基于LLVM的C/C++隱式類型轉換安全性檢測
2022-06-24 10:01:42劉嘉華鄂龍慧
計算機應用與軟件 2022年4期
關鍵詞:檢測
萬 明 劉嘉華 鄂龍慧 朱 江
(南京南瑞信息通信科技有限公司 江蘇 南京 210003)
0 引 言
現代編程語言通過部署類型系統來控制對象使用和錯誤檢測[1]。類型系統可以分為靜態類型、動態類型、強類型和弱類型。由于C/C++是靜態弱類型語言,允許通過默認或強制的方式轉換變量的類型,因此只能依賴于編程人員良好的編程能力和習慣來避免在運行時引入類型錯誤,從而避免出現安全問題。然而編程人員水平參差不齊,且在開發過程中難免會有所疏忽,所以由類型錯誤所引起的安全問題屢見不鮮。據統計,微軟公司所有軟件已發現的代碼執行漏洞中大約有75%是類型和內存錯誤[2]。市場占有率高達63.16%的谷歌瀏覽器被發現了存在于Histogram組件中的編號CVE-2017-5023的類型混淆漏洞,該漏洞允許遠程攻擊者通過發送一個精心構造的網頁來執行受害者電腦上的任意代碼[3]。同年,在蘋果瀏覽器Safari內核的webkit組件中也發現了編號為CVE-2017-2415的類型混淆漏洞,使得幾乎所有的蘋果設備都受到了威脅[4]。由此可見,類型轉換問題不能完全依賴于編程人員的編程技能和人為審計來規避,研發一個有效的針對性的檢測方法是很有必要的,這將在很大程度上幫助編程人員規避軟件中的安全隱患,增強軟件的健壯性。
為此,本文借鑒了動態類型語言Python語言和Go語言中的類型系統[5],提出了一種針對C/C++隱式類型轉換產生的類型安全問題的編譯期檢測方法。該方法在編譯期作用于LLVM中間代碼,對代碼中的隱式類型轉換操作進行檢測,若匹配到相應的模式即給出必要的提示或終止編譯過程。實現上,我們將該方法編譯為一個動態鏈接庫文件,通過LLVM opt工具加載動態鏈接庫來對代碼進行類型轉換安全性檢測。
1 相關工作
面對如今動輒上百甚至數千萬行代碼的重量級軟件,編譯器在處理一些類型轉換錯誤時缺乏必要的提示,使得編程人員很難在代碼海洋里揪出這些不起眼的錯誤。因此,人們開始著眼于構建一個類型轉換錯誤檢測工具,以幫助編程人員在開發過程中規避由類型問題引發的安全隱患。這些工具大體可以分為兩個類別:基于嵌入對象中的vtable指針的方法[6-9]和基于不相交元數據的方法[10-12]。
