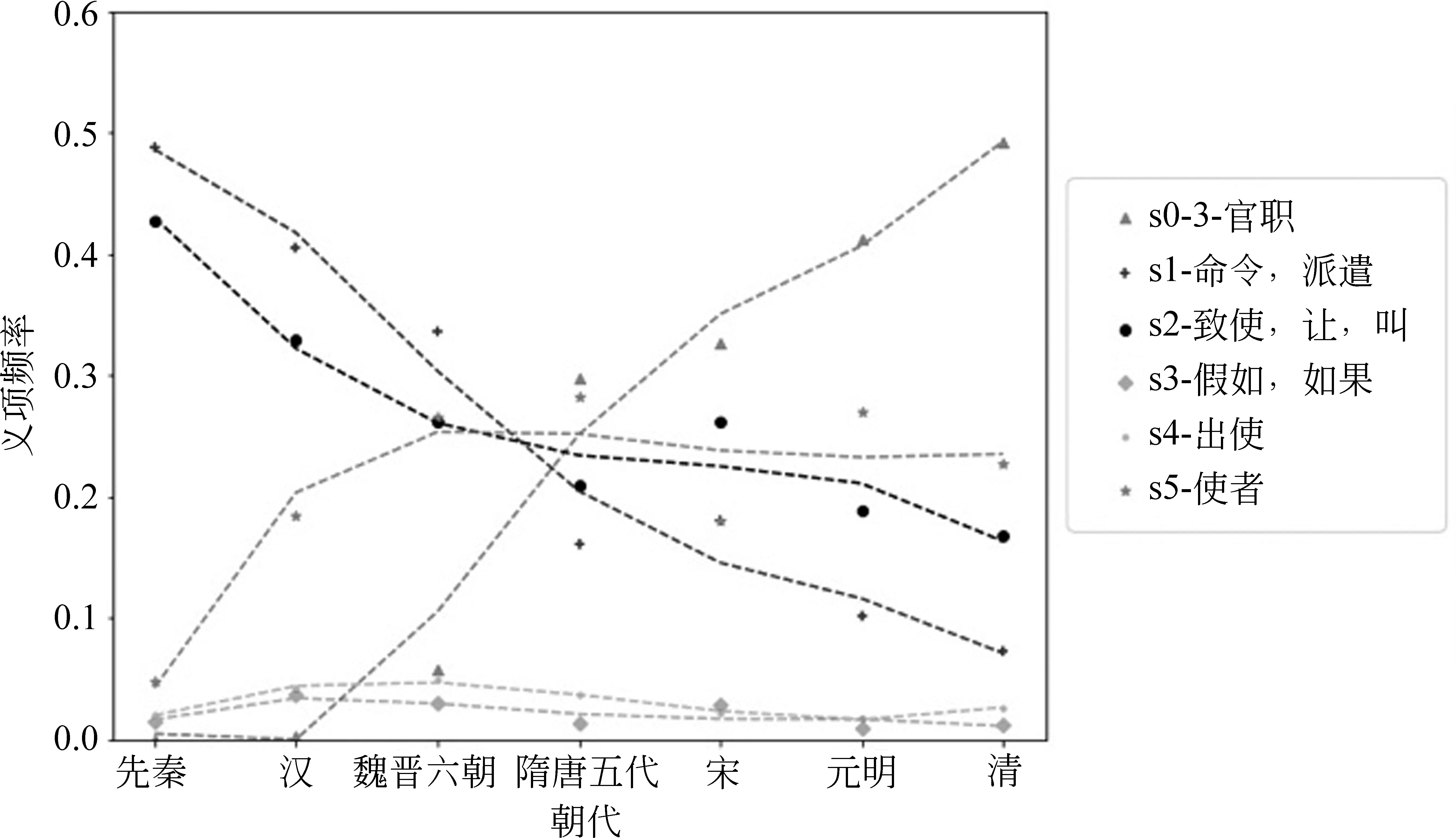
圖2 “使”各義項的歷時變化趨勢
從圖中各義項的歷時變化趨勢可見,“使”作為(君主)使者的含義在先秦即有,而作為官職名稱則可能在漢代以后出現,隨后激增。到了清朝,“使”作為官職名稱成為文獻中最常見的義項。相反的,“命令、派遣”和“致使”意義在先秦頻率較高,但二者的占比在后期總體呈現下降趨勢。
4.3 輔助詞典編撰
除了歷時詞義分析之外,各義項的向量表示也可以作為詞典劃分義族的參考。本文根據詞義標注語料庫,使用古漢語BERT語言模型獲得了多義詞“望”的各義項的向量表示。通過計算各義項向量之間的余弦相似度或采用層次聚類方法,可以獲得各義項之間的親疏關系。層次聚類圖中,目標合并的先后順序標志著所屬類別的遠近。另外,對詞義向量做PCA降維,可以直觀地在語義空間圖中查看義項之間的位置遠近。以詞語“望”為例。在《王力古漢語字典》中,“望”未單列“希圖,企圖”和“向,對著”義項,這兩個義項被《漢語大字典》單列,且在實際標注過程中分別有22和13條例句被標為該義項,因而我們在詞義知識庫的構建過程中新增了這兩個義項。為了描述這兩個義項與其他義項之間的關系,本文采用層次聚類的方法,以常用的歐氏距離作為距離計算公式。如層次聚類圖(圖3)所示,首先目標義項“向,對著”和“遠望”合并、另一個目標義項“希圖,企圖”和“期望,盼望”合并,接著這兩個小類合并后,與“名望”合并,最后,兩個邊緣義項“望日”和“遙祭”合并后再并入其中。

圖3 “望”各主要義項的層次聚類情況
進一步地,如圖4所示,降維后的語義空間反映了義項向量在三維空間中的相對位置關系,雖然降維過程丟失了高維空間中的一些細節,但是還是可以直觀地看到義項“遙祭”和“望日”屬于邊緣義項,而“遠望”和“向,對著”,“期望,盼望”和“希圖,企圖”之間兩兩具有緊密聯系。

圖4 “望”各主要義項向量在降維后的語義空間中的相對位置
因此本文認為“望”的義項“希圖,企圖”和“向,對著”有可能屬于引申義,“希圖,企圖”與“期望,盼望”義項關系密切,“向,對著”和“遠望”義項之間關系密切。考慮到義項“遠望”在《王力古漢語字典》中被認為是本義,而《漢語大字典》中義項“向,對著”的最早用例來自馬王堆帛書的“日月相望”,則推測義項“向,對著”是由本義經過語法化的過程而產生的近引申義。5結論本文以古漢語詞義標注語料庫為研究對象,基于傳統辭書和語料庫中的義項頻率,設計了古漢語多義詞的詞義劃分原則,以200個常用古漢語單音節多義詞為例,構建了詞義級別的知識庫,并據此對包含多義詞的語料開展詞義標注。現有的語料庫包含3.87萬條標注數據,規模超過117萬字,豐富了古代漢語領域的語言資源。實驗顯示,基于該語料庫和BERT語言模型,詞義消歧算法準確率可達到80%左右。在此基礎上,本文介紹了該語言資源在古漢語詞義歷時演變研究、輔助詞典編撰中的應用案例。未來,該資源和相關算法還為文白機器翻譯、文言文信息抽取、古漢語詞匯語法現象研究等提供參考和借鑒。值得一提的是,本研究提出的古漢語詞義標注語料庫依然存在規模較小的問題,為確保提升該資源的應用價值,我們將在未來的研究中對其做進一步的擴充和更新。
