基于詞信息嵌入的漢語構詞結構識別研究
2022-06-21 08:30:32殷雅琦代達勱
中文信息學報 2022年5期
鄭 婳,劉 揚,殷雅琦 ,王 悅,代達勱
(1. 北京大學 計算機學院,北京 100871;2. 北京大學 計算語言學教育部重點實驗室,北京 100871)
0 引言
漢語構詞結構的研究由來已久,從《馬氏文通》[1]開始,涉及語法、詞匯學的論著大都關注構詞的話題,該問題對漢語語言學的重要性不言而喻。趙元任[2]、朱德熙[3]等學者指出,詞的結構是影響詞義的一個重要因素。譚景春[4]、曹煒[5]等深入分析了漢語詞在結構組配過程中的意義和貢獻。蘇寶榮[6]進一步指出結構能夠從句法、詞法和新詞義生成三個層面對語言產生影響。
面向中文信息處理的需求,楊梅[7]給出了一套較為完善的構詞結構標簽,并證明了采用構詞進行計算處理的可操作性和優越性。吉志薇和馮敏萱[8]、田元賀和劉揚[9]嘗試利用語素信息和構詞規則實現對未登錄詞的理解和語義預測。陳龍等[10]則以語素概念和構詞結構為基礎,實現了對具有隱喻和轉喻現象的漢語非字面義詞的表示和理解。Zheng等[11-12]在語義生成和詞義消歧任務中融入了構詞結構信息,并取得了良好的效果。
認識到漢語構詞結構在理論和應用上的重要性,信息處理領域的學者開始關注構詞結構的自動識別,但是迄今為止開展的計算性工作依然較少: 在已有的研究中,Li[13]以句法結構標簽表示對構詞結構進行識別,Zhang等[14]利用四種常見構詞結構幫助識別復合詞的主體部分,孫靜等[15]根據前綴與后綴結構構建計算模型。這類計算中大多沿用句法層面的粗粒度標簽,缺乏相對明晰的語言學分類標準;此外,目前的構詞結構識別主要利用詞間信息[16-18],忽略了語素義和詞義等具有較強指示性的詞內信息。
基于楊梅[7]的構詞研究成果和劉揚等[19]的語言知識工程基礎,我們構建漢語構詞結構及相關信息數據集,首次采用語言學視域下的構詞結構標簽體系開展計算,提出了一種基于Bi-LSTM和self-attention的模型,以此來探究詞內(詞、字、詞義、語素義)、詞間(上下文)等多方面信息對構詞結構識別的影響。該預測方法與數據集將為中文信息處理的多種任務,如語素和詞結構分析、詞義識別與生成、語言文字研究與詞典編纂等提供新的觀點和方案。
本文組織結構如下: 引言部分介紹漢語構詞結構識別的需求、現狀和可能的發展;第1節對相關的理論問題、數據研發與計算方法作了梳理和評述;第2節介紹本文研發的漢語構詞結構及相關信息數據集;第3節給出了一種基于多種詞信息嵌入的漢語構詞結構識別方法;第4節闡述實驗結果并進行了詳細的對比分析,進一步探討了模型的泛化能力;在結語部分,總結了本文工作以及未來可以深入展開的研究方向。
1 相關工作
1.1 漢語構詞的研究與開發