基于vtable指針的解決方案無須跟蹤活動對象,但具有根本的局限性,即它們不支持不具有vtable的非多態類。UBSan[6]使用靜態強制轉換執行顯式的運行時檢查,從而有效地將其轉換為動態強制轉換。為防止非多態類失敗,UBSan需要手動將其列入黑名單。然而,C++編譯器中可用的現有類型檢查基礎結構本質上很慢(因為它是在假設只有很少的動態檢查會被執行且大多數檢查是靜態的前提下設計的),因此UBSan由于開銷過大僅被用作測試工具,而不是一個在線檢測工具。Clang控制流完整性(CFI)[8]旨在提高速度,但尚未發布性能數據。而且,像該組中的所有解決方案一樣,它不能支持非多態類。
基于不相交元數據的方法最早出現的是CaVer[10]。代替手動列入黑名單的方式,CaVer使用不相交的元數據來支持非多態類。然而,由于元數據跟蹤效率低(尤其是在堆棧上)且檢查速度較慢,因此該方法開銷仍然過高,對于某些瀏覽器基準測試,這種開銷高達100%。此外,該方法無法處理線程之間共享的堆棧對象且在對象分配范圍上表現較差,最終導致類型混淆檢測范圍減小。
TypeSan[11]實現了一個sanitizer編譯器組件,為程序添加了獨立設計的元數據類型來記錄類型跟蹤信息,在編譯期間為程序插入額外代碼片,這些代碼片段在運行時跟蹤C++程序中所有cast操作相關的類型轉換操作,能夠檢測出C++中cast操作符使用不當的情形。與CaVer相比,提升了3~6倍的性能,但是仍具有較大的時間開銷和內存開銷(4~10倍基準值)。
HexType[12]在TypeSan的基礎上,改進了記錄類型跟蹤信息的元數據,并嚴格區分了安全cast和不安全cast,對C++中的cast操作符有選擇地進行跟蹤,做到了比TypeSan更高效的cast錯誤檢測。但是,和TypeSan一樣仍然是給程序插入額外的代碼片段,在運行時檢測類型轉換錯誤中的其中一種情形(cast操作符的使用不當)。
綜上所述,現有的工具大多集中于檢測C++中cast操作符的使用不當,新出現的方法主要仍在改進cast操作符使用不當的檢測過程中的效率問題,面對更為普遍存在的隱式類型轉換,仍沒有一種有效的方法來檢測其是否安全合理。
2 技術背景
2.1 類型轉換
類型轉換分為顯式類型轉換和隱式類型轉換。C++中,顯式類型轉換對應四種cast轉換操作符:static_cast、dynamic_cast、const_cast和reinterpret_cast。四種不同的cast操作允許編程人員對變量進行強制類型轉換以滿足開發過程中的不同需求。如果cast操作選擇不當將會產生安全隱患。顯式類型轉換錯誤示例如下:
1 class Parent
2 {
3 int x;
4 };
5 class Son : Parent
6 {
7 double y;
8 };
9 Parent *p=new Parent();
10 Son *s;
11 s=static_cast
12 s→y;
