非自回歸翻譯模型在蒙漢翻譯上的應(yīng)用
2022-06-23 06:25:08蘇依拉仁慶道爾吉
計(jì)算機(jī)工程與應(yīng)用 2022年12期
趙 旭,蘇依拉,仁慶道爾吉,石 寶
內(nèi)蒙古工業(yè)大學(xué) 信息工程學(xué)院,呼和浩特 010080
機(jī)器翻譯(machine translation,MT)[1],是指借助計(jì)算機(jī)處理將一種自然語(yǔ)言(源語(yǔ)言)轉(zhuǎn)換為另一種自然語(yǔ)言(目標(biāo)語(yǔ)言)的過(guò)程,它屬于計(jì)算語(yǔ)言學(xué)研究的范圍。自20世紀(jì)30年代機(jī)器翻譯嶄露頭角開(kāi)始,機(jī)器翻譯的發(fā)展已經(jīng)越來(lái)越迅猛。在當(dāng)今的日常生活、學(xué)習(xí)生活中,已經(jīng)越來(lái)越離不開(kāi)機(jī)器翻譯的支持,其對(duì)于促進(jìn)文化交流、促進(jìn)多元交流有著十分重要的作用。目前機(jī)器翻譯的發(fā)展歷程經(jīng)歷了基于規(guī)則的機(jī)器翻譯到基于統(tǒng)計(jì)的機(jī)器翻譯[2],再到如今基于神經(jīng)網(wǎng)絡(luò)的機(jī)器翻譯(neural machine translation,NMT),每一次的改進(jìn)極大地推動(dòng)了機(jī)器翻譯領(lǐng)域的飛速發(fā)展。
蒙語(yǔ)機(jī)器翻譯的研究最早在20世紀(jì)90年代提出了基于詞典和基于規(guī)則的翻譯方法,主要是研究日蒙機(jī)器翻譯的研究[3]。蒙漢機(jī)器翻譯的研究對(duì)推動(dòng)內(nèi)蒙古自治區(qū)的信息化、促進(jìn)自治區(qū)社會(huì)進(jìn)步和經(jīng)濟(jì)發(fā)展、繁榮和發(fā)展少數(shù)民族文化教育科技事業(yè)有著重要的意義,眾多學(xué)者也提出了很多改進(jìn)蒙漢翻譯的方法[4-6]。在當(dāng)前流行的翻譯模型中,大多為編碼器-解碼器架構(gòu)的翻譯模型,且屬于自回歸翻譯模型(autoregressive model)[7],自回歸翻譯模型在進(jìn)行解碼時(shí),它們根據(jù)之前生成的序列生成當(dāng)前序列,這個(gè)過(guò)程是不可并行的。
雖然當(dāng)前主流翻譯模型大多為自回歸模型,也在眾多生成任務(wù)中得到了廣泛的應(yīng)用,但是自回歸翻譯模型在蒙漢翻譯過(guò)程中也存在著顯著的不足:
蒙語(yǔ)語(yǔ)料較為匱乏,使用當(dāng)前的翻譯模型易導(dǎo)致數(shù)據(jù)稀疏和過(guò)擬合問(wèn)題,語(yǔ)義信息的匱乏會(huì)影響上下文信息的依賴(lài)關(guān)系,進(jìn)而造成蒙漢翻譯質(zhì)量不高[8]。
自回歸模型的解碼過(guò)程是串行輸出的,當(dāng)前序列依賴(lài)于之前生成的序列,導(dǎo)致生成時(shí)間復(fù)雜度比較高,一般借助GPU生成也需要很長(zhǎng)的時(shí)間。
1 神經(jīng)機(jī)器翻譯模型
當(dāng)前流行的神經(jīng)機(jī)器翻譯模型,大多為編碼器-解碼器結(jié)構(gòu),其流程為:將語(yǔ)料進(jìn)行預(yù)處理,借助編碼器編碼生成向量,借助解碼器對(duì)向量以及源語(yǔ)言信息進(jìn)行處理,得到目標(biāo)語(yǔ)言的翻譯結(jié)果。