對于漢語構詞方式,語言學界目前有語法構詞、語義構詞等不同看法。語法構詞的觀點以偏正、主謂等語法結構對構詞成分之間的關系進行分類。郭紹虞[20]、朱德熙[3]等認為漢語句子的構造原則與詞的構造原則基本一致。陸志偉[21]、趙元任[2]、王洪君[22]等學者的研究,也支持復合詞內部結構和句法結構類似這一觀點。語義構詞的觀點則強調以主體、客體等語義標簽分析構詞成分[23-24]。劉叔新[25]、徐通鏘[26]等認為字與字之間是按語義關系構成字組。基于以上觀點,考慮到計算的需求,傅愛平[27]指出,雖然語義構詞在表示詞義時有天然優勢,但其結構產生依據過于復雜,難以達成統一的標簽集,因此不利于計算處理。而語法構詞的結構體系簡單,標準統一,且詞法與句法結構有天然相似性,更適合計算處理。在語言知識工程方面,苑春法和黃昌寧[28]利用語法結構標簽統計分析復合詞的結構、構建語素知識庫。劉揚等[19]、陳龍等[10]依據這些前期研究,建立了以語素概念為基礎語義單元、涵蓋十余種構詞結構的漢語概念詞典。
除構詞方式外,語言學界的另一個關注點是構詞單位。學界普遍認為,語素是漢語中最小的音義結合體,也是構詞的基本單位,能夠對詞相關信息的識別與研究起到關鍵作用[29]。徐樞[30]對《現代漢語詞典》中語素參與組詞的數量進行了統計,結果表明語素在構詞中非常活躍,處于重要的地位。苑春法和黃昌寧[28]的統計結果顯示,語素在構成名、動、形三類主要詞匯后,語素義保持原本意義的比例均高于85.0%,說明了語素義研究對理解詞義的必要性。另一方面,在信息處理中,語素對詞的分析與表達提供了有效幫助。Qiu等[31]利用語素嵌入增強詞嵌入,為缺少上下文的新詞提供表達,并在類比推理任務和詞相似度任務中證明了語素嵌入的優勢。Cao和Rei[32]將語素及其詞內權重納入詞嵌入的生成過程,展現了語素信息對新詞理解的優勢。Lin和Liu[33]建立基于構詞分析的語素嵌入,在語義相似度等內部任務中相比傳統方法取得顯著性能提升。
1.2 漢語構詞信息的計算與應用
目前的中文信息處理以利用及分析詞間信息為主[16-18],對詞內信息的關注相對較少。以往的詞內信息研究大體上分為三類:
第一類研究將對詞的分析細化為對字的分析,進行字符級的研究。Zhao[34]用基于字依賴的表示代替詞向量。Dong等[35]先從字進行分析,再由字組詞來代替傳統分詞模式。Zhang等[14]在設計字符級結構樹標簽時考慮了主謂、動賓、聯合、偏正四種結構,將基于詞的依賴樹擴展為基于字的結構。Zhang等[36]利用前文的標注結果,整合詞間句法依賴和詞內依賴。Li等[37]捆綁了字、詞的詞性標簽及其依賴標簽,將字符作為神經網絡學習的基礎單元,提出了字符級依賴解析器。字符級的研究是詞內結構研究的熱門方向,但在語言學的視域下,構詞的基本單位為語素,而非字符。因此,忽略了語素的字符級研究,存在語義理解與計算上的局限性。