該示例通過子類指針s錯誤訪問父類成員x。cast操作符將int類型轉換為double類型,使得子類s可以訪問比x更大的未初始化空間,造成圖1所示的越界讀。
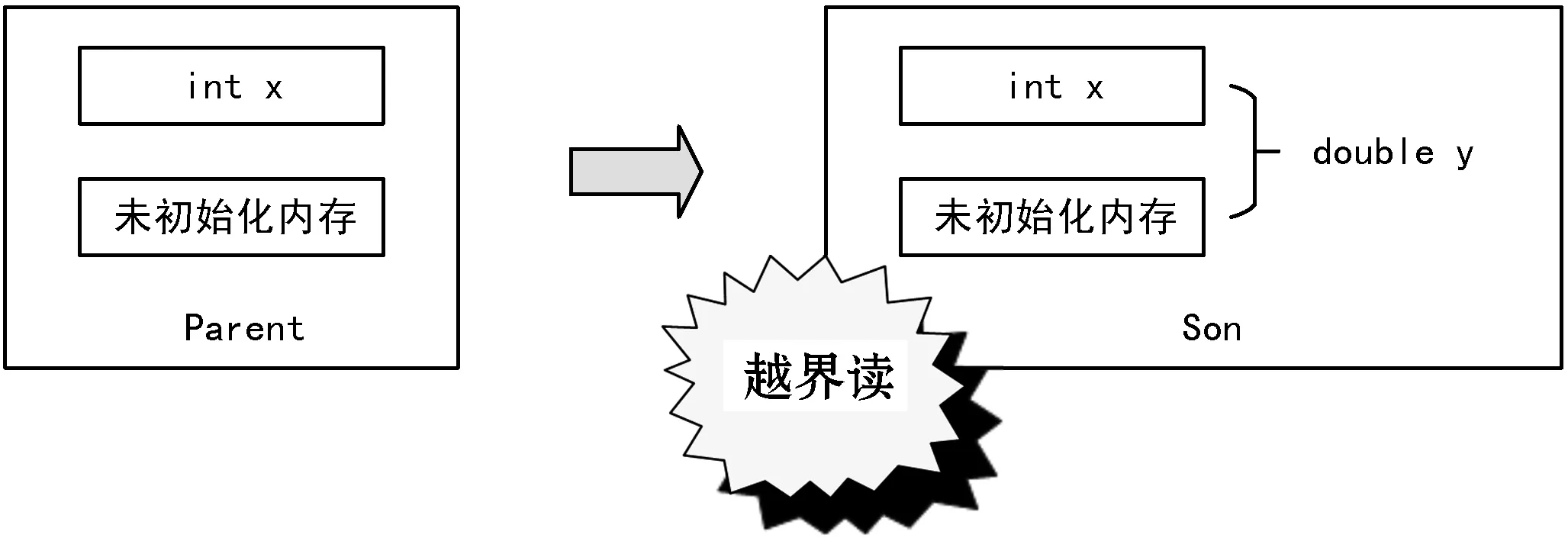
圖1 cast操作使用不當導致的越界讀
不同類型變量間,直接用賦值符“=”進行賦值時,右操作數不指明轉換的類型,則進行的是隱式類型轉換。除了賦值操作,函數調用時形式參數的引用也存在隱式類型轉換,這類隱式類型轉換和賦值形式的隱式類型轉換有一點不同,函數調用時形式參數的隱式類型轉換可能會產生直接的安全問題。C/C++中一個熟知的內存復制函數memcpy可以對變量進行復制,由于memcpy函數的參數是指針變量,內存拷貝操作沒有相應的安全檢測,有潛在的安全風險。像memcpy這樣能直接操作指針變量的函數有不少,在實際開發過程中也經常出現由該情況引起的安全漏洞。本文提出的方法將著重解決該類問題。隱式類型轉換錯誤示例如下:
1 struct Example1
2 {
3 int x;
4 void *func();
5 };
6 struct Example2
7 {
8 int x;
9 long y;
10 };
11 int main()
12 {
13 Example1 *e1=new Example1();
14 Example2 *e2=new Example2();
15 e2→x=0;
16 e2→y=0x1234;
17 memcpy(e1,e2,sizeof(Example1));
18 e1→func();
19 return 0;
20 }
該示例錯誤地將int型變量賦值給了函數指針,調用函數e1->func()時變成了對0x1234這塊內存的解引用,程序試圖去請求訪問0x1234地址的內存,顯然地址0x1234在程序段中并不是一個合法的可讀地址,從而造成了內存訪問違例(對應linux下的segmentfault錯誤)。
2.2 LLVM
本文提出了一種針對C/C++隱式類型轉換產生的類型安全問題的編譯期檢測方法。該方法基于LLVM中間代碼檢索出程序代碼中的類型轉換語句,提取并比對變量類型以判斷該類型轉換是否會引入安全隱患。我們將該方法編譯為一個動態鏈接庫文件,以作為LLVM中間代碼的分析優化器,由LLVM opt工具加載執行。
LLVM[13]編譯器以其提供的優化特性而出名,其中的代碼優化階段允許開發人員利用LLVM提供的豐富的接口以實現自定義pass,也就是我們所說的優化器。LLVM架構如圖2所示。
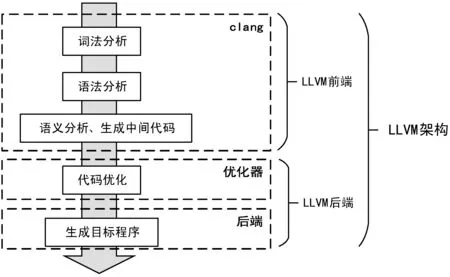
圖2 廣義LLVM架構