傳統(tǒng)的NMT模型,無(wú)論是基于循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)還是基于Transformer的翻譯模型[9],都可以歸類(lèi)為自回歸模型。這里的自回歸指的是在翻譯目標(biāo)語(yǔ)句時(shí),模型是從左到右逐字翻譯的,當(dāng)前字需要依賴(lài)于上一生成的字,這就導(dǎo)致編碼器-解碼器模型進(jìn)行推理生成時(shí),只能逐字翻譯,解碼器不能并行輸出。相比于自回歸翻譯模型,非自回歸翻譯模型克服了自回歸模型性依賴(lài)于上下文輸出的缺陷,借助于編碼器的改進(jìn)實(shí)現(xiàn)了并行輸出,大大提升了生成的速率。同時(shí)借助于跨言詞嵌入[10]和知識(shí)蒸餾技術(shù)[11],對(duì)蒙漢語(yǔ)料進(jìn)行相應(yīng)處理,緩解源與目標(biāo)的依賴(lài)關(guān)系,緩解數(shù)據(jù)稀疏以及過(guò)擬合問(wèn)題等。使非自回歸翻譯模型既有高準(zhǔn)確率也有高生成速率。
在文獻(xiàn)[12]中,基于Transformer翻譯模型進(jìn)行改進(jìn),提出了非自回歸Transformer模型(NAT)在機(jī)器翻譯上的應(yīng)用,在同樣的條件下,相比于Transformer模型,NAT翻譯模型在生成速率上大幅領(lǐng)先Transformer模型,這是因?yàn)閷?duì)編碼器進(jìn)行了改進(jìn),增加了一個(gè)Fertility模塊[13],來(lái)統(tǒng)計(jì)源句每個(gè)詞的出現(xiàn)次數(shù),進(jìn)而得到目標(biāo)句子的長(zhǎng)度,將Fertility與源句子的復(fù)制共同作為解碼器的輸入,實(shí)現(xiàn)翻譯的并行輸出。但也會(huì)導(dǎo)致翻譯準(zhǔn)確率的下降,而借助于知識(shí)蒸餾,將源語(yǔ)言與目標(biāo)語(yǔ)言的依賴(lài)關(guān)系降低,進(jìn)而同步提高翻譯效果與生成速率。故本文基于Transformer和NAT蒙漢翻譯模型,使用內(nèi)蒙古工業(yè)大學(xué)所擁有的120萬(wàn)蒙漢平行語(yǔ)料作為實(shí)驗(yàn)數(shù)據(jù),對(duì)蒙漢語(yǔ)料進(jìn)行通用BPE處理和知識(shí)蒸餾處理做對(duì)比實(shí)驗(yàn)。
1.1 基于Transformer的神經(jīng)機(jī)器翻譯模型
2017年,谷歌提出了一種新的網(wǎng)絡(luò)架構(gòu):Transformer。其完全基于注意力機(jī)制,克服了之前使用的卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)所出現(xiàn)的問(wèn)題,大幅度提升了機(jī)器翻譯的效果。注意力是人類(lèi)特有的一種能力,可以選擇性地選取重點(diǎn),注意力機(jī)制的提出便基于此[14]。Transformer建模公式如式(1)所示:
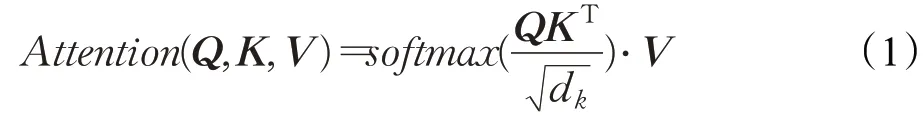
在自注意力層中,每個(gè)單詞有3個(gè)不同的向量來(lái)表示,它們分別是Query向量(Q),Key向量(K)和Value向量(V),長(zhǎng)度均是64,即dk。它們由嵌入向量X乘以三個(gè)不同的權(quán)值矩陣WQ、WK、WV得到,其中三個(gè)矩陣的維度也是相同的,均是512×64。其中為了梯度的穩(wěn)定,Transformer使用了score歸一化,即除以dk,softmax是激活函數(shù),最終計(jì)算結(jié)果表明Q應(yīng)該關(guān)注V中的哪些值,也就是句子中需要重點(diǎn)關(guān)注的語(yǔ)義信息,以及對(duì)應(yīng)語(yǔ)義信息的關(guān)注度達(dá)到多少。