第二類對于詞內結構的研究,關注介于字和詞之間的聯系,即子詞的概念。對于提取子詞,Sennrich等[38]給出了雙字節BPE編碼算法,Schuster和Nakajima[39]則提出了WordPiece詞切分算法,以概率而非頻率提取新的子詞。Kudo[40]的一元語言模型以最大化句子分詞結果概率為目標,同時輸出分詞結果與各詞概率。Yang等[41]利用BPE算法獲得中文子詞列表,再使用Lattice-LSTM模型將子詞嵌入與字符嵌入結合。Zhang等[42]結合詞嵌入與子詞嵌入,獲得子詞增強嵌入,從而增強文本理解任務的結果。Gong等[43]建立字、子詞、詞的樹狀結構表示,組合成HiLSTM模型,應用于命名實體識別任務。子詞的研究在近兩年得到了研究者的關注,介于字與詞之間的粒度讓其應用更加靈活。但子詞在語言學上沒有確切的對應概念,這類方法更偏向統計學計算,而非基于語言本體的研究。
第三類研究則將詞結構分析作為獨立的自然語言處理任務。方艷和周國棟[44]定義了詞結構分析任務,并提出了基于層疊CRF模型的詞結構分析方法,即在傳統分詞方法后,利用層疊CRF識別詞的內部結構。孫靜等[15]提出了基于詞綴的詞結構分析模型,考慮了前綴式與后綴式這兩種構詞結構。蔣萬偉和劉娟[45]在此基礎上針對未登錄詞的特點,設計了一般化的特征集,試圖識別構詞層次結構。但這類研究并未提供語言學視域下的細粒度構詞結構標簽,而更多地關注詞內切分的位置與層次。
2 漢語構詞結構及相關信息數據集
在漢語構詞結構識別中,我們把構詞結構的影響因素分為兩大類: 詞內信息與詞間信息。
2.1 漢語的詞內信息
漢語的詞內信息包括詞、構詞結構、字、語素義與詞義。其中,詞指的是詞型(word type),字指的是構成詞的字型,語素義指的是構成詞的語素的釋義,詞義指的是詞的釋義。
考慮到詞典的權威性,同時為了保證數據的覆蓋度與細粒度,我們從《現代漢語詞典(第五版)》(以下簡稱《現漢》)中收集數據。包括《現漢》中全部45 311個有釋義和例句的漢語二字詞(雙音節詞)詞條,其中有8 684個多義詞。我們把不同的義項視為不同的詞條,并給了每個詞條唯一的ID。以“題字1”為例,其ID為“52061-01-01”,依次代表“該詞的ID-該詞在詞典中的第幾次條目出現-當前是該詞的第幾個義項”。
對于漢語構詞結構的劃分,從語言學的視角出發,楊梅[7]給出了18種構詞結構;在此基礎上,為了中文信息處理的應用需求,劉揚等[19]、陳龍等[10]提出并標注了16種構詞結構。根據現有的前期工作,我們整理了一個包含構詞結構及其相關信息的數據集,在輔助構詞結構預測任務的同時,也為下游任務提供數據資源,具體的構詞結構解釋和使用實例如表1所示,即: 定中、聯合、述賓、狀中、單純、連謂、后綴、述補、主謂、重疊、方位、介賓、名量、數量、前綴與復量。注意到,一些多義詞的不同義項在構詞結構上存在著差異,如表2列舉的“題字”一詞,當表示“為留紀念而寫上字”時,構詞結構為述賓,而表示“為留紀念而寫上的字”時,構詞結構為定中。
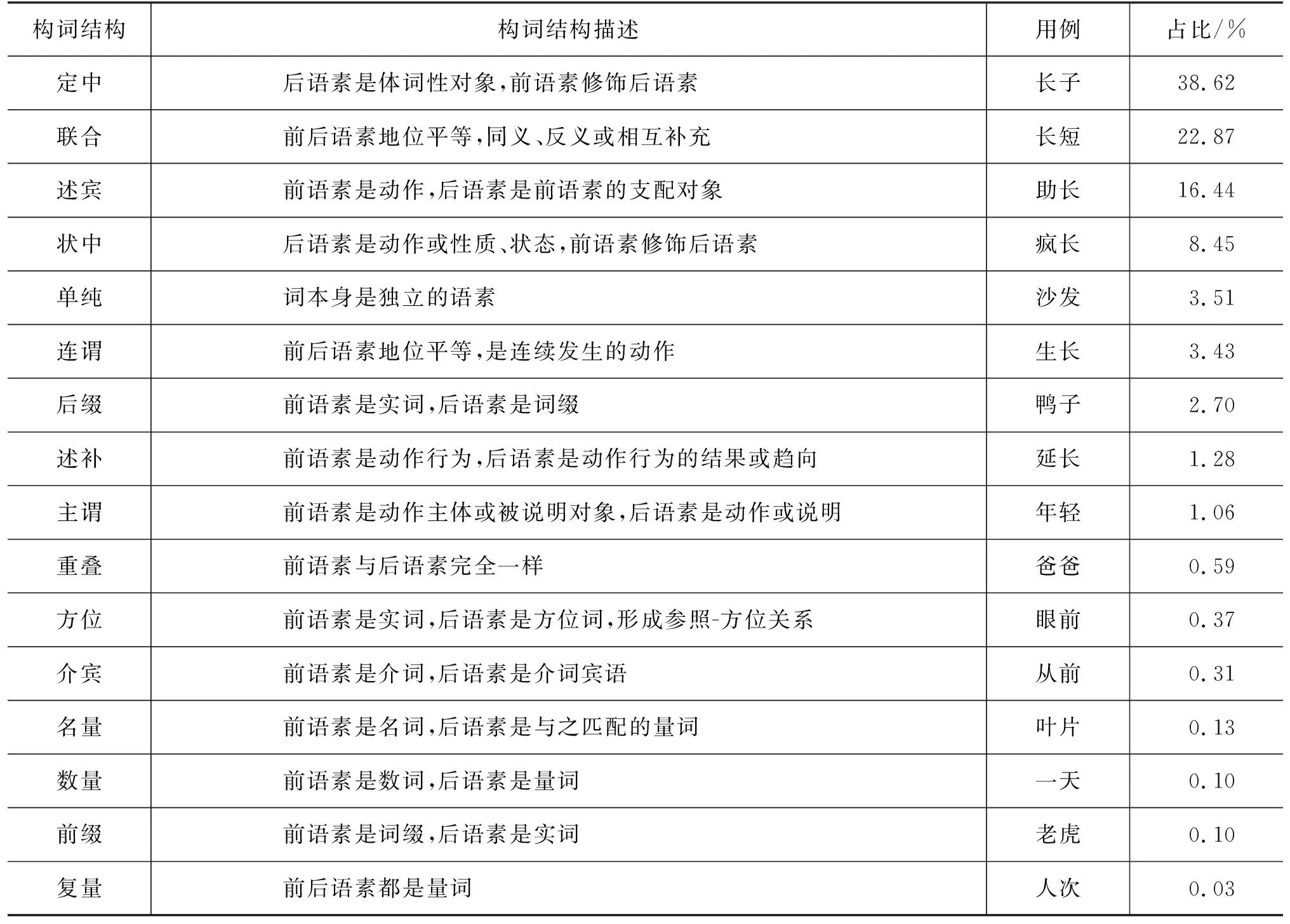
表1 構詞結構與用例(%表示該類型的百分比)

表2 “題字”的兩個義項及釋義例句