如圖3所示,自定義的優化器通過opt工具加載以在編譯期檢測類型轉換操作。opt工具又被稱為模塊化的LLVM優化器和分析器,它接受LLVM IR(LLVM輸出的以.ll為拓展名的中間代碼)和LLVM字節碼(LLVM輸出的以.bc為拓展名的中間代碼)格式作為輸入,通過-load選項選擇要加載的優化器。
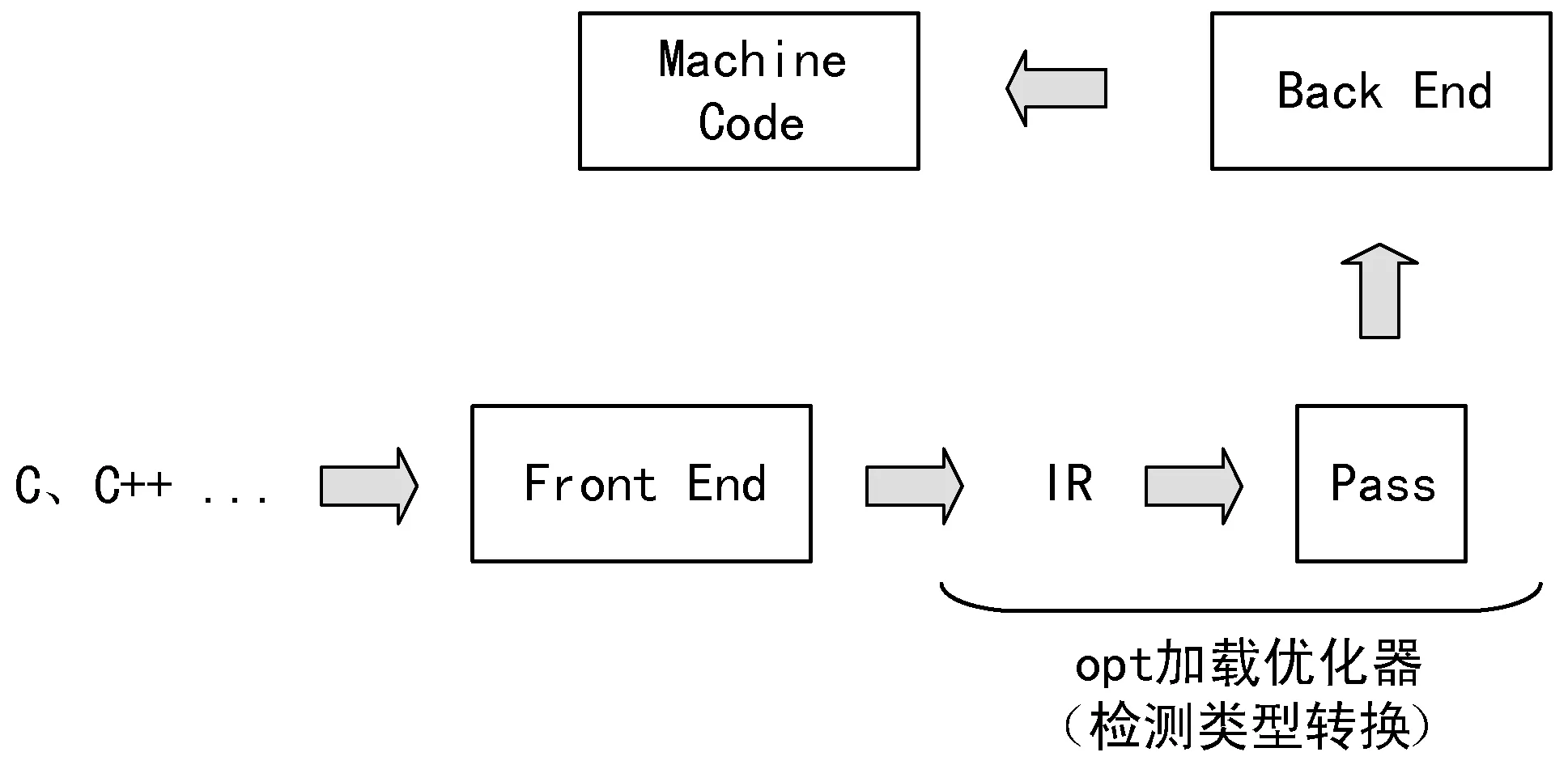
圖3 編譯過程中檢測類型轉換
3 方案設計
本節給出類型轉換安全的定義,并基于C/C++的一些語言特性,實現對類型轉換是否安全的一個判定算法。
3.1 類型處理
C/C++中的類型可以分為基本類型、枚舉類型、void類型和派生類型,由于本文的關注點是類型轉換問題,因此只考慮基本類型和派生類型。
基本類型,即bool、char、short、int等。
派生類型,包括指針類型、數組類型、結構類型、聯合體類型和函數類型。
不同數據類型可能占用不同的存儲空間,占用不用存儲空間的類型之間轉換存在越界讀的風險。本文對所有的數據類型按占用的存儲空間大小進行分組(以64位機器為標準):
① 占用1字節類型:bool、char、unsigned char;
② 占用2字節類型:short、unsigned short;
③ 占用4字節類型:int、unsigned int、float;
④ 占用8字節類型:long、unsigned long、double、long int、long long;
⑤ 占用16字節類型:long double;
⑥ 指針類型(數組類型可以視為指向數組開始元素的指針);
⑦ 結構體、聯合體等由多種類型復合而成的復雜數據類型。
typedef定義的類型別名,在編譯器做宏展開之后根據實際占用空間進行分類。
此外,在考慮變量類型的同時,還應當考慮其作用域。C/C++中可在以下區域聲明變量:
① 局部變量,在函數或代碼塊內部聲明;
② 全局變量,在函數外部聲明;
③ 形參,在函數的參數定義中聲明。
局部變量只能在函數內部被該函數或代碼塊內的語句使用,在函數外部不可見。全局變量定義在函數外部,通常是在程序頂部,在整個程序的生命周期內都是有效的,在任意函數內部均可訪問。形式參數即函數參數,可以作為函數內部的局部變量使用。
變量在定義時就確定了作用范圍,不同的變量其生命周期也可能有所不同。本文為了對不同變量的作用域和生命周期進行管理,確保能夠在必要的時候對變量進行跟蹤,按定義變量的位置對變量的作用域和生命周期進行了劃分:
① 外部變量:所有定義于函數外部的變量,包括函數和全局變量;
② 內部變量:所有定義于函數內部的變量,包括局部變量和形式參數。