人類(lèi)面對(duì)海量信息時(shí),可以選擇性地捕獲重點(diǎn)信息,忽略掉無(wú)關(guān)信息,來(lái)獲取關(guān)鍵信息。神經(jīng)網(wǎng)絡(luò)在處理大量輸入信息時(shí),也可以借助注意力機(jī)制選擇性地獲取處理一些關(guān)鍵信息,來(lái)提高神經(jīng)網(wǎng)絡(luò)的處理性能,Transformer翻譯模型便是完全基于注意力機(jī)制來(lái)實(shí)現(xiàn)的。圖1為基于注意力機(jī)制的Encoder-Deocder模型的結(jié)構(gòu)[15]。
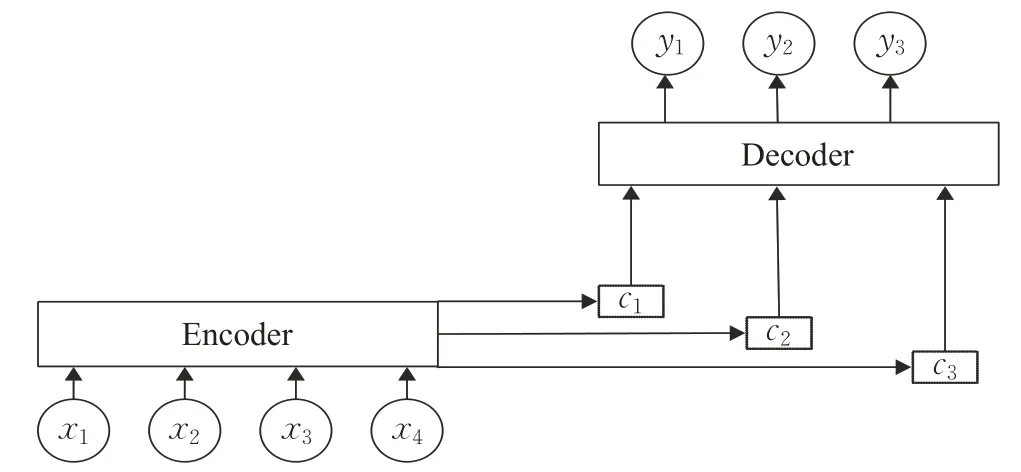
圖1 基于注意力機(jī)制的編碼器-解碼器架構(gòu)圖Fig.1 Encoder-decoder architecture based on attention mechanism
Transformer模型的架構(gòu)也是基于編碼器-解碼器。但其結(jié)構(gòu)相比于之前更加復(fù)雜,包含六層編碼器和六層解碼器。圖2為其基本架構(gòu)圖。
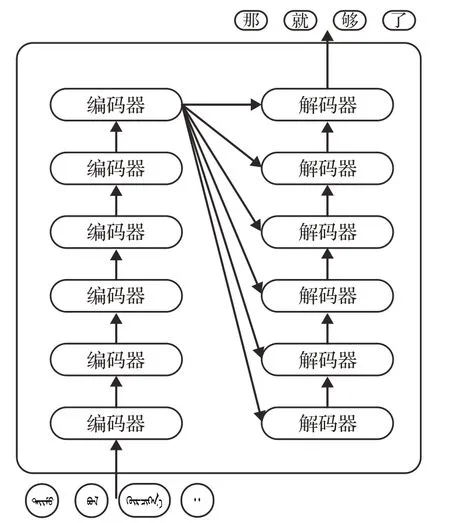
圖2 Transformer基本架構(gòu)圖Fig.2 Architecture of Transformer
對(duì)于每一層的編碼器和解碼器,編碼器包含兩層:自注意力層與前饋神經(jīng)網(wǎng)絡(luò)。自注意力層能夠幫助當(dāng)前節(jié)點(diǎn)結(jié)合上下文語(yǔ)義信息來(lái)獲得正確的語(yǔ)義理解。解碼器除了包含以上兩層外,在兩層的中間還有一層注意力層,幫助當(dāng)前節(jié)點(diǎn)獲取當(dāng)前需要重點(diǎn)關(guān)注的內(nèi)容。圖3為單層編碼器-解碼器的結(jié)構(gòu)。
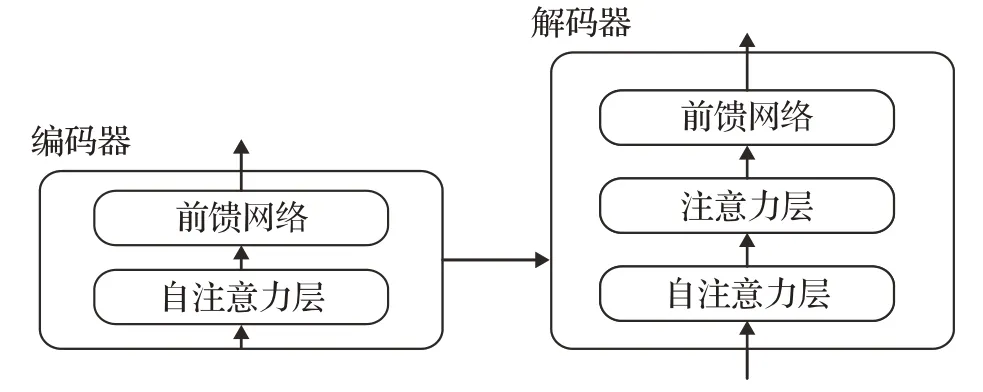
圖3 單層架構(gòu)圖Fig.3 Single layer architecture
模型需要對(duì)輸入的數(shù)據(jù)進(jìn)行一個(gè)生成嵌入向量操作,得到嵌入向量后,輸入到編碼層,自注意力層處理完數(shù)據(jù)后把數(shù)據(jù)輸入到前饋神經(jīng)網(wǎng)絡(luò)中,其計(jì)算過(guò)程可以并行處理,得到的輸出會(huì)輸入到下一個(gè)編碼器。最終編碼完成后,將其輸入到解碼層中,解碼層全部執(zhí)行完畢后,在結(jié)尾通過(guò)一個(gè)全連接層和softmax層,得到最終概率值最大的對(duì)應(yīng)詞就是本文得到的翻譯結(jié)果。具體流程圖見(jiàn)圖4。
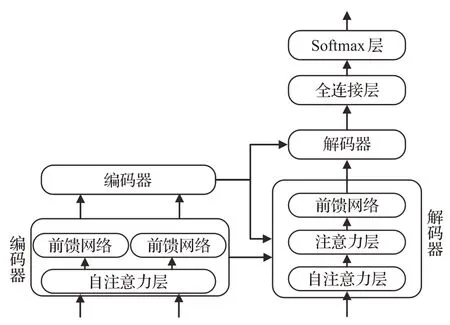
圖4 整體流程圖Fig.4 Overall flow chart
1.2 基于非自回歸Transformer的神經(jīng)機(jī)器翻譯模型
相比于自回歸模型相,非自回歸模型在實(shí)現(xiàn)上主要有以下兩個(gè)區(qū)別:一是解碼器的輸入,二是目標(biāo)序列長(zhǎng)度的獲取。自回歸模型解碼器的輸入是上一步解碼出的結(jié)果,每一步解碼生成都依賴(lài)于上一步解碼的結(jié)果,當(dāng)解碼到EOS標(biāo)志時(shí),序列的生成過(guò)程便自動(dòng)停止,得到最終的解碼序列。而非自回歸模型沒(méi)有這樣的依賴(lài)特性,克服了解碼的串行輸出,實(shí)現(xiàn)了解碼器的并行輸出。圖5為兩者區(qū)別。