為了區分字的不同使用及意義,即語素的情況,接下來需要對構詞結構下的語素成分進行義項標注。我們從《現漢》中收集了8 515個漢字和20 855個語素釋義,并賦予每個語素釋義唯一的ID。表3展示了“長”字的不同語素義及其ID編碼,其中“長1”的釋義為“兩點之間的距離大”,其ID為“長1-06-01”,依次代表“該字在詞典中的第幾次條目出現-該條目共有幾個語素義-當前是該條目的第幾個語素義”。
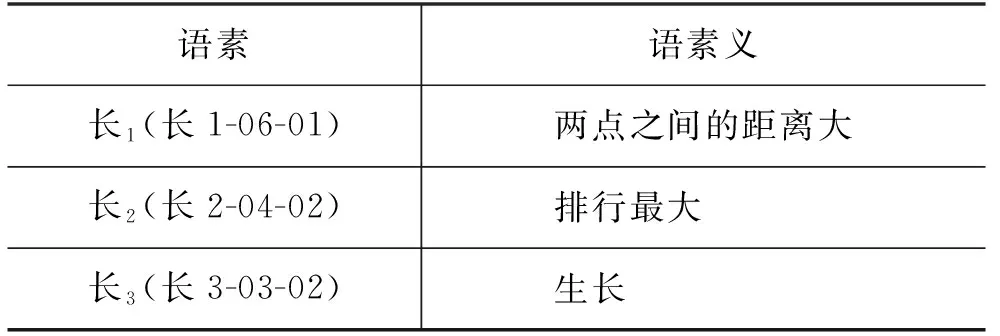
表3 “長”字的三個語素及定義示例
在此基礎上,我們對每個詞條的構詞結構與語素義進行了標注。標注人員包括中文系兩位教授與六名研究生,他們根據詞條釋義為每一個詞條標注構詞結構并綁定對應的語素義ID(表4)。每個詞條由三位標注人員獨立標注并交叉驗證,每位標注人員在標注的同時也會給出一個置信度。如果三位標注人員的標注結果完全相同,則直接收入數據集,如果三位標注人員的標注結果不完全相同,則由另一位標注人員進行審閱,依據之前三位標注人員的標注結果與置信度決定最終標注并收入數據集。在全部45 311個詞條中,81.92%的詞條三位標注人員的標注完全相同,90.86%的詞條至少兩位標注人員的標注完全相同。

表4 語義構詞知識示例
2.2 漢語的詞間信息
此外,影響漢語構詞結構的詞間信息主要是目標詞的上下文。在前文中提到,不同義項的多義詞可能會表現為不同的構詞結構,這也有可能體現在上下文的差異中。《現漢》中的例句和義項是彼此對應的,如表2所示,對于“題字”的兩個義項,《現漢》中均給出了對應的釋義與例句。我們收集了《現漢》中所有二字詞的例句,作為數據集中的上下文信息。綜上所述,我們最終構建的漢語構詞結構及相關信息數據集包含了詞、構詞結構、字、語素義、詞義與上下文,如表5中呈現的例子所示。
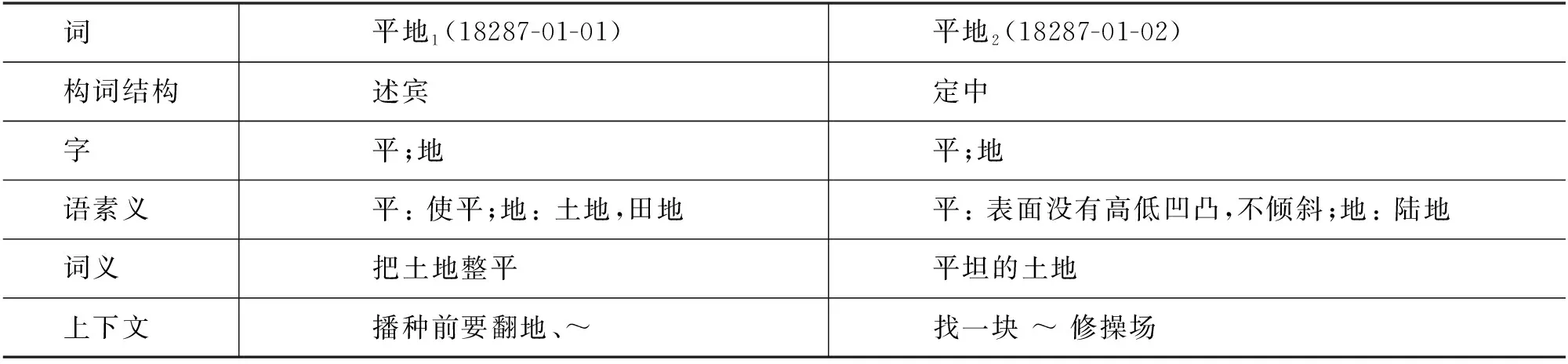
表5 構詞相關信息示例
3 結合詞內和詞間信息的構詞結構識別方法
3.1 任務描述
本文中的構詞結構預測屬于多分類任務,輸入一個目標詞w*及其詞內和詞間信息,輸出該目標詞的構詞結構類別。其目標函數如式(1)所示。
(1)
其中,m表示預測的構詞結構,w*為目標詞,Ch={ch1,ch2}為目標詞中的字,Morph={morph1,morph2}為目標詞中的語素義,Def為目標詞的詞義,Con為目標詞的上下文,f(·)為構詞結構識別的分類器。
3.2 基于Bi-LSTM的構詞結構識別
為了探究詞內和詞間信息對漢語構詞結構識別的影響,我們的模型架構如圖1所示,具體包含四個部分: ①信息輸入層; ②信息編碼層,用來編碼輸入的詞內和詞間信息; ③信息交互層,用來融合編碼信息; ④輸出層,根據編碼的信息來進行分類,輸出預測的構詞結構。

圖1 模型結構圖
3.2.1 信息輸入和編碼層
在信息編碼層,我們首先對五種輸入的信息進行編碼,分別是目標詞、字、語素義、詞義和上下文。