之所以這樣處理,是因為考慮到帶返回值函數的函數返回值也可以在賦值操作的過程中作為賦值符號“=”的右值參與隱式類型轉換,也可以作為函數調用的參數,所以從實際效果上看,帶返回值的函數實際上是一類特殊變量,變量類型由函數返回值(函數)類型決定。由于C/C++語法規定函數不允許嵌套定義,即函數必須定義在其他任意函數的外部,因此從某種意義上帶返回值的函數可以當作全局變量處理。基于此分析,本文在檢測過程中將函數和全局變量視為一類一起檢測,省去了對函數和變量的區分操作,一定程度上提高了檢測效率。
3.2 類型存儲
基于LLVM的中間代碼可以提取出被測程序的變量類型信息,該類信息被寫入變量表。變量表的數據結構如下:
//類型劃分
enum
{
SINGLE,//1字節
DOUBLE, //2字節
QUAR, //4字節
OCT, //8字節
HEX, //16字節
POINTER, //指針類型
COMPLEX, //復雜類型
}type;
//作用域劃分
#define OUTER 1 //外部變量
#define INNER 0 //內部變量
struct
{
long nameHash; //對變量名Hash
int type;
int scope;
complex_type typeLayout; //復雜類型存儲對應結
//構樹,否則為null
}TypeInfo;
SINGLE、DOUBLE、QUAR、OCT、HEX、COMPLEX、OTHER分別對應1字節、2字節、4字節、8字節、16字節、復雜類型和其他類型。某個劃分可能包含不止一種變量類型,這種劃分方式大大簡化了C/C++中的變量類型數量,基于該簡化模型可以更好地對類型轉換進行歸類,提高檢測效率。
校驗復雜數據類型間的轉換較基本類型而言更為復雜。為了比較兩種復雜數據類型的結構一致性,本文將復雜數據結構存儲為一顆名為typeLayout的樹。該樹的數據結構中包含了復雜數據結構各個成員變量相對于起始內存空間的偏移。復雜類型存儲樹數據結構如下:
//復雜類型存儲樹節點
typedef struct LayoutNode
{
long memberHash;
int offset;
LayoutNode child;
}LayoutNode;
//復雜類型存儲樹
typedef struct typeLayout
{
int scope;
long complex_structure_name_hash;
LayoutNode root;
}typeLayout;
3.3 類型提取
本文通過類型信息提取算法抽取出被測程序的類型信息。該算法以程序源碼文件為單位,遍歷函數中的每一條語句,如果在語句中發現類型定義,則將該處的類型信息(變量名稱、變量類型、作用域)以ExtractTypeInfo函數抽取出來。該函數的偽代碼如下:
1 ExtractTypeInfo(type):
2 if type is complex_type
3 NoteAsComplexType(type)
4 typeLayout = AnalyseComplexType(type)
5 CollectInfo(type, typeLayout)
6 else
7 CollectInfo(type, NULL)
在實際提取過程中,會出現這樣一種情形:在被測程序中有A、B兩個函數,兩個函數中均存在變量名為example但類型不同的變量。由于在提取變量的過程中沒有對同名變量做區分,后出現的變量將會覆蓋前面出現的變量的類型,導致類型信息提取過程中的信息丟失。
為此,在提取變量類型的過程中,我們使用如下方法來處理不同函數有相同變量名的情況:在對變量名進行Hash操作時,先用該變量所在的位置和變量名進行拼接組成一個新串,對拼接得到的新串再進行Hash操作。這樣直接通過Hash值區別了不同作用域下的同名變量。
3.4 檢測算法
在占用不同存儲空間大小的變量間進行類型轉換顯然是存在風險的,如將int型變量轉為double型變量,程序原本只能讀4字節的內存空間,卻在轉換后讀取8字節,會造成越界讀的安全問題。
對基本類型而言,我們定義了一個類型轉換操作表。該操作表以一個5×5大小的二維數組basic_conversion_set存儲。如表1所示,int型變量向double型變量轉換時是不安全的,因此basic_conversion_set[QUAR][OCT]=US(UNSAFE);而double型變量向int型變量轉換時,雖然會有精度損失,但是并不算安全問題,因此basic_conversion_set[OCT][QUAR]=S(SAFE)。而對于同級別類型之間的轉換,主要考察其值域是否匹配,例如對于int型變量x,當x=1時,將其轉換為unsigned int是安全的;但是當x=-1時,該轉換是不安全的。特殊的,指針、整數和浮點值均可以隱式地轉換為bool類型:非0值轉換為1,0值轉換為0。
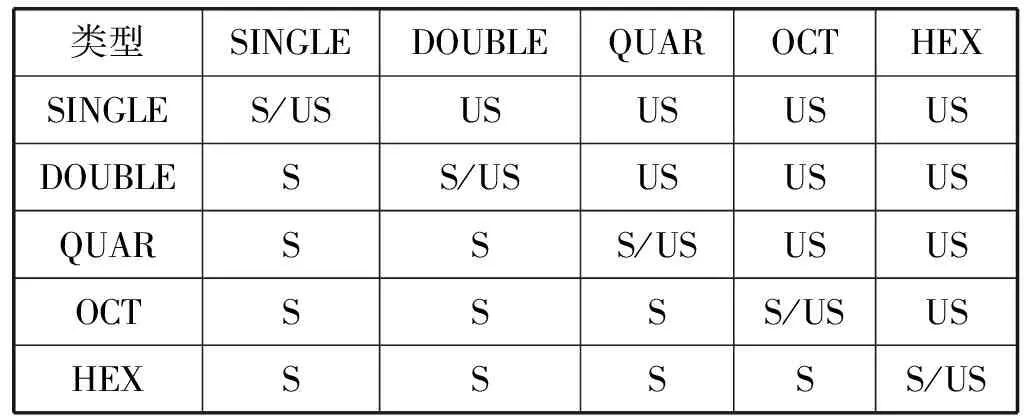
表1 基本類型類型轉換操作表
對指針類型而言,其指向內存的某一塊區域,編程人員可以對該區域進行操作。涉及指針類型的轉換:
① 一個指向任何對象類型的指針都可以轉換為void*類型;
② 兩個void*類型變量之間可以互相轉換,而且可以顯式地將void*轉換為另一個類型;
③ 除此以外的其他操作都是不安全的。
對復雜類型而言,可以將其視作多種數據類型組成的集合,其安全轉換必須滿足以下條件:
① 類型占用的內存空間大小相同;