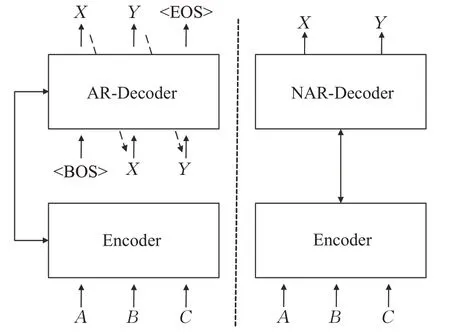
圖5 自回歸與非自回歸模型區(qū)別Fig.5 Differences between autoregressive and non-autoregressive models
NAT翻譯模型采用的也是編碼器-解碼器結(jié)構(gòu),與Transformer相比,是對(duì)編碼器進(jìn)行了改進(jìn),增加了一個(gè)Fertility模塊,來(lái)統(tǒng)計(jì)源句每個(gè)詞的出現(xiàn)次數(shù),進(jìn)而得到目標(biāo)句子的長(zhǎng)度,將Fertility與源句子的復(fù)制共同作為解碼器的輸入,實(shí)現(xiàn)翻譯的并行輸出。圖6為非自回歸Transformer的架構(gòu)。
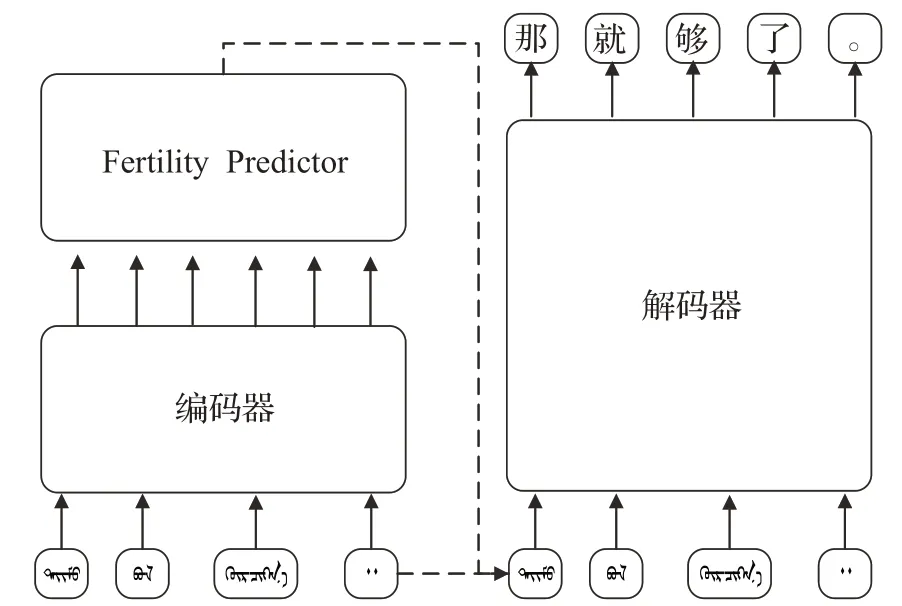
圖6 NAT結(jié)構(gòu)Fig.6 Architecture of NAT
不同于之前所提出的大多數(shù)語(yǔ)言模型,先前的翻譯模型大多為自回歸模型,在進(jìn)行解碼輸出的時(shí)候要根據(jù)先前的輸出來(lái)決定當(dāng)前的輸出,是串行輸出,導(dǎo)致了解碼速度過(guò)慢,而NAT通過(guò)對(duì)編碼器的改進(jìn)解決了這個(gè)問(wèn)題,在基本維持翻譯效果的條件下,大大提升了解碼生成的速度。
2 相關(guān)技術(shù)
2.1 跨語(yǔ)言詞嵌入
在當(dāng)前機(jī)器翻譯研究中,不同語(yǔ)言訓(xùn)練出來(lái)的詞向量雖然是獨(dú)立的,但是它們的分布形態(tài)卻非常相似,兩種語(yǔ)言中意義相近的詞所代表的詞向量在坐標(biāo)空間上的分布非常相近,如圖7所示。
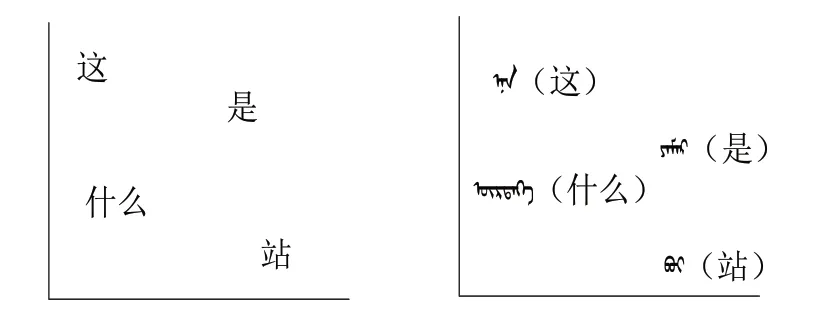
圖7 雙語(yǔ)向量空間分布Fig.7 Bilingual vector space distribution
因此可借助某種線性或非線性的轉(zhuǎn)換[15],將蒙漢雙語(yǔ)的詞向量映射到同一個(gè)共享的空間中,使得意義相近卻來(lái)自不同語(yǔ)言的詞向量具有相近的詞向量表征,縮小兩種語(yǔ)言之間的表征差距。模型可以借助對(duì)方語(yǔ)義信息來(lái)推理詞語(yǔ)含義,可以在雙語(yǔ)之間進(jìn)行知識(shí)遷移,數(shù)據(jù)量少的語(yǔ)言借助高資源語(yǔ)料來(lái)進(jìn)行推理,提高翻譯模型的效果。
為了從源空間映射到目標(biāo)公共空間,一種常見(jiàn)的方法是學(xué)習(xí)一種最小化雙語(yǔ)詞典對(duì)應(yīng)詞對(duì)距離的線性映射。通用的做法是分別獨(dú)立地對(duì)雙語(yǔ)語(yǔ)料進(jìn)行訓(xùn)練[16],得到兩者的嵌入向量,對(duì)其進(jìn)行學(xué)習(xí)訓(xùn)練,得到一種線性映射,使得最小化雙語(yǔ)詞典中列出的等效之間的距離,得到通用向量空間。
設(shè)X和Z表示給定雙語(yǔ)字典的兩種語(yǔ)言中的詞嵌入矩陣,使它們的第i行Xi*和Zi*是字典中第i條的單詞嵌入。本文的目標(biāo)是找到一個(gè)線性變換矩陣W,使XW最接近Z,借助歐氏距離來(lái)進(jìn)行評(píng)估,見(jiàn)式(2):
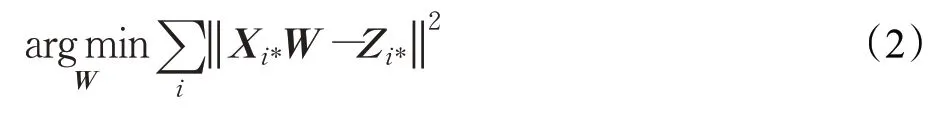