對于目標詞w*和詞中的字Ch={ch1,ch2},我們采用預訓練的詞和字向量來進行編碼,其中,整體的字向量ch*由兩個字向量[ch1;ch2]拼接得到,作為初始輸入。
詞內信息中的語素義Morph={morph1,morph2}、詞義Def和詞間信息的上下文Con屬于長序列輸入。為了更加有效地捕捉到長距離信息,我們利用Bi-LSTM來分別對它們進行編碼,以獲得更豐富的語義信息。LSTM模型輸入向量矩陣,利用遺忘門ft、記憶門it和輸出門ot對隱層狀態hiddent和細胞狀態cellt進行更新,經過下列步驟來獲得隱層向量的表示,如式(2)~式(7)所示。

(8)
其中,dk表示K的維度,用于縮放保持梯度穩定。
通過對語素義Morph、詞義Def和上下文Con進行self-attention后得到語素義編碼,利用Bi-LSTM進行編碼得到輸入,如式(9)~式(12)所示。
mori=Bi-LSTM(Self-Attention([morphi]))
(9)
mor=Wmor([mor1;mor2])+bmor
(10)
con=Bi-LSTM(Self-Attention(Con))
(11)
def=Bi-LSTM(Self-Attention(Def))
(12)
其中;表示向量拼接。最終得到目標詞w*、字ch*、語素義morph、上下文con和詞義def,共五種編碼后的詞內詞間信息,進入信息交互和輸出層。
3.2.2 信息交互和輸出層
在信息交互層,我們使用線性層來融合信息編碼層中獲得的特征,最后通過輸出層計算每種構詞結構的概率分布,并輸出識別概率最高的構詞結構。計算如式(13)、式(14)所示。
k=wk[w*,ch*,mor,con,def]
(13)
α=softmax(k)
(14)
其中,k表示五種詞內和詞間信息通過線性層信息融合的結果,α表示計算得到的構詞結構概率。
4 實驗結果與分析
4.1 實驗設置
4.1.1 實驗數據
我們采用第2節中的數據集,將其按照8:1:1的比例分為訓練集、驗證集與測試集,其統計信息如表6所示。對于多義詞,我們視為不同的詞條,保證每個多義詞僅出現在一個子集里。

表6 數據集統計信息(語素義i表示第i個語素的釋義,長度按句子的平均漢字數計算)
4.1.2 評價指標
構詞結構預測是一種多分類任務,本文使用準確率和F1值作為評價指標。其中,用TP表示預測正確的正例數,TN表示預測錯誤的正例數,FP表示預測正確的負例數,FN表示預測錯誤的負例數,準確率的計算如式(15)所示。
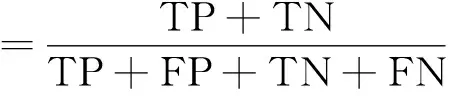
(15)
F1值的計算如式(16)~式(18)所示。

(16)
4.1.3 參數設置
本文使用fastText[48]在中文維基百科上預訓練的詞向量對詞進行初始化,詞向量維度為300,Bi-LSTM隱藏層的維度為300。超參的最優值通過驗證集的結果獲得,訓練的批次大小為128。使用的優化器是Adam,學習率設置為10-3。
