
基于深度學習的單目圖像深度信息恢復
2022-06-23 10:58:12秦文光付新竹
機電工程技術 2022年5期
秦文光,付新竹,張 楠
(1.山西中煤華晉集團公司王家嶺礦,山西運城 043300;2.中國礦業大學,江蘇徐州 221100)
0 引言
隨著計算機視覺技術在日常生活中的普遍應用[1-2],通過算法進行圖像處理在近年獲得極大關注。計算機視覺研究領域的兩大主要任務為物體識別[3-4]和三維重建[5-6],2012 年深度學習興起后,三維重建打開了更為廣泛的思考角度,三維重建的關鍵就是獲取圖像對應的真實深度信息。從圖像中估計場景的深度信息在計算機視覺領域已經探索很久了,在深度學習的推動下應用廣泛。如最近比較流行增強現實和虛擬現實[7],就是借助于場景的深度信息來進行視覺渲染以達到更好的效果。對于更高級的機器視覺任務,如機器人導航[8]和汽車自動駕駛[9-10]的導航定位系統,就是通過場景的深度信息實現精準定位,完成實際導航過程中障礙物躲避和智能路線規劃等任務。
由于卷積神經網絡(Convolution Neural Network,CNN)的進步和發展,單目圖像的深度估計效果逐漸增強,Eigen 和Fergus[11]構建了可獲取全局特征的粗網絡結構和可獲取局部特征的精網絡結構,再聯合兩個架構層獲取的特征得到深度信息。Tompson 等[12]提出了將深度卷積網絡和馬爾科夫隨機場(MRF)進行結合,用于單幅圖像的人體姿態識別。Li 等[13]提出了一種深度卷積神經網絡(DCNN)用于預測圖像的法線和深度信息,使用條件隨機場(CRF)對得到的深度圖進行后處理。Liu 等[14]還提出了一種基于CNN 和CRF 的深度估計方法。Luo W 等[15]提出了一種使用交叉熵的匹配網絡,有助于計算所有像素的浮動差值。Laina 等[16]使用深度殘差網絡進行深度估計,提出了一種在網絡中高效學習特征映射上采樣的方法以提高輸出圖像的分辨率。上述文獻都得到了相對不錯的研究結果,但圖像深度信息恢復網絡中參數量過大導致圖像細節深度信息的丟失進而預測結果準確率不高的問題一直存在。
為了解決上述難題,本文提出一種改進的RG-ResNet網絡模型。將大量的圖像和對應深度信息的數據對輸入到網絡中進行訓練,通過卷積神經網絡自動提取輸入待恢復圖像的特征信息并輸出對應的深度圖,以此實現對輸入的單張RGB 圖像的深度估計,得到準確的圖像深度恢復結果。
1 RG-ResNet網絡模型
分組卷積(Groupable Convolution,GConv)的方式可以大幅降低網絡參數數量,但存在組與組之間信息不相關的缺點。為此,本文提出一種改進的RG-ResNet 網絡模型來實現單目圖像的深度信息恢復。主要研究內容及創新點有:(1)基于分組卷積的思想提出相關聯分組卷積(Related Groupable Convolution,RGConv),解決分組卷積組與組之間信息無法關聯的缺陷,保留分組卷積少參數數量的優勢;(2)基于RGConv 提出改進后的RG-ResNet殘差模塊;(3)結合編-解碼端到端的網絡結構構建RG-ResNet網絡模型。
1.1 相關聯分組卷積
GConv 是當前輕量型網絡設計的核心模塊,簡潔且參數量低。GConv 易于實施,但是通過圖1 所示的分組卷積計算方式發現,每次卷積都是對該組內的信息進行卷積,造成了不同組內的通道數據無關聯。為了提升通道間的相關聯性,同時保留GConv 少參數量和低計算量的優勢,本文提出了一種能夠使得不同分組的通道信息可以交流的分組方式RGConv。
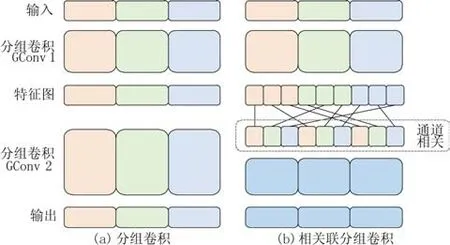
圖1 分組卷積和相關聯分組卷積Fig.1 Groupable convolution and related groupable convolution
圖2 描述了具體的分組規則:將上一層分組卷積的結果進行1~3 標號,后對其每一個標號組續分3 組,同以1~3標號,續分組以其父組號和本身標號組成新的標號按照矩陣排列,根據矩陣中下標不共線規則從左至右連線,組成新的排序組進行后續的卷積操作。圖1 右圖同樣經過GConv1得到對應的特征圖,將得到的三組特征繼續劃分為3組,然后根據圖2所示的分組規則進行對應組合,最終使得輸出結果可融合不同組的通道信息。