接下來(lái)進(jìn)行最大余弦長(zhǎng)度歸一化處理,將兩種語(yǔ)言中的詞嵌入向量歸一化處理為單位向量,保證了訓(xùn)練實(shí)例對(duì)優(yōu)化目標(biāo)有相同的貢獻(xiàn),見(jiàn)式(3):
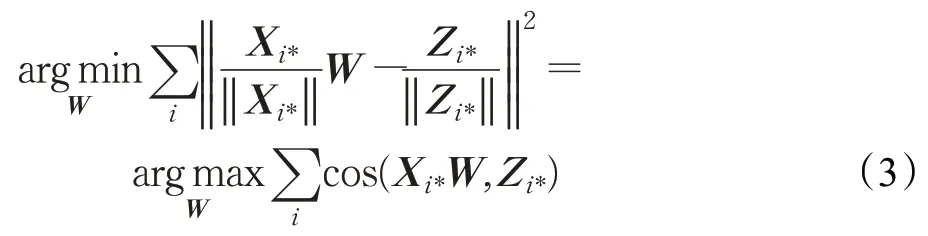
通過(guò)上述操作得到矩陣W來(lái)將兩種語(yǔ)言進(jìn)行嵌入映射,得到跨語(yǔ)言詞向量,縮小兩種語(yǔ)言之間的推理距離[17],提升機(jī)器翻譯的效果。
2.2 知識(shí)蒸餾
雖然NAT模型通過(guò)改進(jìn)編碼器結(jié)構(gòu)實(shí)現(xiàn)了解碼器的并行輸出,大大提升了機(jī)器翻譯的速度,但解碼階段是完全獨(dú)立進(jìn)行的,而在實(shí)際的翻譯中,最終翻譯語(yǔ)句并不是條件獨(dú)立的。條件獨(dú)立性假設(shè)阻止了翻譯模型正確地捕獲目標(biāo)翻譯的高度多模態(tài)分布,模型忽略目標(biāo)語(yǔ)言上下文信息會(huì)導(dǎo)致目標(biāo)語(yǔ)義信息不充足以及翻譯效果的降低。
而知識(shí)蒸餾方法可以在一定程度上解決這個(gè)問(wèn)題,對(duì)數(shù)據(jù)集進(jìn)行知識(shí)蒸餾處理可以在保持原有生成速率的同時(shí),進(jìn)一步提高翻譯的效果。因此,應(yīng)用知識(shí)蒸餾方法,來(lái)改善NAT模型的缺陷。
具體流程如下:首先需要訓(xùn)練一個(gè)自回歸機(jī)器翻譯模型,作為教師模型,在實(shí)驗(yàn)中為了設(shè)置方便,統(tǒng)一采用Transformer模型來(lái)作為教師模型;接下來(lái),借助教師模型在訓(xùn)練集上進(jìn)行集束搜索,構(gòu)建新語(yǔ)料庫(kù),即蒸餾數(shù)據(jù)集;最后將蒸餾數(shù)據(jù)集應(yīng)用在NAT模型(學(xué)生模型)中使用負(fù)對(duì)數(shù)似然(negative log likelihood,NLL)函數(shù)進(jìn)行訓(xùn)練,來(lái)改善NAT模型翻譯效果。其實(shí)現(xiàn)過(guò)程如式(4)~(7)所示:
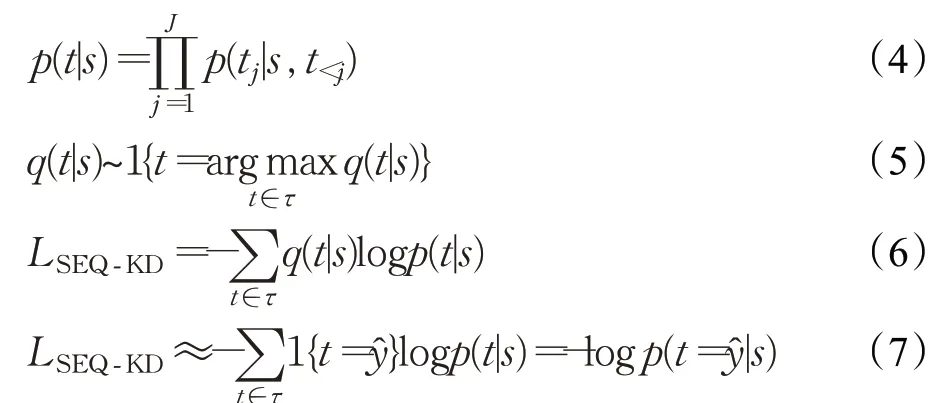
其中,p(t|s)是序列級(jí)分布,q(t|s)是教師模型在可能樣本上的序列分布,對(duì)其取近似值,y?為借助教師模型進(jìn)行集束搜索所生成的蒸餾數(shù)據(jù)集。其流程如圖8所示。
在文獻(xiàn)[18]中,分析了知識(shí)蒸餾方法在機(jī)器翻譯中所起的作用,以及知識(shí)蒸餾如何起到促進(jìn)作用的原因,了解其中的原理對(duì)該文實(shí)驗(yàn)有著極大的積極作用。借助于教師模型的集束搜索對(duì)數(shù)據(jù)集進(jìn)行知識(shí)蒸餾,可以降低數(shù)據(jù)集的復(fù)雜性和減少目標(biāo)端對(duì)上下文的依賴(lài),更好地幫助NAT翻譯模型模擬輸出數(shù)據(jù)的變化,進(jìn)而提升NAT模型的翻譯效果。
3 實(shí)驗(yàn)過(guò)程
3.1 語(yǔ)料劃分及處理