4.2 實驗結果與分析
我們首次采用語言學視域下的構詞結構標簽體系進行預測,并重復進行三次實驗取輸出結果的平均值。在驗證集和測試集上的指標如表7所示。
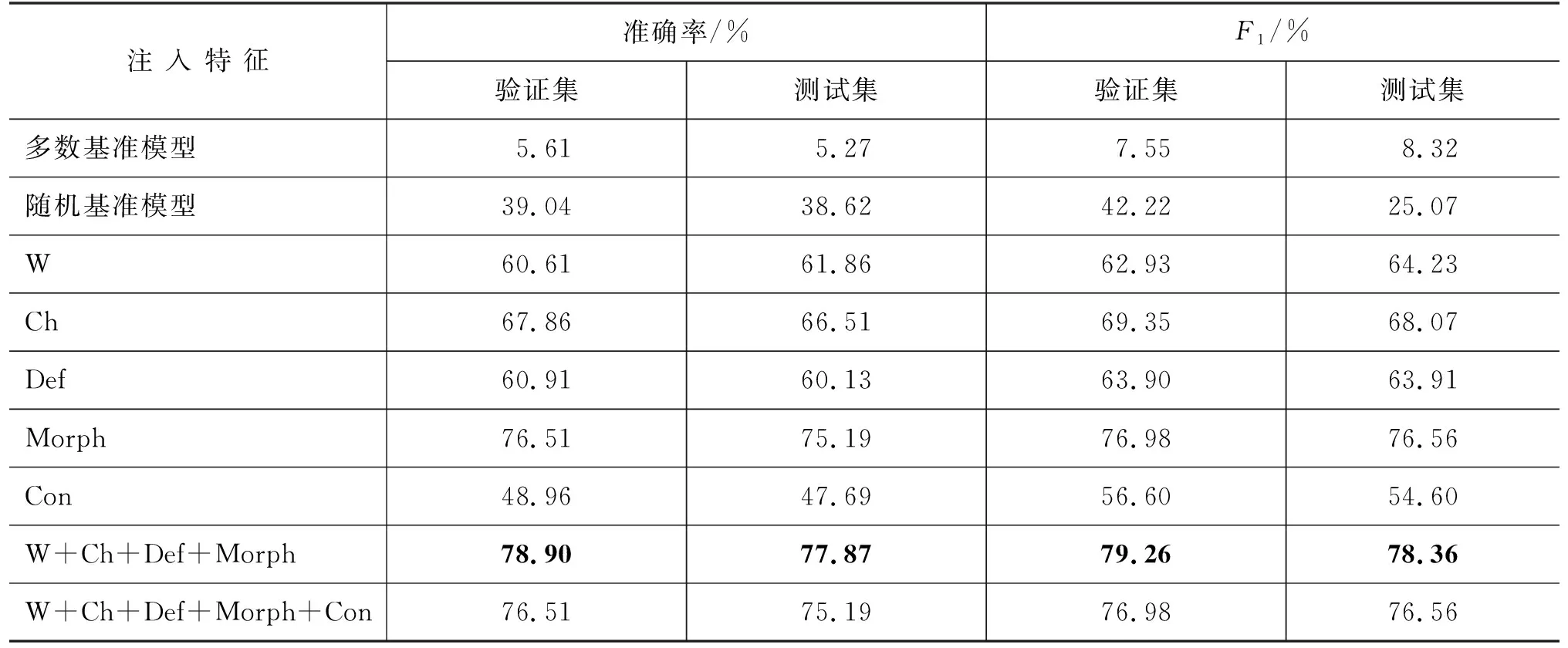
表7 實驗結果
根據表中數據,我們觀察得到如下結論:
(1) 五種詞信息(包括詞內、詞間信息)都能在一定程度上捕捉構詞結構知識,其準確率和F1值遠超隨機基準模型。最佳模型(W+Ch+Def+Morph)取得了良好的構詞結構識別效果,準確率達77.87%,F1值為78.36%,證明了自動構詞結構識別任務的可行性。
(2) 在詞內和詞間信息中,對構詞結構識別效果提升最為明顯的是語素信息(Morph),其次是字(Ch)信息,表現最弱的是上下文信息(Con)。其中,相較于字信息,語素信息在準確率和F1指標上分別有13.05%和12.47%的提升,證明了語素信息能最有效地捕捉到詞內部的構詞結構知識。我們認為上下文信息表現最弱的原因在于其主要包含了詞與詞之間的組合關系,而相對難體現詞內部狀況,因此不容易準確預測構詞結構。
(3) 把使用全部詞內信息(W+Ch+Def+Morph)、使用全部詞間信息(Con)和使用所有詞信息(W+Ch+Def+Morph+Con)的三種模型作比較,結果顯示,僅用詞內信息(W+Ch+Def+Morph)就能達到構詞結構預測的最佳效果。和使用所有詞信息(W+Ch+Def+Morph+Con)相比,使用詞內信息(W+Ch+Def+Morph)在準確率和F1指標上分別有3.56%和2.35%的效果提升。這不僅證明了第2點結論,即上下文信息難以準確識別構詞結構,而且表明了上下文會帶來額外噪聲。
我們根據測試集上的最佳結果制作混淆矩陣,顏色越深代表該類別的概率越高,如圖2所示。
由于不同構詞結構下的詞條的數量差異較大,我們對結果進行歸一化處理。根據圖中趨勢可知:
(1) 對于定中、述賓、聯合、述補、狀中、介賓、后綴、主謂和方位這九類構詞結構,模型的預測準確率較高。“名量”結構的預測準確率最低,可能是由于該結構下的詞條數量最少,在訓練時難以有效捕捉到該構詞結構的特點,因此預測效果較差。“單純”結構的預測準確率次低,可能是該構詞結構代表“詞是獨立的語素”(表1),因此模型同樣無法有效地捕捉到詞的內部結構。
(2) 我們注意到,“連謂”和“重疊”結構經常被錯誤預測為“聯合”結構,這可能是因為“連謂”“重疊”和“聯合”這三種構詞結構在語言學上有很強的關聯和相似性,都隱含有“前后語素地位平等”的意思,而其中“聯合”結構的詞條在訓練數據中占比最高,因此“連謂”和“重疊”結構容易被錯誤預測為“聯合”結構。這一現象符合語言學預期,也從側面表明我們的方法能有效捕捉到構詞結構的隱含特點。