圖2 相關聯卷積分組規則Fig.2 Grouping rules ofrelated Convolution
1.2 RG-ResNet殘差模塊
ResNet 深層殘差結構用于降維和升維的1*1 卷積實質上是特殊的GConv,相當于對輸入特征圖的每個通道都分配了一個通道數為1的1*1卷積核進行卷積。因此基于ResNet 的殘差網絡模塊增加RGConv 結構,改進后的模塊如圖3 中左圖(stride=1)所示,將ResNet 中的1*1卷積全部替換為RGConv,將原有的3*3 卷積替換為GConv,即為所提的RG-ResNet殘差模塊。

圖3 RG-ResNet殘差模塊Fig.3 Residual structure of RG-ResNet
圖3 所示分別為stride=1 和stride=2 的殘差結構,stride=1 為左圖,主分支通過1*1 的RGConv 的具體操作為:首先通過分組數為輸入通道數的GConv,而后通過相關聯分組規則輸出新排列的通道組。輸出經過BN 層和ReLU 激活函數后,進行3*3的分組卷積(分組數為輸入通道數),再次經過BN 層后進行1*1 的RGConv,與側分支的輸入通道進行同維度的相加,結果經過ReLU 激活函數輸出。右圖為當stride=2 時的RG-ResNet 殘差結構,輸入首先通過主分支同stride=1 的結構,側分支將上一層的輸出進行平均池化操作,而后與stride=1 的結構不同在于這里主、側分支進行通道拼接而非同維度的相加操作,拼接后的結果經過ReLU激活函數輸出。
1.3 網絡結構
網絡整體結構如圖4所示,采用編-解碼結構進行網絡搭建。編碼部分采用RG-ResNet 殘差結構堆疊進行特征提取,解碼結構采用上采樣逐步恢復圖像的細節特征和空間分辨率。

圖4 RG-ResNet整體結構Fig.4 The structure of RG-ResNet
1.3.1 編碼器構建
網絡的編碼器部分采用所提的RG-ResNet 殘差模塊進行多次疊加,不斷增加網絡深度用于提取圖像特征。本文采用50 層的殘差網絡的設計方式,對RG-ResNet 殘差模塊進行疊加操作,網絡結構如圖5所示。

圖5 編碼器結構Fig.5 Encoder structure
RG-ResNet 的兩種殘差模塊,經過第一個殘差模塊(黃色模塊)時的1*1卷積并非分在經組卷積,因為此時的網絡輸入通道數量較少。再對RG-ResNet 中stride=1(綠色模塊)和stride=2(藍色模塊)進行如圖5 所示的疊加,構成編碼器實現對圖像的特征提取,編碼部分詳細參數如表1所示。

表1 編碼器網絡參數Tab.1 Encoder parameters
1.3.2 解碼器構建
輸入圖像經過前述編碼模塊提取輸入圖像的特征信息,但是由于經過多層卷積,特征圖的分辨率較低,輸出的尺寸過小,需要將圖像恢復到原來的尺寸,選用反池化+卷積的上采樣操作擴大圖像分辨率,流程如圖6所示。將分辨率較低的特征圖通過U1進行反池化操作,池化索引采用圖6標識的位置增補0的2×2像素塊。反池化操作后的結果進行卷積核為5*5 的卷積C1、C3 操作,經過BN歸一化和ReLU激活函數進行處理,經過C1操作后的特征圖再次進行C3的卷積核為3*3的卷積操作,將C3和C2 處理后的結果進行同維度的通道相加后經過ReLU激活函數,得到分辨率較高的特征圖輸出結果。