本文實(shí)驗(yàn)所用數(shù)據(jù)為內(nèi)蒙古工業(yè)大學(xué)所擁有的120萬(wàn)蒙漢平行語(yǔ)料,語(yǔ)料庫(kù)的格式為蒙語(yǔ)-漢語(yǔ)的平行語(yǔ)料,在使用之前需對(duì)語(yǔ)料庫(kù)進(jìn)行了篩選,將語(yǔ)料庫(kù)中包含的文章類(lèi)的內(nèi)容進(jìn)行了整理篩選,實(shí)驗(yàn)過(guò)程中沒(méi)有使用文章部分,因?yàn)槲恼虏糠置恳痪渲g上下文之間都存在依賴(lài)關(guān)系,對(duì)于非自回歸模型并不友好,不能較好地實(shí)現(xiàn)非自回歸模型的并行,故排除掉文章內(nèi)容后進(jìn)行語(yǔ)料劃分。蒙漢平行語(yǔ)料數(shù)據(jù)集的劃分如表1所示。

表1 數(shù)據(jù)集劃分Table 1 Dataset partition
3.2 語(yǔ)料預(yù)處理
數(shù)據(jù)集劃分完后,需對(duì)語(yǔ)料進(jìn)行預(yù)處理,在本實(shí)驗(yàn)中對(duì)中文進(jìn)行分詞處理,分詞流程包含停用詞表的加載,將標(biāo)點(diǎn)、語(yǔ)氣助詞、副詞等出現(xiàn)頻率很高的詞進(jìn)行篩選清除,降低停用詞對(duì)有效信息產(chǎn)生的干擾。在蒙漢語(yǔ)料中適度地減少停用詞的次數(shù),可以提高關(guān)鍵詞的分布密度,使關(guān)鍵詞語(yǔ)義信息更集中,更突出,對(duì)后續(xù)機(jī)器翻譯性能的提高有一定幫助。
處理完中文分詞后,借助字節(jié)對(duì)編碼(byte pair encoder,BPE)方法對(duì)蒙漢平行語(yǔ)料進(jìn)行處理[19]。BPE是一種根據(jù)字節(jié)對(duì)進(jìn)行編碼的算法。BPE處理的主要目的是為了數(shù)據(jù)壓縮,將字符串里頻率出現(xiàn)最高的一對(duì)字符被一個(gè)沒(méi)有在當(dāng)前字符串出現(xiàn)過(guò)的字符代替,不斷迭代。通過(guò)BPE處理后,可以大大降低數(shù)據(jù)稀疏以及未登錄詞問(wèn)題對(duì)翻譯效果的影響。
首先,BPE算法會(huì)將訓(xùn)練語(yǔ)料以字符為單位進(jìn)行拆分,按照字符對(duì)進(jìn)行組合,并對(duì)所有組合的結(jié)果根據(jù)出現(xiàn)的頻率進(jìn)行排序,出現(xiàn)頻次越高的排名越靠前,排在第一位的是出現(xiàn)頻率最高的子詞,最終會(huì)根據(jù)語(yǔ)料生成codec文件。Codec文件分布如圖9所示。

圖9 蒙漢codec文件Fig.9 Codec file of Mongolian and Chinese
根據(jù)生成的蒙漢雙語(yǔ)codec文件,對(duì)蒙漢語(yǔ)料進(jìn)行處理,最終得到完整的BPE處理后的語(yǔ)料庫(kù)。處理完畢的語(yǔ)料如圖10所示。

圖10 BPE處理后語(yǔ)料Fig.10 Processing of BPE corpora
對(duì)蒙漢語(yǔ)料庫(kù)進(jìn)行BPE處理,也就是對(duì)蒙漢平行進(jìn)行標(biāo)記和分段后,借助BPE生成的子詞(subwords)詞典,使用上述提到的跨語(yǔ)言詞嵌入方法,對(duì)蒙漢語(yǔ)料進(jìn)行映射處理,通過(guò)線性變換得到蒙漢雙語(yǔ)嵌入詞向量,來(lái)充分利用兩種語(yǔ)言在同一向量空間分布的相近性,提升蒙漢機(jī)器翻譯的準(zhǔn)確率。
4 實(shí)驗(yàn)部分
4.1 實(shí)驗(yàn)設(shè)置