根據第2節前人工作的經驗,以上下文為代表的詞間信息能有效輔助詞義消歧、詞義生成、詞義識別等常見語義任務。然而,對于語言學視域下的構詞結構識別任務,上述的實驗結論表明上下文的貢獻較小。這種情況說明,語義構詞識別任務和其他常見語義任務在性質和特征體現方面有不同的狀況和趨向。
為了進一步探究上下文對于構詞結構識別的有效性,我們額外進行了針對上下文的穩定性實驗。在實際下游任務應用中,可能存在上下文的信息量有限、質量難以保障的情況,因此我們設計了上下文替換模板,將訓練集中的上下文替換成低信息量、低質量的句子。我們使用jieba庫對上下文中的目標詞標注詞性,庫中包含名詞、形容詞、動詞、數詞、方位詞等28種詞性,并針對每種詞性設計了不同的替換模板。以部分詞性為例的上下文替換模板如表8所示。
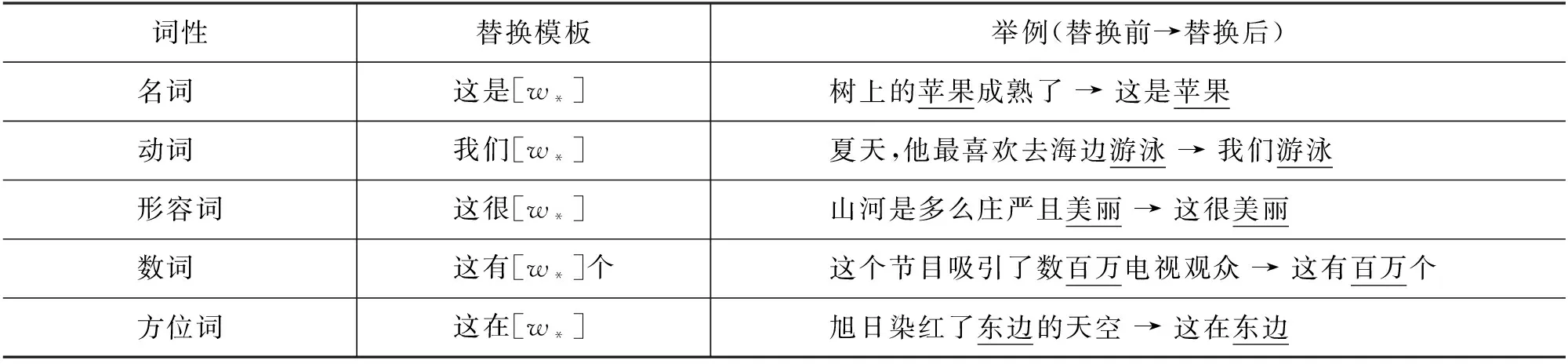
表8 上下文替換模板(其中[w*]和舉例中下劃線的部分表示目標詞)
實驗結果顯示,利用模板替換后,僅用上下文的漢語構詞結構識別在測試集上的準確率為43.62%,F1值為51.38%,相較替換之前分別降低了4.07%和3.22%;用所有詞內和詞間信息的漢語構詞結構識別在測試集上的準確率為71.39%,F1值為73.20%,相較替換之前分別降低了3.80%和3.36%。上述結果表明,雖然上下文能夠提供一定的句法、詞義信息并輔助漢語構詞結構識別,但是其有效性嚴重依賴于上下文的信息量和質量,而這些在實際下游任務應用中無法保障。因此,對于構詞結構識別任務,上下文具有較強的不穩定性,且容易帶來額外噪聲。
4.3 關于模型泛化能力的討論
為驗證本方法的泛化能力,我們進一步在新詞上展開實驗。
新詞的特殊性在于其催生出了新的詞型或義項,也可能衍生出了新的語素義,這些給構詞結構識別帶來了挑戰。為了評估本文方法在新詞構詞結構識別上的效果,我們構建了一個小規模的新詞數據集。其中,新詞及詞義來源于中文維基百科(1)https://dumps.wikimedia.org/zhwiki。我們篩選了維基百科標簽或釋義中帶有“新詞”或“流行語”且未收入《現漢》的詞條,最后選取了覆蓋不同領域的100個詞條。此外,考慮這里面缺少了“名量”等結構的樣例,為了保證數據在構詞結構上的分布一致,我們從王鈞熙[49]的《漢語新詞詞典: 2005-2010》中挑選了特定結構的部分詞條,也加入到數據集中去,共計得到108個新詞。新詞的上下文提取自微博(2)https://weibo.com,并經過人工篩選以保證新詞在上下文中的語義與釋義一致。同時,我們對每個新詞的構詞結構進行了人工標注。
最終,數據集中的每個詞條包含: ①新詞,②構詞結構,③新詞釋義,④語素義,⑤上下文。這些新詞的來源覆蓋了科技、經濟、政治、生活、藝術、體育等多個領域。在表9中,給出了一個新詞的示例,其中“菜”的語素義標注為“(空)”,這是因為目前的《現漢》中缺乏針對此類新衍生出的語素義的定義。

表9 新詞及構詞相關信息示例