圖6 上采樣結構Fig.6 Upsampling structure
1.3.3 損失函數
Huber 損失函數又為平滑平均絕對誤差損失函數,能夠比較清晰地估計出圖像中物體的深度信息,對異常值處理更加魯棒。Huber損失函數如式(1)所示。


式中:f(xi)為估計值;Yi為目標值;λ為超參數取λ=0.15; 設 置c的 值 如 式(2); 令a=f(xi)-Y,c=
2 實驗結果
實驗設備選取型號NVIDIA GTX 1080Ti 顯卡的計算機,操作系統為Ubuntu18.04,選擇Pytorch 深度學習框架。訓練初始學習率(learning rate)設為0.000 1,訓練衰減因子α=0.999。預設批量處理大小(batch size)為8,最大迭代次數(max epoch)為20,損失函數使用Huber損失函數,最終訓練模型參數總數量為25 M。訓練過程中對前幾層的模型權重進行凍結不訓練,同時進行數據增強,避免過擬合,提升訓練效果。
2.1 評價標準
根據目前單目圖像深度信息恢復采用的最通用評價指標進行對所提出的網絡框架進行評估,通用的評估方式[11]為:均方根誤差(Root Mean Squared Error,RMSE);平均對數誤差(Root Mean Squared log Error,RMSElog);平均相對誤差(Average Relative Error,Abs-REL);準確度(Accuracy)。
2.2 不同網絡對比實驗與分析
將所提出的網絡與目前已有的單目圖像深度信息恢復的編-解碼結構網絡架構進行比對。本文提出的方法與單目圖像深度信息恢復的前沿方法[13-14,16]均采用NYU Depth V2 包含659 張圖像對的室內場景進行對比測試,實驗結果如表2 所示。對表中分析,本文所提方法能夠在保證精度的前提下有效地降低錯誤率。雖然該方法[13-14,16]在3 種誤差評估方面都達到了近期較高水平,但本文提出的模型在均方根誤差上比表中效果最佳的Laina 等[16]的方法提高了19.8%,同時平均相對誤差高于表中最優數據3%,相比之下本文提出的方法要優于表中的其他方法。

表2 本文方法與其他方法的定量結果對比Tab.2 Comparison of network quantitative proposed by this paper and others
由于該方法[16]在單目圖像深度估計的實驗結果最優,采用此方法與本文提出的方法進行定性實驗比對,如圖7 所示。圖中Laina 等[16]所提網絡的實驗結果整體預測準確,但是圖中物體邊緣模糊且輪廓不夠清晰,在物體細節和邊緣的深度信息恢復上存在信息丟失、錯誤等缺陷。相較而言,本文所提方法在框線內一些細節(如桌子、沙發、柜子、門框等)的深度信息恢復中,可得到較為準確的結果,保證了深度信息恢復的完整性和準確性。綜上,本文提出的方法能夠實現單目圖像的深度信息恢復,同比于目前其他先進算法,準確率占優同時保證了場景細節深度信息的準確恢復。

圖7 不同網絡深度信息恢復結果對比Fig.7 Comparison of information recovery results of different network depths
3 結束語
為了解決目前圖像深度信息恢復網絡中參數量過大的難題提出RG-ResNet,用于實現單目圖像的深度信息恢復,本文結合編-解碼結構,提出了兩個單目圖像深度信息恢復的網絡模型。
本文首先提出了RGConv 的卷積方式,其保留了分組卷積低參數量的優勢,同時彌補了組與組之間通道信息無關聯的缺陷,而后基于RGConv 對ResNet 殘差模塊進行改進,構建RG-ResNet 網絡模型。實驗結果表明,在基于NYU Depth V2 數據集上RG-ResNet 網絡效果更好,并且與目前先進算法相比在圖像物體邊界、局部細節深度信息的恢復方面能夠達到較好的效果。
在實際應用場景中,不同的天氣環境、硬件等因素都會對網絡的預測結果造成直接的影響,并且目前一個功能的應用都是多種算法的相互配合,這就要求單一算法能夠實現更加穩定準確的輸出,本文在對網絡的穩定性和魯棒性方面的實驗不足,因此下一步將加入實際場景影響因素的考慮和硬件優化的處理,進一步驗證所提出方法的實際可應用性。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
新聞傳播(2015年10期)2015-07-18 11:05:40
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