② 成員變量相對于起始地址的偏移相同;
③ 成員變量間的轉換是安全的。
基于上述分析,我們實現了類型轉換的安全性判定算法,且整個檢測過程執行如下:遍歷程序中的每條語句,判斷語句中是否存在變量;如果語句中存在變量,進一步判斷是對該變量的定義還是引用;如果是定義則執行類型信息提取算法;如果是引用則執行安全性檢測算法。該算法的偽代碼如下:
1 VerifySafety(statement)
2 {
3 if NotImplicitTypeConvertion(statement)
4 return
5 else
6 TypeInfo origin = GetOriginInfo(statement)
7 TypeInfo target = GetTargetInfo(statement)
8 if(size(origin.type)>size(target.type))
9 UNSAFE
10 else if(origin.type && target.type are BASIC)
11 CheckBasicType(origin, target, basic_conversion_set)
12 else if(origin.type || target.type is POINTER)
13 CheckPointerType(origin, target)
14 else if(origin.type || target.type is COMPLEX)
15 CheckComplexType(origin, target)
16 else
17 SAFE
18 }
該函數首先對語句進行判斷,如果該語句包含類型轉換操作,那么進一步提取語句中進行類型轉換的兩個變量的類型信息。根據提取到的類型信息,先比較兩者的內存空間占用,只有在內存空間相同的情況下才進行后續判斷。
4 實 驗
4.1 實驗環境
本文基于LLVM編譯器實現對類型轉換的安全性檢測,為了更方便地使用LLVM編譯環境,選擇了Ubuntu18.04操作系統。實驗所用計算機的處理器為Intel Core i7- 4790 3.60 GHz 8核,內存32 GB,編譯器選擇gcc 8.1.0,項目構建選擇cmake 3.13.4,LLVM選擇了9.0.0。
4.2 實驗數據
本文從美國國家標準與技術研究院[14](National Institute of Standards and Technology,NIST)的軟件保障參考數據集[15](Software Assurance Reference Dataset,SARD)中選取了與類型轉換相關的四個子集以驗證上述方法的有效性。SARD以CWE[16](Common Weakness Enumeration)列表為基準,為列表中出現的各種類型的安全性問題設計了大量的測試用例。SARD類型轉換測試集如下:
CWE194_Unexpected_Sign_Extension
CWE195_Signed_to_Unsigned_Conversion_Error
CWE196_Unsigned_to_Signed_Conversion_Error
CWE843_Type_Confusion
其中,CWE194和CWE843對應不同數據類型之間互相轉換的情況,而CWE195和CWE196對應相同數據類型有符號和無符號之間互相轉換的情況。文件夾下每個文件對應該類型相關的一組測試用例,測試用例的正誤以函數名區分:good表示該例安全,應當通過;bad表示該例不安全,應當報警。

圖4 函數名區分測試用例正誤
4.3 實驗結果
從上述數據集中提取出的測試用例共計1 147個,其中成功檢測1 126個,錯誤檢測21個,準確率為98.17%。我們對錯誤的21個測試用例進行分析,其中一部分是由于在分析建模時,我們為了簡化分析,未考慮C/C++的存儲類,如auto等;另外一部分是由于測試用例中的成員變量類型相同,但是具有不同的排列順序。C/C++為提高內存的讀寫效率,變量在存儲時遵守對齊機制,可以通過特定的宏來定義默認的對齊值。結構體、聯合體在對齊機制的作用下,成員變量的排列順序可能會影響結構體占用的內存空間大小。
如圖5所示,A結構體和B結構體的成員變量及其類型完全相同,但是實際上,A結構體在64位機器下占用的內存大小為16字節,而B結構體占用的內存大小為24字節。考慮到這類情況的出現,本文方法的準確率實際上要高于98.17%。
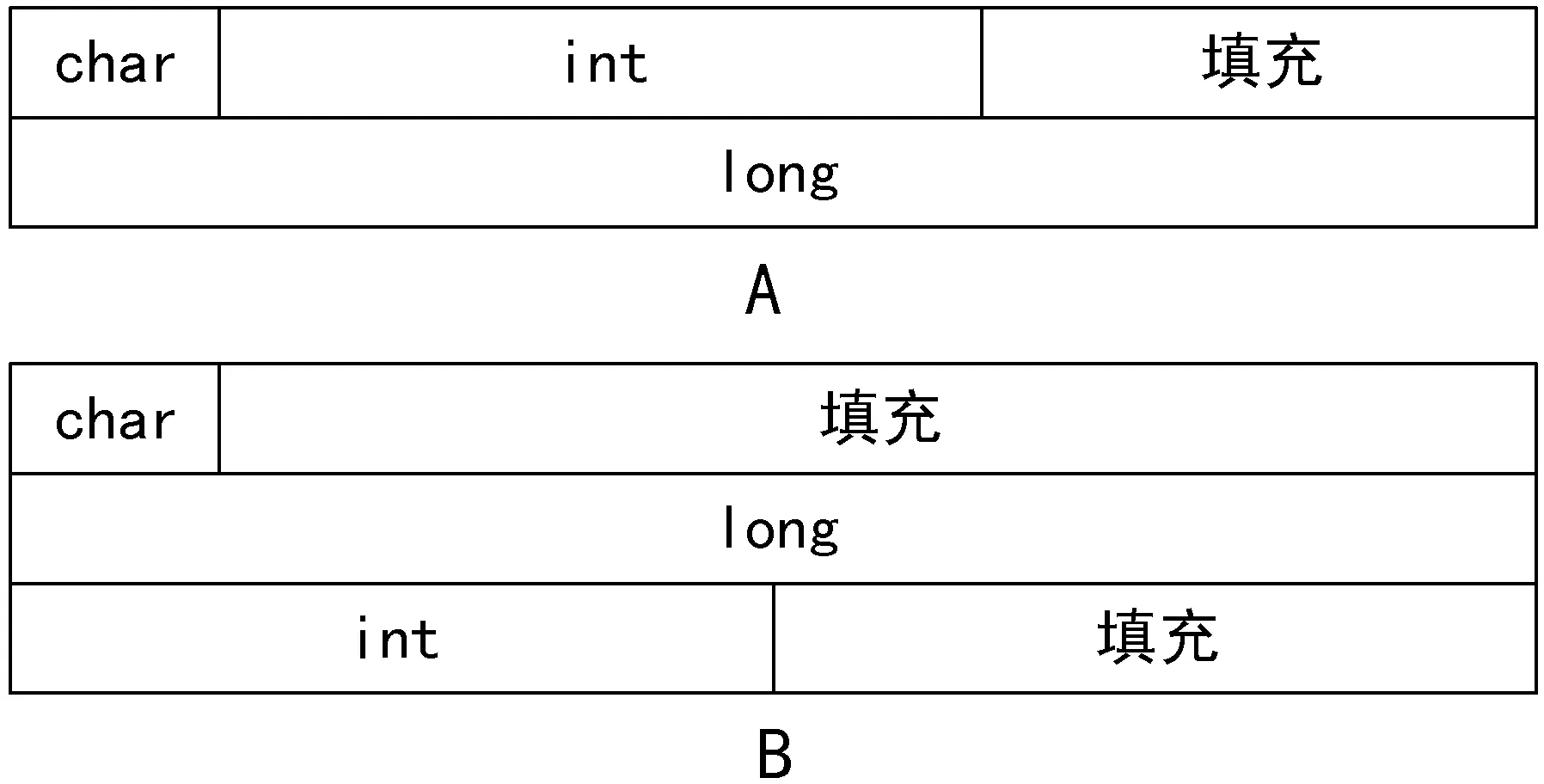
圖5 結構體成員變量的對齊方式
5 結 語
為幫助編程人員規避由類型轉換所帶來的安全風險,本文提出了一種針對C/C++隱式類型轉換產生的類型安全問題的編譯期檢測方法。該方法在編譯期作用于LLVM中間代碼,通過編寫并加載自定義的優化器來實現類型轉換的安全性檢測。自定義優化器繼承了LLVM內置的pass,依次遍歷程序源代碼中的每條語句,判斷語句中是否存在變量;如果語句中存在變量,則進一步判斷是對該變量的定義還是引用;如果是對變量的定義,則提取變量的類型信息并保存;如果是對變量的引用,則依據源變量和目標變量的類型判斷其是否符合安全規則。實驗結果表明,本文提出的方法能夠有效地檢測C/C++中出現的隱式類型轉換操作的安全性。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