實驗結果顯示,使用詞、字、語素義、詞義和上下文信息的方法(W+Ch+Def+ Morph+Con)在新詞測試集上的準確率為68.89%,F1值為67.93%。考慮到上下文信息可能帶來噪聲,去除上下文后,在新詞測試集上的準確率上升到69.92%,F1值上升到68.78%。這兩個實驗結果,遠高于隨機基準模型的效果,且符合主實驗中以往漢語詞匯的表現趨勢,這說明本文方法可以進一步衍生到新詞的構詞結構識別中去。
對比主實驗中以往漢語詞匯上的最佳結果(表7),新詞數據集上的結果分別降低了10.21%(準確率)和12.23%(F1值)。我們猜想,導致這一現象的原因主要有兩方面: 1)大部分新詞存在隱喻、轉喻等非字面義[10],例如,“社畜”表示“社會底層上班族”而非“社會的牲畜”,“巨嬰”表示“心理不成熟的成年人”而非“巨大的嬰兒”。這些非字面義削弱了詞和詞義之間的直接聯系,從而減低了算法中詞義信息表達的有效性; 2)此外,受限于新詞中語素義的新的衍生與發展,部分語素無法在《現漢》中找到對應的語素義。例如,表9中的“菜”,表示“弱;差”的概念,“賣萌”中的“萌”,表示“可愛”的概念,但在目前的《現漢》中均沒有對應的語素義。
這種情況表明,現有語素的語義空間劃分存在缺憾,無法覆蓋新詞中可能衍生出的語素義。在構詞結構識別之后,通過計算性手段,有可能推測出新衍生出的語素義,為漢語語言文字研究和詞典編纂提供幫助。
5 結語
本文旨在探究基于詞信息嵌入的漢語構詞結構識別,我們采用語言學視域下的構詞結構標簽體系,構建漢語構詞結構及相關信息數據集,提出了一種基于Bi-LSTM和self-attention的模型,以此來探究詞內和詞間等多種信息對構詞結構識別的影響,其中,詞內信息包括詞、構詞結構、字、語素義和詞義,詞間信息為上下文。
實驗取得了良好的預測效果,對比測試揭示,詞內的語素義信息對構詞結構識別具有顯著的貢獻,而詞間的上下文信息貢獻較弱,且帶有較強的不穩定性。同時,為了證明模型的泛化能力,我們進一步將模型推廣到新詞的構詞結構識別任務,并取得了良好的效果。
在未來工作中,該預測方法與數據集,將為中文信息處理的多種任務,如語素和詞結構分析、詞義識別與生成、語言文字研究與詞典編纂等提供新的觀點和方案。我們計劃將構詞結構識別融入中文信息處理的下游任務,以進一步提升應用系統的性能。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
開放教育研究(2020年2期)2020-03-31 01:54:14
中華詩詞(2019年7期)2019-11-25 01:43:04
中華手工(2017年2期)2017-06-06 23:00:31
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代語文(2016年21期)2016-05-25 13:13:44
現代企業(2015年9期)2015-02-28 18:56:50
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