本次實(shí)驗(yàn)所用的Transformer翻譯模型以及非自回歸Transformer翻譯模型借助Facebook AI實(shí)驗(yàn)室提出的開(kāi)源庫(kù)Fairseq(https://github.com/pytorch/fairseq)。借助內(nèi)蒙古工業(yè)大學(xué)提供的GPU服務(wù)器進(jìn)行實(shí)驗(yàn),GPU型號(hào)為NVIDIA Tesla P100。實(shí)驗(yàn)環(huán)境為Ubuntu16.04,Linux系統(tǒng),Python版本3.7.0,TensorFlow版本1.13.0,借助BLEU值來(lái)評(píng)估翻譯效果,同時(shí)對(duì)翻譯模型解碼時(shí)間進(jìn)行記錄。
Transformer Transformer神經(jīng)網(wǎng)絡(luò)層數(shù)設(shè)置為6層,多頭注意力機(jī)制設(shè)置為8頭,隱藏單元維度設(shè)置為512,激活函數(shù)使用GELU,優(yōu)化函數(shù)使用Adam算法,初始學(xué)習(xí)率設(shè)置為0.01,Label Smoothing設(shè)置為0.1,一階矩估計(jì)的指數(shù)衰減率設(shè)置為0.9,二階矩估計(jì)的指數(shù)衰減率設(shè)置為0.95,train_steps設(shè)置為200 000,batch_size設(shè)置為4 096。
非自回歸Transformer神經(jīng)網(wǎng)絡(luò)層數(shù)設(shè)置為6層,多頭注意力機(jī)制設(shè)置為8頭,隱藏單元維度設(shè)置為512,優(yōu)化函數(shù)使用Adam算法,激活函數(shù)使用GELU,初始學(xué)習(xí)率設(shè)置為0.01,dropout設(shè)置為0.1,fine-tuning設(shè)置為0.25。PyTorch0.3,torchtext0.2.1,train_steps設(shè)置為200 000,warmup_steps設(shè)置為4 000,batch_size設(shè)置為2 048。同時(shí)借助IBM Model 2提供的Fast_Align(https://github.com/fast_Align)來(lái)實(shí)現(xiàn)編碼器Fertility模塊的改進(jìn)。
4.2 實(shí)驗(yàn)結(jié)果
如圖11、圖12所示,本文分別統(tǒng)計(jì)了基于Transformer神經(jīng)機(jī)器翻譯模型,基于非自回歸Transformer神經(jīng)機(jī)器翻譯模型以及進(jìn)行知識(shí)蒸餾處理后非自回歸Transformer模型在200 000訓(xùn)練步數(shù)上的BLEU值變化趨勢(shì),同時(shí)統(tǒng)計(jì)了三組翻譯模型在實(shí)驗(yàn)過(guò)程中所消耗的時(shí)間變化趨勢(shì),來(lái)對(duì)實(shí)驗(yàn)進(jìn)行完整的分析。
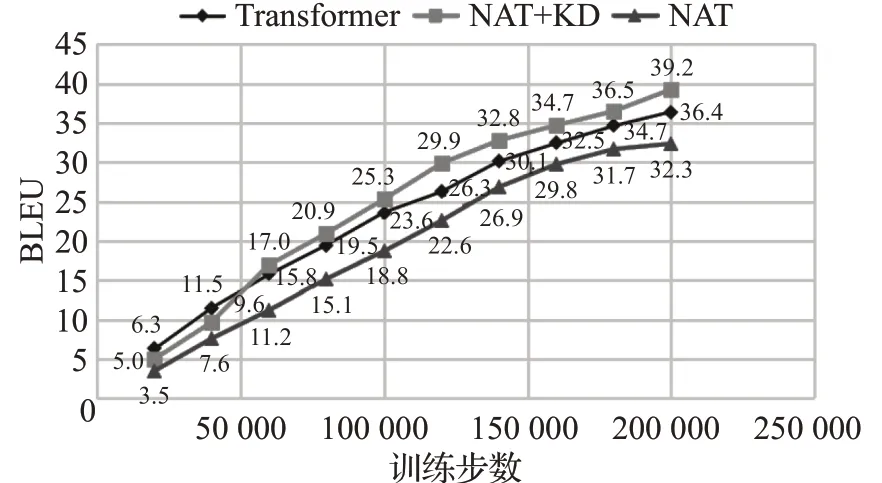
圖11 三組實(shí)驗(yàn)?zāi)P虰LEU值變化趨勢(shì)Fig.11 Change trend of BLEU value in three experimental groups
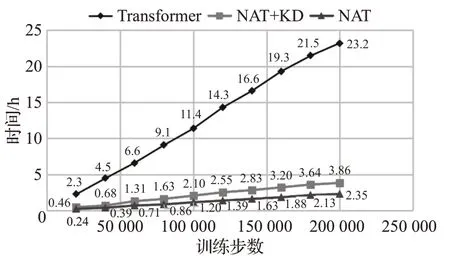
圖12 三組實(shí)驗(yàn)?zāi)P拖臅r(shí)間變化趨勢(shì)Fig.12 Time consumption trends of three experimental models
表2是基于Transformer神經(jīng)機(jī)器翻譯模型,基于非自回歸Transformer神經(jīng)機(jī)器翻譯模型以及進(jìn)行知識(shí)蒸餾處理后的非自回歸Transformer神經(jīng)機(jī)器翻譯模型在測(cè)試集得到的BLEU值以及消耗時(shí)間。
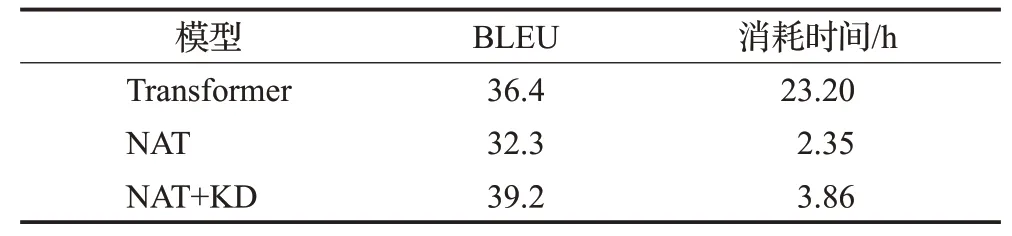
表2 三組翻譯模型BLEU值和消耗時(shí)間Table 2 BLEU and time consumption of three translation models
表2可以得到基于Transformer翻譯模型的BLEU值為36.4,消耗時(shí)間為23.2 h,非自回歸Transformer翻譯模型的BLEU值為32.3,消耗時(shí)間為2.35 h,而進(jìn)行知識(shí)蒸餾處理后的非自回歸Transformer翻譯模型的BLEU值達(dá)到了39.2,相比于Transformer翻譯模型提高了2.8個(gè)BLEU值,消耗時(shí)間為3.86 h,大致為T(mén)ransformer模型的1/8。
圖11、圖12和表2表明進(jìn)行了知識(shí)蒸餾處理后的非自回歸Transformer翻譯模型,在保留非自回歸Transformer翻譯模型耗時(shí)短優(yōu)點(diǎn)的同時(shí),也提高了最終蒙漢翻譯的準(zhǔn)確率,相比于Transformer翻譯模型,用時(shí)大大降低,同時(shí)BLEU值得到了2.8的提升。實(shí)驗(yàn)表明對(duì)語(yǔ)料進(jìn)行知識(shí)蒸餾處理可以有效解決非自回歸Transformer翻譯模型的缺點(diǎn),降低依賴(lài)性,在維持低耗時(shí)的前提下,進(jìn)一步提升蒙漢翻譯的效果。
5 結(jié)束語(yǔ)
當(dāng)前蒙漢機(jī)器翻譯研究中,大多數(shù)翻譯模型的計(jì)算成本很高,獲得高翻譯效果的同時(shí),消耗時(shí)間也是飛速增長(zhǎng),而非自回歸Transformer翻譯模型的提出可以有效解決這個(gè)問(wèn)題,縮短消耗時(shí)間,但會(huì)導(dǎo)致翻譯效果的下降這個(gè)新問(wèn)題的出現(xiàn)。所以本文主要針對(duì)于NAT翻譯模型,研究跨語(yǔ)言詞嵌入[20]和知識(shí)蒸餾在翻譯過(guò)程中所起到的作用,通過(guò)對(duì)各方法的實(shí)驗(yàn)結(jié)果進(jìn)行對(duì)比分析。實(shí)驗(yàn)結(jié)果表明進(jìn)行了知識(shí)蒸餾處理的NAT翻譯模型在維持低耗時(shí)的前提下,相比于Transformer翻譯模型提升了蒙漢翻譯的效果。但知識(shí)蒸餾處理也存在不足之處,知識(shí)蒸餾將源語(yǔ)言與目標(biāo)語(yǔ)言的依賴(lài)關(guān)系降低,這就使得在翻譯生成時(shí),可能會(huì)造成部分語(yǔ)義信息不足的問(wèn)題,所以在接下來(lái)的研究中,考慮是否可以將無(wú)監(jiān)督知識(shí)蒸餾方法[21]和源-目標(biāo)語(yǔ)料對(duì)齊加入到模型訓(xùn)練中,融合更多語(yǔ)義信息,進(jìn)一步提升蒙漢翻譯的效果,這是未來(lái)工作的著重點(diǎn)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
少先隊(duì)活動(dòng)(2021年4期)2021-07-23 01:46:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
沈陽(yáng)醫(yī)學(xué)院學(xué)報(bào)(2015年1期)2015-12-27 13:44:40
